论文笔记《Learning Deep Correspondence through Prior and Posterior Feature Constancy》
- 摘要
- 介绍
- 相关工作
- 本论文方法
- 1 用于多尺度特征提取的茎块
- 2 初始视差估计子网络
- 3 视差精细化子网络
- 4 迭代精细化
- 实验
- 1 脱离实验
- 2 测试基准结果
- 总结
- 参考文献
摘要
立体匹配算法通常由四步组成:代价计算、代价聚合、视差计算和视差精细化。现有的基于CNN的立体匹配方法仅仅采用CNN来解决四步中的部分,或者使用不同的网络来处理不同的步骤,这使得它们很难获得全局最优的解决方案。这篇论文提出了一个合并了立体匹配所以步骤的网络结构。网络由三部分组成:第一部分计算多尺度共享特征。第二部分进行匹配代价计算、匹配代价聚合以及视差计算,以通过使用共享特征估计初始视差。初始视差和共享特征被用来计算在前的和较好的(prior and posterior)feature constancy。第三部分将initial disparity、prior feature constancy和posterior feature constancy输入一个子网络,以通过贝叶斯推理过程来精细化初始视差。
1 介绍
MC-CNN、Content-CNN、L-ResMatch等方法的限制:在计算每个可能的视差的匹配代价时,网络必须执行多个前向传递过程,这导致大的计算负担;遮挡区域的像素不能用于训练,因此这些区域很难获得一个可靠的视差估计;需要使用多个启发式的后处理步骤来精细化视差。在这些方法中,代价聚合和视差计算步骤通过最小化定义在匹配代价之上的能量方程来解决,如SGM。
GC-NET、DispNetC:直接堆叠几个卷积层来训练完整的网络以最小化网络输出与真值视差之间的距离,比起仅仅使用CNN计算匹配代价的方法,精度更高,计算更快。
DRR、CRL:和前两个网络一样,所谓完整的网络只是完成代价计算、代价聚合、初始视差计算。然后再用一个或多个网络来精细化初始视差。将视差精细化步骤和其他三个步骤整合在一起是非平凡的。
本论文:为了建立视差计算和视差精细化之间的桥梁,论文提出使用feature constancy来识别初始视差的正确性,然后将视差精细化任务构建成贝叶斯推理过程。“constancy”是从光流估计中引用而来。“Feature constancy”是指两个像素在特征空间中的对应关系。特别地,初始视差被当做prior disparity,以初始视差为条件的特征空间的重建错误被当做posterior feature constancy,从左右图提取的特征之间的correlation被当做prior feature constancy。然后,视差精细化任务的目标是通过一个子网络估计以feature constancy为条件的posterior disparity。(好多新的专有名词,看论文时要注意回头看定义)
论文贡献:1)将立体匹配中的所有步骤融合进一个网络以提高精度和速度;2)把视差精细化任务表达成一个使用恒定特征的贝叶斯推理过程;3)在KITTI测试基准上获得最好的效果。
2 相关工作
(总结一下)现有的基于CNN的立体匹配方法大致可以分为以下三类:
1)学习匹配代价(CNN for Matching Cost Learning):
MC-CNN[1]: 计算两个 9×9 图像块之间的匹配代价,然后再使用一系列的后处理步骤:基于交叉的代价聚合、半全局匹配、左右一致性校验、亚像素提升以及中值滤波器和双边滤波器。需要多个前馈过程来计算所有可能的视差的匹配代价,因而计算昂贵。
Content-CNN[2]: 将网络训练成多分类分类器,并引入了内积层来计算siamese架构的两个特征向量之间的内积,以减少计算时间。
L-ResMatch[4]: 使用具有多等级权重的残差捷径的高速网络来计算视差。这个架构比MC-CNN、传统的高速网络、ResNets、DenseNet已经ResNets of ResNets效果要好。
2)回归视差(CNN for Disparity Regression)
端到端训练的CNN直接从立体图像对估计视差。
DispNetC[5]:提出一种用于回归视差的编码-解码架构。匹配代价计算无缝地融合到编码部分,视差直接在一个前向过程回归得到。
GC-NET[6]: 在匹配代价上使用3D卷积来融合上下文信息,并且通过一个可微的“soft argmin”操作来回归视差。
这两个网络的运行速度都很快,但是网络中没有包括视差精细化步骤,因为限制了他们的性能。
3)多个网络(Multiple Networks)
L-ResMatch[4]:在使用高速网络计算匹配代价之后,再使用一个额外的全局视差网络来替换传统方法中的WTA。这个方法提高了遮挡、扭曲、高反和稀疏纹理区域的性能。
DRR[7]: 使用Content-CNN来计算初始视差,然后用另外一个网络精细化视差。
SGM-Net[8]: 使用SGM-Net来学习SGM参数化,获得比手工定义的方法更好地效果。
CRL[9]: 在DispNetC之上叠加了一个用于精细化视差的网络。
3 本论文方法
这篇论文把传统匹配方法中的四个步骤融合到一个单一的网络中,这样每个步骤都可以共享特征,并且可以联合优化,即端到端训练。所提出的的网络由三部分组成:多尺度共享特征提取部分、初始视差估计部分和视差精细化部分。

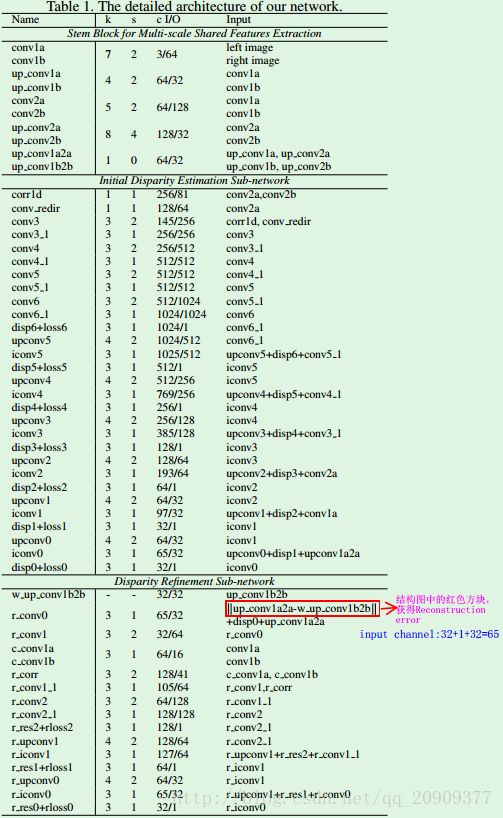
3.1 用于多尺度特征提取的茎块
stem block从两张输入图像提取多尺度共享特征,用于初始视差估计子网络和视差精细化子网络。(左右分支共享权重,以左分支为例)包含两层卷积层(步长为2,通道数: conv1a: 3->64, conv2a: 64->128)以减小输入图像的分辨率,然后再通过两层反卷积层分别上采样两层卷积层的输出到全分辨率(通道数: up_conv1a: 64->32,up_conv2a: 128->32)。这两个上采样的特征再通过一个 1×1 的卷积层进行融合[通道数: (32+32)->32]。具体结果见图1和表1。
stem block的输出可以分为三类:
1)第二层卷积层的输出(左图的conv2a和右图的conv2b)。然后在conv2a和conv2b之间执行具有大位移(40)的correlation(图1中第一个紫色长方块),以捕获两张图像之间的全部粗略对应关系(correspondence),然后用于估计初始视差的第一个子网络。【左右分支的第二层卷积层的输出进行第一次correlation,获得粗略的correspondence】
2)第一层卷积层的输出(左图的conv1a和右图的conv1b)。他们首先通过一个具有 3×3 卷积核的卷积层,被压缩为c_conv1a 和c_conv1b(包含更少通道64->16)。然后执行具有小位移(20)的correlation(图1中第二个紫色长方块),以捕获与前面的对应关系互补的细粒度但短范围的对应关系。另外,这些特征也充当被第二个子网络使用的prior feature constancy。【左右分支的第一层卷积层的输出进行第二次correlation,获得细粒度的correspondence】
3)多尺度融合特征(左图的up_conv1a和右图的up_conv1b经up_conv1a2a)。他们首先被用做跳跃连接特征(skip connection
features),为第一个子网络带来详细信息。然后被用来计算用于第二个网络的posterior feature constancy。
3.2 初始视差估计子网络
这部分子网络通过一个编码-解码结构,从conv2a和conv2b产生一个视差图。首先,利用一个correlation层来计算特征空间中的匹配代价(通道数:(128+128)->81)。注意,这里有个平衡:如果使用高水平的特征来计算代价,会丢失很多细节,并且几个相似的对应关系会无法被分辨。但如果使用低水平的特征来计算代价,则计算成本很高,因为特征图太大,并且感受野太小,无法获得鲁棒的特征。因此,论文中将上面correlation计算的匹配代价和来自左图的conv2a特征concatenate在一起。这样,我们就希望接下来的子网络在匹配代价之上估计视差时能够考虑到低水平的语义信息。这就在一定程度上聚合了匹配代价并改善了视差估计。
视差估计在解码部分在不同尺度上执行,每个尺度引进了跳跃连接,如表1所示。【其实前面两部分网络就是引用了DispNet结构】
3.3 视差精细化子网络
这篇论文把视差精细化任务构建成贝叶斯推理过程。确切地说,我们计算了prior and posterior constancy,并将初始视差当做prior disparity。接下来的视差精细化任务就是去推导考虑了这三个信息的posterior disparity。

其中, FC 是feature constancy(两个像素在特征空间中的对应关系), p(disp) 是第一个子网络产生的初始视差, p(FC) 计算为左和右特征图(c_conv1a, c_conv1b)之间correlation得到的prior feature constancy,度量两个特征图在多个位移下的对应关系,并且与估计的视差无关。 p(FC|disp) 是以初始视差为条件,计算为初始视差的重建错误的posterior feature constancy。确切地说,它是左图的多尺度共享特征(3.1)和右图的反转特征之间的绝对差。它被认为是posterior feature constancy是因为在特征图的每个位置只进行了一个位移,依赖于初始视差中对应的值。如果重建错误比较小,估计的视差就更有可能正确。否则,估计的视差要么错误,要么是来自于遮挡区域。
实际上,给出视差估计子网络产生的初始视差,视差精细化子网络的任务就是估计初始视差的偏差。偏差加上初始视差就被认为是精细化的视差图。
3.4 迭代精细化
为了从多尺度融合特征中提取更多的信息,并从根本上提高视差估计的精度,论文提出一种迭代精细化方法。确切地说,由第二个子网络产生的精细化视差图被认为是一个新的初始视差图,然后feature constancy计算和视差精细化过程反复执行,以获得新的精细化视差。直到两次迭代之间的提升很小。随着迭代次数的增加,提升会减小。这主要是因为重建错误和相关层都不能辨别出预测的视差的不正确。
(个人理解:feature constancy的迭代计算只是posterior feature constancy,而prior feature constancy是固定的。因为prior feature constancy和初始视差无关,而posterior feature constancy,即重建错误,是以初始视差为条件计算的。每一轮迭代结束时,所得到的精细化视差又当做初始视差,然后进行重建错误计算已经后面的精细化计算。也就是图1中,每次得到黄色长方块时,再把结果当做第一个绿色长方块,在两者之间迭代。)
4 实验
将本论文方法-IResNet(iterative residual prediction network)在Scene Flow 和 KITTI数据集上进行评估。
CAFFE架构,Adam优化(β1 =0.9, β2 = 0.999),batch_size=2, Multistep学习率. Scene Flow: 初始学习率为 10−4 , 然后在第20k次、第35k次和第50k次迭代时减少一半。总共训练迭代65k次。为了进一步优化模型,训练程序额外再重复一次。在KITTI数据集上进行微调时,前10k次迭代的学习率为 2×10−5 ,然后再接下来的90k迭代学习率减小为 10−5 。
使用数据增强:空间(旋转、转化、裁剪、缩放)和彩色(颜色、对比度、亮度)转换。这有助于学习一个对光照变化和噪音鲁棒的模型。
4.1 脱离实验
这部分主要是在KITTI上进行脱离实验,也就是分别测试各个模块。使用end-point-end(EPE)度量,计算为估计的视差和真值视差之间的平均欧几里得距离。还使用EPE大于t个像素的视差的百分比。
a) 多尺度跳跃连接
多尺度跳跃连接用来从不同水平引进特征,以改善视差估计和精细化的性能。表4是使用多尺度跳跃连接和单尺度跳跃连接的结果对比。多尺度比单尺度好的原因:第一层卷积层的输出包含高频信息,在目标边缘和具有大的颜色变化的区域会产生大的重建错误。注意,在远离边界的目标的表面区域,会有一个非常精确的初始视差,也就是重建错误会很小,尽管由于纹理的变化会产生大的颜色变化。这样,由第一层卷积层给出的重建错误在这些区域是不精确的。在这种情况下,多尺度跳跃连接可以提高重建错误的可信度。另外,引进高水平特征也有助于 feature constancy的计算,因为高水平特征利用了更多的上下文信息。

b) 用于视差精细化的Feature Constancy

由表可以看到,当加入完全没有feature constancy的DRS时,网络的提升很小(EPE: 2.81->2.72)。另外,可以看到,posterior feature constancy的提升作用最大,如果只是没有这部分,EPE会从2.50增大到2.70。这是因为这部分提供了初始视差的posterior信息,也就是说,那些具有不好的初始视差的区域能够被识别并被对位地改正。当所有三部分融合时,视差精细化网络可以工作在贝叶斯推理框架下,将获得最好的性能。
c) 迭代精细化

随着迭代次数的增加,性能的提升会快速下降。可以总结为:1)通过使用 feature constancy 信息可以高效地提取视差估计的有用信息;2)包含在特征空间中的信息任然有限。因此,通过引进更强大的特征,可以提升视差精细化的性能。
d) 一个网络 vs 多个网络
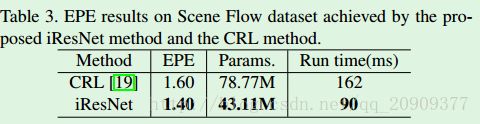
CRL:使用一个DispNetC网络计算视差,再使用一个DispResNet网络精细化视差(使用了两个独立的网络)。本论文是将视差计算和视差精细化融合到一个单一的网络。
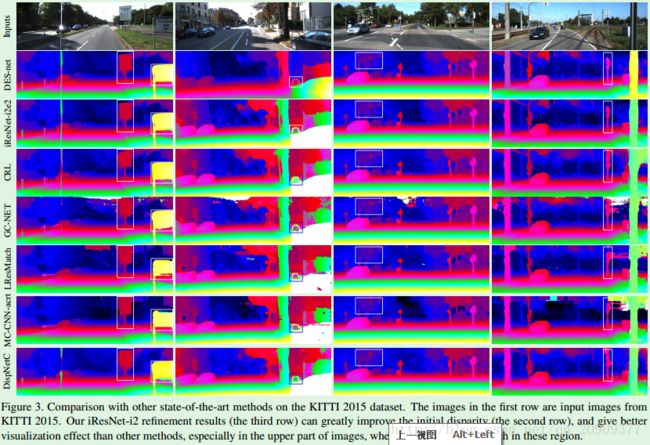
4.2 测试基准结果
本论文方法(iResNet-i2e2):i2是指进行了两次迭代,e2是指把输入图像的尺寸放大两倍。由实验结果可知,本论文提出的方法产生更平滑的结果,特别是在图像的上部,比其他方法好。图像上部没有ground-truth,对应天空或者在lidar工作范围外的区域。


5 总结
本论文提出一种融合了立体匹配的4个步骤的网络架构,可以联合训练。网络首先计算初始视差,然后使用prior和posterior feature constancy精细化视差。精细化被构建成贝叶斯推理过程,使得网络更容易被优化。
参考文献
[1] J. Zbontar and Y. LeCun. Stereo matching by training a convolutional neural network to compare image patches. Journal of Machine Learning Research, 17(1-32):2, 2016.
[2]W. Luo, A. G. Schwing, and R. Urtasun. Efficient deep learning for stereo matching. In IEEE Conference on Computer Vision and Pattern Recognition, pages 56955703, 2016.
3H. Park and K. M. Lee. Look wider to match image patches with convolutional neural networks. IEEE Signal Processing Letters, PP(99):11, 2017.
[4] A. Shaked and L. Wolf. Improved stereo matching with constant highway networks and reflective confidence learning. In IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[5]N. Mayer, E. Ilg, P. Hausser, P. Fischer, D. Cremers, A. Dosovitskiy, and T. Brox. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In IEEE Conference on Computer Vision and Pattern Recognition, pages 40404048, 2016.
[6]A. Kendall, H. Martirosyan, S. Dasgupta, P. Henry, R. Kennedy, A. Bachrach, and A. Bry. End-to-end learning of geometry and context for deep stereo regression. In IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[7]S. Gidaris and N. Komodakis. Detect, replace, refine: Deep structured prediction for pixel wise labeling. In IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[8]A. Seki and M. Pollefeys. SGM-Nets: Semi-global matching with neural networks. In IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2017
[9]J. Pang, W. Sun, J. S. Ren, C. Yang, and Q. Yan. Cascade residual learning: A two-stage convolutional neural
network for stereo matching. In International Conference
on Computer Vision Workshop, 2017.