TrueType字体文件解析和字体光栅化
本文主要记录一下这几天做的一个小Demo,它能够读取.ttf格式的字体文件,获取其中的相关数据,将得到的字体信息光栅化处理后输出到一张PNG文件中,最终输出的结果如下:


有兴趣的可以参考一下源码:
https://github.com/syddf/TTFFontRender
TTF文件解析
首先要注意ttf采用的是大端编址,即最低位的字节在最后面,而最高位的字节在最前面,如果所在的环境用的是小端编址就需要在读取时候逆转一下字节序,在C++中可以像这样读取数据:
static void InverseEudianRead(const char * source, char * target, const int per_data_size, int & offset, const int data_num = 1)
{
assert(target != NULL && source != NULL);
char * ptr = (char*)target;
for (int i = 0; i < data_num; i++)
{
for (int j = per_data_size - 1; j >= 0; j--)
{
ptr[j + i * per_data_size] = source[offset + (per_data_size - 1 - j)];
}
offset += per_data_size;
}
}
template
void TRead(char * source, T * buffer, int & offset)
{
InverseEudianRead(source, (char*)buffer, sizeof(T), offset);
}
ttf格式的字体文件包含的数据非常多,然而如果只是想要把某个汉字提取出来,其实只会用到其中的一小部分数据,下面逐一介绍一下需要解析的内容。
这里每个Table只会说一下其中会用到的几个相关数据的意义和作用,对于其他的数据可以参考MSDN的文档:https://docs.microsoft.com/zh-cn/typography/opentype/spec/avar
OffsetTable
TTF文件中的数据分成了许多块,每一块都记录了不同类型的信息,对于每一块数据,如果想要读取它,那么肯定需要知道它相对于文件起始位置的一个偏移量,然后从相应的位置开始读取,OffsetTable就记录了这样的一些信息。OffsetTable位于TTF文件的开头位置,因此可以直接读取,它的结构如下:
ULONG m_sfntVersion;
USHORT m_numTables;
USHORT m_searchRange;
USHORT m_entrySelector;
USHORT m_rangeShift;
std::unordered_map m_RecordEntries;
其中的TableRecordEntry是这样一个结构:
Tag m_Tag;
ULONG m_Checksum;
ULONG m_Offset;
ULONG m_Length;
可能有一些类型名比较陌生,它们大多都是1、2、4字节的unsigned int类型,具体的类型定义可以看我的代码中的TTF_Type.h文件。
m_numTables表示整个ttf文件中一共有多少个数据块,在m_rangeShift被读取完之后,需要依次读取m_numTables个TableRecordEntry结构,TableRecordEntry记录了每个数据块的 名称、数据块的校验和、相对于文件起始的偏移量、数据块的长度,有了这些信息,在之后需要读取某个数据块时,只需要根据数据块的名称,在OffsetTable中找到相应的TableRecordEntry,然后获得偏移量,偏移到相应位置后开始读取即可。
以我所使用的等线字体为例,它的OffsetTable读取完之后的结果如下:
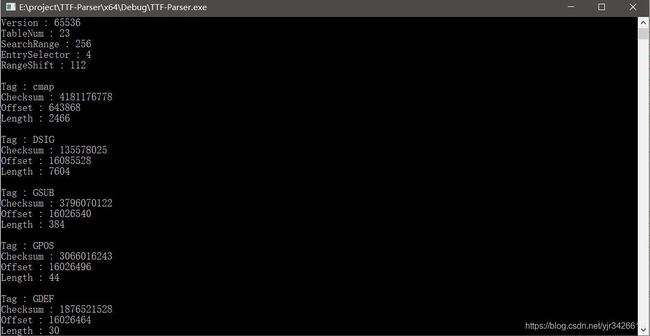
可以看到数据块的个数是一个不小的数字,但是并不需要将所有的数据块都读取出来,如果只想要绘制出字体来,只需要用到:head、maxp、cmap、loca 、glyf 这几个数据块就可以了。
HeadTable
head块的数据非常直观,数量也比较多
Fixed m_Version;
Fixed m_FontRevision;
uint32_t m_ChecksumAdjustment;
uint32_t m_MagicNumber;
uint16_t m_Flags;
uint16_t m_UnitsPerEm;
LONGDATETIME m_Created;
LONGDATETIME m_Modified;
int16_t m_xMin;
int16_t m_yMin;
int16_t m_xMax;
int16_t m_yMax;
uint16_t m_macType;
uint16_t m_lowestRecPPEM;
int16_t m_fondDirectionHint;
int16_t m_indexToLocFormat;
int16_t m_glyphDataFormat;
m_UnitsPerEm表示每个参考网格(Em-Square)中以FUnit为单位的边长,FUnit和Em与TTF字体设计有关,这里可以将它简化处理,就把它看做是我们最终输出的这个结果图像的边长,比如我读取的值是2048,那么我最终输出的PNG文件的大小就是2048*2048的。
m_indexToLocFormat会在读取LocaTable时用到,它的值如果为0表示LocaTable中读取的offset都是16位长度,如果为1表示LocaTable中读取的offset都是32位长度。
我最终采取的输出方式是让所有的字体都居中显示,即把每个字都放在PNG文件的中央,这样的方式不会用到head块中的其他任何数据,所以这里也就不再介绍了,至于每个成员的意义到底是什么,可以参考MSDN。
MaxpTable
maxp块主要记录的是一些与最大数目有关的信息:
Fixed m_Version;
uint16_t m_NumGlyphs;
uint16_t m_MaxPoints;
uint16_t m_MaxContours;
uint16_t m_MaxCompositePoints;
uint16_t m_MaxCompositeContours;
uint16_t m_MaxZones;
uint16_t m_MaxTwilightPoints;
uint16_t m_MaxStorage;
uint16_t m_MaxFunctionDefs;
uint16_t m_MaxInstructionDefs;
uint16_t m_MaxStackElements;
uint16_t m_MaxSizeOfInstructions;
uint16_t m_MaxComponentElements;
uint16_t m_MaxComponentDepth;
这么多的数据中我只用到了m_NumGlyphs,它表示一共有多少个Glyph,在ttf文件中每个字都对应一个glyph,glyph中存储了构成字的轮廓信息,是最重要的一个结构,但是要注意到有可能会有多个字对应同一个glyph,比如对于那些没有被该字体文件设计的字都会对应一个表示未知的glyph。
CMapTable、LocaTable
如果现在我们想要显示"啊",那么我们需要找到"啊"所对应的glyph结构,这可以通过CMapTable完成,CMapTable将采取一定的映射方式,将输入的文字的某一种格式的编码映射到一个标号,代表其对应的glyph的下标,得到glyph的编号后我们需要找到该glyph的相关数据存储在整个字体文件的哪个位置,这就是LocaTable的作用。因此这两个结构就是两张映射表,根据输入的文字找到对应的轮廓信息在文件中的具体位置。
CMapTable:
uint16 version;
uint16 numTables;
EncodingRecord encodingRecords[numTables];
开头是版本以及映射表的数目,需要按照顺序逐一读取每一个映射表,将它们的所有信息汇总到一个映射表上。
EncodingRecord的结构为:
uint16_t platform_id, encoding_id;
uint32_t offset;
查阅MSDN可以看到,platform_id和encoding_id决定了将会使用输入文字的哪一种编码方式,offset给出了映射表的偏移量,这里我们希望使用Unicode编码,因此我们读取platform_id=3,encoding_id=1 或者 platform_id=0,encoding_id=3的那些映射表,其他的表直接忽略掉。根据Offset跳转到相应的位置,读取相应的信息(注意每种平台和编码方式所需要读取的数据信息都是不一样的,此处细节比较多,请参看MSDN)。
LocaTable:
LocaTable就没有CMapTable那么复杂了,根据HeadTable中的m_indexToLocFormat的值来确定读取的offset的大小,根据MaxpTable中的m_NumGlyphs来确定一共要读取多少个Offset,然后按照顺序一个一个读取就可以了。
LocaTable::LocaTable(const TableRecordEntry & entry, char * source, int & offset, int glyph_number , bool isInt16 )
{
m_GlyphLocation.resize(glyph_number + 1);
offset = entry.GetOffset();
int c = 0;
if (isInt16)
{
for (int i = 0; i <= glyph_number; i++)
{
uint16_t off;
TRead(source , &off, offset);
off <<= 1;
if (off != 0)
{
c++;
}
m_GlyphLocation[i] = off;
}
}
else {
for (int i = 0; i <= glyph_number; i++)
{
TRead(source, &m_GlyphLocation[i], offset);
}
}
}
注意:LocaTable读取的Offset是每个Glyph相对于GlyphTable起始位置的偏移量,而不是相对于字体文件开头位置的偏移量。
GlyphTable
GlyphTable应该是最为重要的一个数据块了,它记录了所有的字的轮廓信息,一个Glyph是由多条轮廓线(Contour)构成的,而每个Contour则由一些二阶Bezier曲线和直线构成。
TRead(data, &m_Glyph.contour_num, offset);
TRead(data, &m_Glyph.bounding_box[0], offset);
TRead(data, &m_Glyph.bounding_box[1], offset);
TRead(data, &m_Glyph.bounding_box[2], offset);
TRead(data, &m_Glyph.bounding_box[3], offset);
一开始我们需要先读取每个Glyph所包含的contour的数目,以及Glyph中所包含的点的x、y坐标的最小值和最大值,这个极值在最终要居中显示字体的时候会用到。
contour_num如果大于0,说明这是一个简单的Glyph,所有的一切正常读取就行了,而如果它的值小于0,则说明这是一个composite glyph,它是由多个glyph复合而成,这里不介绍composite glyph的读取并且也没有在代码中实现。就我读取的等线字体来看,没有一个字用到了composite glyph,所以如果对此感兴趣就自行查阅MSDN吧。
随后需要依次读取glyph中用到的点的flag、x坐标和y坐标,
//flag
uint8_t repeat = 0;
for (int i = 0 , p_ind = 0 , c_ind = 0; i < point_nums; i++ , p_ind++)
{
if (repeat == 0)
{
uint8_t flag;
TRead(data, &flag, offset);
if (flag & 0x8) {
TRead(data, &repeat, offset);
}
glyph_flags[i].off_curve = (!(flag & 0b00000001)) != 0;
glyph_flags[i].xShort = ((flag & 0b00000010)) != 0;
glyph_flags[i].yShort = ((flag & 0b00000100)) != 0;
glyph_flags[i].repeat = ((flag & 0b00001000)) != 0;
glyph_flags[i].xDual = ((flag & 0b00010000)) != 0;
glyph_flags[i].yDual = ((flag & 0b00100000)) != 0;
if (p_ind >= (c_ind ? countour_end[c_ind] - countour_end[c_ind - 1] : countour_end[c_ind] + 1) )
{
p_ind = 0;
c_ind++;
}
countour_index_for_point[i] = c_ind;
point_index_in_countour[c_ind][p_ind] = i ;
}
else {
glyph_flags[i] = glyph_flags[i - 1];
repeat--;
}
}
std::vector point_coordinates;
point_coordinates.resize(point_nums);
// x coordinate
for (int i = 0; i < point_nums; i++)
{
if (glyph_flags[i].xDual && !glyph_flags[i].xShort)
{
point_coordinates[i].x = i > 0 ? point_coordinates[i - 1].x : 0 ;
}
else {
if (glyph_flags[i].xShort)
{
uint8_t x;
TRead(data, &x, offset);
point_coordinates[i].x = x;
if (!glyph_flags[i].xDual) {
point_coordinates[i].x *= -1;
}
}
else {
int16_t x;
TRead(data, &x, offset);
point_coordinates[i].x = x;
}
if (i) point_coordinates[i].x += point_coordinates[i - 1].x;
}
}
// y coordinate
for (int i = 0; i < point_nums; i++)
{
if (glyph_flags[i].yDual && !glyph_flags[i].yShort)
{
point_coordinates[i].y = i > 0 ? point_coordinates[i - 1].y : 0;
}
else {
if (glyph_flags[i].yShort)
{
uint8_t y;
TRead(data, &y, offset);
point_coordinates[i].y = y;
if (!glyph_flags[i].yDual) {
point_coordinates[i].y *= -1;
}
}
else {
int16_t y;
TRead(data, &y, offset);
point_coordinates[i].y = y;
}
if (i) point_coordinates[i].y += point_coordinates[i - 1].y;
}
}
最后需要依次读取每一个二阶bezier曲线和直线,它们可能用到的点的坐标已经被读取在了point_coordinates中,一个二阶bezier曲线会用到3个点,1个在曲线上的点+1个不在曲线上的控制点+1个在曲线上的点,点是否在曲线上可以通过flag获取,我们每次考虑两个下标连续的点p0,p1,并且维护一个pre_point来记录此前最后一个在曲线上的点,根据flag,看它们是否在曲线上,如果:
1.p0在曲线上,p1也在曲线上,这说明当前的这条曲线实际上是一条线段p0p1
2.p0在曲线上,p1不在曲线上,这个时候需要往后考虑第三个点p2,如果p2在曲线上那么就可以直接得到一条bezier曲线,而如果p2不在曲线上,这个时候我们就要想办法得到一个在曲线上的点,方法是取p1和p2的中点,认为这个中点是在二阶bezier曲线上
3.p0不在曲线上,p1在曲线上,这个时候就需要让pre_point作为二阶bezier曲线的第一个点,而p0作为bezier曲线的第二个点,p1作为bezier曲线的第三个点
4.p0不在曲线上,p1不在曲线上,这个时候就需要让pre_point作为二阶bezier曲线的第一个点,而p0作为bezier曲线的第二个点,p1不在曲线上,因此要让取p0和p1的中点来代表在曲线上的第三个点。
//find the first point in the curve
if (first_point_flag.off_curve)
{
uint16_t last_ind = point_index_in_countour[j][point_num - 1];
GlyphFlag last_point_flag = glyph_flags[last_ind];
if (last_point_flag.off_curve)
{
pre_point.x = (point_coordinates[first_point_ind].x + point_coordinates[last_ind].x) / 2.0f;
pre_point.y = (point_coordinates[first_point_ind].y + point_coordinates[last_ind].y) / 2.0f;
}
else {
pre_point.x = point_coordinates[last_ind].x;
pre_point.y = point_coordinates[last_ind].y;
}
}
for (int k = 0; k < point_num; k++)
{
uint16_t p0_ind = point_index_in_countour[j][k % point_num];
uint16_t p1_ind = point_index_in_countour[j][(k + 1) % point_num];
GlyphFlag p0_flag = glyph_flags[p0_ind];
GlyphFlag p1_flag = glyph_flags[p1_ind];
Point_i p0 = point_coordinates[p0_ind];
Point_i p1 = point_coordinates[p1_ind];
Curve curve;
if (p0_flag.off_curve)
{
curve.p0.x = pre_point.x;
curve.p0.y = pre_point.y;
curve.p1.x = p0.x;
curve.p1.y = p0.y;
if (p1_flag.off_curve)
{
curve.p2.x = (p0.x + p1.x) / 2.0f;
curve.p2.y = (p0.y + p1.y) / 2.0f;
pre_point = curve.p2;
}
else {
curve.p2.x = p1.x;
curve.p2.y = p1.y;
}
}
else if( !p1_flag.off_curve )
{
curve.p0.x = p0.x;
curve.p0.y = p0.y;
curve.p1.x = p1.x;
curve.p1.y = p1.y;
curve.p2.x = glyph_center.x + 0.5f;
curve.p2.y = glyph_center.y + 0.5f;
pre_point = curve.p0;
}
else {
int p2_ind = point_index_in_countour[j][(k + 2) % point_num];
GlyphFlag p2_flag = glyph_flags[p2_ind];
Point_i p2 = point_coordinates[p2_ind];
if (p2_flag.off_curve)
{
curve.p0.x = p0.x;
curve.p0.y = p0.y;
curve.p1.x = p1.x;
curve.p1.y = p1.y;
curve.p2.x = (p1.x + p2.x) / 2.0f;
curve.p2.y = (p1.y + p2.y) / 2.0f;
pre_point = curve.p2;
}
else {
curve.p0.x = p0.x;
curve.p0.y = p0.y;
curve.p1.x = p1.x;
curve.p1.y = p1.y;
curve.p2.x = p2.x;
curve.p2.y = p2.y;
pre_point = curve.p0;
}
至此已经读取了所有需要的信息,如果需要实现更加精细和复杂的绘制效果,肯定需要理解并读取其他相关数据,有兴趣的读者可以自行深入研究。
字体的光栅化
现在我们可以通过GlyphTable获取某个文字的一系列二阶bezier曲线和直线段,bezier曲线的光栅化非常容易,直接根据其定义计算每个插值点的坐标即可,而对于直线段,我们可以采用Bresenham算法来做光栅化处理。这两步完成后,我们可以得到字体的轮廓线:
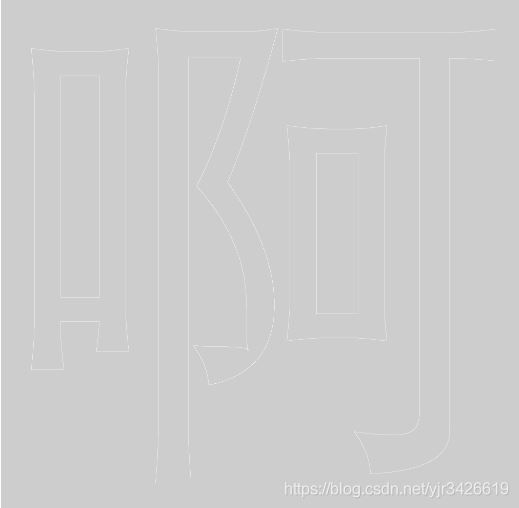
比较困难的一步是填充,关于填充有用于填充多边形的扫描线算法以及可以填充任意封闭区域的种子填充算法。扫描线算法在这里不是很适合,因为我们的轮廓不仅有直线还有bezier曲线,不是很好确定扫描线与bezier曲线的交点(当然似乎有用直线逼近bezier曲线这样的一种做法)
我采用的是种子填充算法,即选择在轮廓线内部的一个点然后向四周逐渐扩散填充,但是如何找到这样一个在轮廓线内部的点?很容易想到,如果由某点朝某个方向发出一条射线,如果射线与轮廓线的交点的个数是奇数的话,说明该点在轮廓线的内部,否则在外部。但是要注意到轮廓线会存在连续的点的问题

比如像这种,黑色的点代表轮廓点,图中的红色点按照上述判定准则会被认为不在轮廓内部,因为它左侧的轮廓点是偶数个,但是事实上它应该是在轮廓内部的,因此在判定的时候需要注意,所有连续的点应该只被当作一个点来统计。
这一部分的代码都比较直观,可以参考代码中的TTFRaster类。
总的来说,对于TrueType文件的解析还是远远不够的,目前所做到的也只是将轮廓提取出来并显示而已,但如果要更近一步,例如修改某个字并写回到文件中,那么肯定需要对TTF文件有更高层次的认识。
\希望这篇文章对于想要提取并绘制字体的朋友有所帮助。