机器学习17 -- GAN 生成对抗网络
1 什么是GAN
1.1 组成部分:生成器和判别器
GAN诞生于2014年,由深度学习三巨头之一的Bengio团队提出。是目前为止机器学习中最令人兴奋的技术之一。目前有几百种不同构架的GAN,论文也是非常非常多,可见研究有多么热门。

论文信息:2014.06,Bengio团队
论文地址:Generative Adversarial Networks
GitHub地址:https://github.com/goodfeli/adversarial
GAN利用Generator和Discriminator,可以完成很多匪夷所思的生成问题。在图像生成、语音转换、文本生成领域均占有很重要地位。它由两部分组成
- Generator生成器,它是一个深度神经网络,输入一个低维vector,输出高维vector(图片或文本或语音)
- Discriminator判别器,它也是一个深度神经网络,输入一个高维vector(图片或文本或语音),输出一个标量。标量越大,代表输入图片(或文本语音)越真实。
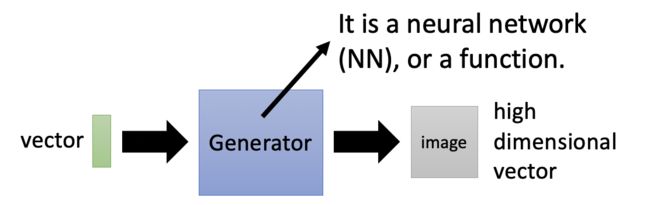

1.2 对抗学习
生成器和判别器二者进行对抗学习,生成器不断迭代进化,努力生成假的图片,从而可以骗过判别器。判别器也在不断迭代进化,努力识别越来越接近真实的假图片。通过二者对抗学习,最终生成器生成的假图片越来越像真实图片,而判别器越来越能区分和真实图片很接近的假图片。二者能力在迭代过程中,都可以得到大幅提升。

如上图所示,枯叶蝶可以视作生成器,鸟可以视作判别器。枯叶蝶不断进化,长得越来越像枯叶,从而可以骗过鸟,不被吃掉。而鸟在这个过程中也是不断进化的,从最初从颜色来区分真假,到从纹理区分,它也在学习如何区分真假枯叶。
1.3 应用场景
GAN在实际中也大有用武之地。
- 商品评价系统中,生成器努力生成接近真实人类的评价,而判别器则努力鉴别真假图片。最终生成器可以用来自动生成高质量评论,而判别器则可以用来发现机器自动生成的评价。生成器和判别器两者都是很有用的。
- 图片生成。比如卡通人脸自动生成。利用GAN可以自动生成超过100万张不重复的高清卡通人脸
- 无监督图片风格转换。比如真实人脸转换为对应卡通人脸,向左看的人脸转换为向右看
- 文本转图片,或图片转文本。
- 语音增强、语音转换。比如语音去噪,将男性声音转换为女性声音等
- NLP数据增强。通过GAN扩充高质量的文本样本,用作数据增强
2 如何实现GAN
2.1 通用步骤
GAN的通用步骤如下
- 固定住生成器,update判别器。从真实图片中随机sample一些样本。然后利用一些随机sample的vector,通过生成器得到一些假样本。真样本标注为1,假样本标注为0。构建完监督数据后就可以训练判别器了。判别器可以用MSE作为loss。它的目标是真实图片得高分,假图片得低分。
- 固定住判别器,update生成器。利用随机sample的vector,通过生成器得到一些假样本。然后再通过判别器进行打分。它的目标是假图片得分也要高。
- 迭代步骤1和步骤2,即可迭代训练生成器和判别器。
2.2 网络架构
其网络架构可以是一个end2end的模型
- 前面几个layer可以作为生成器。需要固定时直接freeze这些参数,让他们不参与模型训练即可
- 后面几个layer可以作为判别器
- 中间某一层输出一个高维的feature map,它可以看做是生成的图片或文本。

2.3 目标函数
判别器的目标是真实样本高分,假样本低分,其目标函数如下,我们需要最大化这个目标函数。其中xi为真实样本,x ̃i为假样本。

生成器的目标是假样本也得高分。zi为一个随机vector,它通过G()得到一个假样本,然后再通过D()进行判别。我们的目标是让判别平均分尽量高

3 生成器为什么需要判别器的帮助
广义来说,生成器和判别器二者不是敌人,他们不是对抗关系。他们其实是在对方帮助下,不断提升了自己,成就了彼此。那现在有个问题,我们利用Auto-Encoder等技术,不是就已经可以生成还不错的图片了吗。貌似生成器不需要判别器,就可以搞定生成的问题啊。
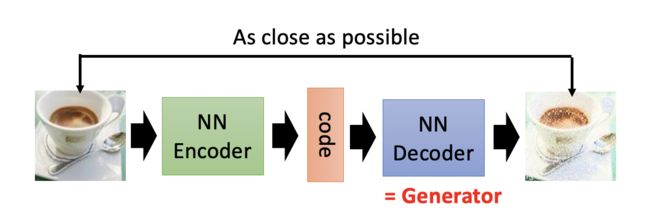
如上图所示,训练完Auto-Encoder后,decoder网络就可以作为生成器了。结合去噪自编码器,变分自编码器VAE等技术,可以大大提升生成器的鲁棒性,提升图片生成质量。那这样做有什么问题呢?
问题就在于As close as possible判别这一步,直接在pixel级别上,对输入输出图片进行对比,是一个很不科学的行为。因为pixel级别对比,特征实在是太低阶了。我们对比两个物体相似度,要尽量在高阶特征上进行对比。比如下面一个典型例子

利用Auto-Encoder生成的数字2,上面两个结果,虽然只有一个pixel的error。但是它们在关键位置出错了,比如出现一个单独的有颜色的pixel,以及中间挖空了一个pixel。这显然不可能是真实人类画出来的。而下面两个结果,虽然有6个pixel的error,但它们都是合乎情理的,只是笔画的加长而已。故直接在pixel级别上判别图片,是很不严谨的一种方法。
一般来说,利用VAE生成的图片没有GAN清晰。如下图所示

那怎么判别图片的生成效果呢?当然就是用判别器了啊。这就是为什么生成器需要判别器的帮助了
4 判别器为什么需要生成器的帮助
那判别器有没有办法独立完成高质量图片的生成呢。我们也是有办法的。我们可以通过组合pixel的办法进行图片的生成,随机sample一些组合后的假图片,和真实图片放一起,给到判别器,从而来训练判别器。通过不断的迭代,判别器能力会越来越强,最终挑选出被打高分的随机组合pixel得到的图片即可。这个办法看似可行,但其实问题也很多
- 速度会特别特别慢,通过组合pixel得到图片的方法,可能性实在是太多了,有点漫无目的的感觉
- 组合pixel得到图片这个方法,很难得到高质量的以假乱真的假图片。导致判别器任务过于简单,训练不充分
- 组合pixel这个方法,不像神经网络模型,可以不断迭代进步。
因此,判别器也是需要有生成器的帮助,才能不断提升任务难度,不断进化的。
5 conditional GAN 条件生成
一般来说自动生成图片或文本意义不算很大,但如果能在一定限制条件下生成,则十分有意义。比如生成一张图片,要和给定的文本语义接近,这就是text2image。利用conditional GAN,我们可以得到我们想要的图片。
5.1 生成器
conditional GAN的生成器一般如下。
- 输入一个正态分布vector z,和条件condition(比如下图中的文本train)
- 通过深度神经网络构建的生成器,生成一个样本

生成器这一块没啥花头,只是多了一个condition输入而已。
5.2 判别器
conditional GAN的判别器一般如下
- 输入一个样本,和条件condition,它们分别经过网络模型进行特征抽取
- 通过深度神经网络构建的判别器,输出一个得分。
判别器的目标有两个,一个是样本要尽量真实,第二个是样本要和条件是匹配的。这和通用的GAN是不同的
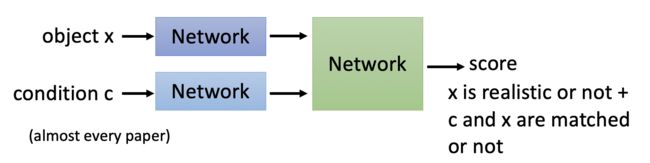
为了避免模型需要应对两个条件,导致难度过大。我们也可以把判别器的两个条件分开,如下

网络分为两路,样本通过绿色network,判别是否是真实样本。条件condition和样本同时经过蓝色network,判别二者是否是match的。
通过condition GAN,我们就可以随心控制想要的输出了。比如我们可以控制想要的眼睛和头发颜色,来生成想要的卡通头像。
6 unsupervised conditional GAN 无监督条件GAN
通用GAN和条件GAN,都需要监督信号,也就是满足条件的真实样本。有时候真实样本不是那么容易得到,那我们有没有办法实现无监督条件GAN呢。在某些任务中,还是可以实现的。比如图片风格转换。
6.1 cycleGAN
conditional GAN需要满足两个条件,一个是图片尽量真实,另一个是图片是想要的风格。cycleGAN利用两个生成器和一个判别器解决了这个问题。如上图所示,我们需要将真实图片转换为抽象派图片,分别记为domain X和domain Y。步骤如下
- domain X真实图片,通过G(x->y),生成一张domain Y的抽象派图片
- 生成的domain Y图片,通过G(y->x),生成一张domain X的图片。
- 对比生成的domain X的图片和真实的domain X的图片,二者越接近越好
- 通过一堆domain Y的图片,训练一个domain Y图片判别器Dy
- 生成的domain Y的抽象派图片,通过判别器Dy进行打分,分数越高越好。
通过两个生成器,将domain x的图片转换为domain y,然后又转换回domain x,从而确保两个domain图片是关联的。这种方法就是cycleGAN。
6.2 其他方法
其他有XGAN、Couple GAN、UNIT、ComboGAN可以解决这个问题。就不一一说了。