视觉SLAM之鱼眼相机模型
最近研究了视觉SLAM中不同的鱼眼相机模型,其中包括:
Scaramuzza的鱼眼相机模型
代表性的SLAM工作为MultiCo-SLAM,是一个以ORB-SLAM为基础的扩展的多鱼眼相机视觉SLAM系统(Video,Paper)
相机模型论文:A Flexible Technique for Accurate Omnidirectional Camera Calibration and
Structure from Motion
2017年Urban等人在此基础上,投影函数,使结果更加精确,论文地址
Scaramuzza相机模型标定工具:Tools:,其操作流程均可在相应网页中找到。
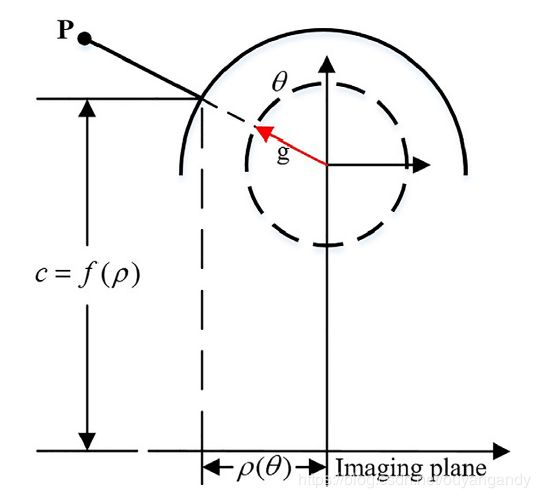
如上图所示,为Scaramuzza模型投影过程。
投影公式:
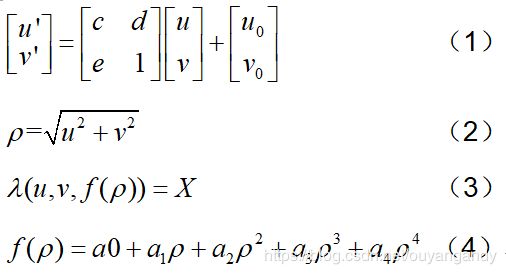
上述公式(1)中, [ u ′ , v ′ ] T \left[u^{\prime}, v^{\prime}\right]^{T} [u′,v′]T为image plane, [ u , v ] T [u, v]^{T} [u,v]T为sensor plane,对应于针孔相机模型来说,其实就是像素平面和图像平面。
上述公式(2)中,ρ为到图像中心的径向欧氏距离。
上述公式(3)中,为image point到空间三维点的映射方程。经过标定你会发现a1=0,这是因为,通过观察上图投影模型你会发现,当 f ( ρ ) f(\rho) f(ρ)取极大值时,图像坐标x=y=0,也就是入射角为0度, f ( ρ ) f(\rho) f(ρ)取导数, f ′ ( ρ ) f^{\prime}(\rho) f′(ρ)=0, ρ = u 2 + v 2 \rho=\sqrt{u^{2}+v^{2}} ρ=u2+v2=0,那么a1=0。
上述公式(4)为投影函数,其实在标定的过程中,主要标定的就是f函数的系数。
用一个示例程序说明Scaramuzza相机模型的投影过程.首先进行标定,下面代码中已经给出标定结果,直接拿来取用,3D点采用随机数产生。部分注释已经写在代码中,欢迎共同交流学习。
// cam_model_general.h
#pragma once
#ifndef CAM_MODEL_GENERAL_H
#define CAM_MODEL_GENERAL_H
#include // cam_model_general.cpp
#include mei相机模型
数学模型如下所示。也是VINS-mono所用的相机模型。具体可参考网页
相机模型的参考论文

未完待续~~仿佛说的不够细致,仿佛什么都没说。