基础概念
- File:用户需要存储或者访问的文件。对于一个基于Ceph开发的对象存储应用而言,这个file也就对应于应用中的“对象”,也就是用户直接操作的“对象”。
- OSD:全称Object Storage Device,也就是负责响应客户端请求读写具体数据的进程。一个Ceph集群一般都有很多个OSD,OSD一般和磁盘绑定。
- PG:全称Placement Grouops,是一个逻辑的概念。PG的用途是对object的存储进行组织和位置映射。一个PG负责组织若干个object(可以为数千个甚至更多),但一个 object只能被映射到一个PG中。
- RADOS:全称Reliable Autonomic Distributed Object Store,是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
- CRUSH:CRUSH是Ceph使用的动态数据分布算法,类似一致性哈希,将PGs均匀映射到OSDs上
- Monitor:维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。 Ceph 保存着发生在Monitors 、 OSD 和 PG上的每一次状态变更的历史信息
Ceph寻址流程

- File -> Objects
file为用户需要访问或者或获取的文件,当file文件超过RADOS限定的最大size时(一般为2M或4M),file会被均等的分割为等大的object对象(最后一块object大小可以不等)。对file进行分割有两个好处:一,让大小不限的file变成最大size一致、可以被RADOS高效管理的 object;二,单一处理的file转化为并行处理的objects - Objects -> PGs
当File被分割成若干Objects时,需要将Objects随机映射到PGs上,计算公式:
#oid为object的唯一id
#ino为file未被分割前的唯一id
#ono为file被分割后该object的序号
#mask为pg总数减一
#hash哈希算法
oid = ino + ono
pgid = hash(oid) & mask
哈希值计算和按位与操作的整体结果事实上是从所有m个PG中近似均匀地随机选择一个。基于这一机制,当有大量object和大量PG 时,RADOS能够保证object和PG之间的近似均匀映射。又因为object是由file切分而来,大部分object的size相同,因而,这一映射最终保证了,各个PG中存储的object的总数据量近似均匀。只有当object和PG的数量较多时,这种伪随机关系的近似均匀性才能成立,Ceph的数据存储均匀性才有保证。为保证“大量”的成立,一方面,object的最大size应该被合理配置,以使得同样大小的file能够被切分成更多的object;另一方面,Ceph也推荐PG总数应该为OSD总数的数百倍,以保证有足够数量的PG可供映射。
Objects和PGs之间的映射关系是多对一的关系
- PGs -> OSDs
RADOS采用CRUSH算法,将pgid作为参数,会得到一个包含多个OSD的组。该组里的OSD共同负责存储,维护一个PG里的Objects。
有关CRUSH:CRUSH是一个动态算法,其结果会受当前系统状态存储策略配置的影响。所以当有设备损坏或者增添时,大部分PG与OSD之间的映射关系不会发生 改变,只有少部分PG的映射关系会发生变化并引发数据迁移。这种可配置性和稳定性都不是普通哈希算法所能提供的。因此,CRUSH算法的设计也是Ceph 的核心内容之一
有关三次映射和二次映射:如果除去PG层的话,从Files到OSDs只有两次映射,Objects采用静态算法直接映射到OSDs上,当OSDs数量发生变化的时候,整个存储系统将无法做到动态拓展。如果Objects仍然采用CRUSH算法映射到OSDs上,则OSDs之间进行信息交互的时间开销将会暴增。
Ceph数据流程

- 步骤1:client向Ceph集群写入一个flie时,通过上述的寻址流程得到三个OSDs,client和Primary OSD(主OSD)发起写请求通信。
- 步骤2,3:Primary OSD获取到client的写请求之后向另外两个OSD发起写请求
- 步骤4,5:另外两个OSD写入数据后向主OSD发送确认信息
- 步骤6:主OSD在获取两个OSD的确认信息后,完成数据写入,并向client发送写入完成确认信息
由于需要等待所有的OSD确认完才能最终返回写入确认,所以整体时延会较长,一般OSD会像client发送两次确认信息,第一次是所有OSD写入内存时,第二次是所有OSD写入磁盘时。
ceph性能优势
- 高性能
1, 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
2, 考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
3, 能够支持上千个存储节点的规模,支持TB到PB级的数据。 - 高可用
1, 副本数可以灵活控制。
2, 支持故障域分隔,数据强一致性。
3, 多种故障场景自动进行修复自愈。
4, 没有单点故障,自动管理。 - 高拓展性
1, 去中心化
2, 拓展灵活
ceph安装
monitor:192.168.4.4
osd1:192.168.4.1
osd2:192.168.4.2
ceph-admin:192.168.0.192
主机名 IP 地址
ceph-admin 192.168.0.192
mon1 192.168.4.4
osd1 192.168.4.1
osd2 192.168.4.2
1, 在上述主机上创建ceph用户
useradd -m -s /bin/bash cephuser
passwd cephuser
2, 获取sudo权限,因为在ceph的安装中不支持sudo命令输入
echo "cephuser ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephuser
chmod 0440 /etc/sudoers.d/cephuser
sed -i s'/Defaults requiretty/#Defaults requiretty'/g /etc/sudoers
3, 安装和配置 NTP
sudo apt-get install -y ntp ntpdate ntp-doc
ntpdate 0.us.pool.ntp.org
hwclock --systohc
systemctl enable ntp
systemctl start ntp
4, 编辑/etc/hosts文件
ceph-admin 192.168.0.192
mon1 192.168.4.4
osd1 192.168.4.1
osd2 192.168.4.2
5,配置admin节点到其他节点的免密ssh登录
ssh root@ceph-admin
su - cephuser
ssh-keygen
vim ~/.ssh/config
#输入以下内容:
Host ceph-admin
Hostname ceph-admin
User cephuser
Host mon1
Hostname mon1
User cephuser
Host ceph-osd1
Hostname ceph-osd1
User cephuser
Host ceph-osd2
Hostname ceph-osd2
User cephuser
#####
chmod 644 ~/.ssh/config
ssh-keyscan ceph-osd1 ceph-osd2 mon1 >> ~/.ssh/known_hosts
ssh-copy-id ceph-admin
ssh-copy-id ceph-osd1
ssh-copy-id ceph-osd2
ssh-copy-id mon1
6, osd节点硬盘划分和挂载
dd if=/dev/zero of=ceph-volumes.img bs=1M count=8192 oflag=direct
sgdisk -g --clear ceph-volumes.img
sudo vgcreate ceph-volumes $(sudo losetup --show -f ceph-volumes.img)
sudo lvcreate -L2G -nceph0 ceph-volumes
sudo mkfs.xfs -f /dev/ceph-volumes/ceph0
sudo mount /dev/ceph-volumes/ceph0 /srv/ceph/osd0
7, ceph-admin创建集群
mkdir cluster
cd cluster/
ceph-deploy new mon1
echo "osd pool default size = 2" >> ceph.conf
8, 从ceph-admin安装ceph到所有节点
ceph-deploy install ceph-admin ceph-osd1 ceph-osd2 mon1
ceph-deploy mon create-initial
ceph-deploy gatherkeys mon1
9, 增加osd到集群
ceph-deploy osd prepare ceph-osd1:/srv/ceph/osd1 ceph-osd2:/srv/ceph/osd2
ceph-deploy osd activate ceph-osd1:/srv/ceph/osd1 ceph-osd2:/srv/ceph/osd2
10, 安装结果验证:
sudo ceph -s

osd盘读写性能测试
osd1读写速度:

osd2读写速度:


集群读写性能
-
集群随机读速度
 集群随机读速度.png
集群随机读速度.png -
集群顺序读速度
 集群顺序读速度.png
集群顺序读速度.png -
集群写速度
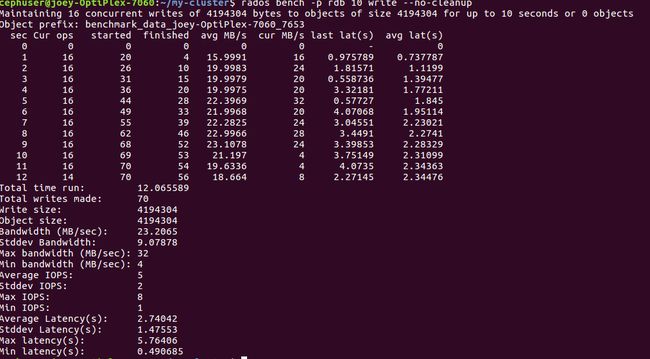 集群写.png
集群写.png
ceph块设备安装
1, 块是一个字节序列(例如,一个 512 字节的数据块)。基于块的存储接口是最常见的存储数据方法,它们基于旋转介质,像硬盘、 CD 、软盘、甚至传统的 9 磁道磁带。无处不在的块设备接口使虚拟块设备成为与 Ceph 这样的海量存储系统交互的理想之选。
2, Ceph 块设备是精简配置的、大小可调且将数据条带化存储到集群内的多个 OSD 。 Ceph 块设备利用 RADOS 的多种能力,如快照、复制和一致性。 Ceph 的 RADOS 块设备( RBD )使用内核模块或 librbd 库与 OSD 交互。
3, 安装ceph设备必须要先完成ceph的集群部署
- 在管理节点上,安装一个ceph-client,ssh的免密设置参考集群部署
#从管理节点安装ceph-client,client地址为172
ceph-deploy install ceph-client
#从管理节点拷贝配置文件到ceph-client
ceph-deploy admin ceph-client
#修改文件权限
sudo chmod +r /etc/ceph/ceph.client.admin.keyring
- 在client节点创建块
#新建设备
rbd create foo --size 4096 -m 192.168.4.1 -k ceph.client.admin.keyring
#映射
sudo rbd map foo --name client.admin -m 192.168.4.1 -k ceph.client.admin.keyring
#创建文件系统
sudo mkfs.ext4 -m0 /dev/rbd/rbd/foo
#挂载
sudo mkdir /mnt/ceph-block-device
sudo mount /dev/rbd/rbd/foo /mnt/ceph-block-device
cd /mnt/ceph-block-device
映射步骤可能会报错“rbd feature disable”,原因是不同内核对ceph默认的rbd服务支持不同,可以使用dmesg | tail命令查找错误码,关闭掉不支持的默认项。具体参考映射问题
ceph文件系统安装
- 创建文件系统
ceph osd pool create cephfs_data
ceph osd pool create cephfs_metadata
ceph fs new cephfs_metadata cephfs_data
- 创建文件挂载
sudo mkdir /mnt/mycephfs
#admin.secret是cat ceph.client.admin.keyring密钥
sudo mount -t ceph 192.168.4.1:6789,192.168.4.2:6789,192.168.4.4:6789:/ /mnt/mycephfs -o name=admin,secretfile=admin.secret
