YOLOv1、YOLOv2和YOLOv3对比
YOLOv1、YOLOv2和YOLOv3对比
- R-CNN系列
- YOLOv1
-
- 结构
- 目标输出
- 网络训练
- YOLOv1的局限性
- 和R-CNN系列的对比
- YOLOv2
-
- 结构
- 目标输出
- 网络训练
- 关于YOLO9000
- YOLOv3
-
- 结构
- 目标输出
- 网络训练
- YOLOv3系统做过的不成功的尝试
- 未来
YOLO深度卷积神经网络已经经过原作者Joseph Redmon已经经过了3代4个经典版本(含YOLOv2和YOLO9000),俄罗斯的AlexeyAB已经完成了第4版迭代,并获得了Joseph官方认可。本文主要对前3个经典版本进行分析。
YOLOv1是2015年提出,其基本原理和创新点可参考Ross Girshick的论文《You Only Look Once: Unified, Real-Time Object Detection》(https://arxiv.org/abs/1506.02640)。
R-CNN系列
YOLOv1在设计之初主要是和Fast R-CNN进行比较,主要是YOLO系列模型是在R-CNN系列模型基础上解决其存在缺点问题提出的。
先简单介绍一下R-CNN系列,R-CNN(Region with CNN feature)顾名思义就是区域卷积神经网络特征提取方法,强调区域和卷积,当然信号检测的最终实现还离不开分类和边界回归。
先说区域R(Region),就是把一幅图先切分为S×S个网格,将小的区域网格使用SS算法(Selective search)不断的合并,然后提取特征每个小的网格的特征。SS算法不进行详细介绍,参考下图进行直观理解。

再说卷积(CNN),不同的卷积核在犹如一个个窗口,在图片上滑动,求相关性,为便于理解,姑且认为是求出的“相关度”。将不同的“相关度”反复归纳合并,最后计算出一个整体相关度。数字识别的卷积核大概只需要5、6个就可以,因为数字无非就是一些曲线、直线、交叉线的组合,第一层计算这些特征,第二层计算这些特征的组合等等。复杂的图像如人、动物等具有更多的特征,所以需要的卷积核就会比较多,特征的组合就比较多,最终网络深度也会比较深。
再说区域+卷积,就是将候选区图像标准化,使用卷积对区域特征进行判断,最后再通过更深层次的卷积层合并特征,获得最终结果。
最后再说分类与边框回归,分类+边框回归合起来完成目标检测,就是不但知道检测的结果是什么,还知道位置和尺寸大小,这样就可以得到我们经常看到的结果输出图像:先画个小框框,再打个标签,有木有觉得马上就高大上了,哈哈!分类呢,简单来说就类似于数字识别,把不同的图分成不同的数字结果,再根据排序找到相应的标签,这个会在以后详细介绍。边框回归通常就是预测出(x,y,w,h),这个方法很多,本文也不详细介绍,先挖个坑,以后再补。
以上描述的这个过程可以参考论文中的示意图,进行直观的理解。
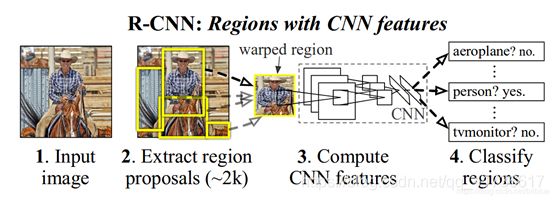
以上就是R-CNN的大体思路,可以说,合并选取的办法是符合科学的思考规律的,区域来源于“感受野”的概念,不同的感受野对应不同的区域。但是R-CNN就是因为这个感受野处理,首先需要消耗大量计算机资源进行候选区提取;其次图像归一化虽然人眼神经处理的很溜,计算机处理起来就会因为尺寸归一化问题导致计算量大大增加,同时因为分辨率的问题效果未必好;另外大量重叠的区域也会导致CNN过程重复计算。
那Fast R-CNN有什么好处呢?当然是“快”啦。和R-CNN最大的区别在于对于候选区的处理。
先来看R-CNN。尺度不同的候选区作为后续卷积网络的输入,为了与之兼容,如后续卷积网络采用 Alexnet(输入227×227), R-CNN 采用了非常暴力的手段,那就是无视候选区域的大小和形状,统一变换到 227×227的尺寸,然后进行分类,边框回归。注意哦,候选区确定的时候,其定位(x,y)已经最终确定了。那Fast R-CNN怎么处理呢?它使用了ROI Pooling层,哈哈,当然不是往RIO鸡尾酒池子放水啦。ROI是region of interest,它是根据我们感兴趣的区域将候选区图片非均匀的切分成固定的大小,每个元素的计算方法通过池化的方式,方法很简单,计算量大大减小。
Faster R-CNN速度更快,是在Fast R-CNN基础上,将选取候选区的SS算法改为RPN(region proposal net),RPN是一个全卷积神经网络。具体结构可以参考下图,这里不进行更加详细的讨论,希望了解可以参考相关文章。

可以看出,R-CNN系列模型的结构就是在进行分类之前,就确定了候选区,然后再使用卷积神经网络完成最终分类和边框回归。需要特别说明的是,R-CNN系列模型通过softmax进行分类,Faster R-CNN在RPN网络中也使用了softmax进行候选框的分类,这样就使得整个模型进行了两次检测。第一次检测判断是不是能够对应上目标类的某一类,第二次检测是判断具体是哪个类型。
YOLOv1
了解了R-CNN系列方法,我们再看看YOLO系列方法。最大的区别就是不再提前确定候选区,也就是没有了R-CNN中的“R”,通过深度卷积神经网络进行处理,所有的结果都在YOLO层一次检测成型,这就是You Only Look Once的精髓吧?哈哈,虽然这个说法是强调一个字“快”但是我还是觉得他的意思在于前面不生成候选区,也不分类,所有工作都在最后成形,眼睛“感受野”中的内容直接一次检测成型。废话不多说,我们接着往下看。
结构
YOLOv1和R-CNN一样,开始也是先把图像分割成S×S个网格,只不过这个切分没有R-CNN那么密集,毕竟不需要提前合并候选框不是?YOLOv1结构如下图:
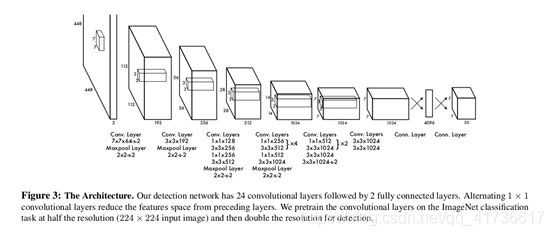
论文上说,前面的卷基层提取特征,后面的全连接层用于计算输出概率和坐标。网络主体采用24个卷基层+2个全连接层的结构。YOLOv1还有一个Fast YOLO版本,这个版本是将前面的24个卷基层裁剪为9个卷基层,其他都一样。
注意,这次我们要结合具体的模型进行讨论了。在YOLOv1的第一个模型中。输入图像都统一到448×448个像素的RGB三通道的图像上,方法嘛就是填充拉伸,长方形图像撑不满这个正方形图像的地方就用五十度灰涂上,这个具体方法以后有机会再说。根据上面的流程图,这个448(像素)×448(像素)×3(通道)的图像,进入网络后:
第一层:使用分辨率为7×7×64卷积核(步长为2),将448×448×3的图像先变为224×224×64图像;再使用分辨率为2×2(步长为2)的最大池化层,将图像变为112×112×64的图像。注意哦,卷积核的个数决定计算后图像的通道数,先挖个坑,后头专门讲darknet使用图像重排和通用矩阵乘法(GEMM,General Matrix Multiplication)方法求卷积。总之,记住卷积后的图像长宽等于原始长宽分别除以卷积步长、通道数等于卷积核个数就行了。
第二层:使用3×3×192的卷积核(步长为1),将112×112×64图像变为112×112×192图像;再使用分辨率为2×2(步长为2)的最大池化层,将图像变为56×56×192的图像。
第三层:使用1×1×128的卷积核(步长为1),将56×56×192图像变为56×56×128图像;使用3×3×256的卷积核(步长为1),将56×56×128图像变为56×56×256图像;使用1×1×256的卷积核(步长为1),56×56×256图像没有变化;使用3×3×512的卷积核(步长为1),将56×56×512图像变为56×56×512图像;再使用分辨率为2×2(步长为2)的最大池化层,将图像变为28×28×512的图像。
第四层:1×1×128的卷积核(步长为1)和3×3×256的卷积核(步长为1)先使用4次,再参考之前的方法,得到14×14×1024的图像。
第五层:得到7×7×1024的图像。
第六层:3×3×1024的两种卷积核使用后得到7×7×1024的图像。
第七层:单层全连接层,得到4096个元素。
第八层:7×7×30的全连接层,得到7×7×30个结果元素。
这就是yolov1结构,共24个卷基层,从第一层到第八层:1+1+4+(2×4+2) +(2×2+2)+2=24。
目标输出
YOLOv1的目标输出为7×7×30个结果,什么意思呢。7×7输出层包含对应448×448原始输入平面对应位置经过64倍缩放和特征提取,每个相应区域能够检测出来的结果。这是一个30维的张量,前10个维度分2组,分别用于检测(注意是“用于”而不是直接“输出”)2个目标置信度confidence、中心的坐标(x,y)、边框(w,h)。后面20个维度用于20中目标的分类。简而言之,YOLOv1的检测能力是一个区域内在20种目标中检测出2个结果。
前面说“用于”而不是输出,是因为还要通过一定的计算公式计算出相应的结果。YOLO和其他模型不同的是,边框回归值并不是直接预测出来坐标和尺寸,而是坐标预测一个0到1之间的偏置值,边框尺寸预测一个0到1的相对值。这个关于目标检测计算的原理这里挖个坑,后面结合代码再说。
网络训练
YOLO系列的模型训练其实是两步训练的,卷积层的初始参数通过ImageNet 1000-class,使用前20个卷基层+平均池化层+一个全连接层的模型进行预训练。后面新增的权重都采用随机生成的方式,用户可以根据自己实际的数据集需求使用YOLO网络,用YOLO预训练的weight文件进行训练。预训练不在我们讨论的范畴,拿来直接用就行了,我们这里讨论YOLO模型本身的训练。
训练的过程当然还是使用反向传播,无论哪个版本的神经网络反向传播原理都是一样的,关于反向传播的具体方法和代码解读这里也挖个坑,后续有机会再说。为了说明不同的版本的YOLO模型的差异,这里重点讨论LOSS函数。
LOSS函数就是损失函数,有时候也叫做代价函数。在YOLOv1中损失函数见下图。
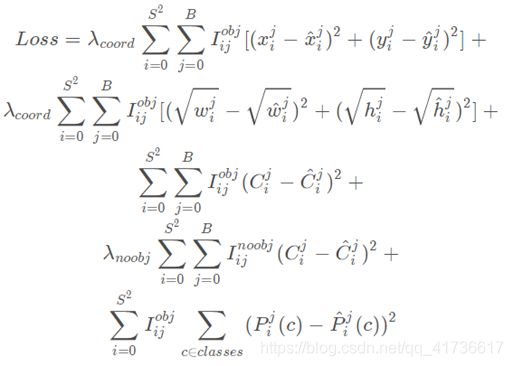
关于这个LOSS函数,我们说几个点:
1.采用平方和误差
2.由于需要均衡不同输出值得数量级和大小对整个LOSS函数的影响,首先,使用了λcoord =5和λnoobj=0.5进行调节;其次宽高计算平方根的误差,而坐标直接计算误差(因为坐标是偏置值,普遍比宽高要小);再次,计算confidence时候,同时计算有目标和无目标的误差。
3.计算分类时候,只计算有目标的条件下的分类的准确性。
4.公式中 表示有物体中心落入的cell,需要计算分类损失,无目标就置0,通过这种方式减少运算量。
总之这个LOSS函数设计的也是煞费苦心,至于λ设置是不是最优,这个很难说,但是应该是一个比较优异的设计。
根据这个LOSS函数,再进行求导,反向传播,调整weight。
YOLOv1的局限性
1.YOLOv1每次只能检测1个类别,两个目标。
2.成群的小目标无法预测。
3. YOLOv1对于大尺度目标效果不错,但是小目标效果欠佳。因为小目标有一点小偏差,其相对误差就会很大,大目标相反。
4.图片长宽比和设置特殊的条件下效果就差一些,比如窄条图像,效果不好。
和R-CNN系列的对比
目标探测是计算机视觉的核心问题,首先都是先进行特征提取,如使用Haar,SIFT,HOG,卷积特征提取等,然后分类器和定位器开始使用滑窗(三十年前雷达信号处理就是这种方法,还有脉冲积累,和图像多层次累积的方法太相似了)或者图像子区域等方法进行处理。
YOLO和R-CNN其实有很多相似之处,首先都是对原始图像划分网格,每个网格又表征一些图像特征,但是YOLO划分的网格要比R-CNN系列少的多,合并后的区域也只有一个最终目标的区域。Fast R-CNN和Faster R-CNN速度更快,但是效果有较大差距。和其他模型相似度更低的模型的比较可以参考YOLOv1的论文,这里再讨论。
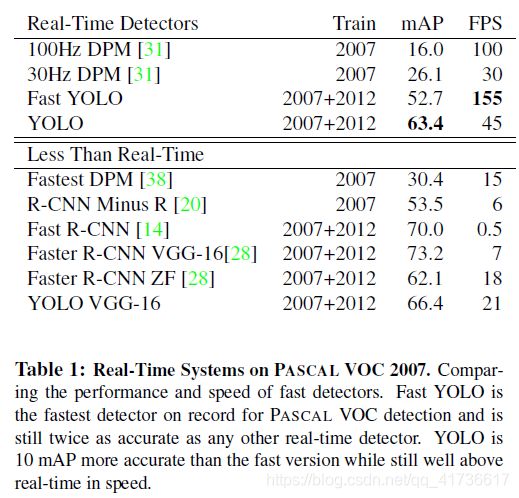
mAP(mean Average Precision)就是每一类平均精度AP(Average Precision)的均值。AP就是对PR曲线(P:precision,R:recall,横轴R,纵轴P)求均值。具体评价体系先挖坑,总之就是考察目标命中率、命中正确率的综合指标。FPS (Frame Per Second)每秒帧率,就是每秒可以处理的图片数量。对于同一个模型,修改设置,这两个指标相互妥协,但是考虑不同模型之间,YOLO具有综合优势。最暴力的理解方式就是把mPA和FPS相乘看哪个大,一般就可以判断出来啦。
另外还有一个对比图
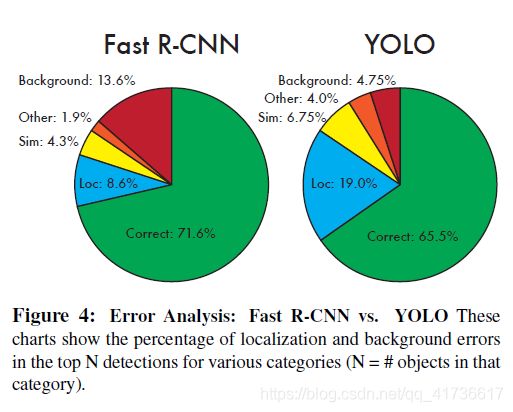
关于这幅图,大家自己看。有个问题不吐不快,当研究出一个新的模型的时候,往往都会有一些妥协的因素在里面。国内学术界往往有一个很不好的习惯,就是是个创新就要全方位比别人优越百分之多少,其实参考这个YOLO,和Fast R-CNN相比,速度就是绝对优势,正确率和同类系统持平就是最大创新。都给你穿刘翔的红魔了,还要什么自行车?
YOLOv2
YOLOv2论文是Joseph Redmon在CVPR 2017获得 Best Paper Honorable Mention的作品,名称《YOLO9000: Better, Faster, Stronger》,首先在YOLOv1基础上改进得到YOLOv2,在COCO检测数据集和ImageNet分类数据集上训练出了YOLO9000模型,其可以检测超过9000多类物体。在保持一惯性的优良速度上,提高了mAP。
上一节我们说到,YOLOv1和R-CNN相比,速度快,但精度下降。到了YOLOv2提出了几个改进策略。
结构
这次的模型的基础分类结构叫做Darknet-19,包括19个卷积层、5个maxpooling层、1个全局Avgpool层,一个softmax分类激活层,如下图所示。

遵循上一节的思路,我们把它分为8个大层。为了和前面描述保持一致,具体描述可参考配置文件darknet19_448.cfg。上图从论文中截取,论文中使用的是224×224的输入,这个都没有很大关系。
每一层具体有什么,输出多大,估计读者已经很熟悉了,参考YOLOv1这里不再啰嗦,需要注意的是第六层:5个卷基层、无池化层;第七层:1×1×1000(步长为1)的卷基层+全局平均池化,得到1000个输出;第八层:softmax分类激活层,得到最终结果。YOLOv2已经没有了4096个输入的全连接层。这个darknet19输出只有分类,具体如何得到估计结果,可以参考yolov2.cfg和yolov2-voc.cfg。
这里以yolov2.cfg描述的结构为例进行进一步说明(这里输入为608×608)。
这里第七层、第八层由region探测模块代替:一个卷积+1000输出的全局平均池化改为3×3×1024(步长为1)的卷基层+3×3×1024(步长为1)的卷基层+route层(往前追溯9层后拿过来累加)+1×1×64(步长为1)的卷基层+reorg层(步长2)+route层(往前追溯1层和4层后拿过来两层累加)+1×1×425(步长为1)的卷基层+region层。
好了,除了整体上结构组成和YOLOv1相比有变化,还有哪些优化呢?下面简单介绍一下,关于源码解析,也挖个坑。
- batch_normalize层
在每一个卷积层的实现中增加了一个batch_normalize层。这个层的主要用处就是防止梯度爆炸和梯度消失。YOLOv1总共只有24个卷积层,到了YOLOv2其实也是24个卷基层,和yolov2和darknet19共同的结构也是前面19个卷基层+5个最大池化层。这时候相比较YOLOv1这个功能还不太明显,但是到了YOLOv3中的darknet53,甚至YOLOv4,这个功能的效果就很明显了。
那么是怎么防止梯度爆炸和梯度消失的呢,计算梯度需要计算误差,反向传播过程中误差也在反向传播,根据反向传播原理会有累加和累乘效应,如果每一层的误差计算不加以控制的话,梯度的增量会逐渐消失或者变成无限大。batch_normalize就是按批次(batch)进行归一化,控制反向传播过程中这种问题。
具体思想要结合随机梯度下降(SGD)的理念来说,把每一层都当做一个联合概率函数,整个系统累乘就是一个巨大的联合概率函数, 元素就是每一层的输入,再在每一层进行归一化的时候,把一个batch的元素放在一起求均值和方差,用计算的元素减去均值再除以方差,就是归一化。执行的时候,为了防止改变概率分布特征,需要对归一化的结果加上尺度变换(scale)和偏置(offset)。 - route层
增加了2个route层。
先说第1个,这个route层往前追溯9层,就到了最后一个maxpool层之前的一层,如果输入是一个608×608的图像。到了这一层,输出就是一个38×38×512的l.output(代码中每个layer结构中都定义了output变量,l.output表示layer变量l中的output,这里这样描述感觉会让读者潜移默化的了解代码,会比较方便,尝试一下哈)。
再说第2个,将reorg层的l.output和第七层中的3×3×1024(步长为1)的卷基层的l.output拿过来,放在一起,这两个l.output的尺寸(l.w×l.h×l.channels)分别是19×19×256和19×19×1024。
那么route层干什么呢?route就是路由,简单的说就是将指定层的输出拿过来放在本层中,如果是多层,就接续放在后面。如果是多层,有一个关键的规则就是这两层的尺寸宽×高(l.w×l.h)必须一样,否则就把l.w和l.h都归零。
由于YOLO是一次检测,特征提取顺序进行,不断的进行卷积卷积再卷积,然后还要池化,卷到最后就可能会有一些信息糊到一起了,很对细节的信息越往前越清楚,越往后分类越清楚,可是坐标啊、图像尺寸啊,就慢慢模糊了。为了进行平衡,需要把前面的信息拿过来和后面的信息混在一起用一用。怎么办呢?就路由一下吧。上一节讨论过妥协,route层使得YOLO不再是纯粹的“你只看一眼”,到后头你还要往前多看两眼,调整一下得到的结果,然后提高了预测准确度。 - reorg层
reorg层的作用是将上一层卷积后的特征图38×38×64 拉伸成19×19×256,步长stride=2就相当于l.input中以每2×2为一个单位拆分到4层,和池化层相比的好处就是不会把2×2中的内容糊到一起,当然,个人觉得使用池化再把池化后的l.output复制4次效果可能也差不多,但是在路由的时候会失掉一些细节,那路由的意义就下降了。 - region层
需要说明的一点,在darknet软件框架中,将YOLOv1的探测层定义为detection,将YOLOv2的探测层定义为region,将YOLOv3的探测层定义为yolo。功能都是用于生成最终的输出结果。
YOLOv1的detection使用的是全连接层,而YOLOv2的region层使用softmax进行分类,使用了anchors进行边框回归获得边框坐标和尺寸。
目标输出
以coco数据集为例,最后一层输出最后一层维度是425,表示可以最多检测80个种类,同时检测5个目标,5*(80+5),输出卷积层l.output是一个425个通道的张量。
注意,这里使用了Anchor boxes,这个玩意就是先验框,提前使用K-means聚类算法,将各种不同的目标聚类成5大类。在region层实现探测的时候,选择最接近的一个,计算目标尺寸和先验框的比值。
这里就很自然的引出来YOLOv2的边框回归计算坐标和目标尺寸的思想。其实在R-CNN系列模型中就已经使用了边框回归了,当然,具体方法有所区别,大体思路还是一致的。
先给一个论文中的新鲜截图
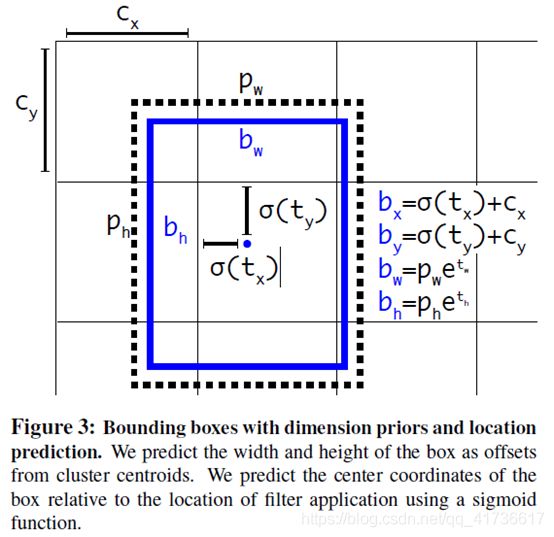
边框回归需要处理的输出就是(tx,ty,tw,th)。公式如下

理论上可以使用一定的公式方法σ(t)先处理一下,当tx<0,,就直接置0,代码实现中使用sigmod函数(LOGISTIC),针对每个预选框前两个输出平面使用激活函数。tw和th之所以需要计算幂值,是因为tw和th实际上是预测宽度和高度与真实值(truth.w和truth.h)的比值,为同样为了防止由于误差过大导致梯度爆炸或梯度消失退,这个比值取了一个log。有说法是根据极限定理,当tw->truth.w,两个值是有线性关系,可以进行线性回归。本人对此不是很认同,解释有点牵强附会。
另外,关于置信度见以下公式
![]()
输出结果中,score,也就是to,也是使用了sigmod函数的。这里面IOU就是预测结果和真实目标(GT,ground truth)的交并比(Intersection-over-Union),说白了,就是两个图像区域的交集和并集的比值。区域重合度越高,说明预测的边框越准确,这个IOU属于区间[0,1),为啥说不可能为1呢?因为你能够计算出1,就是过拟合,你的模型泛化能力就太差了。
关于这个Pr(object)目前没有查到具体的解释,论文中也没有明确的解释,如果以后弄明白了再更新。但是根据本文所需理解的内容,这个公式基本用不到。
网络训练
方法和YOLOv1相同,这里重点看LOSS函数。YOLOv2比YOLOv1的LOSS函数更加复杂。

W和H是先验框宽和高,在YOLOv1中使用了S×S。A表示先验框数目,这里是5,前面在说配置文件的时候中也提到过。
第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差。
第二项是计算先验框与预测框的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状。
第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。先说一下匹配原则,对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值(YOLOv2中bias_match=1),计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。在计算obj置信度时,在YOLOv1中target=1,而YOLOv2增加了一个控制参数rescore,当其为1时,target取预测框与ground truth的真实IOU值。对于那些没有与ground truth匹配的先验框(与预测框对应),除去那些Max_IOU低于阈值的,其它的就全部忽略,不计算任何误差。这点在YOLOv3论文中也有相关说明:YOLO中一个ground truth只会与一个先验框匹配(IOU值最好的),对于那些IOU值超过一定阈值的先验框,其预测结果就忽略了。这和SSD与RPN网络的处理方式有很大不同,因为它们可以将一个ground truth分配给多个先验框。尽管YOLOv2和YOLOv1计算loss处理上有不同,但都是采用均方差来计算loss。另外需要注意的一点是,在计算boxes的和误差时,YOLOv1中采用的是平方根以降低boxes的大小对误差的影响,而YOLOv2是直接计算,但是根据ground truth的大小对权重系数进行修正:l.coord_scale * (2 - truth.w*truth.h),这样对于尺度较小的boxes其权重系数会更大一些,起到和YOLOv1计算平方根相似的效果(参考YOLO v2 损失函数源码分析)。
最终的YOLOv2模型在速度上比YOLOv1还快(采用了计算量更少的Darknet-19模型),而且模型的准确度比YOLOv1有显著提升,详情见paper。
关于YOLO9000
YOLO9000是在YOLOv2的基础上提出的一种可以检测超过9000个类别的模型,其主要贡献点在于提出了一种分类和检测的联合训练策略。
众多周知,检测数据集的标注要比分类数据集打标签繁琐的多,所以ImageNet分类数据集比VOC等检测数据集高出几个数量级。在YOLO中,边界框的预测其实并不依赖于物体的标签,所以YOLO可以实现在分类和检测数据集上的联合训练。对于检测数据集,可以用来学习预测物体的边界框、置信度以及为物体分类,而对于分类数据集可以仅用来学习分类,但是其可以大大扩充模型所能检测的物体种类。
作者选择在COCO和ImageNet数据集上进行联合训练,但是遇到的第一问题是两者的类别并不是完全互斥的,所以作者提出了一种层级分类方法(Hierarchical classification),主要思路是根据各个类别之间的从属关系(根据WordNet)建立一种树结构WordTree。
这部分内容读者有兴趣可以专门研究,本人在将来有时间且搞明白的时候也会努力写一写。
YOLOv3
YOLOv3依然是在YOLOv2的基础上,可参考的论文《YOLOv3: An Incremental Improvement》,文章很简单,作者也说这是个工作报告,把其他的一些文章中的有价值的内容尝试一下。
结构
YOLOv3在YOLOv2的基础上拓展成darknet53,算是比较大的了。先上结构图。

Darknet53就是指52层卷积层+1个全连接层(通过1x1卷积实现)。相比较YOLOv2,YOLOv3再也没有了maxpooling层,没有了reorg层,相比多了residual层,结构上采用了多分辨率的方法,设置大、中、小三个不同尺度的YOLO层。上图和描述YOLOv2的结构图一样,只描述了一个分类结构,参考yolov3.cfg和yolov3-voc.cfg配置文件,代替Avgpool后面内容的是3个并联的yolo层,并联的实现是通过route层。上图。
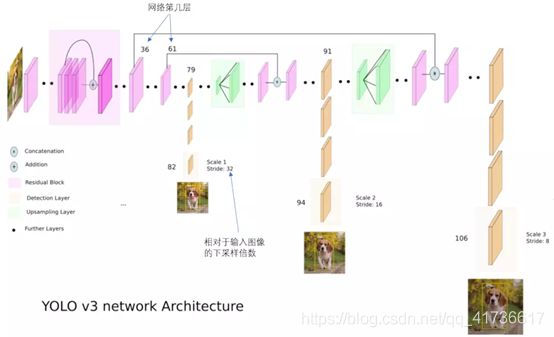
这个图是我在网上看到的最详细的结构图,粉红色为特征提取层,橘色为检测层,绿色为上采样层。其实在配置文件中是52个卷积特征提取层和23个residual(配置文件中为shortcut)之后,先经过(7个卷基层+1个yolo层构成的)8层大尺度检测模块,接着是(1个route层+1个卷基层+1个upsample层+1个route层+7个卷积层+1个yolo层)的12层中尺度检测模块,最后是和中尺度类似结构的12层小尺度检测模块,共107层。
下面说说新增的residual层和upsample层。
- residual层
先说说residual层的产生背景。前面说过,深度神经网络就是一个巨大的联合概率分布,参数越多,提取的特征越多。你可以横向把单个层做的很宽,也可以往深里面做。做的宽没有累乘效应,实现相同的效果参数就会指数增加,往深里做就可以以节约参数,更重要的一点是可以不断抽象、抽象、抽象,可以变得适应性更强。但是往深里走也有坏处,第一个问题是,累乘多了,就会梯度爆炸和梯度消失,前面说归一化的时候已经讨论这个问题了。第二个问题就是网络退化,梯度问题是反向传播的问题,网络退化是凡响传播和前向传播共同的问题。为啥退化呢?这个有点类似于采购与供应链管理中的“牛鞭效应”,一个是就是误差积累,每一层都有误差,通过卷积累乘累加之后误差到牛鞭末梢就会很大;另外,层次越多,“牛鞭”越长,往往前后难以兼顾,训练就很困难。
怎么办呢?ResNets就诞生了,ResNets叫残差网络。残差,顾名思义就是回归运算中估计值与真实值的差,残差网络基本原理就是训练的卷基层不再针对本身输出的结果,而是训练一个残差。前面说过,为了保证网络不过拟合,拥有较好的泛化能力,残差就不可避免,我们这里是将残差训练到最小。
于是,在YOLOv3中,加入了residual层用来实现残差网络。residual层也叫shortcut层,听起来就是个捷联层或者短路层。谁和谁短路呢?一般是将前面若干层的输出直接引到当前层的输出层。但它和route层有个很大的区别,就是route层只是将前面层的输出拿过来放在当前输出的存储空间后面,下一层一起处理这两个层的信息,但residual层就直接用来和当前输出相加,再通过激活函数输出。具体结构见下图,shortcut层就是那个加法结构。
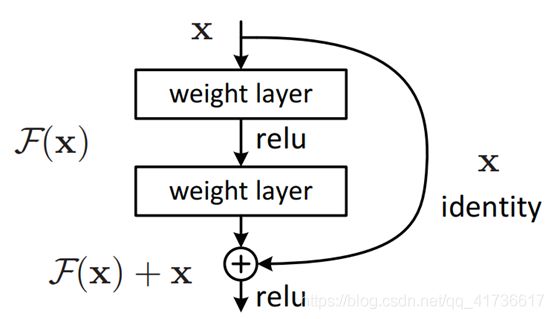
假如没有残差层,以上模块输入为x,输出为H(x),我们优化的目标是H(x)。有了残差层,H(x)=F(x)+ x,残差就是F(x)= H(x)-x,只要把F(x)训练到一个足够小的合适的值,H(x)就会更加接近理想的输出。这里面有两方面原因:
第一,如果一个数据集条件下(注意,不同的数据集对网络配置的需求也不一样,就好像打游戏的人买手机和不打游戏的人买手机需求不同类似)深度神经网络前面的层已经训练饱和,后面的训练其实就不再需要,冗余的配置可以通过残差网络抵消,不使用残差网络就需要把后面几层训练成“恒等映射”,没有约束的条件下随便几层网络是训练不成的。
第二,当非残差层将网络训练到近似可用的条件下,残差网络模块就是一个调优器。用过示波器的朋友们都知道,示波器有一个“粗调”旋钮和一个“细调”旋钮,粗调和细调的步进值不同。训练过程就像一个调节的过程,改变相同的参数幅度,F(x)和 x调节的效果不同。另外,有实验证明残差模块组成需要两层以上,单层的并不起作用。 - upsample层
这个层和上面的reorg层功能有点类似,reorg层是在某一层l.output单个输出特征平面尺寸l.w×l.h比route层拿过来的其它层l.w×l.h尺寸大的时候,把当前的l.output像弹簧圈一样拉细拉长。upsample正相反,用于在route的时候要扩大特征平面,不同通道的内容代表不同的特征,这辈子压扁是不可能了,就只能用每个点的分身去周边填充,吃个虚胖再说。
神经网络越深,不是特征平面越小么,YOLOv3怎么还要增大呢?大家肯定没有忘记,咱们的YOLOv3是分了大、中、小单个尺度。先计算大尺度,大尺度特征比较粗线条,卷积后的特征图肯定是要糊啊,要缩小尺度提高检测精细程度,就要把前面没有糊的较大的特征平面拿过来路由在一起,但是尺寸有不一样,只能打肿脸充胖子。当然说打肿脸也不全对,因为就像发酵的酵母,拿过来一点和新鲜面粉和在一起,可以提高三个尺度检测的一致性,虽然并不是经常都能一致,甚至大尺度有些目标东西根本就检测不出来。 - yolo层
YOLO系列作者挺有意思,v1输出层叫detection层,v2输出层叫region层,v3输出层叫yolo层,也许真的认为v3已经修炼成功了。
看配置文件,共有三个yolo层,配置都一样,唯一的区别就是mask序号不一样,mask对应这一层使用的anchor。从结构上,每层都就简单多了,没有了softmax分类器。
yolo层每层对应3个聚类好的anchor box,尺度一看也可以看出来。anchor预先确定的尺寸是相对整个网络输入层而言的,在训练的时候先确定使用3个框中使用哪个,然后对照训练预测宽高和anchor box宽高的比值。
目标输出
每个yolov层的目标输出为255个通道,255个通道表示可以同时输出80个类别中3个类别的目标,输出结果中每组前5个通道是(x,y,w,h,score),后80个通道是80个类别,一共(4+1+80)×3 = 255。另外,按照darknet中的配置,每个图最多可以显示90个目标,万人大会做不到,有木有感觉有点少。
其他目标输出的检测原理和YOLOv2都是一样的。
网络训练
关于YOLOv3的损失函数,先上公式。

这个公式有4点需要说明:
1.公式是从YOLOv1、YOLOv2演变过来的,使用了二分交叉熵损失,但不再单独区分background,不再使用基于softmax的多分类损失函数。在配置文件中不再专门配置各种λ系数,实际上全都取了常数1。
2.比较有争议的一点是在darknet的实现中,使用了MSE损失函数代替交叉熵损失函数,一种解释是对于Logistic回归,正好方差损失和交叉熵损失的求导形式是一样的,作者这里直接用方差损失代替了,因为数值趋势上是一样的。(可参考https://blog.csdn.net/jasonzzj/article/details/52017438)
3.边框信息损失会乘一个(2-w×h)的比例系数,w 和 h 分别是GT的宽和高。这是为了提升针对小物体预测准确度的一个小技巧,对于w,h<1,如果w,h越小,(2-w×h)越大,这部分权重就越大,误差产生的影响就可以进一步放大,有人做实验针对 YOLOv3,如果不减去 wh,AP 会有一个明显下降,如果继续往上加,如 (2-wh)*1.5,总体的 AP 还会涨一个点左右(包括验证集和测试集)。
4.在代码中计算class的误差有一个是否为0的判断,主要是因为由于不同尺度输出平面每个元素对应网络输入至少8×8的像素面积,在同一个位置可能会预测到多个目标,如果判断为0,就可以转入下一个预测框中。这部分可以看代码(https://blog.csdn.net/jiyangsb/article/details/81976090)中也有说明,写得更详细。
YOLOv3系统做过的不成功的尝试
作者在论文中专门介绍了实验过程中不成功的尝试,这是很新颖的,这里也罗列一下:
1.Anchor box 坐标偏移量预测。作者尝试通过常规的Anchor box预测机制,将坐标偏移量预测为边界框宽度或高度的倍数,激活函数使用linear函数。但是降低了系统的稳定性,效果也不好。
2.使用linear激活函数代替logistic来预测坐标,这种方式导致mAP的下降。其实很佩服的一点是YOLOv3取消了池化层、softmax层、全连接层,已经把卷积神经网络弄得足够简单,但是想把激活函数也去掉(linear激活就相当于不用激活),看来是不行,作者的反叛精神可见一斑。
3. focal loss。下面是focal loss的公式:
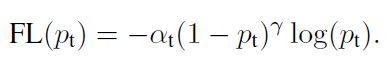
这里不详细讨论,介绍一下背景,方便我们感知目标检测的现状。首先,Lin等人回顾了一下目前目标检测的发展概况,先进的目标检测算法目前大概分成两种,一种是one-stage的,一种是two-stage的。one-stage的代表作YOLO以一种简单统一的网络成功实现了实时检测的目的,但是它的准确率并不是best。相反的,two-stage的代表作RCNN系列则是在准确率方面完胜其他模型,但是它的检测速度真的是慢的有的可怜(相比于YOLO)。 于是,Lin他们就开始研究造成这种现象的原因,接着他们就发现原来是在训练的时候,后景数据相比于前景数据较少的缘故。为了解决这个问题,Lin等人对标准的交叉熵损失函数进行修改,降低那些已经分类很好的样例对loss的影响比重,称之为Focal Loss,也就是会特别关注某一些loss的意思。 最后,Lin等人实现了一个使用Focal Loss的简单的检测系统,最终在速度上几乎赶上了YOLO,并且在准确性了超过了现有的所有检测算法。
其实吧,YOLOv3不再专门检测背景数据是再次提升速度的一个原因,天下没有免费的午餐,想要精度就要牺牲速度,Faster R-CNN也没有必要继续追求快,“快”这个字交给YOLO就好了,未来硬件水平提升了,还能更快。作者也说了,对于focal loss想要解决的问题,YOLO已经做得很好了,这个尝试方向确实有很多不确定的东西。
4.双IOU阈值和真值分配。Faster R-CNN训练时候使用了双IOU阈值。双IOU的意思是如果预测框和GT框的IOU>0.7,则为正样本,0.3到0.7之间忽略,<0.3认为是负样本,实际效果并不好。
未来
写这篇文章,是想从R-CNN开始,梳理了一下YOLOv1、YOLOv2、YOLOv3,便于下一步更加清楚的理解YOLOv3的实现和后续。YOLOv4已经由Alex提出,本质上继承了YOLOv3的结构,加了更多目前的新的用途的trick。YOLOv4主要还是面向工业级的应用,在TensorFlow、pytorch、caffe等框架中都在应用,不同版本的实现各有不同,本质上都是相同的。目前的报道上PaddlePaddle也有了YOLOv3的实现,而且PaddlePaddle这两年受欢迎度蹿升的很厉害,不知道PaddlePaddle版本的应用未来会怎样,我们拭目以待。