这次一定要弄懂-SVM-3-Hard Margin SVM的对偶问题的求解(SMO算法)
文章目录
- 3-1 KKT条件
- 3-1-1 从拉格朗日乘数法的求解过程说起
- 3-1-2 推广出KKT条件
- 3-1-3 KKT条件用于原问题
- 3-1-4 KKT条件的作用:
- 3-1-5 决策边界中b的计算:
- 3-2 SMO算法
- 3-2-1 我们现在面临的棘手问题
- 3-2-2 破解对偶问题的神器SMO算法
- 3-2-3 SMO算法的理论推导
- 3-2-3-1 定义一些变量
- 3-2-3-2 KKT条件的作用
- 3-2-3-3 子问题的推导->如何优化选出的变量
- 3-2-3-3-1 转化为二元二次函数问题
- 3-2-3-3-2 确定$\alpha_j$的可行域
- 3-2-3-3-2 确定$\alpha_j$的值
- 3-2-3-3-3 确定$\alpha_i$的值
- 3-2-3-3-4 更新b
- 3-2-3-3-5 更新$E_k$
- 3-2-3-4 一些证明细节
- 3-2-3-4-1 SVM对偶问题的任意一个子问题都是凸优化问题(抛物线开口向上)
- 3-2-3-4-2 SVM算法收敛性的证明
- 3-2-3-5 优化变量的选择
- 3-2-4 总结SMO算法
- 3-3 总结
前面我们针对Hard Margin SVM推导了他的原问题:
min ω ∣ ∣ ω ∣ ∣ 2 2 \min \limits_{\bold{\omega}}\frac{||\omega||^2}{2} ωmin2∣∣ω∣∣2 s . t . s.t. s.t. y ( i ) ( ω T x ( i ) + b ) ⩾ 1 i=1,2,...m y^{(i)}(\bold{\omega}^T\bold{x^{(i)}}+b)\geqslant1 \quad\text{i=1,2,...m} y(i)(ωTx(i)+b)⩾1i=1,2,...m
对应的对偶问题:
min α 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x ( i ) ⋅ x ( j ) − ∑ i = 1 m α i \min\limits_{\alpha} \frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jx^{(i)}\cdot x^{(j)}-\sum\limits_{i=1}^m\alpha_i αmin21i=1∑mj=1∑mαiαjyiyjx(i)⋅x(j)−i=1∑mαi
s . t . s.t. s.t.
α i ⩾ 0 i = 1 , 2 , . . . , m \alpha_i\geqslant0\quad i=1,2,...,m αi⩾0i=1,2,...,m ∑ i = 1 m α i y i = 0 \sum\limits_{i=1}^m\alpha_iy_i=0 i=1∑mαiyi=0
以及决策边界中未知量w的计算方法:
w = ∑ i = 1 m α i y ( i ) x ( i ) w=\sum\limits_{i=1}^m\alpha_iy^{(i)}x^{(i)} w=i=1∑mαiy(i)x(i)
那决策边界中的未知量b如何计算呢?就要用了KKT条件,同时用于求解对偶问题的SMO算法也要应用到KKT条件,所以这一次的内容从KKT条件开始。
3-1 KKT条件
我们说广义拉格朗日乘子函数的构造是从原本只能解决带等式约束的拉格朗日乘数法推广而来,所以我们先从最原始的拉格朗日乘数法的求解开始过程开始。
3-1-1 从拉格朗日乘数法的求解过程说起
拉格朗日乘数法是求解带有等式约束的最优化问题
min x f ( x ) \min\limits_{x}f(x) xminf(x)
h i ( x ) = 0 , i = 1 , 2 , . . . , p h_i(x)=0,\quad i=1,2,...,p hi(x)=0,i=1,2,...,p
对应的求解方法就是构造拉格朗日乘子函数
L ( x , λ ) = f ( x ) + ∑ i = 1 p λ i h i ( x ) L(x,\lambda)=f(x)+\sum\limits_{i=1}^p\lambda_ih_i(x) L(x,λ)=f(x)+i=1∑pλihi(x)
接着对原始的优化变量以及乘子变量求导,并令导数为0,即:
{ ∇ x f + ∑ i = 1 p λ i ∇ x h i ( x ) = 0 h i ( x ) = 0 , i = 1 , 2 , . . . , p \begin{cases} \nabla_xf+\sum\limits_{i=1}^p\lambda_i\nabla_x h_i(x)=0\\ h_i(x)=0,\quad i =1,2,...,p \end{cases} ⎩⎨⎧∇xf+i=1∑pλi∇xhi(x)=0hi(x)=0,i=1,2,...,p
解这个方程组就可以找到极值点,但目前只是把疑似极值点求出来了,至于是不是极值点,是极大还是极小点,还需要进一步判定。
所以上面的方程组只是取得极值的必要条件,而不是充分条件。
3-1-2 推广出KKT条件
针对既带有等式约束和不等式约束的优化问题,我们可以构造广义拉格朗日函数
min x f ( x ) \min\limits_xf(x) xminf(x)
g i ( x ) ⩽ 0 , i = 1 , 2 , . . . q g_i(x)\leqslant0,\quad i=1,2,...q gi(x)⩽0,i=1,2,...q
h i ( x ) = 0 , i = 1 , 2 , . . . p h_i(x)=0,\quad i=1,2,...p hi(x)=0,i=1,2,...p
构造拉格朗日乘子函数
L ( x , λ , μ ) = f ( x ) + ∑ i = 1 p λ i h i ( x ) + ∑ j = 1 q μ j g j ( x ) L(x,\lambda,\mu)=f(x)+\sum\limits_{i=1}^p\lambda_ih_i(x)+\sum\limits_{j=1}^q\mu_jg_j(x) L(x,λ,μ)=f(x)+i=1∑pλihi(x)+j=1∑qμjgj(x)
设极值点为 x ∗ x^* x∗
在极值点出必须要满足:
| 1.原问题的约束条件 | g i ( x ∗ ) ⩽ 0 , i = 1 , 2 , . . . q g_i(x^*)\leqslant0,\quad i=1,2,...q gi(x∗)⩽0,i=1,2,...q h i ( x ∗ ) = 0 , i = 1 , 2 , . . . p h_i(x^*)=0,\quad i=1,2,...p hi(x∗)=0,i=1,2,...p |
| 2.对偶问题的约束条件 | μ i ⩾ 0 , i = 1 , 2 , . . . q \mu_i\geqslant0,\quad i=1,2,...q μi⩾0,i=1,2,...q |
| 3.松弛互补条件 | μ i g i ( x ∗ ) = 0 , i = 1 , 2 , . . . q \mu_ig_i(x^*)=0,\quad i=1,2,...q μigi(x∗)=0,i=1,2,...q |
| 4.X同时是拉格朗日函数的极小点 ∇ x L ( x ∗ , λ , μ ) = 0 \nabla_xL(x^*,\lambda,\mu)=0 ∇xL(x∗,λ,μ)=0 |
∇ x f ( x ∗ ) + ∑ i = 1 p λ i ∇ x h i ( x ∗ ) + ∑ j = 1 q μ j ∇ x g j ( x ∗ ) = 0 \nabla_xf(x^*)+\sum\limits_{i=1}^p\lambda_i\nabla_xh_i(x^*)+\sum\limits_{j=1}^q\mu_j\nabla_xg_j(x^*)=0 ∇xf(x∗)+i=1∑pλi∇xhi(x∗)+j=1∑qμj∇xgj(x∗)=0 |
再次详细说明下其中的松弛互补条件:
根据 μ i g i ( x ∗ ) = 0 , i = 1 , 2 , . . . q \mu_ig_i(x^*)=0,\quad i=1,2,...q μigi(x∗)=0,i=1,2,...q
我们会发现
当 μ > 0 \mu>0 μ>0时, g i ( x ∗ ) = 0 g_i(x^*)=0 gi(x∗)=0。说明极值点在边界处取得。
当 μ = 0 \mu=0 μ=0时, g i ( x ∗ ) ⩽ 0 g_i(x^*)\leqslant0 gi(x∗)⩽0。说明这个不等式约束对函数没有影响。
以上四条就是KKT条件,它是对原问题最优解的约束,是最优解的必要条件。
但是如果原问题和对偶问题存在强对偶问题,则KKT条件就是取得极值的充要条件。
而我们的支持向量机的原问题不管是线性可分的还是不可分,即使加上后面的核函数,都是强对偶问题。使得我们可以使用KKT条件,得到极值点的一些特征。
3-1-3 KKT条件用于原问题
原问题:
min ω ∣ ∣ ω ∣ ∣ 2 2 \min \limits_{\bold{\omega}}\frac{||\omega||^2}{2} ωmin2∣∣ω∣∣2 s . t . s.t. s.t. y ( i ) ( ω T x ( i ) + b ) ⩾ 1 i=1,2,...m y^{(i)}(\bold{\omega}^T\bold{x^{(i)}}+b)\geqslant1 \quad\text{i=1,2,...m} y(i)(ωTx(i)+b)⩾1i=1,2,...m
根据KKT条件中的松弛互补条件(对于不等式约束,乘子变量*函数值=0)
α i ( y i ( w T x ( i ) + b ) − 1 ) = 0 , i = 1 , 2 , . . . m \alpha_i\Big(y_i(w^Tx^{(i)}+b)-1\Big)=0,\quad i=1,2,...m αi(yi(wTx(i)+b)−1)=0,i=1,2,...m
我们仔细分析下松弛互补条件:
当 α i > 0 \alpha_i>0 αi>0时, y i ( w T x ( i ) + b ) = 1 y_i(w^Tx^{(i)}+b)=1 yi(wTx(i)+b)=1 —>支撑向量
当 α i = 0 \alpha_i=0 αi=0时, y i ( w T x ( i ) + b ) ⩾ 1 y_i(w^Tx^{(i)}+b)\geqslant1 yi(wTx(i)+b)⩾1—>自由变量,对分类超平面不起作用
3-1-4 KKT条件的作用:
- SMO算法选择优化变量
SMO算法是用于求解之后对偶问题的算法,它是一个迭代算法,每次仅选取两个乘子变量进行优化。KKT条件可以帮助我们寻找出需要优化的乘子变量。 - 迭代终止的判定规则
因为对于支持向量机来说KKT条件是极值点的充分必要条件,所以如果在迭代过程中发现待求点已经满足KKT条件了,那我们就把极值点解出来了,无须继续迭代。
3-1-5 决策边界中b的计算:
我们通过将原问题转化为拉格朗日对偶问题,使得最优化的变量从原本的w,b转换为拉格朗日乘子变量 α \alpha α
如果我们可以求得使得对偶问题最优的 α \alpha α后。则决策边界中的w可以通过 w = ∑ i = 1 m α i y i x ( i ) w=\sum\limits_{i=1}^m\alpha_iy_ix^{(i)} w=i=1∑mαiyix(i)求得
而决策边界中b通过松弛互补条件求得。
前面说到,对于最优点来说,当 α i > 0 \alpha_i>0 αi>0时, y i ( w T x ( i ) + b ) = 1 y_i(w^Tx^{(i)}+b)=1 yi(wTx(i)+b)=1。
所以我们只需要到 α i > 0 \alpha_i>0 αi>0对应的样本,求得b。
理论上来说,任意符合 α i > 0 \alpha_i>0 αi>0的样本,都可以用来计算b的值,但由于计算有误差,一般为了减小误差,会用所有满足 α i > 0 \alpha_i>0 αi>0的样本计算b,再取均值。
3-2 SMO算法
3-2-1 我们现在面临的棘手问题
前面讲到了对偶问题,让我们再看下推导得到的对偶问题
min α 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x ( i ) ⋅ x ( j ) − ∑ i = 1 m α i \min\limits_{\alpha} \frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jx^{(i)}\cdot x^{(j)}-\sum\limits_{i=1}^m\alpha_i αmin21i=1∑mj=1∑mαiαjyiyjx(i)⋅x(j)−i=1∑mαi
s . t . s.t. s.t.
α i ⩾ 0 i = 1 , 2 , . . . , m \alpha_i\geqslant0\quad i=1,2,...,m αi⩾0i=1,2,...,m ∑ i = 1 m α i y i = 0 \sum\limits_{i=1}^m\alpha_iy_i=0 i=1∑mαiyi=0
为了方便之后进一步的推导,我们将对偶问题写成向量化的形式
min α 1 2 α T Q α − e T α \min\limits_{\alpha} \frac{1}{2}\alpha^TQ\alpha-e^T\alpha αmin21αTQα−eTα
s . t . s.t. s.t.
y T α = 0 y^T\alpha=0 yTα=0 α i ⩾ 0 , i = 1 , 2 , . . . , m \alpha_i\geqslant0,\quad i=1,2,...,m αi⩾0,i=1,2,...,m
其中
矩阵 Q i j = y i y j x ( i ) ⋅ x ( j ) Q_{ij}=y_iy_jx^{(i)}\cdot x^{(j)} Qij=yiyjx(i)⋅x(j)
向量 e T = [ 1 , 1 , . . . , 1 ] e^T=[1,1,...,1] eT=[1,1,...,1]
关于从 ∑ j = 1 m α i α j y i y j x ( i ) ⋅ x ( j ) \sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jx^{(i)}\cdot x^{(j)} j=1∑mαiαjyiyjx(i)⋅x(j)到 α T Q α \alpha^TQ\alpha αTQα
应用了二次型展开。
这部分我不是熟悉,只依稀记得一个例子
x 2 + y 2 + z 2 = [ x y z ] [ 1 0 0 0 1 0 0 0 1 ] [ x y z ] x^2+y^2+z^2=\begin{bmatrix} x &y&z \end{bmatrix}\begin{bmatrix} 1 & 0 &0\\ 0 & 1&0\\ 0 & 0 &1 \end{bmatrix}\begin{bmatrix} x\\ y\\ z \end{bmatrix} x2+y2+z2=[xyz]⎣⎡100010001⎦⎤⎣⎡xyz⎦⎤
中间的矩阵对应的是原本的系数,所以Q本质上就是 α i α j \alpha_i\alpha_j αiαj的系数矩阵
这是一个大规模的二次函数的最优化问题,由于本身是凸优化问题,所以一些经典的最优化算法(如牛顿法,梯度下降法)可以收敛到极值点处。
但棘手的是还存在着等式约束和不等式约束,所以需要更好的求解算法,那就是SMO算法(序列最小最优化算法)
从SVM提出,到SMO算法提出之前,SVM并没有广泛使用就是因为这个对偶问题的求解非常麻烦。
3-2-2 破解对偶问题的神器SMO算法
SMO算法(Sequential minimal optimization)序列最小最优算法的核心思想是分治法(把一个大问题拆解成很多子问题来求解,然后把解合并起来,形成大问题的解)
SMO算法的巧妙之处在于每次选取两个变量进行优化。为什么不只选出一个变量进行优化呢?
因为我们有一个等式约束 ∑ i = 1 m α i y i = 0 \sum\limits_{i=1}^m\alpha_iy_i=0 i=1∑mαiyi=0,如果只有一个 α \alpha α变化的话,就会破坏原来的等式约束。
因此只调整一个变量是不行的,最少要调整2个变量。
根据这个想法,就可以把原来的m元2次问题转化成2元2次问题。
而对于2元2次函数的极值问题的求解就是初中内容了,可以通过等式约束,消掉一个变量,变成一元二次函数求极值的问题。
一元二次函数就是一个抛物线,但因为有 α ⩾ 0 \alpha\geqslant0 α⩾0的限定条件,所以我们需要根据这个情况来进行极值的讨论。
3-2-3 SMO算法的理论推导
3-2-3-1 定义一些变量
之后原来代换的变量也写在这边,方便查看
| 定义矩阵Q | Q i j = y i y j X i T X j Q_{ij}=y_iy_jX_i^TX_j Qij=yiyjXiTXj |
| 定义 u i u_i ui | u i = ∑ j = 1 m y j α j X j ⋅ X i + b u_i=\sum\limits_{j=1}^my_j\alpha_jX_j\cdot X_i+b ui=j=1∑myjαjXj⋅Xi+b u i u_i ui相当于把第i个样本带到我们的预测函数中 |
| 定义 K i j K_{ij} Kij | K i j = X i T X j K_{ij}=X_i^{T}X_j Kij=XiTXj |
| 定义s | s = y 1 y 2 s=y_1y_2 s=y1y2 |
| 定义 v i v_i vi | v i = ∑ k = 1 , k = ̸ i , k = ̸ j m y k α k K i k v_i=\sum\limits_{k=1,k=\not i,k=\not j}^m y_k\alpha_kK_{ik} vi=k=1,k≠i,k≠j∑mykαkKik |
| 定义 ξ \xi ξ | ξ = y i α i + y j α j = − ∑ k = 1 , k = ̸ i , k = ̸ j m y k α k \xi=y_i\alpha_i+y_j\alpha_j = -\sum\limits_{k=1,k=\not i,k=\not j}^m y_k\alpha_k ξ=yiαi+yjαj=−k=1,k≠i,k≠j∑mykαk |
| 定义 w w w | w = ξ y i w=\xi y_i w=ξyi |
| 定义 η \eta η | η = K i i + K j j − 2 K i j \eta=K_{ii}+K_{jj}-2K_{ij} η=Kii+Kjj−2Kij |
| 定义 E i E_i Ei | E i = u i − y i E_i=u_i-y_i Ei=ui−yi |
3-2-3-2 KKT条件的作用
再回忆KKT条件:
{ α i > 0 y i ( w T x ( i ) + b ) = 1 α i = 0 y i ( w T x ( i ) + b ) ⩾ 1 \begin{cases} \alpha_i>0 & y_i(w^Tx^{(i)}+b)=1\\ \alpha_i=0 & y_i(w^Tx^{(i)}+b)\geqslant1 \end{cases} {αi>0αi=0yi(wTx(i)+b)=1yi(wTx(i)+b)⩾1
之前讲到,KKT条件用于选择优化变量,判定迭代是否终止
-
选择优化变量:
KKT条件帮助我们选择每次哪两个变量来优化,怎么挑呢?只要这个变量违反KKT条件,我们就把它挑出来。
所以如果不满足kkt条件,就一定不是极值点,所以我们要把它挑出来,调整 α \alpha α使得满足KKT条件 -
判定迭代的依据:
如果alphai都满足,说明找到了极值点。
所以大体上SMO算法的流程图为:

根据SMO算法的流程图,可以看出我们需要解决的几个小问题,分别是如何初始化,如何选出优化变量,如何优化选出的变量。先就其中最繁琐的如何优化选出的变量说起。
3-2-3-3 子问题的推导->如何优化选出的变量
3-2-3-3-1 转化为二元二次函数问题
假如我们已经通过KKT条件,从m个 α \alpha α中已经选出了需要优化的2个变量 α i , α j \alpha_i,\alpha_j αi,αj
这时对于对偶问题 f ( α ) = 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x ( i ) ⋅ x ( j ) − ∑ i = 1 m α i f(\alpha)=\frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jx^{(i)}\cdot x^{(j)}-\sum\limits_{i=1}^m\alpha_i f(α)=21i=1∑mj=1∑mαiαjyiyjx(i)⋅x(j)−i=1∑mαi来说,只有 α i \alpha_i αi和 α j \alpha_j αj是变量,其他的都是常量,这时我们的目标函数就转化成了二元二次函数,再根据等式约束,可以进一步转化为一元二次求极值的问题。
我们将上式整理下,写成 系数 α i 2 + 系数 α j 2 + 系数 α i α j + 系数 α i + 系数 α j + 系数 \boxed{\text{系数}}\alpha_i^2+\boxed{\text{系数}}\alpha_j^2+\boxed{\text{系数}}\alpha_i\alpha_j+\boxed{\text{系数}}\alpha_i+\boxed{\text{系数}}\alpha_j+\boxed{\text{系数}} 系数αi2+系数αj2+系数αiαj+系数αi+系数αj+系数这样的形式
g ( α i , α j ) = 1 2 K i i α i 2 + 1 2 K j j α j 2 + s K i j α i α j + y i v i α i + y j v j α j − α i − α j g(\alpha_i,\alpha_j)=\frac{1}{2}K_{ii}\alpha_i^2+\frac{1}{2}K_{jj}\alpha_j^2+sK_{ij}\alpha_i\alpha_j+y_iv_i\alpha_i+y_jv_j\alpha_j-\alpha_i-\alpha_j g(αi,αj)=21Kiiαi2+21Kjjαj2+sKijαiαj+yiviαi+yjvjαj−αi−αj
其中
s = y 1 y 2 s=y_1y_2 s=y1y2
v i = ∑ k = 1 , k = ̸ i , k = ̸ j m y k α k K i k v_i=\sum\limits_{k=1,k=\not i,k=\not j}^m y_k\alpha_kK_{ik} vi=k=1,k≠i,k≠j∑mykαkKik
约束条件为
α i ⩾ 0 \alpha_i\geqslant0 αi⩾0
α j ⩾ 0 \alpha_j\geqslant0 αj⩾0
∑ k = 1 m y k α k = 0 \sum\limits_{k=1}^my_k\alpha_k=0 k=1∑mykαk=0由此可以推出
y i α i + y j α j = − ∑ k = 1 , k = ̸ i , k = ̸ j m y k α k = ξ y_i\alpha_i+y_j\alpha_j = -\sum\limits_{k=1,k=\not i,k=\not j}^m y_k\alpha_k=\xi yiαi+yjαj=−k=1,k≠i,k≠j∑mykαk=ξ
接下来的目标就是计算 f ( α i , α j ) f(\alpha_i,\alpha_j) f(αi,αj)的极值
3-2-3-3-2 确定 α j \alpha_j αj的可行域
因为
y i α i + y j α j = − ∑ k = 1 , k = ̸ i , k = ̸ j m y k α k = ξ y_i\alpha_i+y_j\alpha_j = -\sum\limits_{k=1,k=\not i,k=\not j}^m y_k\alpha_k=\xi yiαi+yjαj=−k=1,k≠i,k≠j∑mykαk=ξ
所以
α i + y i y j α j = y i ξ \alpha_i+y_iy_j\alpha_j=y_i\xi αi+yiyjαj=yiξ
由于 y i y j y_iy_j yiyj的正负号不知,所以一共对应四种情形,同时我们还可以尝试确定下 ξ \xi ξ的正负
| 序号 | y i y_i yi | y j y_j yj | α i + y i y j α j = y i ξ \alpha_i+y_iy_j\alpha_j=y_i\xi αi+yiyjαj=yiξ | ξ \xi ξ |
|---|---|---|---|---|
| 1 | + | + | α i + α j = ξ \alpha_i+\alpha_j=\xi αi+αj=ξ | + |
| 2 | - | - | α i + α j = − ξ \alpha_i+\alpha_j=-\xi αi+αj=−ξ | - |
| 3 | + | - | α i − α j = ξ \alpha_i-\alpha_j=\xi αi−αj=ξ | 不知 |
| 4 | - | + | α i − α j = − ξ \alpha_i-\alpha_j=-\xi αi−αj=−ξ | 不知 |
对应这四种情况,我们可以通过图像,分别确定出 α j \alpha_j αj的取值范围
| 序号 | y i y_i yi | y j y_j yj | α i + y i y j α j = y i ξ \alpha_i+y_iy_j\alpha_j=y_i\xi αi+yiyjαj=yiξ | ξ \xi ξ | |
|---|---|---|---|---|---|
| 1 | + | + | α i + α j = ξ \alpha_i+\alpha_j=\xi αi+αj=ξ | + |  Low boundary = 0 0 0 High boundary= α i + α j \alpha_i+\alpha_j αi+αj |
| 2 | - | - | α i + α j = − ξ \alpha_i+\alpha_j=-\xi αi+αj=−ξ | - |  Low boundary = 0 0 0 High boundary= α i + α j \alpha_i+\alpha_j αi+αj |
| 3 | + | - | α i − α j = ξ \alpha_i-\alpha_j=\xi αi−αj=ξ | 不知 |  Low boundary = max { 0 , α i − α j } \max\{0,\alpha_i-\alpha_j\} max{0,αi−αj} High boundary= + ∞ +\infin +∞ |
| 4 | - | + | α i − α j = − ξ \alpha_i-\alpha_j=-\xi αi−αj=−ξ | 不知 | 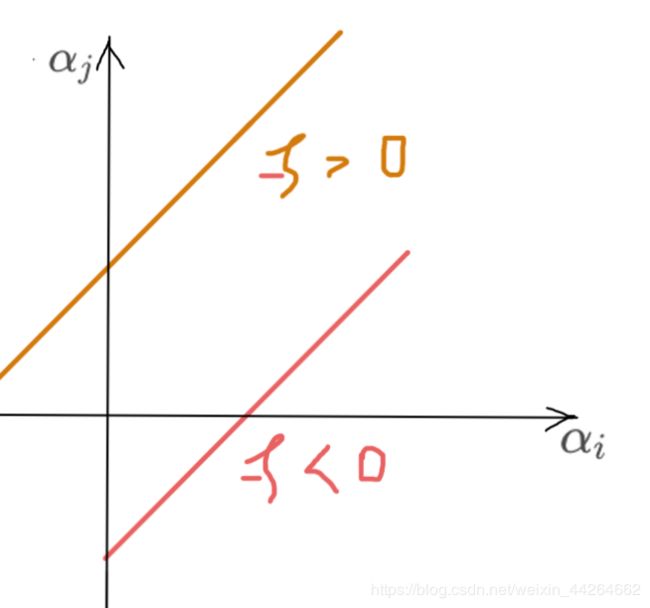 Low boundary = max { 0 , α i − α j } \max\{0,\alpha_i-\alpha_j\} max{0,αi−αj} High boundary= + ∞ +\infin +∞ |
最终总结下 α j \alpha_j αj的取值范围
{ α j ∈ [ 0 , α i + α j ] y i y j = 1 α j ∈ [ max { 0 , α i − α j } , + ∞ ) y i y j = − 1 \begin{cases} \alpha_j \in [0,\alpha_i+\alpha_j] & y_iy_j=1\\ \alpha_j\in [\max\{0,\alpha_i - \alpha_j\},+\infin)& y_iy_j=-1 \end{cases} {αj∈[0,αi+αj]αj∈[max{0,αi−αj},+∞)yiyj=1yiyj=−1
3-2-3-3-2 确定 α j \alpha_j αj的值
由于 α i \alpha_i αi与 α j \alpha_j αj存在等式关系,即 y i α i + y j α j = ξ y_i\alpha_i+y_j\alpha_j=\xi yiαi+yjαj=ξ,
左右同时乘以 y i y_i yi得
α i + y i y j α j = ξ y i \alpha_i+y_iy_j\alpha_j=\xi y_i αi+yiyjαj=ξyi,即
α i + s α j = ξ y i \alpha_i+s\alpha_j=\xi y_i αi+sαj=ξyi
令 w = ξ y i w=\xi y_i w=ξyi
故 α i = w − s α j \alpha_i=w-s\alpha_j αi=w−sαj
所以我们将上式带入
g ( α i , α j ) = 1 2 K i i α i 2 + 1 2 K j j α j 2 + s K i j α i α j + y i v i α i + y j v j α j − α i − α j g(\alpha_i,\alpha_j)=\frac{1}{2}K_{ii}\alpha_i^2+\frac{1}{2}K_{jj}\alpha_j^2+sK_{ij}\alpha_i\alpha_j+y_iv_i\alpha_i+y_jv_j\alpha_j-\alpha_i-\alpha_j g(αi,αj)=21Kiiαi2+21Kjjαj2+sKijαiαj+yiviαi+yjvjαj−αi−αj
就可以得到关于 α j \alpha_j αj的一元二次函数,接下来就是这个带入过程。
g ( α j ) = 1 2 K i i ( w − s α j ) 2 + 1 2 K j j α j 2 + s K i j ( w − s α j ) α j + y i v i ( w − s α j ) + y j v j α j − ( w − s α j ) − α j g(\alpha_j)=\frac{1}{2}K_{ii}(w-s\alpha_j)^2+\frac{1}{2}K_{jj}\alpha_j^2+sK_{ij}(w-s\alpha_j)\alpha_j+y_iv_i(w-s\alpha_j)+y_jv_j\alpha_j-(w-s\alpha_j)-\alpha_j g(αj)=21Kii(w−sαj)2+21Kjjαj2+sKij(w−sαj)αj+yivi(w−sαj)+yjvjαj−(w−sαj)−αj
我们可以通过对 g ( α j ) g(\alpha_j) g(αj)求导=0,得到极值点的位置
g ′ ( α j ) = K i i ( w − s α j ) ( − s ) + K j j α j + s K i j w − 2 s 2 K i j α j − s y i v i + y j v j + s − 1 = 0 g'(\alpha_j)=K_{ii}(w-s\alpha_j)(-s)+K_{jj}\alpha_j+sK_{ij}w-2s^2K_{ij}\alpha_j-sy_iv_i + y_jv_j+s-1=0 g′(αj)=Kii(w−sαj)(−s)+Kjjαj+sKijw−2s2Kijαj−syivi+yjvj+s−1=0
在整理过程中,我们使用一个小技巧
s y i v i = y i y j y i v i = y j v i sy_iv_i=y_iy_jy_iv_i=y_jv_i syivi=yiyjyivi=yjvi
带入目标函数中得到
( K i i + K j j − 2 K i j ) α j = s w ( K i i − K i j ) + y j v i − y j v j − s + 1 \big(K_{ii}+K_{jj}-2K_{ij}\big)\alpha_j=sw\big(K_{ii}-K_{ij}\big)+y_jv_i-y_jv_j-s+1 (Kii+Kjj−2Kij)αj=sw(Kii−Kij)+yjvi−yjvj−s+1
等号的右边可以进一步简化成和左边相似的结构。
用到一些小技巧比如
s w = y i y j y i ξ = y j ξ sw=y_iy_jy_i\xi=y_j\xi sw=yiyjyiξ=yjξ
其中 ξ = α i ∗ y i + α j ∗ y j \xi=\alpha_i^*y_i+\alpha_j^*y_j ξ=αi∗yi+αj∗yj
α i ∗ \alpha_i* αi∗和 α j ∗ \alpha_j^* αj∗表示未迭代的值
所以 s w = y j ( α i ∗ y i + α j ∗ y j ) sw=y_j(\alpha_i^*y_i+\alpha_j^*y_j) sw=yj(αi∗yi+αj∗yj)
将 s w = y j ( α i ∗ y i + α j ∗ y j ) sw=y_j(\alpha_i^*y_i+\alpha_j^*y_j) sw=yj(αi∗yi+αj∗yj)带入右式,同时让 s = y i y j s=y_iy_j s=yiyj, 1 = y j y j 1=y_jy_j 1=yjyj
s w ( K i i − K i j ) + y j v i − y j v j − s + 1 = y j ( α i ∗ y i + α j ∗ y j ) ( K i i − K i j ) + y j v i − y j v j − y i y j + y j y j = y i y j α i ∗ K i i + α j ∗ K i i − y i y j α i ∗ K i j − α j ∗ K i j + y j ( v i − v j + y j − y i ) \begin{aligned} &sw\big(K_{ii}-K_{ij}\big)+y_jv_i-y_jv_j-s+1 \\ &=y_j(\alpha_i^*y_i+\alpha_j^*y_j)\big(K_{ii}-K_{ij}\big)+y_jv_i-y_jv_j-y_iy_j+y_jy_j\\ &=y_iy_j\alpha_i^*K_{ii}+\alpha_j^*K_{ii}-y_iy_j\alpha_i^*K_{ij}-\alpha_j^*K_{ij}+y_j\big(v_i-v_j+y_j-y_i\big)\\ \end{aligned} sw(Kii−Kij)+yjvi−yjvj−s+1=yj(αi∗yi+αj∗yj)(Kii−Kij)+yjvi−yjvj−yiyj+yjyj=yiyjαi∗Kii+αj∗Kii−yiyjαi∗Kij−αj∗Kij+yj(vi−vj+yj−yi)
接下来的化简要将 v i v_i vi用 u i u_i ui表示
回忆
v i = ∑ k = 1 , k = ̸ i , k = ̸ j m y k α k K i k = X i ⋅ ∑ k = 1 , k = ̸ i , k = ̸ j m y k α k X k v_i=\sum\limits_{k=1,k=\not i,k=\not j}^m y_k\alpha_kK_{ik}=X_i\cdot\sum\limits_{k=1,k=\not i,k=\not j}^m y_k\alpha_kX_k vi=k=1,k≠i,k≠j∑mykαkKik=Xi⋅k=1,k≠i,k≠j∑mykαkXk
u i = ∑ j = 1 m y j α j K i j + b = X i ⋅ ∑ j = 1 m y j α j X j + b = v i + y i α i ∗ X i X i + y j α j ∗ X j X i + b u_i=\sum\limits_{j=1}^my_j\alpha_jK_{ij}+b=X_i\cdot\sum\limits_{j=1}^my_j\alpha_jX_{j}+b=v_i+\textcolor{blue}{y_i\alpha_i^*X_iX_i+y_j\alpha_j^*X_jX_i+b} ui=j=1∑myjαjKij+b=Xi⋅j=1∑myjαjXj+b=vi+yiαi∗XiXi+yjαj∗XjXi+b
也就是说
v i − v j = u i − u j + y j α j X j X j + y i α i X i X j − y i α i X i X i − y j α j X j X i v_i-v_j=u_i-u_j+y_j\alpha_jX_jX_j+y_i\alpha_iX_iX_j-y_i\alpha_iX_iX_i-y_j\alpha_jX_jX_i vi−vj=ui−uj+yjαjXjXj+yiαiXiXj−yiαiXiXi−yjαjXjXi
= u i − u j + y j α j ∗ K j j + y i α i ∗ K i j − y i α i ∗ K i i − y j α j ∗ K i j =u_i-u_j+y_j\alpha_j^*K_{jj}+y_i\alpha_i^*K_{ij}-y_i\alpha_i^*K_{ii}-y_j\alpha_j^*K_{ij} =ui−uj+yjαj∗Kjj+yiαi∗Kij−yiαi∗Kii−yjαj∗Kij
所以等号右边可以继续化简
= y i y j α i ∗ K i i + α j ∗ K i i − y i y j α i ∗ K i j − α j ∗ K i j + y j ( v i − v j + y j − y i ) =y_iy_j\alpha_i^*K_{ii}+\alpha_j^*K_{ii}-y_iy_j\alpha_i^*K_{ij}-\alpha_j^*K_{ij}+y_j\big(v_i-v_j+y_j-y_i\big) =yiyjαi∗Kii+αj∗Kii−yiyjαi∗Kij−αj∗Kij+yj(vi−vj+yj−yi)
= y i y j α i ∗ K i i + α j ∗ K i i − y i y j α i ∗ K i j − α j ∗ K i j + y j ( u i − u j + y j α j ∗ K j j + y i α i ∗ K i j − y i α i ∗ K i i − y j α j ∗ K i j + y j − y i ) =y_iy_j\alpha_i^*K_{ii}+\alpha_j^*K_{ii}-y_iy_j\alpha_i^*K_{ij}-\alpha_j^*K_{ij}+y_j\big(u_i-u_j+y_j\alpha_j^*K_{jj}+y_i\alpha_i^*K_{ij}-y_i\alpha_i^*K_{ii}-y_j\alpha_j^*K_{ij}+y_j-y_i\big) =yiyjαi∗Kii+αj∗Kii−yiyjαi∗Kij−αj∗Kij+yj(ui−uj+yjαj∗Kjj+yiαi∗Kij−yiαi∗Kii−yjαj∗Kij+yj−yi)
= y i y j α i ∗ K i i + α j ∗ K i i − y i y j α i ∗ K i j − α j ∗ K i j + α j ∗ K j j + s α i ∗ K i j − s α i ∗ K i i − α j ∗ K i j + y j ( ( u i − u j ) − ( y i − y j ) ) =y_iy_j\alpha_i^*K_{ii}+\alpha_j^*K_{ii}-y_iy_j\alpha_i^*K_{ij}-\alpha_j^*K_{ij}+\alpha_j^*K_{jj}+s\alpha_i^*K_{ij}-s\alpha_i^*K_{ii}-\alpha_j^*K_{ij}+y_j\big((u_i-u_j)-(y_i-y_j)\big) =yiyjαi∗Kii+αj∗Kii−yiyjαi∗Kij−αj∗Kij+αj∗Kjj+sαi∗Kij−sαi∗Kii−αj∗Kij+yj((ui−uj)−(yi−yj))
= α j ∗ ( K i i + K j j − 2 K i j ) + y j ( ( u i − u j ) − ( y i − y j ) ) =\alpha_j^*\big(K_{ii}+K_{jj}-2K_{ij}\big)+y_j\big((u_i-u_j)-(y_i-y_j)\big) =αj∗(Kii+Kjj−2Kij)+yj((ui−uj)−(yi−yj))
这时,等号的左右边都有 ( K i i + K j j − 2 K i j ) \big(K_{ii}+K_{jj}-2K_{ij}\big) (Kii+Kjj−2Kij),对于取得极值点的 α j \alpha_j αj可以进一步化简
设
η = K i i + K j j − 2 K i j \eta=K_{ii}+K_{jj}-2K_{ij} η=Kii+Kjj−2Kij
E i = u i − y i E_i=u_i-y_i Ei=ui−yi
η α j = α j ∗ η + y j ( E i − E j ) \eta\alpha_j=\alpha_j^*\eta+y_j(E_i-E_j) ηαj=αj∗η+yj(Ei−Ej)
所以 α j = α j ∗ + y j ( E i − E j ) η \alpha_j=\alpha_j^*+\frac{y_j(E_i-E_j)}{\eta} αj=αj∗+ηyj(Ei−Ej)
这是在无约束时,使得 g ( α i , α j ) g(\alpha_i,\alpha_j) g(αi,αj)最小的点,我们令其为 α j b e s t \alpha_j^{best} αjbest但由于 α j \alpha_j αj还存在不等式约束
{ α j ∈ [ 0 , α i + α j ] y i y j = 1 α j ∈ [ max { 0 , α i − α j } , + ∞ ) y i y j = − 1 \begin{cases} \alpha_j \in [0,\alpha_i+\alpha_j] & y_iy_j=1\\ \alpha_j\in [\max\{0,\alpha_i - \alpha_j\},+\infin)& y_iy_j=-1 \end{cases} {αj∈[0,αi+αj]αj∈[max{0,αi−αj},+∞)yiyj=1yiyj=−1
所以再根据约束,进一步考虑最终迭代后 α i 的 值 \alpha_i的值 αi的值
对应的一共有三种情况
| 情况一 | 情况二 | 情况三 |
|---|---|---|
 |
 |
 |
最终迭代后 α j n e w \alpha_j^{new} αjnew的值为
α j n e w = { L if α j b e s t < L α j b e s t if L ⩽ α j b e s t ⩽ H H if α j b e s t > H \alpha_j^{new}=\left\{ \begin{aligned} &L & \quad\text{if }\alpha_j^{best}<L\\ &\alpha_j^{best} &\quad\text{if }L\leqslant\alpha_j^{best}\leqslant H \\ &H &\quad\text{if }\alpha_j^{best}>H \end{aligned} \right. αjnew=⎩⎪⎪⎨⎪⎪⎧LαjbestHif αjbest<Lif L⩽αjbest⩽Hif αjbest>H
3-2-3-3-3 确定 α i \alpha_i αi的值
因为 α i n e w y i + α j n e w y j = α i ∗ y i + α j ∗ y j \alpha_i^{new}y_i+\alpha_j^{new}y_j=\alpha_i^*y_i+\alpha_j^*y_j αinewyi+αjnewyj=αi∗yi+αj∗yj
所以迭代后
α i n e w = α i ∗ + s ( α j ∗ − α j n e w ) \alpha_i^{new}=\alpha_i^*+s(\alpha_j^*-\alpha_j^{new}) αinew=αi∗+s(αj∗−αjnew)
3-2-3-3-4 更新b
如果 α 1 > 0 \alpha_1>0 α1>0
则 ∑ k = 1 m y k α k X k X 1 + b 1 n e w = y 1 \sum\limits_{k=1}^my_k\alpha_kX_kX_1+b_1^{new}=y_1 k=1∑mykαkXkX1+b1new=y1
即 ∑ k = 3 m y k α k X k X 1 + α 1 n e w y 1 K 11 + α 2 n e w y 2 K 21 + b 1 n e w = y 1 \sum\limits_{k=3}^my_k\alpha_kX_kX_1+\alpha_1^{new}y_1K_{11}+\alpha_2^{new}y_2K_{21}+b_1^{new}=y_1 k=3∑mykαkXkX1+α1newy1K11+α2newy2K21+b1new=y1
所以 b 1 n e w = y 1 − ∑ k = 3 m y k α k X k X 1 − α 1 n e w y 1 K 11 − α 2 n e w y 2 K 21 b_1^{new}=y_1-\sum\limits_{k=3}^my_k\alpha_kX_kX_1-\alpha_1^{new}y_1K_{11}-\alpha_2^{new}y_2K_{21} b1new=y1−k=3∑mykαkXkX1−α1newy1K11−α2newy2K21
未更新的 E 1 = ∑ k = 3 m y k α k K k 1 + α 1 ∗ y 1 K 11 + α 2 ∗ y 2 K 21 + b ∗ − y 1 E_1=\sum\limits_{k=3}^my_k\alpha_kK_{k1}+\alpha_1^{*}y_1K_{11}+\alpha_2^{*}y_2K_{21}+b^{*}-y_1 E1=k=3∑mykαkKk1+α1∗y1K11+α2∗y2K21+b∗−y1
所以可得 y 1 − ∑ k = 3 m y k α k K k 1 = − E 1 + α 1 ∗ y 1 K 11 + α 2 ∗ y 2 K 21 + b ∗ y_1-\sum\limits_{k=3}^my_k\alpha_kK_{k1}=-E_1+\alpha_1^{*}y_1K_{11}+\alpha_2^{*}y_2K_{21}+b^* y1−k=3∑mykαkKk1=−E1+α1∗y1K11+α2∗y2K21+b∗
故
b 1 n e w = − E 1 + α 1 ∗ y 1 K 11 + α 2 ∗ y 2 K 21 + b ∗ − α 1 n e w y 1 K 11 − α 2 n e w y 2 K 21 b_1^{new}=-E_1+\alpha_1^{*}y_1K_{11}+\alpha_2^{*}y_2K_{21}+b^*-\alpha_1^{new}y_1K_{11}-\alpha_2^{new}y_2K_{21} b1new=−E1+α1∗y1K11+α2∗y2K21+b∗−α1newy1K11−α2newy2K21
= b ∗ − E 1 + y 1 K 11 ( α 1 ∗ − α 1 n e w ) + y 2 K 21 ( α 2 ∗ − α 2 n e w ) =b^*-E_1+y_1K_{11}(\alpha_1^*-\alpha_1^{new})+y_2K_{21}(\alpha_2^*-\alpha_2^{new}) =b∗−E1+y1K11(α1∗−α1new)+y2K21(α2∗−α2new)
同理可得
b 2 n e w = b ∗ − E 2 + y 1 K 12 ( α 1 ∗ − α 1 n e w ) + y 2 K 22 ( α 2 ∗ − α 2 n e w ) b_2^{new}=b^*-E_2+y_1K_{12}(\alpha_1^*-\alpha_1^{new})+y_2K_{22}(\alpha_2^*-\alpha_2^{new}) b2new=b∗−E2+y1K12(α1∗−α1new)+y2K22(α2∗−α2new)
最终 b n e w b^{new} bnew的取值为
b n e w = b 1 n e w + b 2 n e w 2 b^{new}=\frac{b_1^{new}+b_2^{new}}{2} bnew=2b1new+b2new
对b的更新还不是十分确定,先暂时按这样的方式实现下代码
3-2-3-3-5 更新 E k E_k Ek
每次完成两个变量的优化之后,还必须更新对应的 E k E_k Ek,并将他们保存在列表中, E k E_k Ek值的更新要用到 b n e w b_{new} bnew
E k n e w = ∑ i = 1 m y i α i K i k + b n e w − y k E_k^{new}=\sum\limits_{i=1}^my_i\alpha_iK_{ik}+b^{new}-y_k Eknew=i=1∑myiαiKik+bnew−yk
3-2-3-4 一些证明细节
3-2-3-4-1 SVM对偶问题的任意一个子问题都是凸优化问题(抛物线开口向上)
用到的方法利用是Hessian矩阵判断
子问题的Hessian矩阵为
[ Q i i Q i j Q j i Q j j ] \begin{bmatrix} Q_{ii} & Q_{ij}\\ Q_{ji} & Q_{jj} \end{bmatrix} [QiiQjiQijQjj]
可以写成如下矩阵乘积的形式
[ y i X i T y i X j T ] [ y i X i y j X j ] = A T A \begin{bmatrix} y_iX_i^T \\ y_iX_j^T \end{bmatrix} \begin{bmatrix} y_iX_i & y_jX_j \end{bmatrix}=A^TA [yiXiTyiXjT][yiXiyjXj]=ATA
任意的向量x
x T A T A x = ( A x ) T ( A x ) ⩾ 0 x^TA^TAx=(Ax)^T(Ax)\geqslant0 xTATAx=(Ax)T(Ax)⩾0
所以Hessian矩阵半正定,因此目标函数一定为凸函数
3-2-3-4-2 SVM算法收敛性的证明
因为无论迭代时,两个变量的初始值时多少,通过上面的子问题求解算法得到的是在可行域内的最小值,因此每次更新完这两个变量后,都能保证目标函数的值小于或者等于初始值,即函数值下降。同时SVM要求解的对偶问题是凸优化问题,有全局最小解,所以SMO算法能保证收敛。
3-2-3-5 优化变量的选择
使用KKT条件,挑选出违反KKT条件的样本,进行优化。
根据前面的推导,在最优点处必须满足
{ α i > 0 y i ( w T x ( i ) + b ) = 1 α i = 0 y i ( w T x ( i ) + b ) ⩾ 1 \begin{cases} \alpha_i>0 & y_i(w^Tx^{(i)}+b)=1\\ \alpha_i=0 & y_i(w^Tx^{(i)}+b)\geqslant1 \end{cases} {αi>0αi=0yi(wTx(i)+b)=1yi(wTx(i)+b)⩾1
其中 w w w用 α \alpha α来表示
设
u i = ∑ j = 1 m y j α j X j ⋅ X i + b u_i=\sum\limits_{j=1}^my_j\alpha_jX_j\cdot X_i+b ui=j=1∑myjαjXj⋅Xi+b
所以在最优点处必须满足
{ α i > 0 y i u i = 1 α i = 0 y i u i ⩾ 1 \begin{cases} \alpha_i>0 & y_iu_i=1\\ \alpha_i=0 & y_iu_i\geqslant1 \end{cases} {αi>0αi=0yiui=1yiui⩾1
根据上式,依此检查所有样本,如果违反了上面的条件,则需要优化。
优先优化 α i > 0 \alpha_i>0 αi>0
第二个变量的选择,选择使 ∣ E i − E j ∣ |E_i-E_j| ∣Ei−Ej∣最大化的值。
其中 E i = u i − y i E_i=u_i-y_i Ei=ui−yi
为什么选 ∣ E i − E j ∣ |E_i-E_j| ∣Ei−Ej∣最大的呢?因为这样选出来的值,通过调整后,使得目标函数下降最快
3-2-4 总结SMO算法
操作过程:
- 为 α i \alpha_i αi设置初始值,让 α i = 0 \alpha_i=0 αi=0
目的在于让初始的 α \alpha α满足等式约束和不等式约束 - 外层循环:
根据KKT条件选择两个优化变量
求解子问题
如果已经收敛,则退出,否则继续循环 - 结束循环
3-3 总结
终于把KKT条件和SMO算法整理好啦,发现这些理论推导,多试着推一推,也没有想象中那么恐怖。
接下来打算在下一篇文章中,整理下整个Hard Margin SVM的计算过程,并用python实现下。