星星之火OIer:斐波那契数列(二)——O(logn)算法(矩阵加速)
在上一讲中,我们已经了解了关于斐波那契数列的 算法
算法
但是我们在上一讲留了一个问题
当n几近于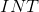 _
_ 时
时
又该怎么处理呢
那就要引入我们今天讲的::
矩阵加速
这个神奇的玩意可以将时间复杂度降至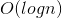
是不是很神奇!?
下面开始我们的正题
首先,让我们来了解了解矩阵::

这个A就是一个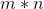 的矩阵
的矩阵
说直白点
的矩阵就指的是一个长方形的东西里面有 行
行 列的,有这么多个数
列的,有这么多个数
然后呢,矩阵有一些基本的运算
这些基本运算在作者的另一篇博客里有详细的讲解
这里主要提一下矩阵的乘法::
矩阵乘法有一个要求
两个矩阵必须一个为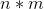 ,一个为
,一个为![]()
即这第一个矩阵的列必须和第二个矩阵的行数相同
就像是这样::

然后乘出来应该是一个![]() 的矩阵
的矩阵
如上图
![]()
所以乘出来的 应该是
应该是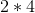 的矩阵
的矩阵
怎么来的呢??
乘出来的矩阵的第一行的第一个数是由 矩阵的第一行乘
矩阵的第一行乘 矩阵的第一列
矩阵的第一列
第一行的第二个数是由矩阵的第一行乘矩阵的第二列
第二行的第一个数是由矩阵的第二行乘矩阵的第一列
第行的第 个数是由矩阵的第行乘矩阵的第列
个数是由矩阵的第行乘矩阵的第列
依次这样下去,就会得到::

![]()
手算的,有错请帮忙指正一下
而且大家可以看一下,矩阵乘法满足交换律
即::![]()
大家可以自行推一推
再贴一个矩阵乘法的板子
结构体版::
struct matrix {
int n,m;
int mat[105][105];
matrix() {
n=0,m=0;
memset(mat,0,sizeof(mat));
}
void READ(const int N,const int M) {
n=N,m=M;
for(int i=1;i<=N;i++)
for(int j=1;j<=M;j++)
read(mat[i][j]);
}
matrix cut(const int row,const int col) const {
matrix res;
res=matrix();
res.n=n-1,res.m=m-1;
for(int i=1,cnt1=1;i<=n;i++)
if(i^row) {
for(int j=1,cnt2=1;j<=m;j++)
if(j^col) {
res.mat[cnt1][cnt2]=mat[i][j];
cnt2++;
}
cnt1++;
}
return res;
}
const int* operator [](const int row) const {
return mat[row];
}
matrix operator * (const matrix &other) const {
matrix res;
res=matrix();
res.n=n,res.m=other.m;
for(int i=1;i<=res.n;i++)
for(int j=1;j<=res.m;j++)
for(int k=1;k<=m;k++)
res.mat[i][j]+=mat[i][k]*other.mat[k][j];
return res;
}
void print() const {
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++)
if(i==n&&j==m)
pr(mat[i][j]);
else if(j==m)
pr(mat[i][j]),putchar('\n');
else
pr(mat[i][j]),putchar(' ');
}
}a,b,c;PS:代码里面的read和pr是作者打的快读快输的代码,这里未体现,详情请点击
当然,如果你不会结构体,那就看这个::
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++)
for(int k=1;k<=p;k++)
c[i][k]=c[i][k]+a[i][j]*b[j][k];简洁明了
然后呢
我们要了解一下快速幂
有这么一个东西
写作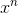
TA还可以写作![]() (n为偶数)
(n为偶数)
于是就有了快速幂
快速幂可以在的时间复杂度内算出
贴个快速幂的板子::
int ksm(int b,int n) {//b是底数,n是指数
int a=1;
while(n) {
if(n%2==1)//奇数就多乘一个
a*=b;
b*=b;//翻倍
n/=2;//指数相应就要变为原来的二分之一
}
return a;
}当然你也可以用递归写,只不过时间复杂度要高一些
好像接近我们今天探讨的话题了
有了
但矩阵乘法和快速幂有神马用呢??
如果我们能把矩阵和快速幂联系起来,那不就完美了吗
我们设置两个矩阵::
![]()
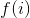 还是表示斐波那契的第
还是表示斐波那契的第 项
项
我们用![]()
发现乘出来的![]()
所以只要用![]() 就可以得到
就可以得到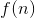
这就是矩阵乘法和快速幂的结合带来的强大效应
当然,如果你不喜欢写成2个数组,你也可以写成这样::
![]()
你把这个数组自乘一下,你会发现跟上面的是一个效果
至于怎么推出来的,请看作者的下一篇博客
然后呢,你就可以浪了
我们只要把快速幂和矩阵加速结合::
PS:这里作者给的是第二种算法,如果想看另一种方法的话,请看作者的另一篇类似的博客
#include
#include
inline void read(long long &x) {
x=0;
long long f=1;
char s=getchar();
while(s<'0'||s>'9') {
if(s=='-')
f=-1;
s=getchar();
}
while(s>='0'&&s<='9') {
x=x*10+s-48;
s=getchar();
}
x*=f;
}
inline void pr(long long x) {
if(x<0) {
putchar('-');
x=-x;
}
if(x>9)
pr(x/10);
putchar(x%10+48);
}//快读快输上面有解释
long long A[2][2]={1,1,1,0},n,m,ans[2][2];
inline void cheng(long long a[2][2],long long b[2][2]) {//矩阵乘法运算
long long c[2][2];
c[0][0]=c[0][1]=c[1][0]=c[1][1]=0;//乘了之后保存答案
for(long long i=0;i<2;i++)
for(long long j=0;j<2;j++)
for(long long k=0;k<2;k++)
c[i][j]=(c[i][j]+a[i][k]%m*b[k][j]%m)%m;//按上面说明的乘,记得模
memcpy(a,c,sizeof(c));//传回答案
}
inline void ksm(long long a[2][2],long long k) {//模拟快速幂
if(k==1) {//边界
memcpy(a,A,sizeof(A));
return;
}
long long c[2][2];
ksm(c,k/2);//这是递归的代码
cheng(c,c);//平方
if(k&1)//就是k%2==1即k为奇数
cheng(c,A);单独再乘一个
memcpy(a,c,sizeof(c));//传回答案
}
int main() {
read(n),read(m);
ksm(ans,n-1);
pr(ans[0][0]%m);//读入计算输出
} 这就是斐波那契数列的算法了
有不对的请帮忙指出哟
谢谢大家啦
另外还有一个
斐波那契数列——番外篇