论文翻译阅读_Generative Image Inpainting with Adversarial Edge Learning
引言Abstract
在过去的几年,深度学习技术使得图像修复领域产生了很大的进步。然而,很多技术仍然还是重建合理的结构,因为他们通常都过度平滑了图像或者模糊。这篇文章针对图像修复提出了新的方法,它能够较好地再现充满细节的区域。提出了两阶段的生成对抗模型 Edge Connect,该模型包含一个边缘生成器和一个图像修复网络。边缘生成器可以预测出缺失区域的边缘信息,而修复网络将边缘生成器预测得到的边缘信息作为先验信息来完成对缺失区域的修复。我们在公开可用的数据集CelebA、Places2和Paris StreetView上对我们的模型进行了端到端的评估,并表明它在定量和定性上都优于当前最先进的技术。

1 Introduction
图像修复,或图像补全,包括填充图像的缺失区域。在很多的图像编辑任务中,这是很重要的一步。例如,这个技术可以被用来移除一张图片不想要的目标区域后,对其进行修复。人类有一种不可思议的能力,可以专注于视觉上的不一致。因此,填充区域在感知上必须是可信的。其他方面,在填充的区域缺乏精细的结构,这是一个缺点和问题,尤其是当图像中包含尖锐的细节时。我们观察到很多图像修复技术造成过度平滑或者模糊,导致不能不产生精细的细节,这激发了本篇文章的工作。
我们将图片修复工作分为两个阶段处理(图1):边缘生成和图像修复。边缘生成阶段单独仅仅关注在缺失区域的边缘生成。图像修复网络使用生成的边缘信息来估计缺失区域的RGB像素强度。这两个阶段都使用生成对抗网络[18]的框架来确保生成的边缘信息和RGB像素强度在视觉上的一致性。两个网络都包含基于深度特征的损失去迫使产生真实的结果。
和大部分的计算机视觉问题一样,图像修复问题也很早就开始使用深度学习技术。一般来说,传统的图像修复方法被分为两类:diffusion-based and patch-based .1.基于扩散的方法通过一个典型的使用微分算子建模的扩散过程将背景数据传播到缺失区域[4, 14, 27, 2]。2.另一方面,基于补丁的方法是用源图像集合中的补丁来填补缺失的区域,从而最大限度地提高补丁的相似性[7,21]。然而,这些方法在重建缺失区域的复杂细节方面还是做的不好。
最近深度学习方法在图像修复领域取得了显著的成功。这些方案利用学习数据的分布来补全缺失图像。他们能使得修复的区域保持一致性,这是用传统方法所不能做到的。虽然这些方法能够生成带有有意义结构的缺失区域,但生成的区域往往很模糊或存在伪影,这表明这些方法很难准确地重建高频率信息。
那么如何使得一个图像修复网络能够生成精细的细节信息呢?因为图像的结构很好的在图像的边缘掩码中被表示,我们证明了通过在缺失区域的边缘上设置图像修复网络可以产生很好的修复结果。显然,我们无法获取缺失区域的边缘信息,那么我们训练了一个边缘生成器来预测出缺失区域的边缘信息。我们的方法“先线条,后颜色”是受到艺术家工作的启发。在线描中,线条不仅描绘和定义空间和形状;它们在构图中也扮演着至关重要的角色,贝蒂·爱德华兹说,从艺术的角度强调了素描的重要性。我们认为,边缘修复是一些比图像修复要简单的任务。我们提出的模型本质上是在解耦恢复出缺失区域的高频和低频信息。我们在标准数据集 CelebA [30]、Places2 [56] 和Paris StreetView[8]上评估我们提出的模型。我们将我们的模型的性能与当前最先进的方案进行比较。此外,我们提供了实验结果,以研究边缘信息对图像修复任务的影响。本文有以下贡献:
- 提出一种边缘发生器,能够在缺失区域预测边缘,给定边缘和图像其余部分的灰度像素强度
- 一种图像补全网络,将缺失区域的边缘与剩余图像的颜色和纹理信息相结合,以填补缺失区域
- 一种端到端可训练的网络,结合了边缘生成和图像补全来填补缺失的区域,展示出精细的细节。
我们证明了我们的模型可以用于一些常见的图像编辑应用,如对象删除和场景生成。我们的源代码可在以下地址获得:![]()
2. Related work
基于扩散的方法将邻居信息传播到缺失区域[4,2],[14]采用于图像修复的Mumford-Shah分割模型。然而,这些基于扩散的方法的重建只限于局部可用的信息,而且这些方法无法恢复缺失区域中有意义的结构。这些方法也不能处理有大规模缺失区域的修复。
基于补丁的方法通过复制同一图像(或一组图像)的相似区域(即源)的信息来填补缺失的区域(即目标)。源区域通常被混合到目标区域中,以减少不连续[7,21]。这些方法都很耗费计算,因为要计算每个目标和源之间的相似性。PatchMatch[3]通过使用快速最近邻域算法解决了这个问题。然而,这些方法假定被着色区域的纹理可以在图像的其他地方找到。这些假设并不总是可行的,因此这些方法擅长模式高度相同的图像,例如背景修复,但是针对局部比较特别的重建工作则很难进行。
第一个用深度学习的方法进行图像修复的是 上下编码器(context encoder)[38],它使用编码器-解码器的结构。编码器将带有缺失区域的图像映射到一个低维的特征空间上,解码器使用这个低维的特征进行重建输出图像。然而,由于信道全连接层的信息瓶颈导致图像的修复区域经常包含视觉上伪影和模糊。这个问题被Lizuka et al[22] 所解决,他通过减少下采样层的数目和用一系列的空洞卷积[51]来取代全通道的全连接层。下采样层的减少通过使用不同的膨胀因子来补偿。然而,由于使用大膨胀因子创建的极其稀疏的滤波器,训练时间显著增加。Yang er al[49] 使用预训练的vgg网络[42]来改善上下文编码器(context encoder)的输出,通过最小化图像背景的特征差异。该方法需要迭代求解多尺度优化问题,这明显增加了推理时间的计算成本。Liu at al [28]引入了部分卷积算法用于图像修复,卷积权值由卷积滤波器当前所在窗口的掩模区域归一化。这有效地防止了卷积滤波器在扫描到缺失区域时捕捉过多的零。
最近,在图像修复前提供额外信息的几个方法被提出。Yeh等人。[50]训练GAN用未损坏的数据进行图像修复。在推理过程中,反向传播被使用了1500次迭代,以找到在均匀噪声分布上的损坏图像的表示。然而,这个方法在推理的的时候,每张图片都需要进行反向传播来对图像进行修复。Dolhansky 和Ferrer[9]论证了样本信息对修复图像的重要性。他们的方法能够达到清晰和真实的修复效果。然而他们的方法只针对对人的正脸缺失眼睛区域进行修复,是高度的特定的修复方法,不具有通用性。上下文注意力(context Attention)[53]的方法采用两阶段的步骤去解决图像修复问题,首先,它得到一个对缺失区域粗略的估计。接下来,精修网络使用注意力机制对粗估计的结果进行调整,注意力机制是通过搜索背景patch和缺失区域的粗估计结果的patch之间相似度,根据相似度,采用合适的背景区域来完成对缺失区域的修复。[43]采用了类似的方法,并引入了一个“patch-swap”层,用边界上最相似的补丁替换缺失区域内的每个补丁。这些方法有两个局限性:1)精化网络假设粗估计是合理的,2)这些方法不能处理任意形状的缺失区域。在[52]中提出的自由形式修复方法可能在思想上最接近我们的方案。它使用手绘草图来指导修复过程。我们的方法不需要手绘草图,而是学习在缺失区域产生预测的边缘。
2.1 Image -to-Edges vs Edges-to-Image
本文提出的图像修复技术是将图像到边缘和边缘到图像这两个完全不同的计算机视觉问题的子集。有大量的文章可以解决图像到边缘的问题[5,10,26,29].Canny边缘检测器,是较早的用来构建边缘图的框架。Dollár 和Zitnikc[11]在随机决策森林上使用结构化学习[35]预测局部边缘掩模。整体嵌套边缘检测(HED)[48]是一种完全卷积的网络,它根据边缘信息作为整体图像特征的重要性来学习。在本文的工作中,使用Canny边缘检测器计算的边缘进行训练。这将在第4.1节和第5.3节中对此进行详细解释。
传统的边缘到图像方法通常采用词袋方法,其中图像内容是通过一组预定义的关键字来构造的。然而这些方法不能准确的构建精细的细节,尤其是在接近物体的边缘时。[41]是一个基于学习的模型,其中的图像是使用线草图作为输入生成的。 他们的结果被控制的很接近艺术的风格,颜色的分布是根据输入时线草图所使用的颜色来指导的 。Isola等人[23]提出了一种条件GAN框架[33],称为pix2pix,用于图像到图像的转换问题。该方案利用可用的边缘信息作为先验。CycleGAN[57]扩展了这个框架,并找到了一个反向映射到原始数据分布。这个方法产生了很好的结果,因为它的目的学习正向映射的逆过程。
#3. EdgeConnect
本文提出的图像修复网络包含两个阶段:1.边缘生成器,2图像修复网络。两个阶段都使用生成对抗网络的思想,即都包含生成器和鉴别器。设g1和d1分别为边缘生成器和鉴别器,g2和d2分别为图像补全
网络的生成器和鉴别器。为了简化符号,我们还将使用这些符号来表示它们各自网络的函数映射。
我们的生成器架构和Johnson 等提出的网络架构基本相似,该架构在图像的风格转移,超分辨率,和图像的翻译上取得了很好的结果。具体来说,生成器由向下采样两次的编码器、后面跟随的8个残差块[19]和向上采样图像到原始大小的解码器组成。在残差层中使用膨胀系数为2的膨胀卷积代替常规卷积,导致在最终的残差块处的感受野为205。对于识别器,我们使用70 x70 PatchGAN[23,57]架构,它决定大小为70 x70的重叠图像块是否是真实的。我们在网络2的所有层使用实例规范化[45]。
3.1 Edge Generator
用 I g t I_{gt} Igt表示真实的图像,它的边缘图和灰度图分别表示W为 C g t C_{gt} Cgt和 I g r a y I_{gray} Igray.在图像边缘生成器中,使用灰度图的掩码 I g r a y ‘ = I g r a y . ( 1 − M ) I_{gray}`=I_{gray}.(1-M) Igray‘=Igray.(1−M)作为输入。真实的边缘标签为 C g t ’ = C g t . ( 1 − M ) C_{gt}’=C_{gt.(1-M)} Cgt’=Cgt.(1−M),掩码M,1表示缺失区域,0表示背景。生成器预测掩码区域的边缘地图:
![]()
使用 C g t C_{gt} Cgt和 C p r e d C_{pred} Cpred在 I g r a y I_{gray} Igray条件下作为判别器的输入,该判别器预测一个边缘图是否真实。该网络是训练的目标,包括一个对抗损失和特征匹配损失。
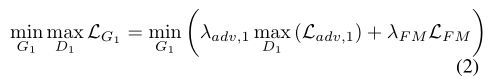
其中 λ a d v , 1 \lambda_{adv,1} λadv,1和 λ F M \lambda_{FM} λFM是正则化参数,对抗损失被定义为如下:
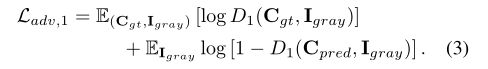
特征匹配损失 L F M L_{FM} LFM比较了鉴别器中间层的激活映射,这通过强制生成器产生与真实图像相似的表示结果来稳定训练过程。这与感知损失很相似【24,16,15】,都是比较来自预训练的vgg网络的激活层的(这里翻译和理解不是太对)。然而因为vgg网络不是被训练来生成边缘信息的,它不能捕捉到我们在第一个阶段需要的结果。特征匹配损失被定义为 L F M L_{FM} LFM:
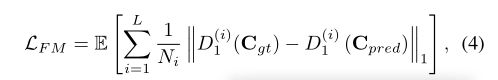
这里的L是鉴别器的最后一个卷积层, N i N_i Ni是第i个激活层里每个元素的数目, D 1 i D_1^i D1i是鉴别器第i层中的激活函数。SN(Spectral normalizeation)通过将权重矩阵按其各自的最大奇异值缩小进一步稳定了训练,有效地限制了网络的Lip- schitz常数变成1。虽然最初提出这只用于鉴别器,但最近的研究[54,36]表明,generator也可以从SN中受益通过抑制参数和梯度值的突然变化。因此,我们对生成器和鉴别器都应用SN。(后面的不太理解)
3.2 Image completion Network
修复网络使用不完整的彩色图像 I g t ‘ = I g t ∗ ( 1 − M ) I_{gt}‘=I_{gt}*(1-M) Igt‘=Igt∗(1−M)作为输入,同时将综合的边缘信息作为附带条件信息。综合边缘信息由真实的背景边缘信息和在第一阶段产生的缺失区域的边缘信息构成。 C c o m p = C g t ∗ ( 1 − M ) + C P r e d ∗ M C_{comp}=C_{gt}*(1-M)+C_{Pred}*M Ccomp=Cgt∗(1−M)+CPred∗M.这个图像修复网络输出的是一张彩色的图片 I p r e d I_{pred} Ipred,包含着对缺失区域的修复:
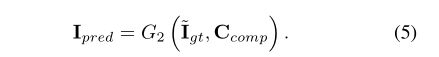
上述的公式是通过联合损失进行训练的,损失包括: L 1 L_1 L1损失,生成对抗损失,感知损失,风格损失。为了确保适当的缩放,l1损失是通过掩码的尺寸进行归一化的。生成对抗损失被定义的类似于公式3:

我们引入了在文献【16,24】中提到两种损失:感知损失和风格损失。顾名思义, ζ p r e c \zeta_{prec} ζprec通过在预先训练过的网络的激活映射之间定义一个距离度量来惩罚那些在感知上与标签不相似的结果。感知损失的定义是:

其中 ϕ i \phi_i ϕi为预训练网络第i层的激活图。在我们的研究中, ϕ i \phi_i ϕi对应于Im- ageNet数据集[39]上预先训练的VGG-19网络的relu1 1、relu2 1、relu3 1、relu4 1和relu5 1层的激活映射。这些激活映射也被用来计算风格损失,度量激活映射的协方差之间的差异。给定尺寸为 C j ∗ H j ∗ W j C_j*H_j*W_j Cj∗Hj∗Wj的特征图,计算风格损失:

其中 G j ϕ G_j^\phi Gjϕ是由激活函数映射 ϕ j \phi_j ϕj构造成的一个 C j ∗ C j C_j*C_j Cj∗Cj的Gram 矩阵。我们选择使用风格损失,正如Sajjadi等人的[40]所显示的那样,它是对抗由转置卷积层[37]所造成的“棋盘”伪制品的有效工具。我们的总损失是:
![]()
对于我们的实验,将 λ l 1 \lambda_{l1} λl1=1, λ a d v , 2 \lambda_{adv,2} λadv,2= λ p \lambda_p λp=0.1, λ s \lambda_s λs=250.我们注意到,如果包括spectral normalization归一化,训练时间显著增加。我们认为,这是由于网络变得过于严格,与增加项在损失函数。因此,我们选择从图像补全网络中排除sn归一化。
4. Experiments
4.1 Edge Information and Image Masks
为了训练G1,我们使用Canny边缘检测器生成训练标签(即边缘地图)。Canny边缘检测器的灵敏度由高斯平滑滤波器σ的标准差控制。在我们的测试中,我们通过经验发现σ≈2可以得到最好的结果(图6)。在第5.3节中,我们研究了边缘图的质量对整体图像补全的影响。
在我们的实验中,我们使用了两种类型的图像掩模:规则和不规则。常规mask是固定大小的正方形mask(占图像总像素的25%),位于图像的随机中心位置。我们从Liu等人[28]的工作中获得了不规则口罩。不规则的mask是aug-由引入四个旋转(0◦,90◦,180◦,270◦)和水平反射为每个mask。它们是根据它们相对于整个图像的大小(以10%为单位)进行分类的(例如,0-10%,10-20%,等等)。
4.2 Training Setup and Strategy
使用的输入图片大小为256x256,batch_size=8.优化器采用Adam optimizer, β 1 = 0 , β 2 = 0.9 \beta_1=0,\beta_2=0.9 β1=0,β2=0.9,生成器G1,G2被分开进行训练,使用Canny边缘检测器,学习率=10-4直到损失平稳。然后将学习率调整为10-5继续训练G1,G2直到收敛。最后,通过移除D1微调整个网络,训练G1,G2,端到端的训练,学习率为10-6直到收敛。辨别器的学习率为生成器的十分之一。
器,学习率=10-4直到损失平稳。然后将学习率调整为10-5继续训练G1,G2直到收敛。最后,通过移除D1微调整个网络,训练G1,G2,端到端的训练,学习率为10-6直到收敛。辨别器的学习率为生成器的十分之一。
参考文献:
Generative Image Inpainting with Adversarial Edge Learning