机器学习读书笔记之7 - 分类方法梳理
在介绍具体分类方法之前,先来明确两个概念,过拟合(OverFit)与欠拟合(UnderFit),这是在分类器训练,包括神经网络训练中都会遇到的问题。
过拟合 一般是训练了一个分类器,对于训练及测试样本分类近似100%,但实际分类效果却很差,究其原因在于也许数据本身更符合二次特征,由于噪声导致采用更高次函数模拟,或者参数迭代次数过多导致,解决方案是选择合适的参数个数、交叉样本验证或者设置一个有效的停止机制。
欠拟合 一般是指分类器本身的训练不到位,或者说无法收敛到一个比较好的极值点,产生的主要原因在于样本的数量或者说可分性不够。
• KNN
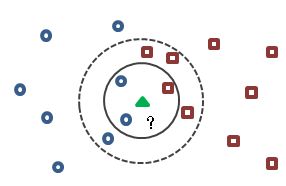
K-近邻(K-NearestNeighbor)算法是最简单的一种分类算法,将所有样本作为分类依据,对于一个新的数据,计算与其距离最近的K个邻居,根据K个样本的标签进行投票,得到其分类类别。
不同的K值会影响对应三角形的分类,如上图所示,当K=3时,类别判定为圆形,当K=5时,判定为矩形。
经常容易与KNN混淆的是K-Means算法,K-Means是一种非监督的聚类算法,初始化过程设置K个初始中心点(对应K类),迭代过程将样本按照距离分配到对应中心点并计算新的中心点,重复迭代过程直到收敛。
• SVM
通俗来讲,支持向量机(supportvector machine,简称SVM)是一种二分类模型,其定义在于通过一个向量模型判断特征向量的类别,非此即彼。
线性分类的实例是对SVM最好也是最简单的解释。
两类划分并不是困难的问题,直观上看,分割的间隙越大越好,这样两个类别的点可以分得比较开。虚线也能够将样本分开,但显然不是最优划分,那么我们可以把SVM定义为求解最优划分问题(上面图示的黑色实线)。在SVM中,称为Maximum Marginal,是SVM的一个理论基础之一。选择使得间隙最大的函数作为分割平面是有道理的,新的判别点落在可分域内的概率更大,具体证明这里就不展开讲,仅作为一个结论。
• 朴素贝叶斯
贝叶斯 是从统计概率的角度来进行分类,也就是条件概率。

• 决策树
决策树 是最接近我们思维逻辑的判别方式,if-then-else的二叉树风格是程序员的最爱。
决策树训练过程可以描述为:
1)从根节点开始训练,从M维特征中无放回的选择m维特征,从中选择分类效果最好的一个特征F,计算阈值Th,为小于Th的样本建立左节点,其余为右节点;
2)重复节点分裂过程,直到终止条件(样本数量或深度),得到叶节点,定义输出为对应样本集中最多的一类Cj,概率为Cj在样本集的占比。
决策(分类)过程非常好理解,我们通过一个图例来进行说明。
可以看到,决策树本质是一个树结构,每个中间节点通过一个逻辑判断来进行下一步决策。
决策树的优点在于:
1)模型简单,易于理解和解释;
2)数据简单,不需要统一的数据格式,在相对短的时间内能够对大型数据源做出可行且效果良好的结果;
3)易扩展,可以对有许多属性的数据集构造决策树,决策树可很好地扩展到大型数据库中,同时它的大小独立于数据库的大小。
缺点在于:
1)对于各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征;
2)决策树处理缺失数据比较困难,而且容易出现过度拟合的问题;
3)决策方式单一,忽略了数据集中属性之间的相关性,某些情况下会导致决策失败。
• AdaBoost
Adaptive boosting(AdaBoost)是提升树(boosting tree)算法的一种,所谓“提升树”就是把“弱分类算法”提升(boost)为“强分类算法”(见《统计学习方法》)。
可以将其解释为“三个臭皮匠,顶个诸葛亮”,AdaBoost核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器。“总结也是创新,就靠加权平均”其实也是我们写Paper的一个大类思想。
对于AdaBoost,可以说名声在外,在Deep Learning之前,SVM和AdaBoost几乎是是应用最多、也是效果最好的两个分类算法。

AdaBoost算法不需要预先知道弱分类器的误差,这点与Boosting算法不同,最后得到的强分类器的精度依赖于所有弱分类器的分类精度,这样可以深入挖掘弱分类器算法的能力。

从上面步骤可以看出,AdaBoost核心思想在于利用样本值逐层迭代,上一层的分类结果将会影响下一级的权值调整(上图右上箭头),如果一个训练样例在前一个弱分类器中被错分,那么它的权重会被加重,作用于下一个弱分类器,相应地,被正确分类的样例的权重会降低。
• GBDT
GBDT 是一种基于决策树的分类回归算法,全称为GradientBoosting Decision Tree。
把它拆成三个部分来理解 - Gradient | Boosting| Decision Tree:
Gradient是指梯度下降,在求目标函数最小化的时候,作为一阶优化方法,沿着负梯度方向能够快速收敛,这个应该不用多说。
Boosting作为模型组合方式,对多个子树的结果进行叠加,得到最终分类(回归)结果。
Decision Tree在这里是指回归树(RegressionTree),原因是分类树无法通过Boosting进行叠加,因此GBDT有时也称为GBRT。
Gradient Boosting采用迭代的方式,与Adaboost的区别在于每一次迭代输入是上一次的残差(residual),在残差的梯度方向建立一个新的模型。

• 随机森林
随机森林(RandomForest)是包含多棵决策树的一种分类器,采用“三个臭皮匠,顶个诸葛亮”的策略,多个决策树之间没有关联,通过投票的方式得到最终分类结果。
所谓“随机”体现在构造过程的两个方面:
1)每个决策树的训练是通过对样本进行有放回的抽样得到,即每棵树都不是通过全部样本得到(类似CNN的DropOut),不会产生过拟合;
2)训练每棵树的节点时,使用的特征是从所有特征中按照一定比例随机无放回的抽取,从中选择分类最好的一个特征进行分类。
随机森林取得了非常好的分类结果(数据集表现良好),其优点体现在:
1)算法简单,训练速度快,可以并行实现;
2)训练完后,能够区分哪些特征比较重要;
3)能够处理高维度数据,并且不用做特征选择。