金融风控训练营TASK03学习笔记
金融风控训练营TASK03学习笔记
- 学习知识点概要
- 学习内容
-
- 1、特征工程的概念和重要性
- 2、数据处理常见操作
- 3、异常值处理
- 4、特征编码
- 5、数据分桶、特征交互以及特征选择
- 学习问题与解答
-
- 1、模板修改
- 2、 比赛文件的生成
- 学习思考与总结
本学习笔记为阿里云天池龙珠计划金融风控训练营的学习内容,学习链接为:https://tianchi.aliyun.com/specials/activity/promotion/aicampfr
学习知识点概要
- 特征工程的基本概念
- 特征工程的操作流程
- 对代码的学习和修整
- 正确格式文件的生成
学习内容
1、特征工程的概念和重要性
业界广泛流传这样一句话:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”,由此可见特征工程在机器学习中的重要性。具体来说,特征越好、灵活性越强,构建的模型越简单、性能越出色。
- 概念:特征工程就是从原始数据提取特征的过程,这些特征可以很好地描述数据,并且利用特征建立的模型在未知数据上的性能表现可以达到最优(或者接近最佳性能)。
- 特征工程一般包括特征使用、特征获取、特征处理处理、特征选择和特征监控。
- 特征工程的处理流程为首先去掉无用特征,接着去除冗余的特征,如共线特征,并利用存在的特征、转换特征、内容中的特征以及其他数据源生成新特征,然后对特征进行转换(数值化、类别转换、归一化等),最后对特征进行处理(异常值、最大值、最小值,缺失值等),以符合模型的使用。
简单来说,特征工程的处理一般包括数据预处理、特征处理、特征选择等工作,而特征选择视情况而定,如果特征数量较多,则可以进行特征选择等操作。
2、数据处理常见操作
- 首先是task02讲到的将特征分为数值型与类别型两类:numerical_fea(数值型)、category_fea(数值型)
numerical_fea = list(data_train.select_dtypes(exclude=['object']).columns)
category_fea = list(filter(lambda x: x not in numerical_fea,list(data_train.columns)))
label = 'isDefault'
numerical_fea.remove(label)
- 查看缺失值情况
data_train.isnull().sum()
- 查看中位数情况
data_train[numerical_fea].median()
- 查看众数情况
data_train[category_fea].mode()
- 查看某一特征的各类别数目
data_train['employmentLength'].value_counts(dropna=False)
- 缺失值填充
#把所有缺失值替换为指定的值0
data_train = data_train.fillna(0)
#向用缺失值上面的值替换缺失值
data_train = data_train.fillna(axis=0,method='ffill')
#纵向用缺失值下面的值替换缺失值,且设置最多只填充两个连续的缺失值
data_train = data_train.fillna(axis=0,method='bfill',limit=2)
- 数值型与类别型填充方式不同
另外median是中位数,mean才是平均数。为了防止有人真的搞错,还是给提一下。
mean和median的区别和适用性在这里~
#按照中位数填充数值型特征
data_train[numerical_fea] = data_train[numerical_fea].fillna(data_train[numerical_fea].median())
data_test_a[numerical_fea] = data_test_a[numerical_fea].fillna(data_train[numerical_fea].median())
#按照众数填充类别型特征
data_train[category_fea] = data_train[category_fea].fillna(data_train[category_fea].mode())
data_test_a[category_fea] = data_test_a[category_fea].fillna(data_train[category_fea].mode())
3、异常值处理
- 当你发现异常值后,一定要先分清是什么原因导致的异常值,然后再考虑如何处理。首先,如果这一异常值并不代表一种规律性的,而是极其偶然的现象,或者说你并不想研究这种偶然的现象,这时可以将其删除。其次,如果异常值存在且代表了一种真实存在的现象,那就不能随便删除。在现有的欺诈场景中很多时候欺诈数据本身相对于正常数据勒说就是异常的,我们要把这些异常点纳入,重新拟合模型,研究其规律。能用监督的用监督模型,不能用的还可以考虑用异常检测的算法来做。
- 注意test的数据不能删
- 均方差
在统计学中,如果一个数据分布近似正态,那么大约 68% 的数据值会在均值的一个标准差范围内,大约 95% 会在两个标准差范围内,大约 99.7% 会在三个标准差范围内。
- 代码详解
第一次运行到这里的时候,看着蹦出来的一行行正常值异常值,不知道有没有小伙伴跟我一样,脑子里也蹦出一句,“发生甚么事了?”(哈哈哈)

我看作者在这里并没有给出注释,而本人又看不懂统计和计量的知识,只能看懂代码,所以找点事干,把这部分代码稍微解释一下(不要说我水字数)
下面这段代码的功能是找出异常值:判断标准为若data的值在3Segama范围外则标注为’异常值’,否则为’正常值’
Python中的lambda和apply的用法
def find_outliers_by_3segama(data,fea):
data_std = np.std(data[fea])
data_mean = np.mean(data[fea])
outliers_cut_off = data_std * 3
lower_rule = data_mean - outliers_cut_off
upper_rule = data_mean + outliers_cut_off
data[fea+'_outliers'] = data[fea].apply(lambda x:str('异常值') if x > upper_rule or x < lower_rule else '正常值')
return data
- 定义好函数之后紧接着就是调用,第一行估计是作者写错了,我也不知道会不会对后续的操作有影响。(copy()作用是防止可变类型的数据被后续操作中篡改,更详细的讲解可以看这里)
data_train = data_train.copy()
for fea in numerical_fea:
data_train = find_outliers_by_3segama(data_train,fea)
print(data_train[fea+'_outliers'].value_counts())
print(data_train.groupby(fea+'_outliers')['isDefault'].sum())
print('*'*10)
- 调用之后data_train会变成这个样子,可以看到比原来多出一倍的列,多出的列上的值是说明正常或异常,
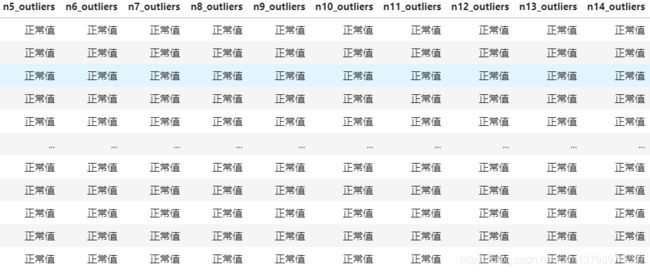
- 后面两句是统计正常值和异常值数量并输出,比如,n0_outliers这一列正常值有782773个,异常值有17227个;按n0_outliers分组后isDefault这一列的正常值有156125个,异常值有3485个。

- 用这样的操作挑出异常值后,后面就比较好处理了,下面这段代码就是按每列去除异常值的操作,然后再重新设置index(索引)
#删除异常值
for fea in numerical_fea:
data_train = data_train[data_train[fea+'_outliers']=='正常值']
data_train = data_train.reset_index(drop=True)
- 去除后800000行就变成612742行

4、特征编码
- tqdm()
tqdm简介及使用方法 - LabelEncoder()
Python数据预处理中的LabelEncoder与OneHotEncoder
5、数据分桶、特征交互以及特征选择
我也不会了希望有大佬能指点迷津
学习问题与解答
1、模板修改
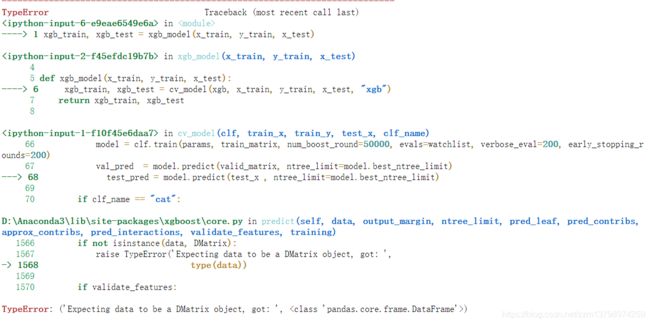
在task03的最后,作者简单写了lightgbm、xgboost和catboost的模型训练函数,第一个lgb_model()还是很顺利能出结果的,但是不知道有没有小伙伴跟我一样,在运行xgb_model()时遇到了这样的问题,
在运行cat_model()时遇到了这样的问题,

反正我是遇到了,所幸出现的问题还在我的认知范围内,于是试着把这个bug改过来。同时借着这次机会把自己对遇到bug时的应对经验分享一下,算是贡献自己微薄的知识吧。顺便小声嘀咕原来大佬也犯这种错误
- xgb_model()
运行xgb_model()给出的错误是typeError,那么根据给出的提示,大概可以推断是在给某个函数传数据的时候出现了数据类型或者说数据结构不一致的情况(即不是DMatrix类型),
这时候再结合jupyter给出的具体出问题的代码,就可以推测一下,诶,会不会是这个test_x的数据类型有问题?
 带着这样的思考,再定位到出现错误的那行代码还有它的前几行代码,可以观察到test_x的画风明显和前两行不一样(前两行都是matrix后缀,凭什么test_x不一样!)
带着这样的思考,再定位到出现错误的那行代码还有它的前几行代码,可以观察到test_x的画风明显和前两行不一样(前两行都是matrix后缀,凭什么test_x不一样!)
model = clf.train(params, train_matrix, num_boost_round=50000, evals=watchlist, verbose_eval=200, early_stopping_rounds=200)
val_pred = model.predict(valid_matrix, ntree_limit=model.best_ntree_limit)
test_pred = model.predict(test_x , ntree_limit=model.best_ntree_limit)
- 到这里,前面的猜测(test_x的数据类型问题)就更有底气了点,再往前看,可以看到两行代码
train_matrix = clf.DMatrix(trn_x , label=trn_y)
valid_matrix = clf.DMatrix(val_x , label=val_y)
- 这是把trn_x和val_x转换成Dmatrix,然而并没有转换test_x,那就照猫画虎地抄一下
test_matrix = clf.DMatrix(test_x)#这里没有test_y,所以不加label参数
.
.
.
#同时把下面的test_x换成test_matrix
test_pred = model.predict(test_matrix , ntree_limit=model.best_ntree_limit)
- 再运行
xgb_train, xgb_test = xgb_model(x_train, y_train, x_test)
(模型训练时间较长)等待30分钟,一般情况下是可以运行通并跑出结果的
- cat_model()
根据运行cat_model()给出的提示TypeError: cannot unpack non-iterable NoneType object
指的是函数返回值的数量不一致
举个例子
定义一个函数,当你调用它时,打印里面的内容
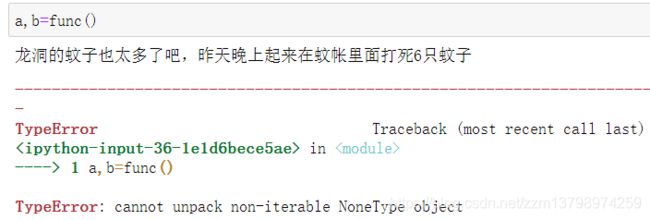
def func():
print('龙洞的蚊子也太多了吧,昨天晚上在蚊帐里面打死6只蚊子')

- 但是如果你除了调用,还要接收返回值,比如
a,b=func()
- 就会出现一样的错误
解决方法很简单,既然要接收返回值,那就return一致个数的返回值,比如return 0,1
这样再调用时就不会出错了,且a,b也接收到了返回值

那么同样的,cat_model()的解决办法就是return cat_train,cat_test
到此问题就解决了。当然了,如果按着步骤来最后还是没改对,希望能在评论下面说一声,可以看看我还有哪里出现了疏漏
2、 比赛文件的生成
我们模型训练出来的lgb_test、xgb_test、cat_test,如果不严格要求,其实已经可以算是一个比赛结果,具备参赛资格,说人话就是可以试着提交上去看看得分了。但是提交的话需要参照官方给出的格式,在sample_submit.csv文件中给到的格式是这样的
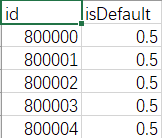
我们的结果显然还不能够,得把它们转换成上面的格式并生成csv文件,出于好奇心理,我写了一段函数将结果转换成对应格式的csv文件,想看看能得到怎样的分数
def to_csv(test,name):
test_copy=test.copy()
test_copy=test_copy.tolist()
n=0
for i in range(800000,1000000):
test_copy.insert(n,i)
n+=2
test=np.array(test_copy)
test=test.reshape(-1,2)
df=pd.DataFrame(test,columns=['id','isDefault'])
df.to_csv(f'{name}_test.csv',index=False)
其中,参数test=模型训练出的结果,参数name=模型名字,例:
to_csv(cat_test,'cat')
然后就可以提交到天池了。
学习思考与总结
- 首先说说我在用DSW运行时遇到的问题:
- 不能同时运行多个cell,只能等前一个运行完,再运行下一个,不然就会有概率出现明明已经运行完毕,但是【星星】一直是那个【星星】的情况。像这样,
这个问题说大也不大,就是让强迫症有点抓狂 - DSW其实并不能运行task03最后的训练模型,我是把代码搬到本地运行的,猜测可能是配置原因吧,DSW给的CPU配置是2核4G(但是如果猜测不对的话,当我后面的话没说),在训练lgb模型的时候半个小时过去了,它还是停在一折,最后被DSW强行叫停,本地的话半小时可能已经训练好了。可能有人会说了,那就在本地跑呗,能跑出结果的CPU就是好CPU,但是,我不就是图云服务器不占用资源吗,这个是我本地训练模型时的CPU占用率,
 可以看到使用率一直维持在100%,对于我的CPU不顾自己寿命给我训练模型这件事我一点都不骄傲,我只会心疼CPU呜呜呜。所以想给个小小的建议,天池平台能否把配置提高一点,不然连训练模型都不能够,免费DSW的存在就没有意义了。
可以看到使用率一直维持在100%,对于我的CPU不顾自己寿命给我训练模型这件事我一点都不骄傲,我只会心疼CPU呜呜呜。所以想给个小小的建议,天池平台能否把配置提高一点,不然连训练模型都不能够,免费DSW的存在就没有意义了。
- 其次是说说我自己的问题,如果说在task02还能凭借自己的基础看懂的话,这次task03的学习是真的有点吃力了,代码方面可能勉强还行,但是在涉及统计计量方面的理论知识的时候,没有基础真是寸步难行(汗颜)。看来自己还有很长的路要走,本来是因为对自己专业没什么兴趣,想来看看能不能转行到数据科学这个领域,真是行行都有本难念的经,不过现在放弃倒也不至于,还是要逼自己一把。加油啊,打工人<( ̄︶ ̄)↗[GO!]