卡尔曼最优预测以及最优滤波方程的相关推导--最优滤波篇
上一篇帮大家回忆了相关数学基础,介绍了相关问题背景以及最优预测方程的推导,本篇将开启卡尔曼最优滤波方程的推导。同时,在本篇的最后会给出两个详细的实际应用的例子帮助大家理解应用卡尔曼最优滤波。
一、问题的提法
对于线性离散系统,其状态空间描述为:
![]()
在最优滤波篇中,我们的基本假设跟前面的最优预测的部分相同。因此我们可以把问题描述为:在给出观测序列![]() 的条件下,要求找出
的条件下,要求找出![]() 的线性最优估计
的线性最优估计![]() ,使得估计值
,使得估计值![]() 与
与![]() 之间的误差:
之间的误差:![]() 的方差最小,同时要求估计值
的方差最小,同时要求估计值![]() 是观测序列
是观测序列![]() 的线性函数,且估计是无偏的,即
的线性函数,且估计是无偏的,即![]()
二、线性离散系统的卡尔曼最优滤波方程
通常在推导卡尔曼最优滤波方程时,我们同样先忽略控制输入信号的作用,即认为输入为0,这样我们可以得到系统的状态空间描述为:
![]()
在获取到观测序列![]() 后,假定我们已经找到状态
后,假定我们已经找到状态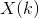 的最优滤波估计
的最优滤波估计![]() ,同样在
,同样在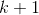 时刻,在还未获取到观测值
时刻,在还未获取到观测值![]() 的情况下,我们可以先得到一步最优估计
的情况下,我们可以先得到一步最优估计![]() ,由于
,由于![]() 为零均值的白噪声序列,其最优估计为
为零均值的白噪声序列,其最优估计为 ,因此:
,因此:
![]()
同样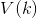 也是零均值的白噪声序列,我们可以得到观测值
也是零均值的白噪声序列,我们可以得到观测值![]() 的预测值:
的预测值:
![]()
在我们获取到观测值![]() 之后,跟在最优预测里面一样,我们来讨论一下观测值
之后,跟在最优预测里面一样,我们来讨论一下观测值![]() 以及其预测值
以及其预测值![]() 之间的误差,以期用于修正对
之间的误差,以期用于修正对![]() 的预测值
的预测值![]() 从而得到
从而得到![]() :
:
![]()
![]()
![]()
式中的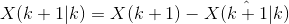 是状态
是状态![]() 的预测估计误差。不难看出,误差主要由
的预测估计误差。不难看出,误差主要由![]() 以及
以及![]() 的观测误差项
的观测误差项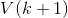 构成。一般来讲
构成。一般来讲![]() 的维数与
的维数与![]() 的维数不同,因而也不能直接使用
的维数不同,因而也不能直接使用![]() 来修正
来修正![]() 。同样,由于采用的是线性最小方差估计,因此跟最优预测一样,我们使用加权的方法来修正,同样引入一个待定的最优滤波增益矩阵
。同样,由于采用的是线性最小方差估计,因此跟最优预测一样,我们使用加权的方法来修正,同样引入一个待定的最优滤波增益矩阵![]() ,此时我们可以获得
,此时我们可以获得![]() 的线性最小方差估计
的线性最小方差估计![]() :
:
![]()
也就是:
![]()
也可以写为:
![]()
下面我们来求最优增益滤波矩阵![]() 。由正交定理,
。由正交定理,![]() 的滤波估计误差:
的滤波估计误差:
![]()
![]()
![]()
应与观测值![]() 正交,也就是:
正交,也就是:
![]()
即:
![]()
观察上式不难看出,右侧第2、4、5项均为0,令:
![]()
为最优预测误差方差阵。则上式可化简为:
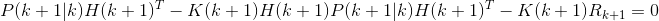
由此我们可以计算出最优滤波增益矩阵:
![]()
由于引入了新的最优预测误差方差阵![]() ,下面我们来计算
,下面我们来计算![]() 。
。
由:
![]()
我们可以得到:
又:
观察上式不难发现第2、3项为0,因此上式可以化简为:
![]()
上式中![]() 为最优滤波误差方差阵,下面我们来计算其表达式。由定义:
为最优滤波误差方差阵,下面我们来计算其表达式。由定义:
观察上式,不难看出第3、6、7、8项均为0,即可进一步化简为:
![]()

![]()
![]()
将式![]() 代入上式,由此得到:
代入上式,由此得到:
方程![]() 即构成了卡尔曼最优滤波方程组,将它们写到一起就是:
即构成了卡尔曼最优滤波方程组,将它们写到一起就是:
(1)最优预测估计方程:
![]()
(2)最优滤波估计方程:
![]()
(3)最优滤波增益矩阵方程:
![]()
(4)最优预测估计误差方差阵方程:
![]()
(5)最优滤波估计误差方差阵方程:
当然,很多时候我们经常看到的是另一种形式的![]() ,由之前的推导可知:
,由之前的推导可知:
![]()
![]()
式中的 为单位阵。
为单位阵。
实际系统中,很多时候系统的输入并不为0,也就是![]() ,则仅需将最优预测估计方程修改为:
,则仅需将最优预测估计方程修改为:
![]()
而其他方程无需变化,具体推导过程类似。
此外,五组方程也经常写为:
![]()
![]()
![]()
![]()
![]()
三、线性离散系统的卡尔曼最优滤波的算法实现
(1)将上一次的最优滤波估计值![]() 代入最优预测估计方程计算出一步最优预测
代入最优预测估计方程计算出一步最优预测![]() 。
。
(2)根据上一次的最优滤波误差方差阵![]() 代入最优预测估计误差方差阵方程计算出
代入最优预测估计误差方差阵方程计算出![]() 。
。
(3)由上一步计算出的![]() ,代入最优滤波增益矩阵方程计算出
,代入最优滤波增益矩阵方程计算出![]() 。
。
(4)在获取到新的观测值![]() 后,用上一步得到的
后,用上一步得到的![]() 分别代入最优滤波估计方程,得到最优滤波估计值
分别代入最优滤波估计方程,得到最优滤波估计值![]()
(5)最后由![]() 代入最优滤波估计误差方差阵,更新滤波估计误差方差阵以便于下一次迭代。
代入最优滤波估计误差方差阵,更新滤波估计误差方差阵以便于下一次迭代。
四、举例实现卡尔曼最优滤波算法
1.在很多数模混合系统中,我们经常需要使用ADC测量模拟输出以便下一步的数字处理。但是实际模拟系统中,各放大器、电源等均存在噪声,因此反映在输出的模拟信号中也存在大量的随机噪声,同时ADC采集的时候也会存在测量噪声,且这两种噪声一般都相互独立,且绝大部分噪声均服从均值为0的高斯分布,因此满足卡尔曼滤波的基本假设条件,可以使用卡尔曼滤波获得最优估计值。下面我们以一维卡尔曼滤波为例,具体实现一下卡尔曼滤波算法。
首先对系统进行建模,对于一个采样系统来说,我们可以假定系统没有输入,在很短的时间内系统的状态几乎不变但是噪声每时每刻都存在,且观测值就是实际ADC的输出值,但是夹带着观测噪声,也就是:
![]()
因此:
系统矩阵![]()
输入矩阵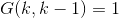
输入向量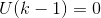
系统噪声![]() 的方差为
的方差为![]() 且恒定,
且恒定,![]()
输出矩阵![]()
观测噪声的方差为![]() 且恒定。
且恒定。
接下来我们用C代码来一步一步写出一维的卡尔曼滤波算法。首先声明,这里给出的算法仅仅是演示用,既不高效也不节省空间,仅仅是为了将算法步骤说清楚,不涉及优化的内容,若读者有兴趣可以自行进行算法优化。
先给出所需的数据结构:
typedef struct
{
float Q;
float R;
float P_K_1[1];
float P_K[1];
float K;
float state_vector[1];
float optimal_state_vector[1];
float input_vector[1];
float obsered_vector[1];
}kalman_filter_1d_t;结构体中:
Q为系统噪声的方差,需根据实际系统参数确定
R为测量噪声的方差,需根据ADC相关参数确定
P_K_1[1]也就是方程里面的![]() ,即最优预测估计误差方差阵,这里为一个
,即最优预测估计误差方差阵,这里为一个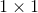 矩阵,也就是一个一维变量
矩阵,也就是一个一维变量
P_K[1]也就是方程里面的![]() ,即最优滤波估计误差方差阵
,即最优滤波估计误差方差阵
K为最优滤波增益矩阵,这里也是一维的变量
state_vector为状态向量,同时存储一步最优预测值
optimal_state_vector为当前时刻最优滤波估计值
input_vector为系统输入向量
obsered_vector为系统观测向量
接下来是相关定义以及初始化,在此不再赘述,假定代码中的Q,R为已知的。
kalman_filter_1d_t filter =
{
.Q = Q,
.R = R,
.P_K_1[0] = {0.0f},
.P_K[0] = {0.0f},
.K = 0.0f,
.state_vector[0] = {0.0f},
.optimal_state_vector[0] = {0.0f},
.input_vector[0] = {0.0f},
.observed_vector[0] = {0.0f}
};
下面我们来实现算法:
1)根据最优预测估计方程以及存储在结构体中的上一时刻的最优滤波估计值optimal_state_vector计算当前时刻的一步最优预测并存储到state_vector中,由于![]() 以及即:
以及即:
filter.state_vector[0] = filter.optimal_state_vector[0] + filter.input_vector[0];2)根据最优预测估计误差方差阵方程以及上一时刻的最优滤波误差方差阵P_K计算当前时刻的最优预测估计误差方差阵P_K_1,且![]() 以及
以及![]() ,则:
,则:
filter.P_K_1 = filter.P_K + filter.Q;3)根据最优滤波增益矩阵方程以及在上一步中获得的最优预测估计误差方差阵P_K_1来计算当前时刻最优滤波增益矩阵K。本来方程中涉及到矩阵求逆运算(这里其实是一个很大的问题,但是不在本文的讨论的范围之内,后续有空可以细说一下),但是这里仅仅是一个矩阵,因此求逆变得非常容易:
filter.K = filter.P_K_1 / (filter.P_K_1 + filter.R);4)假设我们已经获取到当前时刻的观测值为adc_value,则根据最优滤波估计方程以及上一步得出的最优滤波增益矩阵K计算出当前时刻的最优滤波估计值optimal_state_vector:
filter.observed_vector[0] = adc_value;
filter.optimal_state_vector[0] = filter.state_vector[0] + \
filter.K * (filter.observed_vector[0] - filter.state_vector[0]);5)最后更新当前时刻的最优滤波估计误差方差阵以便于下一次迭代,也就是:
filter.P_K = (1.0f - filter.K) * filter.P_K_1;至此完成一次迭代,完整版代码如下:
float kalman_filter_1d_calc(float adc_value)
{
filter.observed_vector[0] = adc_value;
filter.state_vector[0] = filter.optimal_state_vector[0] + filter.input_vector[0];
filter.P_K_1 = filter.P_K + filter.Q;
filter.K = filter.P_K_1 / (filter.P_K_1 + filter.R);
filter.optimal_state_vector[0] = filter.state_vector[0] + \
filter.K * (filter.observed_vector[0] - filter.state_vector[0]);
filter.P_K = (1.0f - filter.K) * filter.P_K_1;
return filter.optimal_state_vector[0];
}循环调用该函数并传入每次ADC的测量值即可不断迭代获得最优滤波估计。同时还可以输出P_K进行观察,若P_K很小接近于0,那滤波就是有效的。
2.在上一篇提到我接触卡尔曼滤波就是从调试惯性MEMS单元那儿来的,卡尔曼滤波在惯性MEMS数据融合方面也有很多应用。这里就拿笔者熟悉的MPU6050为例做介绍,其他惯性MEMS处理方法均类似。MPU6050是一颗6轴惯性单元,其中包含3轴陀螺仪跟3轴加速度计。
正如大家所熟知的,陀螺仪输出的是角速度值![]() ,想要获取角度值必须对其进行积分,也就是:
,想要获取角度值必须对其进行积分,也就是:
![]()
对其离散化之后可写成:
![]()
其短时具有很高的精度,但是随着时间的推移,积分误差会逐渐增大,并且其同时存在漂移,虽然漂移会随时间变化,但是在短时间内我们可以认为其漂移近似不变。而加速度计直接输出三个维度的加速度值,在物体处于平衡状态时其合力为0,也就是加速度和为0,且重力加速度恒定为1g,此时若能获取到三个维度的加速度值,就能反推出物体的姿态角。(单纯依靠三轴加速度计不能获取到偏航角,但是这又是另一个话题了,在此不再展开细说。)但是一旦物体离开平衡状态,也就是物体开始做非匀速直线运动,那么其就有其他方向的加速度,则单纯依靠加速度计获得的姿态角精度将极大降低,但是其不像陀螺仪一样会存在积分误差。因此可以对陀螺仪跟加速度计的数据做融合,提高精度。
下面开始对系统建模,先仅研究某一方向的姿态角。对于陀螺仪获取角度值,我们有:
![]()
式中:
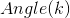 为当前时刻计算出的角度值
为当前时刻计算出的角度值
![]() 为上一时刻计算出的角度值
为上一时刻计算出的角度值
![]() 为获取到的陀螺仪输出值
为获取到的陀螺仪输出值
![]() 为上一时刻陀螺仪的漂移
为上一时刻陀螺仪的漂移
![]() 为陀螺仪系统噪声
为陀螺仪系统噪声
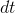 为积分时间间隔
为积分时间间隔
前面提到虽然漂移会随时间变化,但是在短时间内我们可以认为其漂移近似不变,但是混杂着噪声,因此对于漂移,我们有:
![]()
式中:
![]() 为当前时刻陀螺仪的漂移
为当前时刻陀螺仪的漂移
![]() 为上一时刻陀螺仪的漂移
为上一时刻陀螺仪的漂移
![]() 为漂移噪声
为漂移噪声
综合上述两个方程,我们可以选取姿态角跟漂移量作为系统的状态变量。系统的输入量为陀螺仪的输出值,因此将两方程合并并写成矩阵方程的形式有:
由此我们得到系统的状态方程。
式中:
![]() 为系统的状态向量,也就是
为系统的状态向量,也就是
![]() 为系统矩阵,也就是
为系统矩阵,也就是![]()
![]() 为系统的输入矩阵,也就是
为系统的输入矩阵,也就是![]()
![]() 为系统的输入向量,也就是
为系统的输入向量,也就是![]()
![]() 为陀螺仪噪声与漂移噪声矩阵,也就是
为陀螺仪噪声与漂移噪声矩阵,也就是![]()
![]() 为方程中的
为方程中的![]()
同时我们还可以从加速度计获取到姿态角度,因此我们可以将加速度计解算出的姿态角作为观测值,但是其同样存在噪声,并且不能获取到陀螺仪的漂移值,因此我们可以写出观测方程:
![]()
式中:
![]() 为系统的观测值,也就是
为系统的观测值,也就是![]()
![]() 为系统的输出矩阵,也就是
为系统的输出矩阵,也就是![]()
![]() 为系统的观测噪声
为系统的观测噪声
假定我们已知陀螺仪噪声方差![]() ,漂移噪声方差
,漂移噪声方差![]() 以及加速度计的噪声方差
以及加速度计的噪声方差![]() ,并且由于陀螺仪的积分性质,
,并且由于陀螺仪的积分性质,![]() 与
与![]() 均与时间相关,但是各噪声之间互不相关,且均服从均值为0的高斯分布,则陀螺仪噪声与漂移噪声的协方差矩阵为一个对角阵,且对角元素为各自的方差,也就是:
均与时间相关,但是各噪声之间互不相关,且均服从均值为0的高斯分布,则陀螺仪噪声与漂移噪声的协方差矩阵为一个对角阵,且对角元素为各自的方差,也就是:
![]()
而加速度计的噪声方差阵为:
![]()
易知该系统满足卡尔曼滤波的基本假设条件,接下来我们来实现卡尔曼滤波器算法。
首先给出用到的数据结构:
typedef struct
{
float dt;
float Q[2][2];
float R;
float P_K_1[2][2];
float P_K[2][2];
float K[2];
float state_vector[2];
float optimal_state_vector[2];
float input_vector[1];
float observed_vector[1];
}imu_kalman_filter_2d_t;结构体中:
dt为陀螺仪的积分时间间隔
Q[2][2]为陀螺仪噪声以及漂移噪声的协方差矩阵,也就是基本方程里面的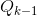
R为加速度计的噪声方差,也就是基本方程里面的![]()
P_K_1[2][2]为最优预测估计误差方差阵,也就是基本方程里的![]()
P_K[2][2]为最优滤波估计误差方差阵,也就是基本方程里面的![]()
K[2]为最优滤波增益矩阵,也就是基本方程里面的![]()
state_vector[2]存储一步最优预测估计值
optimal_state_vector[2]为当前时刻最优滤波估计值
input_vector[1]为系统的输入,也就是陀螺仪的输出值
observed_vector[1]为系统的观测值,也就是加速度计的输出值
接下来是相关定义以及初始化,在此不再赘述,假定代码中的Q0,Q1,R为已知的,CALC_PERIOD为计算周期。
void kalman_filter_init(imu_kalman_filter_2d_t * instance)
{
instance->dt = CALC_PERIOD;
instance->Q[0][0] = Q0;
instance->Q[0][1] = 0.0f;
instance->Q[1][0] = 0.0f;
instance->Q[1][1] = Q1;
instance->R = R;
instance->input_vector[0] = 0.0f;
instance->observed_vector[0] = 0.0f;
instance->state_vector[0] = 0.0f;
instance->state_vector[1] = 0.0f;
instance->optimal_state_vector[0] = 0.0f;
instance->optimal_state_vector[1] = 0.0f;
instance->K[0] = 0.0f;
instance->K[1] = 0.0f;
instance->P_K[0][0] = 0.0f;
instance->P_K[0][1] = 0.0f;
instance->P_K[1][0] = 0.0f;
instance->P_K[1][1] = 0.0f;
instance->P_K_1[0][0] = 0.0f;
instance->P_K_1[0][1] = 0.0f;
instance->P_K_1[1][0] = 0.0f;
instance->P_K_1[1][1] = 0.0f;
}下面我们来实现算法:
1)根据最优预测估计方程计算一步最优估计值,也就是方程:
![]()
在我们的系统中也就是:
代码里我们可以写成:
instance->state_vector[0] = (instance->optimal_state_vector[0] - \
instance->optimal_state_vector[1] * instance->dt) + \
instance->input_vector[0] * instance->dt;
instance->state_vector[1] = instance->optimal_state_vector[1];2)根据最优预测估计误差方差阵方程计算出![]() ,也就是方程:
,也就是方程:
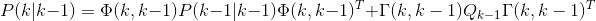
在我们系统中也就是:
将其展开并合并化简有:
写成代码也就是:
instance->P_K_1[0][0] = instance->P_K[0][0] + instance->Q[0][0] * instance->dt - \
instance->P_K[0][1] * instance->dt - instance->P_K[1][0] * instance->dt + \
instance->P_K[1][1] * instance->dt * instance->dt;
instance->P_K_1[0][1] = instance->P_K[0][1] - instance->P_K[1][1] * instance->dt + \
instance->Q[0][1] * instance->dt;
instance->P_K_1[1][0] = instance->P_K[1][0] - instance->P_K[1][1] * instance->dt + \
instance->Q[1][0] * instance->dt;
instance->P_K_1[1][1] = instance->P_K[1][1] + instance->Q[1][1] * instance->dt;注意上面代码段中Q[0][1]以及Q[1][0]均为0
3)根据最优滤波增益矩阵方程计算最优滤波增益矩阵,也就是方程:
![]()
即:
拆开并合并得到:
![]()
代码如下:
instance->K[0] = instance->P_K_1[0][0] / (instance->P_K_1[0][0] + instance->R);
instance->K[1] = instance->P_K_1[1][0] / (instance->P_K_1[0][0] + instance->R);4)根据最优滤波估计方程计算最优滤波估计值,方程为:
![\hat{X(k|k)} = \hat{X(k|k-1)} + K(k)[Z(k)-H(k)\hat{X(k|k-1)}]](http://img.e-com-net.com/image/info8/717c039ab2b5484eb368b1f216446894.gif)
即:
也就是:
代码为:
instance->optimal_state_vector[0] = instance->state_vector[0] + \
instance->K[0] * (instance->observed_vector[0] - \
instance->state_vector[0]);
instance->optimal_state_vector[1] = instance->state_vector[1] + \
instance->K[1] * (instance->observed_vector[1] - \
instance->state_vector[1]);5)最后根据最优滤波估计误差方差阵方程更新最优滤波估计误差方差阵,也就是方程:
![]()
也就是:
化简后有:
![]()
代码为:
instance->P_K[0][0] = instance->P_K_1[0][0] - instance->K[0] * instance->P_K_1[0][0];
instance->P_K[0][1] = instance->P_K_1[0][1] - instance->K[0] * instance->P_K_1[0][1];
instance->P_K[1][0] = instance->P_K_1[1][0] - instance->K[1] * instance->P_K_1[0][0];
instance->P_K[1][1] = instance->P_K_1[1][1] - instance->K[1] * instance->P_K_1[0][1];至此完成一次迭代,完整版代码如下:
float imu_kalman_filter_2d_calc(imu_kalman_filter_2d_t * instance, float observed_value, float input_value)
{
instance->observed_vector[0] = observed_value;
instance->input_vector[0] = input_value;
instance->state_vector[0] = (instance->optimal_state_vector[0] - instance->optimal_state_vector[1] * instance->dt) + \
instance->input_vector[0] * instance->dt;
instance->state_vector[1] = instance->optimal_state_vector[1];
instance->P_K_1[0][0] = instance->P_K[0][0] + instance->Q[0][0] * instance->dt - \
instance->P_K[0][1] * instance->dt - instance->P_K[1][0] * instance->dt + \
instance->P_K[1][1] * instance->dt * instance->dt;
instance->P_K_1[0][1] = instance->P_K[0][1] - instance->P_K[1][1] * instance->dt + instance->Q[0][1] * instance->dt;
instance->P_K_1[1][0] = instance->P_K[1][0] - instance->P_K[1][1] * instance->dt + instance->Q[1][0] * instance->dt;
instance->P_K_1[1][1] = instance->P_K[1][1] + instance->Q[1][1] * instance->dt;
instance->K[0] = instance->P_K_1[0][0] / (instance->P_K_1[0][0] + instance->R);
instance->K[1] = instance->P_K_1[1][0] / (instance->P_K_1[0][0] + instance->R);
instance->optimal_state_vector[0] = instance->state_vector[0] + \
instance->K[0] * (instance->observed_vector[0] - instance->state_vector[0]);
instance->optimal_state_vector[1] = instance->state_vector[1] + \
instance->K[1] * (instance->observed_vector[1] - instance->state_vector[1]);
instance->P_K[0][0] = instance->P_K_1[0][0] - instance->K[0] * instance->P_K_1[0][0];
instance->P_K[0][1] = instance->P_K_1[0][1] - instance->K[0] * instance->P_K_1[0][1];
instance->P_K[1][0] = instance->P_K_1[1][0] - instance->K[1] * instance->P_K_1[0][0];
instance->P_K[1][1] = instance->P_K_1[1][1] - instance->K[1] * instance->P_K_1[0][1];
return instance->optimal_state_vector[0];
}循环调用该函数并传入每次陀螺仪的输出值即可不断迭代获得最优滤波估计。同时还可以输出P_K进行观察,若P_K主对角元素很小接近于0,那滤波就是有效的。
最后个人在ESP32的板子(今年回家没带其他板子,凑合着试了下)上面验证了一下算法,里面包含MPU6050的驱动跟卡尔曼滤波算法,最后效果还行。
代码链接在这:
https://download.csdn.net/download/u013910954/12136477
五、总结
卡尔曼滤波器是一种线性无偏递推滤波器,其算法简单,且存储数据少,实时性很高,因而应用非常广泛。这两篇文章仅仅是对卡尔曼最优预测跟最优滤波的一种简单的推导,其实还有很多种其他推导方法,有兴趣的读者可以查阅相关书籍。
最后贴出个人认为还不错的两个讲解卡尔曼滤波以及应用的链接:
1.https://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/#comment-1010
2.http://blog.tkjelectronics.dk/2012/09/a-practical-approach-to-kalman-filter-and-how-to-implement-it/
六、一点小扩展
之前有提到,在基本方程中的最优滤波增益矩阵中,若观测方程维数不为1,则存在矩阵求逆的运算,一般来讲普通矩阵求逆是一个很麻烦的事,但是对于上三角或者下三角矩阵求逆就比较简单,并且在滤波方程里面的需要求逆的矩阵是一个正定对称矩阵,由矩阵的三角分解的相关定理,对于满秩方阵可以做LU分解为一个单位下三角矩阵与一个上三角矩阵的乘积,由此可以方便的计算出矩阵的逆,读者若有兴趣可以参考矩阵理论的相关章节。
还有一种方法是矩阵分析里面的Neumann定理,将矩阵求逆转换成矩阵级数求和的运算,但是要求矩阵的谱半径小于1且运算量较大,因此不再赘述,这里给出我们矩阵理论的相关章节的课件,有兴趣的读者可以查阅。
课件链接:
https://download.csdn.net/download/u013910954/12136595