【概率论】一维随机变量
未经同意,禁止转载
本文为本人在校学习笔记,若有疑问或谬误,欢迎探讨、指出。
文章目录
- 未经同意,禁止转载
- 【概率论】一维随机变量
-
- 离散型
-
- (0-1)分布 Bernoulli Distribution
- 二项分布 Binomial Distribution
- 泊松分布 Poisson Distribution
- 几何分布 Geometric Distribution
- 连续型
-
- 均匀分布 Uniform Distribution
- 指数分布 Exponential Distribution
-
- 伽马分布 Gamma Distribution
- 正态分布 Normal Distribution
【概率论】一维随机变量
- 离散型:有限个 / 可列无限多个取值
- 连续型:分布函数是由一个非负可积函数变上限积分得到的(易知是连续的)
- 混合型:不是离散也不是连续型
证明分布函数右连续:
海涅定理 + 极限
证明 P { x = a } = F ( a − 0 ) P\{x=a\} = F(a-0) P{ x=a}=F(a−0)
-
证明:连续型随机变量的分布函数一定连续
转化为证明由可积函数(概率密度)$f(x) $ 的变上限积分 ∫ − ∞ x f ( x ) d x \int_{-\infty}^xf(x) \mathrm{d}x ∫−∞xf(x)dx 一定连续
lim δ → 0 ∫ − ∞ x + δ f ( x ) d x ⇒ lim δ → 0 ( ∫ − ∞ x f ( x ) d x + ∫ x x + δ f ( x ) d x ) only need to prove lim δ → 0 ∫ x x + δ f ( x ) d x = 0 \begin{aligned} & \lim_{\delta\to0} \int_{-\infty}^{x+\delta}f(x)\mathrm{d}x \\ & \Rightarrow \lim_{\delta\to0} (\int_{-\infty}^{x}f(x)\mathrm{d}x + \int_{x}^{x+\delta}f(x)\mathrm{d}x) \\ \quad \\ & \text{only need to prove } \lim_{\delta\to0}\int_{x}^{x+\delta}f(x)\mathrm{d}x = 0\\ \end{aligned} \\ δ→0lim∫−∞x+δf(x)dx⇒δ→0lim(∫−∞xf(x)dx+∫xx+δf(x)dx)only need to prove δ→0lim∫xx+δf(x)dx=0
f ( x ) is integrabel, so it is bounded ∃ M , s.t. − M < f ( x ) < M ∵ − M δ ≤ ∫ x x + δ f ( x ) d x ≤ M δ ⇒ lim δ → 0 − M δ ≤ lim δ → 0 ∫ x x + δ f ( x ) d x ≤ lim δ → 0 M δ ⇒ 0 ≤ lim δ → 0 ∫ x x + δ f ( x ) d x ≤ 0 ∴ Squeeze Theorem: lim δ → 0 ∫ x x + δ f ( x ) d x = 0 f(x)\text{ is integrabel, so it is bounded} \\ \exists M, \text{ s.t.}-M < f(x) < M \\ \begin{aligned} & \because -M\delta \le \int_{x}^{x+\delta}f(x)\mathrm{d}x \le M\delta \\ & \Rightarrow \lim_{\delta\to0} -M\delta \le \lim_{\delta\to0} \int_{x}^{x+\delta}f(x)\mathrm{d}x \le \lim_{\delta\to0} M\delta \\ & \Rightarrow 0 \le \lim_{\delta\to0} \int_{x}^{x+\delta}f(x)\mathrm{d}x \le 0 \\ & \therefore \text{Squeeze Theorem: } \lim_{\delta\to0} \int_{x}^{x+\delta}f(x)\mathrm{d}x = 0 \\ \end{aligned} \\ f(x) is integrabel, so it is bounded∃M, s.t.−M<f(x)<M∵−Mδ≤∫xx+δf(x)dx≤Mδ⇒δ→0lim−Mδ≤δ→0lim∫xx+δf(x)dx≤δ→0limMδ⇒0≤δ→0lim∫xx+δf(x)dx≤0∴Squeeze Theorem: δ→0lim∫xx+δf(x)dx=0
lim δ → 0 ∫ − ∞ x + δ f ( x ) d x = ∫ − ∞ x f ( x ) d x , ∫ − ∞ x f ( x ) d x is continuous \lim_{\delta\to0} \int_{-\infty}^{x+\delta}f(x)\mathrm{d}x = \int_{-\infty}^{x}f(x)\mathrm{d}x, \\ \int_{-\infty}^{x}f(x)\mathrm{d}x\text{ is continuous} δ→0lim∫−∞x+δf(x)dx=∫−∞xf(x)dx,∫−∞xf(x)dx is continuous
离散型
(0-1)分布 Bernoulli Distribution
(两点分布、伯努利分布) X ∼ B ( 1 , p ) X \sim B(1, p) X∼B(1,p)
可以视为仅重复一次的伯努利试验
-
随机变量
X ( e ) = { 0 , when e = e 1 , 1 , when e = e 2 , X(e) = \begin{cases} 0, & \text{when } e=e_1, \\ 1, & \text{when } e=e_2, \\ \end{cases} X(e)={ 0,1,when e=e1,when e=e2, -
分布律
P { X = k } = p k ( 1 − p ) 1 − k , k = 0 , 1 P\{X = k\} = p^k (1-p)^{1-k},\quad k=0,1 P{ X=k}=pk(1−p)1−k,k=0,1 -
数字特征
-
数学期望
E ( X ) = 1 ⋅ p + 0 ⋅ ( 1 − p ) = p E(X) = 1\cdot p + 0\cdot (1-p) = p E(X)=1⋅p+0⋅(1−p)=p -
方差
D ( X ) = E ( X 2 ) − E 2 ( X ) = p − p 2 ⇒ D ( X ) = p ( 1 − p ) D(X) = E(X^2) - E^2(X) = p - p^2 \\ \Rightarrow D(X) = p(1-p) D(X)=E(X2)−E2(X)=p−p2⇒D(X)=p(1−p)
-
二项分布 Binomial Distribution
X ∼ B ( n , p ) X \sim B(n, p) X∼B(n,p)
n重伯努利试验中 A A A 发生 X X X 次的概率服从二项分布
-
伯努利试验:每次实验只有两种结果( A , A ‾ A, \overline{A} A,A),则称该试验为Bernoulli试验
-
分布律
A A A 的成功概率为 p p p, 则有
P { X = k } = C n k p k ( 1 − p ) n − k , k = 0 , 2 , 3 , . . . , n P\{X=k\} = C_n^k p^k (1-p)^{n-k}, \quad k=0,2,3,...,n P{ X=k}=Cnkpk(1−p)n−k,k=0,2,3,...,n -
趋势

-
数字特征
- 数学期望
E ( X ) = n p E(X) = np E(X)=np
推导:
X i = { 1 , 第i次试验成功 0 , 第i次试验失败 X_i = \begin{cases} 1, & \text{第i次试验成功} \\ 0, & \text{第i次试验失败} \\ \end{cases} Xi={ 1,0,第i次试验成功第i次试验失败
X = ∑ i = 1 n X i X = \sum_{i=1}^n X_i X=i=1∑nXi
E ( X ) = E ( ∑ i = 1 n X i ) = ∑ i = 1 n E ( X i ) = ∑ i = 1 n X i ⇒ E ( X ) = n p E(X) = E(\sum_{i=1}^n X_i) = \sum_{i=1}^n E(X_i) = \sum_{i=1}^n X_i \\ \Rightarrow E(X) = np E(X)=E(i=1∑nXi)=i=1∑nE(Xi)=i=1∑nXi⇒E(X)=np
-
方差
D ( X ) = n p ( 1 − p ) D(X) = np(1-p) D(X)=np(1−p)
推导:各次伯努利试验之间相互独立,协方差项为0,则
D ( X ) = D ( ∑ i = 1 n X i ) = ∑ i = 1 n D ( X i ) = n D ( X i ) = n p ( 1 − p ) \begin{aligned} D(X) & = D(\sum_{i=1}^n X_i) = \sum_{i=1}^n D(X_i) \\ & = nD(X_i) \\ & = np(1-p) \end{aligned} D(X)=D(i=1∑nXi)=i=1∑nD(Xi)=nD(Xi)=np(1−p)
- 数学期望
-
计算性质:可加性
X ∼ b ( n 1 , p ) , Y ∼ b ( n 2 , p ) X + Y ∼ b ( n 1 + n 2 , p ) X \sim b(n_1, p), Y \sim b(n_2, p) \\ X+Y \sim b(n_1+n_2, p) X∼b(n1,p),Y∼b(n2,p)X+Y∼b(n1+n2,p)
泊松分布 Poisson Distribution
X ∼ π ( λ ) X \sim \pi(\lambda) X∼π(λ)
-
分布律
P { X = k } = λ k k ! e − λ , k = 0 , 1 , 2 , . . . P\{X=k\} = \frac{\lambda^k}{k!}e^{-\lambda},\quad k=0,1,2,... P{ X=k}=k!λke−λ,k=0,1,2,... -
数字特征
-
数学期望
E ( X ) = λ E(X) = \lambda E(X)=λ
(推导):
E ( x ) = ∑ k = 0 ∞ k ⋅ λ k k ! e − λ = λ e − λ ∑ k = 0 ∞ λ k − 1 ( k − 1 ) ! = λ e − λ e λ = λ \begin{aligned} E(x) & = \sum_{k=0}^\infty k\cdot \frac{\lambda^k}{k!}e^{-\lambda} \\ & = \lambda e^{-\lambda}\sum_{k=0}^\infty \frac{\lambda^{k-1}}{(k-1)!} \\ & = \lambda e^{-\lambda} e^\lambda \\ & = \lambda \\ \end{aligned} E(x)=k=0∑∞k⋅k!λke−λ=λe−λk=0∑∞(k−1)!λk−1=λe−λeλ=λ -
方差
D ( X ) = λ D(X) = \lambda D(X)=λ
(推导):E ( X 2 ) = E [ X ( X − 1 ) + X ] = E [ X ( X − 1 ) ] + E ( X ) = ∑ k = 0 ∞ k ( k − 1 ) ⋅ λ k k ! e − λ + E ( x ) = e − λ ∑ k = 0 ∞ λ k − 2 ( k − 2 ) ! + E ( x ) = λ 2 e − λ ∑ k = 2 ∞ λ k − 2 ( k − 2 ) ! + E ( x ) = λ 2 e − λ ∑ i = 0 ∞ λ i i ! + E ( x ) = λ 2 e − λ e λ + E ( x ) = λ 2 + λ \begin{aligned} E(X^2) & = E[X(X-1) + X]\\ & = E[X(X-1)] + E(X) \\ & = \sum_{k=0}^\infty k (k-1)\cdot \frac{\lambda^k}{k!}e^{-\lambda} + E(x) \\ & = e^{-\lambda} \sum_{k=0}^\infty \frac{\lambda^{k-2}}{(k-2)!} + E(x) \\ & = \lambda^2e^{-\lambda} \sum_{k=2}^\infty \frac{\lambda^{k-2}}{(k-2)!} + E(x) \\ & = \lambda^2e^{-\lambda} \sum_{i=0}^\infty \frac{\lambda^i}{i!} + E(x) \\ & = \lambda^2e^{-\lambda}e^{\lambda} + E(x) \\ & = \lambda^2 + \lambda \end{aligned} E(X2)=E[X(X−1)+X]=E[X(X−1)]+E(X)=k=0∑∞k(k−1)⋅k!λke−λ+E(x)=e−λk=0∑∞(k−2)!λk−2+E(x)=λ2e−λk=2∑∞(k−2)!λk−2+E(x)=λ2e−λi=0∑∞i!λi+E(x)=λ2e−λeλ+E(x)=λ2+λ
代入方差表达式得
D ( X ) = E ( X 2 ) − E 2 ( X ) = λ 2 + λ − λ 2 = λ \begin{aligned} D(X) & = E(X^2) - E^2(X) \\ & = \lambda^2 + \lambda - \lambda^2 \\ & = \lambda \end{aligned} D(X)=E(X2)−E2(X)=λ2+λ−λ2=λ
-
-
计算性质:可加性
X ∼ π ( λ 1 ) , Y ∼ π ( λ 2 ) X + Y ∼ π ( λ 1 + λ 2 ) X \sim \pi(\lambda_1), Y \sim \pi(\lambda_2) \\ X+Y \sim \pi(\lambda_1 + \lambda_2) X∼π(λ1),Y∼π(λ2)X+Y∼π(λ1+λ2) -
泊松定理
设 λ > 0 \lambda > 0 λ>0 是一个常数, n n n 为任意正整数, 设 n p n = λ np_n = \lambda npn=λ, 则对于任一固定的非负整数有
lim n → ∞ C n k p k ( 1 − p ) n − k = λ k e − λ k ! \lim_{n\to\infty}C_n^k p^k (1-p)^{n-k} = \frac{\lambda^k e^{-\lambda}}{k!} n→∞limCnkpk(1−p)n−k=k!λke−λ样本 n n n 足够大时, p n p_n pn 会很小。
当 λ = n p \lambda = np λ=np 值合适时(不太大也不太小),可用Poisson Distribution逼近Binomial Distribution
C n k p k ( 1 − p ) n − k ≈ λ k e − λ k ! C_n^k p^k (1-p)^{n-k} \approx \frac{\lambda^k e^{-\lambda}}{k!} Cnkpk(1−p)n−k≈k!λke−λ
几何分布 Geometric Distribution
X ∼ G E ( p ) X \sim GE(p) X∼GE(p)
在n次Bernoulli试验中,试验k次才得到第一次成功的机率。也即:前k-1次皆失败,第k次成功的概率。
几何分布是Pascal分布当r=1时的特例。
-
分布律
P { X = k } = ( 1 − p ) k − 1 p , k = 1 , 2 , . . . P\{X = k\} = (1-p)^{k-1} p, \quad k=1,2,... P{ X=k}=(1−p)k−1p,k=1,2,... -
数字特征
-
数学期望
E ( X ) = 1 p E(X) = \frac{1}{p} E(X)=p1
直觉:命中率更高的,数学期望小(失败次数少)。推导:
E ( X ) = ∑ k = 0 ∞ k ( 1 − p ) k − 1 p = p ∑ k = 0 ∞ [ − ( 1 − p ) k ] ′ = − p ⋅ [ ∑ k = 0 ∞ ( 1 − p ) k ] ′ = − p ⋅ [ 1 p ] ′ = 1 p \begin{aligned} E(X) & = \sum_{k=0}^\infty k(1-p)^{k-1}p \\ & = p \sum_{k=0}^\infty [-(1-p)^{k}]' \\ & = -p \cdot [\sum_{k=0}^\infty (1-p)^{k}]' \\ & = -p \cdot [\frac{1}{p}]' \\ & = \frac{1}{p} \end{aligned} E(X)=k=0∑∞k(1−p)k−1p=pk=0∑∞[−(1−p)k]′=−p⋅[k=0∑∞(1−p)k]′=−p⋅[p1]′=p1
(用等差乘等比数列方法求 a k = k ( 1 − p ) k − 1 a_k = k(1-p)^{k-1} ak=k(1−p)k−1 前n项和通项,再求极限,也能够推出,但麻烦) -
方差
D ( X ) = 1 − p p 2 D(X) = \frac{1-p}{p^2} D(X)=p21−p推导:
E ( X 2 ) = E [ X ( X − 1 ) ] + E ( X ) = ∑ k = 1 ∞ k ( k − 1 ) ( 1 − p ) k − 1 p + E ( X ) = ∑ k = 2 ∞ k ( k − 1 ) ( 1 − p ) k − 1 p + E ( X ) = p ( 1 − p ) ∑ k = 2 ∞ k ( k − 1 ) ( 1 − p ) k − 2 + E ( X ) = p ( 1 − p ) ∑ k = 2 ∞ [ ( 1 − p ) k ] ′ ′ + E ( X ) = p ( 1 − p ) [ ∑ k = 2 ∞ ( 1 − p ) k ] ′ ′ + E ( X ) = p ( 1 − p ) ⋅ [ ( 1 − p ) 2 p ] ′ ′ + E ( X ) = 2 ( 1 − p ) p 2 + 1 p = 2 − p p 2 \begin{aligned} E(X^2) & = E[X(X-1)] + E(X) \\ & = \sum_{k=1}^\infty k(k-1)(1-p)^{k-1}p + E(X) \\ & = \sum_{k=2}^\infty k(k-1)(1-p)^{k-1}p + E(X) \\ & = p(1-p)\sum_{k=2}^\infty k(k-1)(1-p)^{k-2} + E(X) \\ & = p(1-p)\sum_{k=2}^\infty [(1-p)^{k}]'' + E(X) \\ & = p(1-p)[\sum_{k=2}^\infty (1-p)^{k}]'' + E(X) \\ & = p(1-p) \cdot [\frac{(1-p)^2}{p}]'' + E(X) \\ & = \frac{2(1-p)}{p^2} + \frac{1}{p} \\ & = \frac{2-p}{p^2} \\ \end{aligned} \\ E(X2)=E[X(X−1)]+E(X)=k=1∑∞k(k−1)(1−p)k−1p+E(X)=k=2∑∞k(k−1)(1−p)k−1p+E(X)=p(1−p)k=2∑∞k(k−1)(1−p)k−2+E(X)=p(1−p)k=2∑∞[(1−p)k]′′+E(X)=p(1−p)[k=2∑∞(1−p)k]′′+E(X)=p(1−p)⋅[p(1−p)2]′′+E(X)=p22(1−p)+p1=p22−p故可计算
D ( X ) = E ( X 2 ) − E 2 ( X ) D(X) = E(X^2) - E^2(X) D(X)=E(X2)−E2(X)
-
-
无记忆性
推导:(从无记忆性的需求推导出变量离散情况下的概率为几何分布)
P { X > t + s ∣ X > t } = P { X > s } ⇔ P { X > t + s ∩ X > t } P { X > t } = P { X > s } ⇔ P { X > t + s } = P { X > s } P { X > t } \begin{aligned} & P\{X>t+s|X>t\} = P\{X>s\} \\ & \Leftrightarrow \frac{P\{X>t+s \cap X>t\}}{P\{X>t\}} = P\{X>s\} \\ & \Leftrightarrow P\{X>t+s\} = P\{X>s\}P\{X>t\} \\ \end{aligned} \\ P{ X>t+s∣X>t}=P{ X>s}⇔P{ X>t}P{ X>t+s∩X>t}=P{ X>s}⇔P{ X>t+s}=P{ X>s}P{ X>t}
let y ( x ) = P { X > x } y(x) = P\{X > x\} y(x)=P{ X>x}, then
y ( t + s ) = y ( s ) y ( t ) y(t+s) = y(s)y(t) \\ y(t+s)=y(s)y(t)
assume y ( 1 ) = q y(1) = q y(1)=q, therefore
y ( 2 ) = y ( 1 + 1 ) = y 2 ( 1 ) = q 2 y ( 3 ) = y ( 1 + 2 ) = y 3 ( 1 ) = q 3 . . . y ( k ) = q k \begin{aligned} & y(2) = y(1+1) = y^2(1) = q^2 \\ & y(3) = y(1+2) = y^3(1) = q^3 \\ & ... \\ & y(k) = q^k \\ \end{aligned} y(2)=y(1+1)=y2(1)=q2y(3)=y(1+2)=y3(1)=q3...y(k)=qk∵ P { X = k } = P { X > k − 1 } − P { X > k } = y ( k − 1 ) − y ( k ) = q k − 1 − q k = q k − 1 ( 1 − q ) \begin{aligned} \because P\{X = k\} & = P\{X > k-1\} - P\{X > k\} \\ & = y(k-1) - y(k) \\ & = q^{k-1} - q^k \\ & = q^{k-1}(1 - q) \\ \end{aligned} \\ ∵P{ X=k}=P{ X>k−1}−P{ X>k}=y(k−1)−y(k)=qk−1−qk=qk−1(1−q)
let p = 1 − q p = 1 - q p=1−q, then
P { X = k } = ( 1 − p ) k − 1 p ∴ X ∼ G E ( p ) P\{X = k\} = (1-p)^{k-1}p \\ \therefore X \sim GE(p) P{ X=k}=(1−p)k−1p∴X∼GE(p)
连续型
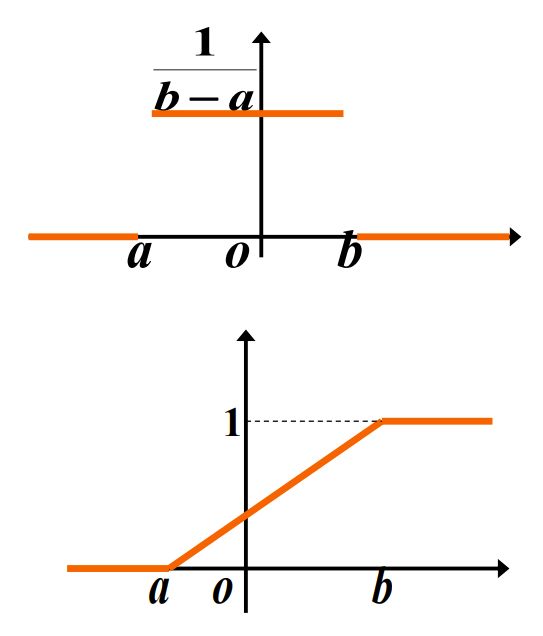
均匀分布 Uniform Distribution
X ∼ U ( a , b ) X \sim U(a, b) X∼U(a,b)
- 概率密度
f ( x ) = { 1 b − a , x > 0 0 , o t h e r f(x) = \begin{cases} \frac{1}{b-a}, & x>0\\ 0, & other \end{cases} f(x)={ b−a1,0,x>0other
- 分布函数
F ( x ) = { x − a b − a , x > 0 0 , o t h e r F(x) = \begin{cases} \frac{x-a}{b-a}, & x>0\\ 0, & other \end{cases} F(x)={ b−ax−a,0,x>0other
- 图线
-
数字特征
-
数学期望
中点
E ( X ) = 1 2 ( a + b ) E(X) = \frac{1}{2}(a+b) E(X)=21(a+b) -
方差
D ( X ) = 1 12 ( b − a ) 3 D(X) = \frac{1}{12}(b-a)^3 D(X)=121(b−a)3
-
-
背景
X ∼ U ( a , b ) X \sim U(a,b) X∼U(a,b) 时, X X X 取得 ( a , b ) (a,b) (a,b) 上某一区间内值的概率,与该区间长度成正比。
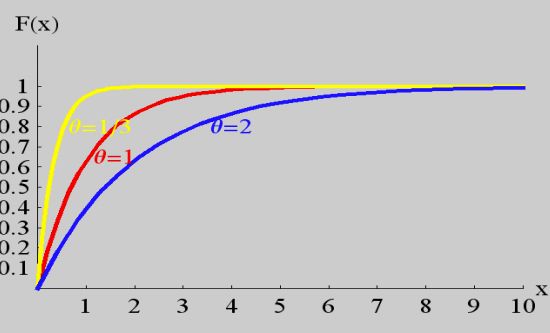
指数分布 Exponential Distribution
X ∼ E ( λ ) X \sim E(\lambda) X∼E(λ) or X ∼ E ( θ ) X \sim E(\theta) X∼E(θ)
参数是 λ \lambda λ 的表示方法是站在伽马分布的角度,把 λ \lambda λ 作为伽马分布的 β \beta β 参数, α = 1 \alpha = 1 α=1,得到指数分布 E ( λ ) = Γ ( 1 , λ ) E(\lambda) = \Gamma(1, \lambda) E(λ)=Γ(1,λ)
参数是 θ \theta θ 的表示方法是站在指数分布表达式的角度(或均值的角度),有 E ( X ) = θ E(X) = \theta E(X)=θ
- 概率密度
f ( x ) = { 1 θ e − 1 θ x , x > 0 0 , o t h e r f(x) = \begin{cases} \frac{1}{\theta}e^{-\frac{1}{\theta}x}, & x > 0 \\ 0, & other \end{cases} f(x)={ θ1e−θ1x,0,x>0other
- 分布函数
F ( x ) = { 1 − e − 1 θ x , x > 0 0 , o t h e r F(x) = \begin{cases} 1 - e^{-\frac{1}{\theta}x}, & x > 0 \\ 0, & other \end{cases} F(x)={ 1−e−θ1x,0,x>0other
-
图线
x → 0 x \to 0 x→0 时密度逼近最大值 1 / θ 1 / \theta 1/θ

-
数字特征
-
数学期望
E ( X ) = θ = 1 λ E(X) = \theta = \frac{1}{\lambda} E(X)=θ=λ1
推导:分部积分 -
方差
D ( X ) = θ 2 = 1 λ 2 D(X) = \theta^2 = \frac{1}{\lambda^2} D(X)=θ2=λ21
-
-
无记忆性
P { X > t + s ∣ X > t } = P { X > s } P\{X>t+s|X>t\} = P\{X>s\} P{ X>t+s∣X>t}=P{ X>s}
推导:(从无记忆性的需求推导出变量连续情况下的概率为指数分布)
P { X > t + s ∣ X > t } = P { X > s } ⇔ P { X > t + s ∩ X > t } P { X > t } = P { X > s } ⇔ P { X > t + s } = P { X > s } P { X > t } \begin{aligned} & P\{X>t+s|X>t\} = P\{X>s\} \\ & \Leftrightarrow \frac{P\{X>t+s \cap X>t\}}{P\{X>t\}} = P\{X>s\} \\ & \Leftrightarrow P\{X>t+s\} = P\{X>s\}P\{X>t\} \\ \end{aligned} \\ P{ X>t+s∣X>t}=P{ X>s}⇔P{ X>t}P{ X>t+s∩X>t}=P{ X>s}⇔P{ X>t+s}=P{ X>s}P{ X>t}
let y ( x ) = P { X > x } y(x) = P\{X>x\} y(x)=P{ X>x}, then
y ( t + s ) = y ( s ) y ( t ) ⇒ y ( t + s ) − y ( s ) = y ( s ) y ( t ) − y ( s ) ⇒ y ( t + s ) − y ( s ) = y ( s ) y ( t ) − y ( s ) y ( 0 ) ⇒ y ( t + s ) − y ( s ) t = y ( s ) y ( t ) − y ( s ) y ( 0 ) t ⇒ lim t → 0 y ( t + s ) − y ( s ) t = lim t → 0 y ( s ) y ( t ) − y ( s ) y ( 0 ) t ⇒ y ′ ( s ) = y ( s ) ⋅ y ′ ( 0 ) ⇒ y ′ ( s ) y ( s ) = y ′ ( 0 ) ⇒ ∫ y ′ ( s ) y ( s ) d s = ∫ y ′ ( 0 ) d s ⇒ ln ∣ y ( x ) ∣ = y ′ ( 0 ) ⋅ s + C ⇒ y ( x ) = e y ′ ( 0 ) ⋅ s + C \begin{aligned} & y(t+s) = y(s)y(t) \\ & \\ & \Rightarrow y(t+s)-y(s) = y(s)y(t)-y(s) \\ & \Rightarrow y(t+s)-y(s) = y(s)y(t)-y(s)y(0) \\ & \Rightarrow \frac{y(t+s)-y(s)}{t} = \frac{y(s)y(t)-y(s)y(0)}{t} \\ & \Rightarrow \lim_{t\to0}\frac{y(t+s)-y(s)}{t} = \lim_{t\to0}\frac{y(s)y(t)-y(s)y(0)}{t} \\ & \Rightarrow y'(s) = y(s) \cdot y'(0) \\ & \Rightarrow \frac{y'(s)}{y(s)} = y'(0) \\ & \Rightarrow \int \frac{y'(s)}{y(s)}\mathrm{d}s = \int y'(0) \mathrm{d}s\\ & \Rightarrow \ln|y(x)| = y'(0)\cdot s + C\\ & \Rightarrow y(x) = e^{y'(0)\cdot s + C} \end{aligned} y(t+s)=y(s)y(t)⇒y(t+s)−y(s)=y(s)y(t)−y(s)⇒y(t+s)−y(s)=y(s)y(t)−y(s)y(0)⇒ty(t+s)−y(s)=ty(s)y(t)−y(s)y(0)⇒t→0limty(t+s)−y(s)=t→0limty(s)y(t)−y(s)y(0)⇒y′(s)=y(s)⋅y′(0)⇒y(s)y′(s)=y′(0)⇒∫y(s)y′(s)ds=∫y′(0)ds⇒ln∣y(x)∣=y′(0)⋅s+C⇒y(x)=ey′(0)⋅s+C
let − 1 θ = y ′ ( 0 ) -\frac{1}{\theta} = y'(0) −θ1=y′(0), x = s x = s x=s, and y ( 0 ) = 1 ⇒ C = 0 y(0) = 1 \Rightarrow C = 0 y(0)=1⇒C=0, then
y ( x ) = e − 1 θ x y(x) = e^{-\frac{1}{\theta}x} y(x)=e−θ1x
or let − λ = y ′ ( 0 ) -\lambda = y'(0) −λ=y′(0), then
y ( x ) = e − λ x y(x) = e^{-\lambda x} y(x)=e−λx
so
P { X > x } = e − 1 θ x ⇒ F ( x ) = P { X ≤ x } = 1 − e − 1 θ x \begin{aligned} & P\{X>x\} = e^{-\frac{1}{\theta}x} \\ & \Rightarrow F(x) = P\{X \le x\} = 1 - e^{-\frac{1}{\theta}x} \end{aligned} P{ X>x}=e−θ1x⇒F(x)=P{ X≤x}=1−e−θ1x
伽马分布 Gamma Distribution
X ∼ Γ ( α , β ) X \sim \Gamma(\alpha, \beta) X∼Γ(α,β)

服从指数分布 E ( λ ) E(\lambda) E(λ) 也即服从伽马分布 Γ ( 1 , λ ) \Gamma(1, \lambda) Γ(1,λ) ,是伽马分布的一种特例
-
伽马函数性质
Γ ( α + 1 ) = α Γ ( α ) , Γ ( α ) = ( α − 1 ) Γ ( α − 1 ) , … \Gamma(\alpha+1) = \alpha\Gamma(\alpha), \\ \Gamma(\alpha) = (\alpha-1)\Gamma(\alpha-1), \\ \dots Γ(α+1)=αΓ(α),Γ(α)=(α−1)Γ(α−1),…
数字特征 -
-
数学期望
积分中使用 u = x / β u = x / \beta u=x/β 换元,使用伽马函数的性质,易得
E ( X ) = α β E(X) = \alpha\beta E(X)=αβ
- 方差
先积分计算 E ( X 2 ) E(X^2) E(X2) ,同样使用还原和伽马函数的性质,易得
E ( X 2 ) = α ( 1 + α ) β 2 E(X^2) = \alpha (1+\alpha) \beta^2 E(X2)=α(1+α)β2
故有
D ( X ) = α β 2 D(X) = \alpha\beta^2 D(X)=αβ2 -
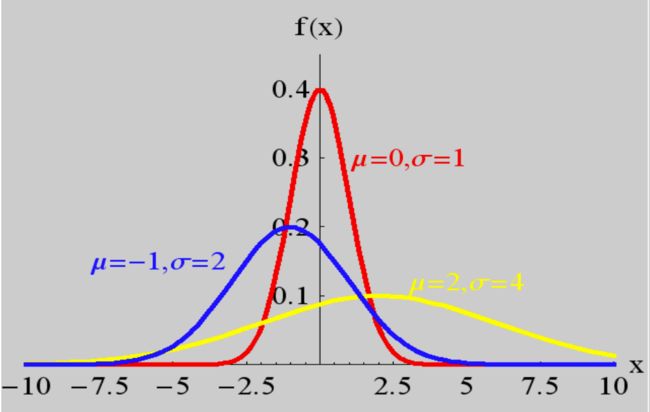
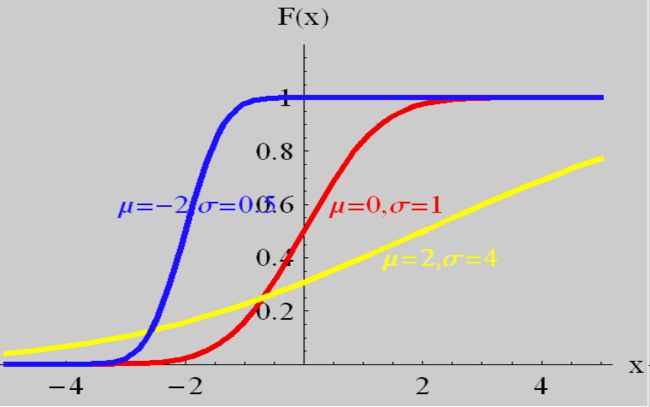
正态分布 Normal Distribution
X ∼ N ( μ , σ 2 ) X \sim N(\mu, \sigma^2) X∼N(μ,σ2)
又名为高斯分布(Gauss Distribution)。
参数 μ \mu μ (数学期望)控制分布集中位置,参数 σ \sigma σ (标准差)控制分布的离散程度(越大越离散)
- 概率密度
f ( x ) = 1 2 π ⋅ σ e − ( x − μ ) 2 2 σ 2 , − ∞ < x < ∞ f(x) = \frac{1}{\sqrt{2\pi}\cdot\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}},\quad -\infty
- 分布函数
F ( x ) = 1 2 π σ ∫ − ∞ x e − ( x − μ ) 2 2 σ 2 d x , − ∞ < x < ∞ F(x) = \frac{1}{\sqrt{2\pi}\sigma}\int_{-\infty}^{x}e^{-\frac{(x-\mu)^2}{2\sigma^2}} \mathrm{d}x,\quad -\infty
-
图线
-
标准正态分布 X ∼ N ( 0 , 1 ) X \sim N(0, 1) X∼N(0,1)
概率密度: φ ( x ) = 1 2 π e − x 2 2 , − ∞ < x < ∞ \varphi(x) = \frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}},\quad -\infty
分布函数: Φ ( x ) = 1 2 π ∫ − ∞ x e − x 2 2 d x , − ∞ < x < ∞ \Phi(x) = \frac{1}{\sqrt{2\pi}}\int_{-\infty}^{x}e^{-\frac{x^2}{2}} \mathrm{d}x,\quad -\infty
-
标准正态分布函数易知以下规律:
- Φ ( − x ) = 1 − Φ ( x ) \Phi(-x) = 1 - \Phi(x) Φ(−x)=1−Φ(x)
- P { ∣ X ∣ < a } = 2 Φ ( a ) − 1 P\{|X|< a\} = 2\Phi(a) - 1 P{ ∣X∣<a}=2Φ(a)−1
-
任一正态分布 X ∼ N ( 0 , 1 ) X \sim N(0, 1) X∼N(0,1) 通过线性替换
Z = X − μ σ Z = \frac{X-\mu}{\sigma} Z=σX−μ
都能够得到标准正态分布 Z ∼ N ( 0 , 1 ) Z \sim N(0, 1) Z∼N(0,1)
-