《Linux内核分析》(二)——从一个简单Linux内核分析进程切换原理
作者:Sandy 原创作品转载请注明出处
《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000 ”
实验环境:c+Linux64位 (32位系统可能结果会不同)
依照学术诚信条款,我保证此回答为本人原创,所有回答中引用的外部材料已经做了出处标记。
源代码以及运行环境搭建请参考mykernel,其中提供了一个简单的Linux内核源代码,本文主要分析其中的三个文件:
- mypcb.h
- mymain.c
- myinterrupt.c
通过对这三个文件的分析来理解进程的切换原理。
注意,虽然在源代码中建立了4个进程并且进行循环的切换,但是为了简便分析时假定只有两个进程,编号0和1。另,在实际的Linux系统中每个进程都会有两个堆栈:用户态一个、内核态一个,但是在这个模拟的内核中每个进程只分配了一个堆栈。
首先,从mymain.c开始分析
在进程切换中最为重要的是运行栈的切换和eip(即程序计数器)的正确跳转,mymain.c中的函数my_start_kernel是最开始执行的代码,因此从这个函数开始进行分析。my_start_kernel函数首先建立起了4个进程并且进行了初始化,如分配栈等,注意在刚建立的时候只有0号进程的状态是runuable,其余的都是unrunnable。还有就是PCB结构中的threap.sp,每个进程对应一个栈,所以在这里thread.sp指向对应PCB内的char stack[KERNEL_STACK_SIZE - 1],即用这个字符数组作为运行栈,因为栈是由高地址向低地址增长,所以指向stack[KERNEL_STACK_SIZE - 1]。
接下来重点分析这段代码:
/* start process 0 by task[0] */
pid = 0;
my_current_task = &task[pid];
asm volatile(
"movl %1,%%esp\n\t" /* set task[pid].thread.sp to esp */
"pushl %1\n\t" /* push ebp */
"pushl %0\n\t" /* push task[pid].thread.ip */
"ret\n\t" /* pop task[pid].thread.ip to eip */
"popl %%ebp\n\t"
:
: "c" (task[pid].thread.ip),"d" (task[pid].thread.sp) /* input c or d mean %ecx/%edx*/
);这段内嵌汇编代码的功能是完成对0号进程的启动,其运行时的栈的情况如下:
开始之前的栈的情况:
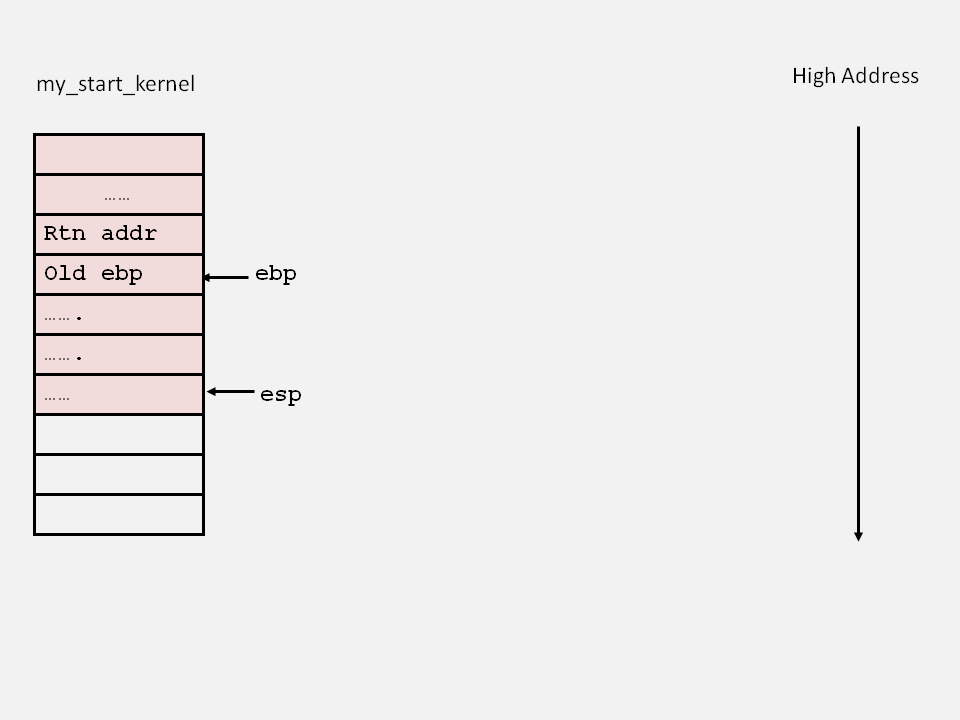
"movl %1,%%esp\n\t" /* set task[pid].thread.sp to esp */本条指令把0号进程当前的栈顶地址放入esp,因为初始化的时候task[0].thread.sp指向的是stack[KERNEL_STACK_SIZE-1],所以执行完这条指令之后esp指向task[0]的堆栈的栈顶处,如下图:

"pushl %1\n\t" /* push ebp */把task[0]的sp压入栈,栈的示意图如下:

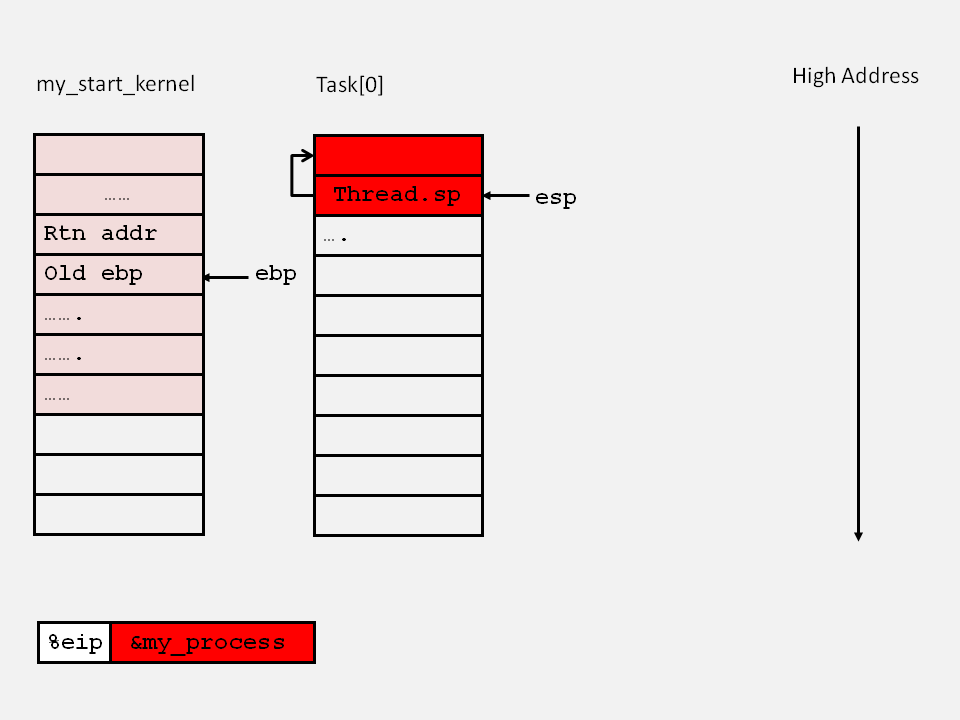
"pushl %0\n\t" /* push task[pid].thread.ip */把0号进程的ip,即my_process()函数的入口地址入栈,此时栈内情况如下图:

"ret\n\t" /* pop task[pid].thread.ip to eip */从栈中弹出刚刚放入的my_process()函数入口地址赋给eip,开始运行0号进程
my_process()在执行时将会判断是否需要进行进程切换,由于我们假设内核中只有0和1两个进程,我们假定切换条件已经满足,在此直接分析从0号进程切换到1号进程的情况。
由于当前1号进程的pid[1].state是 “-1”(unrunnable),所以将会执行my_schedule()函数的else分支的内容。
my_interrupt.c文件的my_schedule()函数的else分支的内容如下:
else
{
next->state = 0;
my_current_task = next;
printk(KERN_NOTICE "switch from %d process to %d process\n \
>>>process %d running!!!<<<\n\n\n",prev->pid,next->pid,next->pid);
/* switch to new process */
asm volatile(
"pushl %%ebp\n\t" /* save ebp */
"movl %%esp,%0\n\t" /* save esp */
"movl %2,%%esp\n\t" /* restore esp */
"movl %2,%%ebp\n\t" /* restore ebp */
"movl $1f,%1\n\t" /* save eip */
"pushl %3\n\t"
"ret\n\t" /* restore eip */
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
}在此重点分析其中内嵌的汇编代码。由于在从函数my_start_kernel()切换到函数my_process()的时候会有保存现场的动作,函数my_process()调用函数my_schedule()也会保存现场,所以在上述代码执行前的栈的情况应该是:
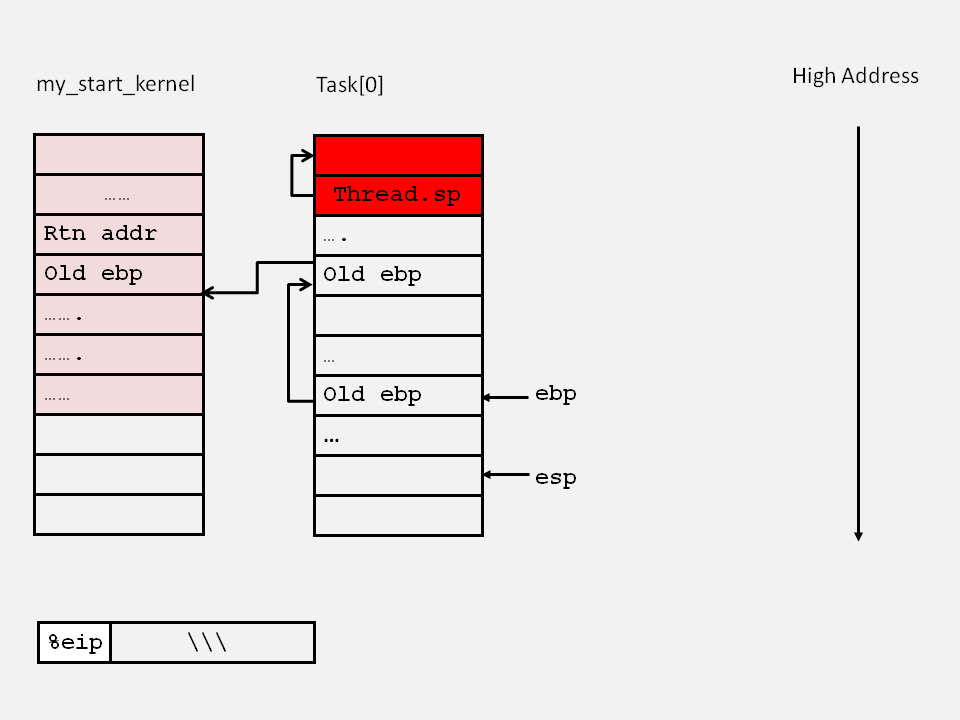
"pushl %%ebp\n\t" /* save ebp */
"movl %%esp,%0\n\t" /* save esp */保存0号进程的运行现场,即首先把0号进程的当前的栈底保存在栈中,然后把当前esp的值保存在0号进程的thread.sp中,这些现场值在切回到0号进程的时候是可以复原的,此时的栈的情况:

"movl %2,%%esp\n\t" /* restore esp */
"movl %2,%%ebp\n\t" /* restore ebp */开始进行栈切换,即从task[0].stack,切换到task[1].stack,此时的栈的情况:

"movl $1f,%1\n\t" /* save eip */这里的$1f是一个有特殊意义的数字,上述这条代码的功能是当下一次进程切换回0号进程时,将会从这里继续执行。
"pushl %3\n\t"把1号进程的进程入口地址(这里因为是1号进程第一次运行,所以就是my_process()函数的入口地址,若果不是第一次运行,由于执行过上一条代码”movl $1f,%1\n\t”那么进程1将会按照被切换掉的时候的代码继续执行下去)入栈。此时栈中情况如图:

"ret\n\t" /* restore eip */从当前栈task[1].stack中弹出刚刚送入的1号进程的入口地址,即执行my_process()函数,启动1号进程,与0号进程的启动类似,接下来就是判断是否需要进程切换。在此同样假设进程切换的条件都已经满足,接下来分析从1号进程切换到0号进程的过程。
首先,经过了一系列的函数调用,1号进程的栈已经发生了变化,示意图如下:

接下来开始分析从1号进程切换回0号进程的的流程
由于0号进程之前运行过,所以其状态是runnable,则调度过程中将进入my_schedule()方法的if分支执行,即执行如下代码:
if(next->state == 0)/* -1 unrunnable, 0 runnable, >0 stopped */
{//save current scene
/* switch to next process */
asm volatile(
"pushl %%ebp\n\t" /* save ebp */
"movl %%esp,%0\n\t" /* save esp */
"movl %2,%%esp\n\t" /* restore esp */
"movl $1f,%1\n\t" /* save eip */
"pushl %3\n\t"
"ret\n\t" /* restore eip */
"1:\t" /* next process start here */
"popl %%ebp\n\t"
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
my_current_task = next;//switch to the next task
printk(KERN_NOTICE "switch from %d process to %d process\n>>>process %d running!!!<<<\n\n",prev->pid,next->pid,next->pid);
}主要分析嵌入的汇编代码
"pushl %%ebp\n\t" /* save ebp */
"movl %%esp,%0\n\t" /* save esp */实现1号进程的运行栈环境保存,具体做法是把当前ebp入栈,然后把栈顶指针esp存入1号进程的task[1].thread.sp,执行后的栈情况如图:
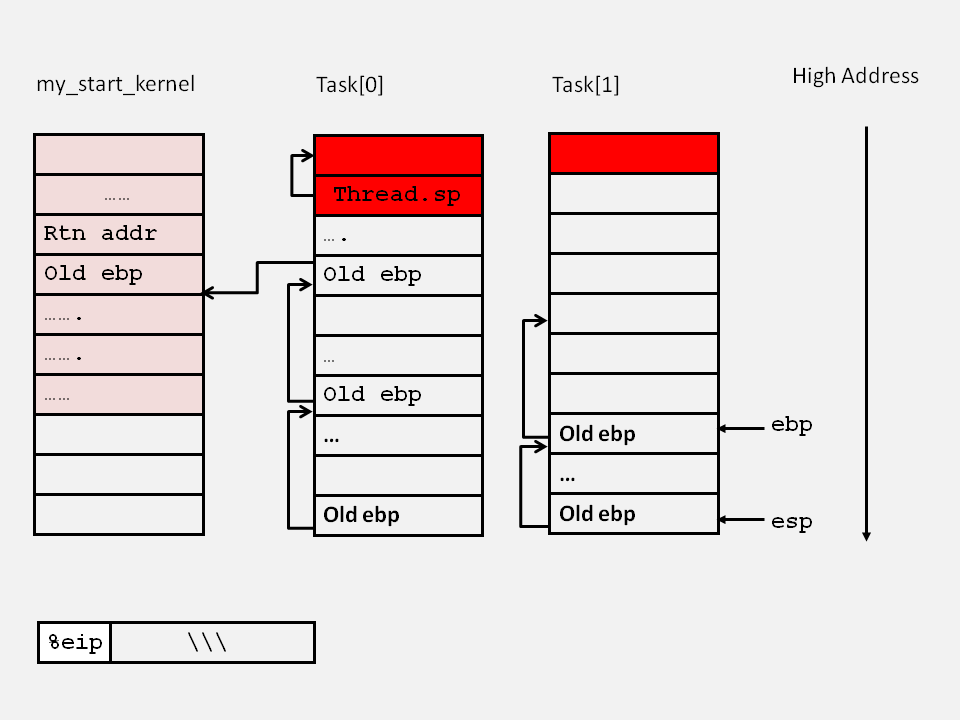
"movl %2,%%esp\n\t" /* restore esp */此条汇编语句执行后,esp所指的栈已经改变,即由1号进程切换到0号进程,把进程0的thread.sp的值赋给esp,由于在从进程0切换到进程1的时候保存过thread.sp的值,所以此时的栈如图:

"movl $1f,%1\n\t" /* save eip */
"pushl %3\n\t"这两条代码与之前切换时实现相同的功能,都是为下一步的切换做的准备,之后的栈如图:

"ret\n\t" /* restore eip */这是由1号进程,即当前进程调用的my_schedule()将执行最后一条指令,其后的语句将在下次进行进程切换,切换回1号进程时继续执行。 此时栈情况如图:

此时eip和esp都已经切换回了由进程0切换到进程1最后时刻的值,当eip继续去指令时,得到的将是0号进程上一次被切换掉时的指令的下一条指令,如下:
/* start process 0 by task[0] */
pid = 0;
my_current_task = &task[pid];
asm volatile(
"movl %1,%%esp\n\t" /* set task[pid].thread.sp to esp */
"pushl %1\n\t" /* push ebp */
"pushl %0\n\t" /* push task[pid].thread.ip */
"ret\n\t" /* 进程0在这里被切换走 */
"popl %%ebp\n\t" /* 接着应该执行这条指令 */
:
: "c" (task[pid].thread.ip),"d" (task[pid].thread.sp) /* input c or d mean %ecx/%edx*/
);也就是说接下来要执行的指令是:
"popl %%ebp\n\t"之后的栈的情况如图:

在这之后,0号进程将顺着执行流,完成对my_schedule()的调用,并且返回0号进程的my_process(),然后就是在进程0与进程1之间不断的切换。
参考文献:
https://github.com/mengning/mykernel/blob/master/mymain.c
https://github.com/ExiaHan/linuxKernelStudy/blob/master/secondWeekend/processSwitch.md