frustum-pointnets复现过程+遇到的问题+解决方法
frustum-pointnets复现过程+遇到的问题+解决方法
系统Ubuntu16.04
1.下载KITTI数据集:

并按照README中的格式解压并重组数据集:
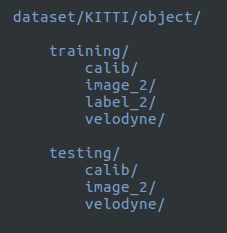
2.运行环境配置:
在复现KPConv的环境(‘python3’)下继续,首先安装一些包,已经安装的包不再安装(可KPConv复现链接中查看):
conda install pillow
pip install opencv-python
注意:若想在纯净的python环境下运行此代码(即:不使用conda,在系统python环境下),首先选择使用系统下的python2还是python3,然后pip安装需要的依赖项。若使用系统下的python3,则需要将frustum-pointnets/scripts/下的所有.sh文件中的python改为python3
3.数据准备
在对应目录终端下,运行sh scripts/command_prep_data.sh
训练v1模型(command_train_v1.sh)
4.修改部分代码
(1)frustum-pointnets/train/provider.py
import cPickle as pickle ----> import _pickle as pickle
将self.id_list = pickle.load(fp)等涉及pickle.load的函数,修改为
self.id_list = pickle.load(fp, encoding='latin1') # or “ encoding='iso-8859-1' ”
(2)frustum-pointnets/kitti/kitti_util.py
将cv2.CV_AA修改为cv2.LINE_AA(因为opencv-python==4.1.0.25)
(3)frustum-pointnets/kitti/prepare_data.py
import cPickle as pickle ----> import _pickle as pickle
(4)遇到问题:TypeError: 'float' object cannot be interpreted as an integer
解决办法:frustum-pointnets/train/train.py
train_one_epoch函数和eval_one_epoch函数中:
num_batches = len(TRAIN_DATASET)/BATCH_SIZE
---->
num_batches = len(TRAIN_DATASET)//BATCH_SIZE
5.成功运行CUDA_VISIBLE_DEVICES=0 sh scripts/command_train_v1.sh
测试v1模型(command_test_v1.sh)
6.修改部分代码
(1)遇到问题:TabError: inconsistent use of tabs and spaces in indentation
解决办法:frustum-pointnets/train/test.py
修改line 231和line 310中的batch_output, batch_center_pred, \语句,将该语句前面的tab换成空格。
(2)frustum-pointnets/train/test.py
import cPickle as pickle ----> import _pickle as pickle
(3)frustum-pointnets/train/test.py
在 def inference(sess, ops, pc, one_hot_vec, batch_size)中:
num_batches = pc.shape[0]/batch_size
---->
num_batches = pc.shape[0]//batch_size
(4)需要重新编译frustum-pointnets/train/kitti_eval/evaluate_object_3d_offline:
方法一:sh compile.sh(无报错)
方法二:g++ evaluate_object_3d_offline.cpp
遇到问题:
fatal error: boost/numeric/ublas/matrix.hpp: No such file or directory
解决办法:
sudo apt-get update
sudo apt-get install libboost-all-dev
(5)遇到问题:
sh: 1: gnuplot: not found
sh: 1: pdfcrop: not found
解决办法:
sudo apt-get install libx11-dev
sudo apt-get install gnuplot
sudo apt install texlive-extra-utils
7.成功运行CUDA_VISIBLE_DEVICES=0 sh scripts/command_test_v1.sh
「以下部分不在conda下环境下运行的,而是在(系统python3,tensorflow1.12.0,cuda9.0,cudnn7.4)下运行的」
训练v2模型(command_train_v2.sh)
8.修改部分代码
(1)frustum-pointnets/models/tf_ops/3d_interpolation/tf_interpolate_compile.sh
注释掉原有代码,写入:
# TF1.12.0, cuda9.0, cudnn7.4
g++ -std=c++11 tf_interpolate.cpp -o tf_interpolate_so.so -shared -fPIC -I /home/lab522/.local/lib/python3.5/site-packages/tensorflow/include -I /usr/local/cuda-9.0/include -I /home/lab522/.local/lib/python3.5/site-packages/tensorflow/include/external/nsync/public -lcudart -L /usr/local/cuda-9.0/lib64/ -L/home/lab522/.local/lib/python3.5/site-packages/tensorflow -ltensorflow_framework -O2 -D_GLIBCXX_USE_CXX11_ABI=0
然后在此目录下运行sh tf_interpolate_compile.sh
做此修改的主要原因在于cuda版本和tensorflow安装地址与原代码不一致,修改部分主要将cuda-8.0修改为了cuda-9.0,将/usr/local/lib/python2.7/dist-packages/tensorflow/修改为了/home/lab522/.local/lib/python3.5/site-packages/tensorflow/。
可以通过下面两行代码获得本机环境的tensorflow地址
import tensorflow as tf
print(tf.__path__)

(2)后面才发现这个文件可以不运行,所以这步可以略去
frustum-pointnets/models/tf_ops/grouping/compile.sh
------遇到问题1:compile.sh: 2: compile.sh: nvcc: not found
解决方法:这是nvcc找不到的问题。首先查看/usr/local/cuda/bin下是否有nvcc可执行程序,如果没有说明cuda没有正常安装,需要重新安装,如果有,进入下一步。第二步是在终端运行sudo gedit ~/.bashrc,在文件末尾添加export PATH=$PATH:/usr/local/cuda/bin,保存关闭文档后,终端运行source ~/.bashrc,最后终端运行nvcc --version检查是否成功。
------遇到问题2:gcc: error: query_ball_point_grid_count.cu: No such file or directory
解决办法:注释掉文档中的nvcc query_ball_point_grid_count.cu -o query_ball_point_grid_count
然后在此目录下运行sh compile.sh
(3)frustum-pointnets/models/tf_ops/grouping/tf_grouping_compile.sh
首先将文档中第二行的cuda-8.0改为cuda-9.0,然后注释掉原有代码(不注释前两行),写入:
# TF1.12.0, cuda9.0, cudnn7.4
g++ -std=c++11 tf_grouping.cpp tf_grouping_g.cu.o -o tf_grouping_so.so -shared -fPIC -I /home/lab522/.local/lib/python3.5/site-packages/tensorflow/include -I /usr/local/cuda-9.0/include -I /home/lab522/.local/lib/python3.5/site-packages/tensorflow/include/external/nsync/public -lcudart -L /usr/local/cuda-9.0/lib64/ -L/home/lab522/.local/lib/python3.5/site-packages/tensorflow -ltensorflow_framework -O2 -D_GLIBCXX_USE_CXX11_ABI=0
然后在此目录下运行sh tf_grouping_compile.sh
(4)frustum-pointnets/models/tf_ops/sampling/tf_sampling_compile.sh
首先将文档中第二行的cuda-8.0改为cuda-9.0,然后注释掉原有代码(不注释前两行),写入:
# TF1.12.0, cuda9.0, cudnn7.4
g++ -std=c++11 tf_sampling.cpp tf_sampling_g.cu.o -o tf_sampling_so.so -shared -fPIC -I /home/lab522/.local/lib/python3.5/site-packages/tensorflow/include -I /usr/local/cuda-9.0/include -I /home/lab522/.local/lib/python3.5/site-packages/tensorflow/include/external/nsync/public -lcudart -L /usr/local/cuda-9.0/lib64/ -L/home/lab522/.local/lib/python3.5/site-packages/tensorflow -ltensorflow_framework -O2 -D_GLIBCXX_USE_CXX11_ABI=0
然后在此目录下运行sh tf_sampling_compile.sh
(5)frustum-pointnets/scripts/command_train_v2.sh
遇到问题:Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
解决方法:OOM代表Out Of Memory。这意味着GPU空间不足,可以通过缩小模型或减小批量来解决此问题。将command_train_v2.sh文档中的--batch_size 24修改为--batch_size 8
9.成功运行CUDA_VISIBLE_DEVICES=0 sh scripts/command_train_v2.sh
测试v2模型(command_test_v2.sh)
10.修改部分代码
(1)frustum-pointnets/train/test.py
遇到问题:IndentationError: unexpected indent
解决办法:在6(1)中修改batch_output, batch_center_pred, \语句的缩进时出现操作失误,少缩进了4个空格,应该处于上一个for循环内部。
11.成功运行CUDA_VISIBLE_DEVICES=0 sh scripts/command_test_v2.sh
其他
12.git上下载frustum-pointnets-view-results,然后修改view_results.py中:
找到line 32、line 40、line 41、line 213、line 216的语句,将该语句前面的tab换成空格,然后运行python kitti/view_results.py
未完待续…