ECCV 2020 DETR:《End-to-End Object Detection with Transformers》论文笔记
目录
- 简介
- 动机
- 贡献
- 方法
- 实验
简介
本文出自FaceBook AI,方法很新颖,不同于已有的R-CNN一系列,也不同于Yolo一系列,也不同于FCOS、CenterNet等最新的Anchor Free模型。作者将目标检测视为direct set prediction problem(直接集预测)。
下载链接
本篇博客的部分内容参考自这里
动机
simplify pipelines.
贡献
本文将Transformer融入目标检测的pipeline,实现了真正的No Anchor。实验结果上,能够超过精调的Faster R-CNN。
方法
方法的整体架构如下图所示。

更为具体的结构图如下图所示。其实就三个部分:backbone、transformer (encoder + decoder)、prediction heads。其中,backbone就是传统的CNN结构,用于提取图像的2D信息。encoder和decoder一会再说。prediction heads用于对decoder的输出进行分类。
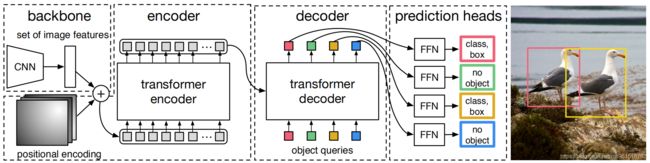
下面说encoder和decoder。下图是更加清晰的encoder和decoder结构,来自原文的附录。这里比较有意思的是Object queries,我一直也没太理解它的直观意思,下面说一下我的大致理解。从作者的代码中,能够看出,所谓的Object queries其实是一个大小为 100 × 2 × 256 100 \times 2 \times 256 100×2×256的变量,而且是通过训练确定的!这里的100是个超参数,表示对于每张图片,预测100个bboxes。设为100的原因是,数据集中有90个类别,100刚好合适。

有两点值得注意的 1. 和NLP中的transformer不太一样,DETR中在decoder部分将Object queries一起作为输入,而非序列化地一个一个输入。2. 只用image features进行编码是不够的,需要融入位置信息,也就是上图中的Spatial positional encoding部分。这部分我没具体看,代码里是这样的,有兴趣的可以分析一下。
# spatial positional encoding
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors
mask = tensor_list.mask
assert mask is not None
not_mask = ~mask
y_embed = not_mask.cumsum(1, dtype=torch.float32)
x_embed = not_mask.cumsum(2, dtype=torch.float32)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos
实验
下图是在COCO上的实验结果,主要和Faster R-CNN进行了对比。
