动态场景下基于实例分割的SLAM(毕业设计动态SLAM论文学习部分)
2020.01.13
回家拜访亲戚加上陪几位老人耽误了点时间,不过我真的没想到居然有人会看我这个渣渣的更新。
动态场景下的slam:
- DS-SLAM A Semantic Visual SLAM towards dynamic environments ,代码开源,利用帧间图像的光流跟踪,进行一致性检验 。
- DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes ,代码开源,利用Mask RCNN去除动态
- Improving RGB-D SLAM in dynamic environments: A motion removal approach,基于RGB-D system 参考学习。
先这3个吧。
补充:
- Multi-object Monocular SLAM for Dynamic Environments
- Dynamic SLAM The Need For Speed
DynaSLAM论文阅读笔记
在简介部分,作者说他在单目和双目部分是使用一个CNN框架做一个像素级的语义分割,不在提供的先验动态物体范围内提取特征,而RGB-D则尝试利用多视角几何学和深度学习方法直接推测出任意动态物体并分割,移除动态和遮挡。原文如下:
In the monocular and stereo cases our proposal is to use a CNN to pixel-wise segment the a priori dynamic objects in the frames (e.g., people and cars), so that the SLAM algorithm does not extract features on them. In the RGB-D case we propose to combine multi-view geometry models and deep-learning-based algorithms for detecting dynamic objects and, after having removed them from the images, inpaint the occluded background with the correct information of the scene (Fig. 1).
动态场景SLAM相关工作(参考博客):
1、几何角度:
a、使用光流法估计基础矩阵,进行极线距离阈值判断筛选出动态点;
b、使用深度数据,将关联帧的点投影到当前帧,进行深度判别;
c、基于特征点之间相连边的距离变化信息进行判断
2、深度学习:
a、使用深度学习模型学习光流
b、深度学习产生对象mask
DynaSLAM相比较前面的工作,解决了两个问题:第一,解决了语义分割剔除动态特征时,语义掩码不准确的问题(原文:先验动态物体处于静止状态时常常被牺牲掉,@_YAO阿瑶,感谢指正,这部分DynaSLAM并没有解决);第二,解决了基于几何方法下剔除动态场景时,容易忽略小物体和初始化困难的情况。这个问题的解决主要集中在RGB-D上,利用几何和深度联合的方法,而单目和立体视觉相对就比较简单,整体框架图如下:
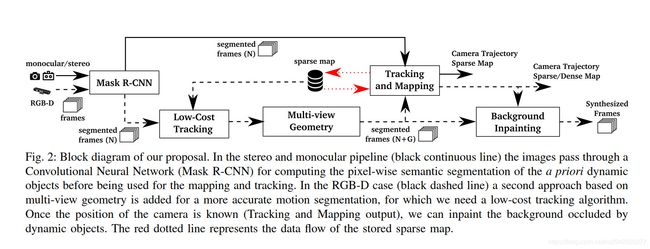
作者认为,几何方法的问题在于the main problem is that initialization is not trivial ,这里我的理解是对于小物体由于几何本身的特性而无法被检测出来(有待验证 );学习的问题在于动态物体是先验的,而静态物体移动无法检测。可以从论文中的图4看出,两者结合完美的对动态物体进行更好的检测。但是它是如何将几何法与深度学习结果融合的呢?作者是这么解释的:
if an object has been detected with both approaches, the segmentation mask should be that of the geometrical method. If an object has only been detected by the learning based method, the segmentation mask should contain this information too.
即,如果两种方法都能检测到,更信任几何方法;如果仅有学习方法检测,则直接使用学习方法。
接着是背景修补,但是比较有意思的是最后实验结果表明,在TUM数据集中,有背景修复的DynaSLAM的绝对误差其实比不上没带背景修复的,作者解释道:
the background reconstruction is strongly correlated with the camera poses. Hence, for sequences with purely rotational motion (rpy, halfsphere), the estimated camera poses have a greater error and lead to a non-accurate background reconstruction.
因此作者认为背景修补的意义在于虚拟现实贴图用,而非实际追踪定位。
另一个比较有意思的细节在于,反直觉的是ORB-SLAM(即单目版本)比ORB-SLAM2(增加立体、RGB-D版本)在动态场景下更加准确,这个是由于初始化问题造成的,毕竟单目初始化真的麻烦,而且慢,但是却意外的避免了一开始就初始化造成动态物体在开始就加入地图的困境。
作者还在KITTI室外数据集上做了一些试验,但是从结果来看基本是对半开(因为该文章主要在RGB-D上有创新,而KITTI则只有单目和立体两种),也就是说,这种纯动态掩码的效果对于去除动态干扰效果并不好,作者解释道:
An example of this would be the sequences KITTI 01 and KITTI 04, in which all vehicles that appear are moving. In the sequences in which most of the recorded cars and vehicles are parked (hence static),the absolute trajectory RMSE is usually bigger since the keypoints used for tracking are more distant and usually belong to low-texture areas (KITTI 00, KITTI 02, KITTI06).
也就是之前说的可移动的物体与移动物体的区别(movable and moving objects)
但是我觉得可能不仅仅是这个原因,因为同类型的序列也是一个好一个坏,作者并未针对这个问题深入展开,不过我觉得这个问题对我这种做室外的可能比较重要,之后可以试试。
2020.01.14
DS-SLAM论文阅读笔记
这是清华的一篇文章,而且也是基于ORB-SLAM2而改进的,但是这个是基于光流的(我很好奇ORB怎么光流):
we focus on reducing the impact of dynamic objects in vision-based SLAM by combining semantic segmentation network with optical flow method and meanwhile providing a semantic presentation of the octo-tree map
它的主要贡献在于另外开了一个语义分割的线程,联合语义分割的结果,利用移动的连续性去筛查具有动态属性的物体(我没理解错的话应该是moving);
which combining semantic segmentation with moving consistency check method to filter out dynamic portions of the scene,
此外他还结合深度信息和语义分割结果生成了一个稠密语义3D八叉树,用于去除不稳定的、更新带有语义的体素,这个可能和VR之类的有关的,不是很清楚。
相关工作分为语义SLAM和动态SLAM两部分,但是都没啥好说的,后者还主要集中在光流部分,能借鉴的比较少。
DS-SLAM的语义网络是基于SegNet [4]网络的,这个网络的简介:https://blog.csdn.net/Freeverc/article/details/83309714,这个网络不算很新,现在比较好的网络都是基于残差的那种,因此这个可以替换。
他的核心部分在于 Moving Consistency Check 这一部分,步骤为:
- 计算光流金字塔,光流金字塔是光流法的一种常见的处理方式,能够避免位移较大时丢失追踪的情况,这一部分在高博的十四讲里面有所提及。
- 若接近边界,或其像素值与以它为中心的邻域的3x3区域内的像素值差别太大,就丢弃这对匹配。
- 用RANSAC方法选择大部分内点,确定基础矩阵。
- 利用基础矩阵和参考帧的像素坐标计算极线。
- 计算当前帧的像素点到极线的距离,若大于阈值则为动态点。
可以看出,与DS-SLAM与之前的DynaSLAM有较大的差异,比较两者(自己瞎写,有错误请及时指出):
| DynaSLAM | DS-SLAM | |
|---|---|---|
| 投影维度 | 3D点投影 | 2D点投影 |
| 原理 | 投影深度进行判断 | 极线距离判断 |
| 适用范围 | 能提供深度信息的RGB-D最佳 | 可以适用于单目、立体和RGB-D |
| 精度 | 见后面 | 见后面 |
| 与语义信息结合方法 | 更信任几何信息,语义做补充 | 以语义作为基准,在语义结果上判断 |
关于语义和SLAM追踪结合的部分,作者说:
If there are certain number of dynamic points produced by moving consistency check fall in the contours of a segmented object,then this object is determined to be moving.
如果我没有理解错的话应该是在语义分割的基础上进行连续性检查,但是后面作者又说:
During the waiting period, moving consistency check could be performed.
这个waiting是指tracking线程,所以也就是说其实本质上是同时进行连续性检查和语义分割,但是不具有连续性的部分只有在语义分割内被标记过movable时,才会被剔除动态特征点。它本质上丢失了DynaSLAM提出的那种静态物体被移动,或者没有先验知识的动态物体移动的情况。但是我个人认为这个对室外环境影响不大,除非是超长时间的那种SLAM。
关于语义与地图结合基本就是贴个标签,没啥,唯一有点意思的是,为了解决多个物体在语义地图上重叠的问题,作者引用了优势对数记分法,但是个人觉得没什么必要,你把语义分割换成实例分割不就好了吗?所以直接跳过。
突然想到一个问题,对于动态而言,如果一个人走走停停,是不是会有较大的影响?尤其在占图面积较大的时候。
实验结果它并没有室外的数据集,只有室内的,所以只能和DynaSLAM比一下TUM数据集:
| ATE | ORB-SLAM(median) | DynaSLAM(median) | DS-SLAM(median) |
|---|---|---|---|
| w_halfsphere | 0.351/0.3964 | 0.025 | 0.0222 |
| w_xyz | 0.459/0.5857 | 0.015 | 0.0151 |
| w_rgy | 0.662/0.7059 | 0.035 | 0.2835 |
| w_static | 0.090/0.3087 | 0.006 | 0.0067 |
看起来相差不大。
2020.01.15
Improving RGB-D SLAM in dynamic environments: A motion removal approach论文阅读笔记:
这是个基于RGB-D SLAM系统的关于RGB-D的SLAM,主要贡献有:动态去除,使用向量化的深度图辅助运动分割;emmm好像就没了,感觉有点水啊。
相关工作主要提了一下动态去除的工作,没什么注意的;问题表述解释了为什么动态物体会导致误差,还画了一张图,列了一些不明觉厉的公式证明,虽然没什么必要,但是写论文拿来装样子必是极好的,不过我再看了一下论文的时间,释然了,这个文章是2016年收录的,比那两个2018年的要早一点,可能当时这个方向不太流行?而且从整个框架来看和主流的是有着一定的区别:
整个处理的框架分为三部分:
- 基于 ego-motion compensated image differencing 方法检测运动物体(输入上一帧和当前帧的RGB图);这里需要指出的是,尽管题目说的是RGB-D,但是在该部分作者并没有用到深度信息,作者解释道第一2D信息足够表示,第二ICP算法明显慢于2D的算法,这部分就是我们可以借鉴的核心地方。
- 使用滤波器追踪运动以加强运动检测(输入当前帧RGB图,本质上就是tracking),追踪同样用的是2D信息而不是3D信息。
- 使用 Maximum-a-posterior (MAP) estimator 在向量化的深度图片上决定前景物体(输入深度图片)
作者指出:
It should be noted that what we track in our approach are motion patches but not moving objects. Our approach is different from most tracking techniques[34] which build models for moving objects and track the built models.
也就是追踪的其实是patches;并且他的分割部分是放在tracking后的,串行而不是另开线程并行运行,其速度可能会不是很理想。此外,对于动态物体占据主要位置时候,会直接导致追踪定位偏离;场景内也必须要有平面(因为利用了单应阵);对于停止运动的物体效果也很差……
所以基本重点就在第一部分这里,他的思路就是用ego-motion代替,假设相机不动,然后用一个2D的变化矩阵代替ego-motion,然后投影,划定区域两帧相减,提取前景……怎么说,简单粗暴。原文表述如下:
Our idea is to temporarily stabilize the camera with ego-motion compensation so that the frame differencing is able to work. We use 2-D perspective transformation matrices to represent the ego-motions. We warp the last frame with the perspective matrix and subtract the current frame with the warped frame. Motions are roughly indicated by the frame differencing results.
论文里图3画的很清楚:
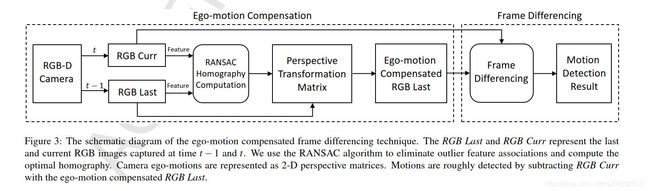
后面是滤波器,emm,跳了,至少现在用不到,而且扫了一下貌似没啥创新点;
实验结果来看,基本是比不过后面(DS-SLAM 和 DynaSLAM)的那两个的。
ok,基本的论文思路已经理的差不多了,虽然才看了3篇,但是这个方向的论文的确不是很多,接下来准备看代码。
2020.02.22-23:补充
老师给我发了两篇arxiv的文章,2020.02.10的,很新。
第一篇叫做:Multi-object Monocular SLAM for Dynamic Environments
从摘要和简介可以看出,该文章的主要工作是:建立一个多物体追踪的SLAM系统、利用SLAM管线和地标等解决单目三角化中的尺度不确定性问题、建立多位姿优化方程这三个方面,并声称该文章 is the first practical monocular multi-body SLAM system to perform dynamic multi-object and ego localization in a unified framework in metric scale.
这篇文章提醒了我一个非常重要的问题,即关于多物体追踪时单目如何统一尺度,说实话之前是完全没有想到这个问题,和老师交流了一下,认为还是要依靠先验知识,比如车辆的宽度等来实际确定。尽管这一方法极为不精确,但是误差也不会太大。先按这个来做,有好方法再说。
总体结构图如下:
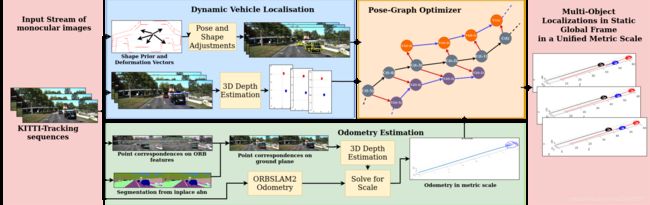
相关工作:这里的相关工作很多是和多物体追踪有关的,可以标记学习一下,之前还真没有碰过相关领域的文章。
标记以下几篇文章:
- Kundu et al. [7] proposed 。对动态物体分配运动轨迹
- Later Namdev et al. [12] 。提出对车辆的运动进行建模分析
- Ranftl et al. [19] 。定义动态物体和环境的支持先验
- Reddy et al. [25] and Li et al. [26] 。双目相机
基本流程:
- 图片序列进入pipeline
- 利用地面平面的点确定3D点的深度信息
- 拟合每个车辆的形状先验
- ORB-SLAM2视觉里程计
- 带入优化公式
- 在测量尺度下生成多体定位
在第2步中,作者假定相机处于恒定高度,利用【29】S. Song and M. Chandraker, “Joint sfm and detection cues formonocular 3d localization in road scenes,” in CVPR, 2015.这篇文章的公式确定道路平面上的3D点深度,再在ORB-SLAM中使相邻两帧在道路平面上的点与未定尺度的特征点重投影误差最小,从而解决了尺度问题。

利用投影关系:推得:
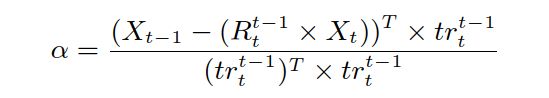
比较迷惑的是它的物体定位方面,它主要参考【30】 J. K. Murthy, S. Sharma, and K. M. Krishna, “Shape priors for real-time monocular object localization in dynamic environments,” in IROS,2017.这篇文章。形状先验由K=32个关键点(3D)组成,能够区分汽车和小货车。关键点由CNN网络生成的向量为平均向量,图片中的车辆向量为基础向量。则有先验向量:
![]()
沈老师解释:实质上就是把一个形状分解成平均形状加上一组基的线性组合形式,比如人脸五官轮廓大致分布都相似,但是人与人之间肯定有细节的不同。因此你可以收集比如说10000个人脸,算他们的平均人脸五官轮廓形状作为平均值。要拟合每个特定的人脸只要在这个平均值上作一个扰动,扰动部分可以由一组基的线性组合组成。平均人脸轮廓就是mean shape,基就是basis vector。这组基也是从10000个人脸学习出来的。这样做的好处是原来你要描述汽车轮廓需要记录轮廓线上所有的点,可能要几千个,而你用上面的方法之需要记录线性组合的系数即可(mean shape和basis vector对于不同的汽车都是一样的),一般系数只需要几十个数字就可以了。容易优化也节约空间。
优化部分:相当于将动态物体、静态物体的位姿一同进行优化,计算他们的二元边的累计误差,详见图3和公式推导。值得注意的是,由于采用了形状先验,因此获得的车辆的是一个位姿(齐次5维)而非简单的一组三维坐标,极大的方便了优化和计算。而对于一组三维点的处理,我有一些思路,写在了第5部分。
剩下的信息矩阵约束,也就是Confidence Parameterization部分,说实话没看懂,有空还得麻烦一下老师。唯一看懂的就是后面说在近距离时,基于地面特征测深度准确性不如形状先验确定定位,而在远处相反。
最后的图画的很漂亮,很好奇它是怎么做出来的。
2020.02.25-26:补充
论文:Dynamic SLAM: The Need For Speed
这篇文章发布日期更新,2020.02.20。粗看起来和我们想要的效果很像。
该文章主要解决了两个问题:1. 不在需要多物体追踪所需要的3D模型;2. 标注除了运动刚体的速度。
主要创新点为:
a novel pose change representation used to model the motion of a collection of points pertaining to a given rigid body and the integration of this model into a SLAM optimisation framework
之所以把作者原话放上来是因为实在不知道:pose change representation是什么东西,或许后面会有解释
据作者所说该文章也有一个第一:
this is the first work able to estimate, along with the camera poses, the static and dynamic structure, the full SE(3) pose change of every rigid object in the scene, extract object velocities and be demonstrable on a real-world outdoor dataset.
我倒不觉得是第一篇,我觉得昨天看的那篇文章好像也差不多,无非只针对汽车,而且没有用李代数表达罢了。
相关工作:大致看了一下,比较有吸引力的是 【26】S. Yang and S. Scherer, “Cubeslam: Monocular 3-d object slam,” IEEE Transactions on Robotics, 2019. 其他的都不太一样。
原理部分,B. Motion Model Of A Point On A Rigid Body 是该文章的重点所在。该文章详细推导出了不用刚体位姿变换也能计算动点的数学表述。公式为
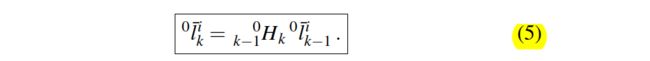
可以看出,这个公式在不需要计算在参考定坐标系{0}下刚体的运动位姿,仅仅通过计算刚体上点i在参考定坐标系{0}下的坐标就能推算出刚体在参考定坐标系{0}下的位姿变换H。
关于速度的公式为:
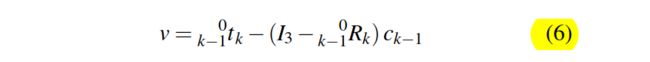
一开始没看懂,后来发现具体的推导在附录那边,但还是没看懂是为什么一个变换矩阵拆成R,t后为什么这样写。
优化公式见公式7,没啥……之后是因子图,根据运动类型,场景分为城市内部(运动复杂多变)和高速公路(运动近乎恒定),然后第二种可以简化一下因子图之类的。不过这个不会有误差吗?毕竟高速公路上也不全是恒速啊,搞不懂作者在想些什么。
订正,刚才有一句英文没看懂,查了翻译才明白恒速度模型用于处理被遮挡物体,并不是没用的。
实验:有一个数据集吸引了我Virtual KITTI Dataset,google了一下:论文是:http://xxx.itp.ac.cn/pdf/1605.06457.pdf,Virtual Worlds as Proxy for Multi-Object Tracking Analysis 。数据集网址在:https://europe.naverlabs.com/research/computer-vision/proxy-virtual-worlds-vkitti-1/。主要有实例级别的语义分割、位姿、深度信息等在KITTI数据集中没有的东西。
有一点值得注意,在该段中作者指出,光流法比描述子获得的匹配更多,也更加准确。不知道这一结论在KITTI上是否成立(KITTI的相邻帧跨越距离比较大),需要试验。
另外,该文章用的MASKRCNN,及RGBD数据。