matlab coder分析
转自 https://zhuanlan.zhihu.com/p/27151590
Matlab coder本身的作用是生成C/C++代码,一般来说是配合Embedded coder给嵌入式环境使用,其本身在本身也可以配置的时候选择运行的嵌入式环境。
但其很多奇奇怪怪的功能也被我用来做各种奇奇怪怪的事情了。。。。。。
在此简单介绍一下
- 运行加速
- matlab动态链接库分发
- C/C++代码生成
- 数据限制
- 运行内存和运算量检查
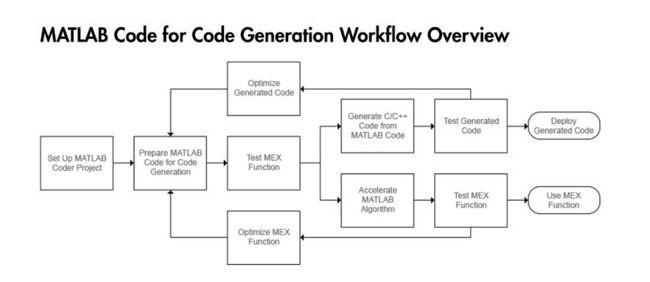
首先大概聊一下coder的运行步骤(以最新的matlab coder为准),在command window输入命令coder,自动就会打开coder的界面。一共有6(7)个步骤,分别为Select,Review,Define,Check,Generate,Finish。如果选择转为定点数据,那么在Check之后还有多一个Convert步骤用来搞定数据转换。
用一个官方图来说明整个的使用步骤:
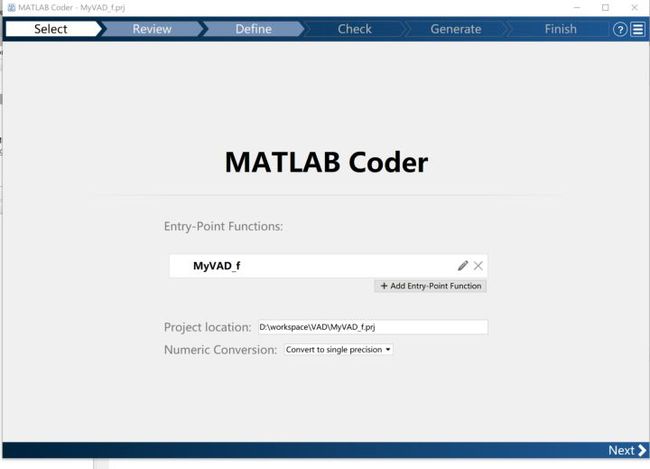
1) Select
首先选择一个函数,脚本不能转换,Project location一般是这个coder project的存储位置,方便下次打开。
Numeric conversion 一般指的是数据格式的转换,matlab里面默认的数据类型都是双精度浮点型,但是一般嵌入式环境下都不可能能够承受如此的数据量和计算精度,需要对此数据做出限制。
2) Review
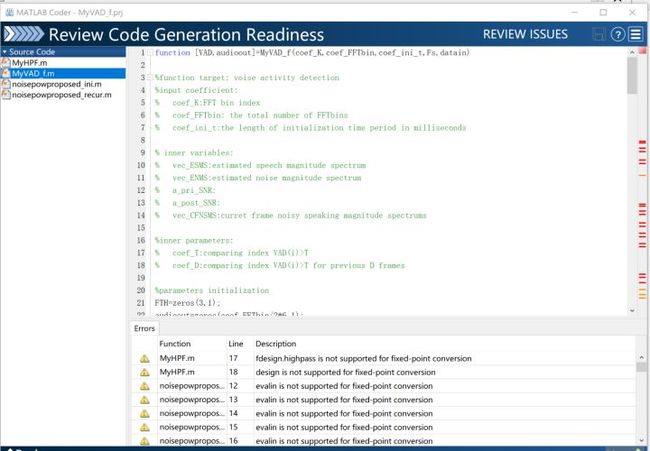
在Review中会检查是否所有的函数都能被支持,而像evalin,assignin以及滤波器设计这种函数其实就不被支持。一般来讲,C风格的所有函数都能被支持,具体关于哪些函数会被Coder支持,可以自行查阅mathwork官网。
3)Define
开头就已经说过,只能转换函数而不是脚本,所以需要定义函数的输入输出的矩阵规模和数据格式,其中如果有调用此函数的脚本,则可以使用脚本来确定输入输出数据的矩阵规模和数据格式。
当然也可以手动输入输入数据数据的矩阵规模和数据格式。
对于Global 的输入,也可以手动输入矩阵规模和数据格式。
4)check
在check中,会生成一个临时性的mex文件(关于mex文件,稍后详细解释),运行调用此函数的脚本,然后核对matlab函数和临时生成的mex的之间的差别,一般有问题都会在这里指出,方便debug。
同时在这一步,因为调用实际使用的测试脚本,故可以查看每一条语句的调用次数。
5)Generate
关于Generate里面有很多选项,关键着重讲几个,第一个是目标形式,可以是source code,可以是mex,可以是.a等等库文件:
• MEX function
• C/C++ Static Library
• C/C++ Dynamic Library
• C/C++ Executable
• C/C++ source code
开始谈几个问题,一个是source code,主要是直接形成c/c++代码,最关键的其实是输入输出矩阵的形式,我们在主函数中需要调用matlab function转换的source code,这个接口是非常重要的。
这个时候需要提出矩阵的信息到底有哪几部分构成:
i. 矩阵数据类型(ex. 复/实数)
ii. 矩阵数据表示类型(ex. 单/双精度)
iii. 矩阵维数(向量/矩阵/三维向量)
iv. 矩阵规模(矩阵规模 2*2/4*4 矩阵)
vi. 矩阵数据
由此可以看出,除了最后一项是真正的数据以外,其他的都可以算作矩阵的“头数据”。对于真正的数据,矩阵数据是以一维指针的形式传递,那么就涉及到矩阵元素的排列顺序是行优先还是列优先,在matlab和fortan中,数据以列优先的形式存放,在C/C++中,数据都已行优先的形式。具体的矩阵传递接口,matlab生成的代码中,有相关的各种内存结构体参数提供,可以自行查阅生成的函数。
第二个选项是mex格式,mex格式的全称是matlab executable,实质上是一个matlab的动态链接库,另外matlab调用C函数的接口实际上也是通过mex接口,所以有多种用途,但选择编译为mex以后,选项只有JIT(just in time)选项,在官方文档中,对JIT选项的解释为integrated in file to save run time?(详细的等我查证一下)。
后几个都是源码的各种库,我都没有用过,故就不说明了。
简单谈谈matlabC函数的生成模式,
比如式子:C=AB,其中A,B,C都是矩阵
那么在matlab中式子就是:
C=A*B
而如果仔细检查生成的C代码,每一步小计算式(最简单的计算)C代码包含:
a)C矩阵的内存大小检查,如果不够,就动态分配再次申请空间。
b)生成C矩阵的”头信息“,之前说过“头信息”内容。
c)计算的得到C矩阵的数据。
在这简单谈一下为什么自动转码出来的代码可能运行速度比自己写的要差一点,我们常常用来黑C/C++的一个关键点,C/C++的内存管理实际上是有程序员而不是编译器来控制的,虽然要求程序员需要能强的能力,但是也是最贴近底层的。
而在内存分配之前已经做好的情况下,每一步都要检查内存实际上有时间的浪费,还有就是一句题外话,在运算迭代中,如果内存不足而需要频繁的malloc/free的话,可能占用时间比运算时间还要长。
好的,在此简单切入主题,怎么用这个Matlab coder来实现功能(运行加速/matlab动态链接库分发/C/C++代码生成/数据限制/运行内存和运算量检查)
运行加速:生成mex函数,然后使用mex函数替代原来的函数,使用方法,就跟原来function的调用方法一样,在没改文件名的情况下,增加后缀“_mex”就好了。
matlab动态链接库(可以用来分发给其他计算机的matlab):生成mex函数
C/C++:不需要我说了
数据限制:numberic conversion
运行内存和运算量检查:
这个要着重说一下,全部的转化完成以后,会得到一个report
其中在这个报告中,可以看到各个子函数的内存使用和计算复杂度(complexity)。
先说一下这个复杂度,我用profile这个工具对比过运行时间合格复杂度直接的差别,按道理来说,复杂度和运行时间应该是线性的,但实际上是有一点区别的,而且,report的复杂度应该跟数学式子的复杂度也是线性的,但也是有区别的。
后来我仔细研究过,发现报告中对于内存操作的复杂度跟实际有一定区别,因为这个,所以这个report中的复杂度我一般只用来横向对比各个算法,这点还是很好用的。
关于内存使用,对于每个子函数指标叫self_stack_size 和accum_size,其中分别代表在迭代计算中不能被释放和可以被释放的内存量,所以对于整个算法的内存用两实际为:
accumulated_stack_size = sum( self_stack_size1,self_stack_size2.....self_stack_sizeN) + max(accum_size1, accum_size2 ..., accum_sizeN)
其中1-N分别代表1-N个子函数。
Matlab Coder是一个非常强大的工具,除了我们能够看到的转码,现在也发展出来了很多千奇百怪的副产物,先写到这里,一方面做自我总结,所以结构还是挺混乱的,另一方面,欢迎大家讨论。
Reference
[1]https://cn.mathworks.com/help/coder/gs/generating-c-code-from-matlab-code-using-the-matlab-coder-project-interface.html
[2]https://cn.mathworks.com/help/pdf_doc/coder/coder_gs.pdf
: