非刚性人脸跟踪(二)
上一篇博文讲了如何在人脸图像中获得面部特征。这篇博文主要介绍面部的几何模型。
在人脸跟踪系统中,几何形状是指在人脸图像上预先定义的一组点的空间结构,这组点与真实人脸上某些几何形状(如眼角、鼻尖和眉毛边缘)保持一一对应关系。
面部几何参数变化通常有两个因素组成:全局(刚性)变化和局部(非刚性)形变。全局变化考虑人脸在图像中的整体位置,允许人脸随意变化。局部形变考虑的是不同人面部形状以及同一个人面部表情的差异。换句话说,全局变化是二维坐标的常规处理,可用于任意类型的对象。局部形变针对的是具体对象,需要从训练集中学习。
定义一个形状模型描述面部的几何模型:
class shape_model //2d linear shape model
{
public:
Mat p; // parameter vector (kx1) CV_32F
Mat V; // linear subspace (2nxk) CV_32F
Mat e; // parameter variance (kx2) CV_32F
Mat C; // connectivity (cx2) CV_32S
int npts() { return V.rows / 2;} //number of points in shape model
void calc_param(const vector 表示人脸形状变化的模型被编码在子空间V和方差向量e中。参数向量p保存着一个关于该模型形状的编码。连通矩阵C用于可视化面部形状的实例中。
calc_params函数将一个点集投影到貌似脸形(face space)的空间中,对每个投影的点有选择地给出置信权重。
calc_shape函数通过解码用在人脸模型的参数向量p(通过V和e编码)来生成点集。
train函数从脸形数据集中学习编码模型,这些脸形有相同的点数。frac、 kmax是训练过程的参数,根据数据来设置。
下面看看shape_model类的实现:
- Procrustes 分析
为了建立脸形的形变模型,首先必须删除原始标注数据中适用于全局性运行的部分。在二维几何模型中,常用相似变换来表示刚性运动,相似变换包括伸缩、平面内旋转、变换。从点集删除全局刚性运动的过程叫做Procrustes分析。

在数学上,Procrustes分析的目的是要同时找到一个标准形状和每个数据实例的相似变换,并让这些数据实例与标准形状对齐。对齐程度的度量使用最小平方距离。
Procrustes分析的实现:
#define fl at算法从去除每个形状的中心开始,随后执行一个迭代:就像处理所有形状的归一化平均一样来计算标准形状,然后旋转和缩放每个形状使之能与标准形状有最佳的匹配。
归一化所估计的标准形状可以解决尺度问题,并防止所有形状收缩至0. 这里的标准形状向量C所采用的长度为1.0 。
形状的旋转和伸缩实现:rot_scale_align 类
Mat shape_model::rot_scale_align(const Mat &src, const Mat &dst)
{
//construct lineaar system
int n = src.rows / 2; float a = 0, b = 0, d = 0;
for (int i = 0; i < n; i++)
{
d += src.fl(2*i) *src.fl(2*i) + src.fl(2*i +1)*src.fl(2*i +1);
a += src.fl(2*i) *dst.fl(2*i) + src.fl(2*i +1)*dst.fl(2*i +1);
b += src.fl(2*i) *dst.fl(2*i + 1) - src.fl(2*i +1)*dst.fl(2*i );
}
a /= d; b /= d; //solved linear system
return(Mat_(2,2) << a,-b,b,a);
} 使用该函数rot_scale_align可以得出旋转形状与标准形状的最小二乘。数学表达式为: 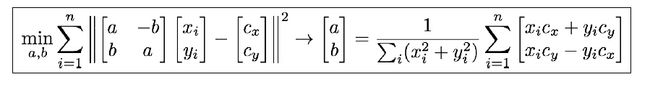
只需要求解a、b变量即可; 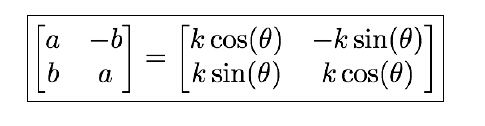
对原始数据进行普氏分析后,其可视化效果如下图所示: 
每个面部特征使用一种颜色表示,在变化归一后, 结构变得很明显,面部特征的位置都聚集在这些平均特征周围。在迭代完成伸缩和旋转的归一化后,同一特征之间聚集的更加紧凑,更能反映面部形变引起的变化。
2.线性形状模型
面部形变模型的目标是找到一组少量参数来表示多个人以及不同表情的脸型是如何变化的。 这里使用面部几何的线性表示 ,能精确捕获面部形变,且获得其代表性参数比较简单,操作代价低。面部几何线性模型的主要思想如下:由N个面部特征构成的一幅人脸图像可看成是2N维空间的一个点。线性模型的目标就是找到一个低维超平面嵌入2N维空间,所有人脸的点(绿色)都在这个2N维空间中。这个超平面仅由整个2N维空间的一个子集生成,因此称它为子空间。
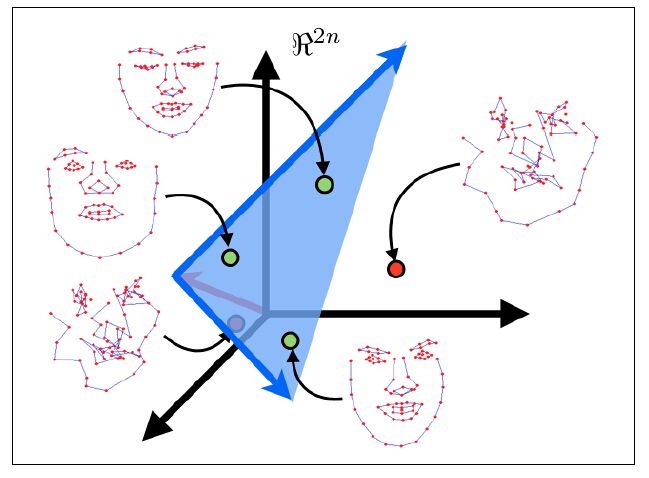
子空间的维数越低,对人脸的描述越简单,跟踪过程的约束就越强,鲁棒性更强。查找生成数据集的最佳低维子空间的过程叫主成分分析(principal component analysis,PCA)。opencv有计算PCA的类,但需要预先指定获得的子空间维数。预先得到这个维数很困难,通常采用启发式方法得到,即按所选择的特征向量对应的特征值占整个特征值的比例来确定该维数。
在定义的shape_model::train类中,PCA的实现:
//Data = U*w*Vt,奇异值矩阵为w
SVD svd(dY *dY.t());
int m = min(min(kmax, N -1), n -1);
float vsum = 0; for(int i = 0; i< m; i++) vsum += svd.w.fl(i);
float v = 0; int k = 0;
for(k = 0; k < m; k++) //取前k个奇异值
{
v += svd.w.fl(k);
if(v / vsum >= frac) {k++; break;}
}
if(k > m) k = m;
Mat D = svd.u(Rect(0, 0, k, 2*n)); //非刚性变化投影变量dY的每列表示减掉均值后用Procrustes对齐的脸型。
SVD:singular value decompose,奇异值分解
w: opencv中SVD的类成员变量,存放数据主要变化方向的方差,从大到小存储。svd.w 和svd.u的每个元素通常称为特征值和特征向量。
选择子空间的维数的常用方法是在w中找一个最小集合,使该集合元素与整个数据能量的比例大于变量frac,因为w中的元素是降序排列的,只要取前k个变化方向的能量就可得到要选择的子空间维数。
3.局部-全局相结合的表示
因为一幅图像帧的形状由局部形变与全局形变组合在一起得到,通常将全局变换作为一个线性子空间,将其加到形变子空间中。也就是说,联合矩阵可以分成2个分块矩阵,左半边是刚性参数(4列),右半边是非刚性参数(k列)。

上述公式中,a和b是刚性变化的参数,tx和ty是非刚性变化参数,x和y是样本特征点坐标。由于在得到非刚性参数之前,样本特征点就已经去中心化了,因此非刚性子空间正交于刚性子空间。那么将两个子空间串联起来,得到上述脸型的联合线性表达[a b tx ty]T也是正交的。这样,我们就可以非常容易得使用这个正交空间来描述脸型。
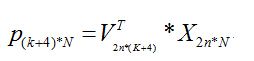
P是人脸形状在联合子空间中的坐标,V是联合变化矩阵,X是2N维空间样本坐标。这样就可以获得联合分布空间的坐标了。
//combine bases
V.create(2*n, 4+k, CV_32F);
Mat Vr = V(Rect (0, 0, 4, 2*n)); R.copyTo(Vr); //rigid subspace
Mat Vd = V(Rect (4, 0, k, 2*n)); D.copyTo(Vd); // nonrigid subspace最后要注意的是线性模型化脸型要怎样约束子空间坐标,才使得生成的形状有效。通常的做法是用正负3倍的数据标准差作为一个箱约束,这个部分占数据变化的99.7%。
//compute variance(normalized wrt scale)
Mat Q = V.t() * X; //矩阵Q即为联合分布空间的新坐标集合
for (int i = 0; i < N; i++)
{
/*用Q的第一行元素分别去除对应的0~K+4行元素,归一化新空间的scale,防止
数据样本(联合分布投影后)的相对尺度过大,影响后面的判断*/
float v = Q.fl(0, i); Mat q = Q.col(i);
q /= v;
}
e.create(4 + k, 1, CV_32F);
pow(Q, 2, Q); // multiply(Q, Q, Q)
for (int i = 0; i < 4 + k; i++)
{
if(i < 4) e.fl(i) = -1; //no clamping for rigid coefficients,矩阵Q的前4列为刚性系数
else e.fl(i) = Q.row(i).dot(Mat::ones(1, N, CV_32F))/(N - 1); //点积,对k列非刚性系数分别求每个图像的均值
}4.训练与可视化
从标注数据训练人脸模型:
#include "ft.h"
#include "ft_data.h"
#include "shape_model.h"
#include ("annotations.xml");
if(data.imnames.size() == 0)
{
cerr << "Data file does not contain any annotations."<< endl;
return 0;
}
//remove unlabeled samples and get reflections as well
data.rm_incomplete_samples();
for(int i = 0; i < int(data.points.size()); i++)
{
points.push_back(data.get_points(i,false));
if(mirror)
points.push_back(data.get_points(i,true));
}
//train model and save to file
cout << "shape model training samples: " << points.size() << endl;
smodel.train(points,data.connections,frac,kmax);
cout << "retained: " << smodel.V.cols-4 << " modes" << endl;
save_ft("shape.xml",smodel);
return 0;
} 加载人脸模型,进行可视化:
#include "ft.h"
#include "ft_data.h"
#include "shape_model.h"
#include // for 'sprintf()'
using namespace std;
using namespace cv;
//image to draw on text
void draw_string(Mat img, const string text)
{
Size size = getTextSize(text, FONT_HERSHEY_COMPLEX, 0.6f, 1, NULL);
putText(img, text, Point(0, size.height), FONT_HERSHEY_COMPLEX, 0.6f, Scalar::all(0), 1, CV_AA);
putText(img, text, Point(1, size.height + 1), FONT_HERSHEY_COMPLEX, 0.6f, Scalar::all(255), 1, CV_AA);
}
void draw_shape(Mat &img, const vector("shape.xml");
namedWindow("shape model");
//compute rigid parameters
//矩阵V为脸型的刚性和非刚性联合变换矩阵,大小为2n*(k+4),
//V的第一列为尺度大小,第三、第四列对应x和y方向的变化
int n = smodel.V.rows / 2;
float scale = calc_scale(smodel.V.col(0), 200);
float tranx = n*150.0 / smodel.V.col(2).dot(Mat::ones(2*n, 1, CV_32F));
float trany = n * 150.0 / smodel.V.col(3).dot(Mat::ones(2*n, 1, CV_32F));
//generate trajectory of parameters 生成画图的坐标系
for(int i = 0; i < 50; i++)
val.push_back(float(i) / 50);
for(int i = 0; i < 50; i++)
val.push_back(float(50 - i) / 50);
for(int i = 0; i < 50; i++)
val.push_back(-float(i) / 50);
for(int i = 0; i < 50; i++)
val.push_back(-float(50 - i) / 50);
//visualise
while (1)
{
//按照非刚性变化,展示动画,动画数量供V.cols-3个,不断遍历这个循环
for (int k = 4; k < smodel.V.cols; k++)
{
for (int j = 0; j < int(val.size()); j++)
{
Mat p = Mat::zeros(smodel.V.cols, 1, CV_32F);
//这3个参数为固定值,使得图像处于屏幕中央
p.at<float>(0) = scale;
p.at<float>(2) = tranx;
p.at<float>(3) = trany;
//根据缩放尺度、坐标系、柔性变化(标准差),还原脸型
p.at<float>(k) = scale * val[j] *3.0 * sqrt(smodel.e.at<float>(k));
p.copyTo(smodel.p);
img = Scalar::all(255);
char str[256];
sprintf(str,"mode: %d, val : %f sd", k-3, val[j] / 3.0);
vector 最后加载的可视化线性人脸模型: 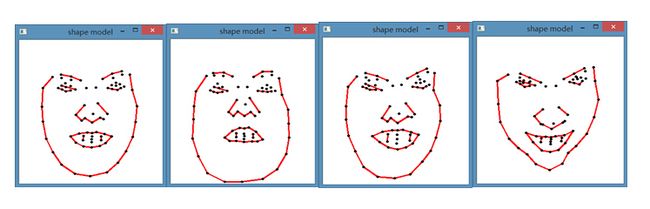
发现有一个写该系列写的很好的博客。顿时感觉自己写的就像流水账。。。。参考:非刚性人脸跟踪系列
代码:http://download.csdn.net/detail/yiluoyan/8676873