概述
4V特征
Volume:数据量
Variety:多样性、复杂性
Velocity:速度
Value:基于高度分析的新价值(价值密度的高低与数据的总量成反比),因此数据是需要进行提纯的。
技术变革
技术驱动
存储:文件存储==>分布式存储
计算:单机 ==>分布式计算
网络:万兆
数据库:RDBMS ==>NoSQL(HBase、Redis..)
商业驱动
从大量数据中获得价值
技术概念
数据采集:Flume Sqoop
数据处理、分析、挖掘:Hadoop、Spark、Flink...
数据存储:Hadoop
可视化:常用第三方技术工具、框架
Hadoop概述
Hadoop Common: 基础框架,通用工具集
HDFS-分布式存储框架(文件系统):将文件以块为单位切割开,以三副本方式存储
MapReduce-分布式计算框架:Input->Splitting->Mapping->Shuffling->Reducing->Final result
YARN-资源调度框架(Yet Another Resource Negotiator):负责资源及作业的调度,也可以负责多框架的调度(如MapReduce、Hive、Spark、PIG、Storm等不同框架的统一调度)
狭义的Hadoop指的是Hadoop框架中的基础模块,包括HDFS、YARN、MapReduce
广义的Hadoop一般指的是Hadoop生态系统
发行版的选择
- Apache
优点:纯开源
缺点:不同版本、框架直接需要进行整合,会出现大量的jar包冲突。 - CDH (www.cloudera.com)
优点:可以借助cm(cloudera manager)一键安装各种框架,升级方便,文档清晰,可以使用impala。
缺点:cm不开源,与社区版本有一些出入 - Hortonworks(HDP)
优点:原装Hadoop、开源、支持tez。企业可以基于HDP页面框架进行改造,发布自己的数据平台。
缺点:企业级框架不开源 - MapR
HDFS
设计目标:
- 硬件故障
以block为单位切分并采用3副本方式存储 - 流式数据访问
以流式访问数据,因此建议采用批处理而不是交互式处理。HDFS设计更多的是为了高吞吐量,而不是低延迟。 - 大规模数据集
在HDFS上一个典型的文件单位通常是Gb、Tb。HDFS不怕文件大,但是会怕文件小。 - 移动计算比移动数据更划算
移动数据成本较高,HDFS给计算提供了接口,方便将计算放在靠近数据的集群上进行计算。
HDFS的架构
HDFS是一个master/slave的架构,一个HDFS由一个NameNode(master server)及一系列DataNode组成。
其中: NN负责管理命名空间NameSpace,提供给客户端进行访问数据。DN负责数据的存储。HDFS暴露出系统的命名空间,允许用户进行存储的数据。
内部执行逻辑:一个文件将会根据配置大小拆分成多个块(block),这些块(及副本)会被存储在一系列的DataNode上。
NameNode执行文件系统的操作(即CRUD),并决定block和DataNode的映射关系(拆分的block会存在不同的DataNode上,NameNode记录的就是这种对应关系)
DataNode负责数据(block)的读和写的操作。
部署配置相关
hadoop-cdh版本:
从http://archive.cloudera.com/cdh5/cdh/5/下载到本地,再通过scp命令scp file username@ip-address:path上传到服务器。
或使用wget命令直接下载到服务器中:
wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.15.1.tar.gz
java-jdk1.8:
从https://www.oracle.com/java/technologies/javase-jdk8-downloads.html下载[jdk-8u241-linux-x64.tar.gz]文件到本地,再通过scp命令scp file username@ip-address:path上传到服务器
或直接通过wget方式下载(由于oracle提供的下载通道需要用户进行登录下载,所以命令有些变化):
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" https://download.oracle.com/otn/java/jdk/8u241-b07/1f5b5a70bf22433b84d0e960903adac8/jdk-8u241-linux-x64.tar.gz
实际使用中wget方法的jdk虽然能下载下来但是解压会报错
安装
- 解压jdk到~/app/
tar -zvxf file -C path - 配置环境变量
vi /.bash_profile
添加:
export JAVA_HOME=jdk_path
path = JAVA_HOME/bin
export path
使得配置生效:
source /.bash_profile
ssh免密码登录
ssh免密码登录是通过rsa验证的方式来进行的。当ssh到某个服务器的某个目录(用户)下时,服务器会将随机字符串发送给本地,本地通过私钥加密将加密后的字符串发给服务器,服务器通过公钥解密,如果解密的结果和之前发送给本地的随机字符串一致则认证成功。rsa是非对称加密,私钥id_rsa加密的数据需要用公钥id_rsa.pub来解密,同样公钥id_rsa.pub加密的数据需要用私钥id_rsa来解密。因此我们可以通过以下方式进行操作:
- 使用常规ssh方式登录到服务器,在本地~目录产生.ssh文件夹及known_host文件。
- 使用命令
ssh-keygen -t rsa,此时在.ssh目录会生成私钥文件id_rsa和公钥文件id_rsa.pub,将id_rsa.pub通过scp上传到服务器的ssh目录下,修改或直接cat创建(cat id_rsa.pub >>authorized_keys)文件名为authorized_keys的文件,并通过chmod命令修改权限为600。- 在第2步中是通过上传公钥文件来进行的,也可以直接使用命令行来进行操作:
ssh-copy-id username@ip_address
hadoop(HDFS)安装
1.下载
2.解压
3.添加hadoop的bin目录到环境变量中
4.修改配置文件
hadoop目录文件
bin hadoop客户端名单
etc/hadoop 所有的hadoop配置文件
sbin 启动hadoop相关进程的脚本(如启动hdfs、启动yarn等,属于server相关的脚本)
lib 依赖包
share 常用例子,如“share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.15.1.jar”
配置文件修改:
根据apache官方文档规范要求,
修改 etc/hadoop/hadoop-env.sh:
export JAVA_HOME=xxxx
修改etc/hadoop/core-site.xml:fs.defaultFS hdfs://localhost:9000 修改etc/hadoop/hdfs-site.xml:
(由于hadoop/tmp的默认路径是linux的tmp文件夹,一旦重启linux,tmp会被清空,因此需重新指定新的tmp目录)dfs.replication 1 hadoop.tmp.dir xxxx/tmp
5.启动hdfs
首次启动需要进行格式化:
hdfs namenode -format
启动dfs服务:
start_dfs.sh
6.验证是否成功启动
jps,查看是否存在NameNode、DataNode、 SecondaryNameNode这三个
或者通过浏览器http://ip:50070
start-dfs.sh与hadoop-daemons的关系:
start-dfs.sh = (hadoop-daemons.sh start namenode)+ (hadoop-daemons.sh start datanode)+ (hadoop-daemons.sh start secondarynamenode)
HDFS的命令行操作
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/FileSystemShell.html
HDFS的shell操作命令为bin/hadoop fs xxx
大部分和linux的shell命令类似,其余大部分是本地文件系统和dfs系统之间的文件交互命令。
交互命令:
hadoop fs -put xxx /
hadoop fs -get xxx
hadoop fs -copyFromLocal xxx /
hadoop fs -moveFromLocal xxx /
hadoop fs -copyToLocal
hadoop fs -moveToLocal
操作命令:
hadoop fs -ls
hadoop fs -mkdir
hadoop fs -rmdir
hadoop fs -rm
hadoop fs -rm -r
hadoop fs -getmerge
hadoop fs -cat
hadoop fs -text
...
hdfs-api
基本写法
//配置configuration
Configuration configuration = new Configuration();
//配置登录url
URI uri = new URI("hdfs://xxx:9000");
//配置登录用户名
String user = "xxx";
//配置dfs对象
FileSystem fs = FileSystem.get(uri, configuration, user);
//对dfs进行操作
Boolean b = fs.mkdirs(new Path("/test-api"));
fs.copyFromLocalFile(new Path("/Users/michealki/nohup.out"),new Path("/test-api/test-nohup.out"));
......
单元测试写法
//变量声明
public static final String xxx = xxx;
xxx = null;
....
@Before
public void setUp(){
//初始化
}
@After
public void tearDown(){
//清空资源
}
@Test
public 其他测试函数(){
...
}
api示例
@Test
public void mkdir() throws Exception {
/*
* 创建文件夹
* */
Boolean b = fs.mkdirs(new Path("/test-api"));
System.out.println(String.valueOf(b));
}
@Test
public void ls() throws Exception{
/*
* 使用listFile及迭代器方法遍历指定路径的文件
* 迭代器对象需要强制转换为LocatedFileStatus类型
* */
RemoteIterator iter = fs.listFiles(new Path("/"),true);
while (iter.hasNext()){
LocatedFileStatus obj= (LocatedFileStatus)iter.next();
System.out.println(obj.getPath().toString().
replace(url,""));
}
}
@Test
public void read() throws Exception {
/*
* 打印文件内容
* 使用open方法打开某个文件夹路径
* 使用util的copyByte方法将open返回的stream打印输出
* */
FSDataInputStream inputStream = fs.open(new Path("/js/基本语法.js"));
IOUtils.copyBytes(inputStream,System.out,1024);
}
@Test
public void write() throws Exception{
/*
* 写入内容到指定文件中
* */
//使用InputStream读取文件
FileInputStream inputStream = new FileInputStream("/Users/michealki/Desktop/js/基本语法.js");
byte[] buff = new byte[inputStream.available()];
inputStream.read(buff);
inputStream.close();
String data = new String(buff);
data = "/*****create by api*****/" + data;
// 在dfs中创建新文件,并把读取到的内容写入
FSDataOutputStream outputStream = fs.create(new Path("/基本语法_create_by_api.js"));
outputStream.writeUTF(data);
outputStream.flush();
outputStream.close();
//查看写入的内容
FSDataInputStream dfs_inputStream = fs.open(new Path("/基本语法_create_by_api.js"));
IOUtils.copyBytes(dfs_inputStream,System.out,1024);
}
@Test
public void put() throws Exception {
/*
* 上传文件(或文件夹)
**/
fs.copyFromLocalFile(new Path("/Users/michealki/Desktop/js"),new Path("/"));
}
@Test
public void rename() throws Exception{
/*
* 修改文件名
**/
Path oldPath = new Path("/基本语法_create_by_api.js");
Path newPath = new Path("/基本语法-create-by-api.js");
Boolean b = fs.rename(oldPath,newPath);
System.out.println(b);
//ls
RemoteIterator iter = fs.listFiles(new Path("/"),true);
while (iter.hasNext()){
LocatedFileStatus obj = (LocatedFileStatus)iter.next();
String s = obj.getPath().toString().replace(url,"");
System.out.println(s);
}
@Test
public void getBlockLocations() throws Exception{
/*
* 获取文件的块(存储)信息
* */
FileStatus file = fs.getFileStatus(new Path("/test-api/jdk-8u241-linux-x64.tar.gz"));
BlockLocation[] blocks = fs.getFileBlockLocations(file,0,file.getLen());
for (BlockLocation block:blocks){
for(String name:block.getNames()){
System.out.println(name + "|" + block.getOffset() + "|" + block.getLength() + "|" + new String(block.getHosts()[0]));
}
}
}
}
@Test
public void download() throws Exception{
/*
* 下载文件到本地
* */
fs.copyToLocalFile(new Path("/基本语法-create-by-api.js"), new Path("/Users/michealki/Desktop/123.js"));
}
@Test
public void remove() throws Exception{
/*
* 删除文件
* */
boolean b = fs.delete(new Path("/test-api"),true);
System.out.println(b);
}
Replication
副本Replication的大小是根据配置文件中的dfs.replication来确定的。这个参数存在于hadoop的hdfs-site.xml中,同时在java的安hadoop安装包中的hdfs-default.xml中也存在这个参数。如果我们是在hdfs系统中通过命令行来执行创建文件,那么会根据hdfs-site.xml中配置的副本数量来创建,而如果是通过java api来创建的,那么副本数量是以hdfs-default.xml为准的。
如果想在api中使用自定义副本数量,需要修改configuration配置:
configuration.set("dfs.replication","1");
注意
System.out.println(configuration.get("dfs.replication"));
fs = FileSystem.get(new URI(url),configuration,user);
System.out.println(configuration.get("dfs.replication"));
这两个输出分别是null以及3,说明了configuration是在dfs确定了配置文件以后才有效的。未给dfs对象配置configuration的时候,configuration各个参数值为null。
hdfs词频统计V1
package com.zjk.hadoop_hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class HDFSWCAPP01 {
static final String url = "hdfs://xxx:9000";
static final String user = "xxx";
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI(url), configuration, user);
configuration.set("dfs.replication", "1");
FSDataInputStream inputStream = fs.open(new Path("/wc/pap"));
byte[] buf = new byte[inputStream.available()];
inputStream.read(buf);
String data = new String(buf);
String[] lines = data.split("\n");
Map wdcount= new HashMap();
for(String line:lines){
String[] words = line.split(" ");
for(String word:words){
if (wdcount.containsKey(word)){
Integer cnt = wdcount.get(word)+1;
wdcount.put(word,cnt);
}
else {
if (word.equals(" ")){
word = "__space__";
}
wdcount.put(word,1);
}
}
}
for (String s:wdcount.keySet()){
System.out.println(s + ": " + wdcount.get(s));
}
}
}
hdfs词频统计V2
该版本中加入了1)面向对象思想,按功能划分业务对象。2)通过读取配置文件来解决代码中存在的硬编码问题。 3)反射机制,生成配置文件中指定的mapper类对象,降低类间耦合性。
//HDFSAPP.class 主要用于各个类之间的统一调度
package com.zjk.hadoop_hdfs.HDFSAPP04;
import org.apache.hadoop.fs.FileSystem;
import java.io.BufferedReader;
public class HDFSAPP04{
public static void main(String[] args) throws Exception{
/*
* 通过properties读取配置文件信息
* */
FSys sys = new FSys();
FileSystem fs = sys.getFileSystem();
String srcPath = sys.getProperties().getProperty(Constant.SRC_PATH);
String desPath = sys.getProperties().getProperty(Constant.DEST_PATH);
// 获取IO缓冲区
BufferedReader buff = sys.getBuffer(fs,srcPath);
// 通过反射机制实例化mapper对象
Class cls = Class.forName(sys.getProperties().getProperty(Constant.MAP_CLASS));
Mapper mapper = (Mapper) cls.newInstance();
// 对缓冲区执行map过程,并将计算结果写入缓存中
Context context = sys.wordCount(buff, mapper);
// 输出处理结果到dfs
sys.save(fs,desPath,context);
// 关闭dfs
fs.close();
}
}
//Fsys.class 负责大部分的hdfs操作工作
package com.zjk.hadoop_hdfs.HDFSAPP04;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.Map;
import java.util.Properties;
public class FSys {
private Configuration configuration = new Configuration();
public Properties getProperties() {
return properties;
}
private Properties properties;
FSys() throws Exception{
properties = new ParamsUtils().getProperties();
}
FileSystem getFileSystem() throws Exception{
URI uri = new URI(properties.getProperty(Constant.HDFS_URI));
String user = properties.getProperty(Constant.HDFS_USER);
return FileSystem.get(uri,configuration,user);
}
public void setConfig(String value, String name){
configuration.set(name,value);
}
public void setConfig(Map map){
for(Map.Entry m:map.entrySet()){
configuration.set(m.getKey(),m.getValue());
}
}
BufferedReader getBuffer(FileSystem fs, String srcPath) throws Exception{
FSDataInputStream in = fs.open(new Path(srcPath));
InputStreamReader reader = new InputStreamReader(in);
return new BufferedReader(reader);
}
Context wordCount(BufferedReader buff, Mapper mapper) throws Exception{
String line = "";
while ((line = buff.readLine())!=null){
mapper.map(line," ");
}
buff.close();
return mapper.getContext();
}
void save(FileSystem fs, String desPath, Context context) throws Exception{
FSDataOutputStream fsDataOutputStream = fs.create(new Path(desPath));
for(Map.Entry entry:context.getCacheMap().entrySet()){
String statics = entry.getKey()+"\t"+entry.getValue()+"\n";
fsDataOutputStream.writeBytes(statics);
}
fsDataOutputStream.flush();
fsDataOutputStream.close();
}
}
//Context.class 使用map实现上下文机制,起到一个缓冲区的作用
package com.zjk.hadoop_hdfs.HDFSAPP04;
import java.util.HashMap;
import java.util.Map;
class Context {
private Map cacheMap= new HashMap();
Map getCacheMap() {
return cacheMap;
}
void put(Object name,Object value){
cacheMap.put(name,value);
}
Object get(Object name){
return cacheMap.get(name);
}
Boolean has(Object name){
return cacheMap.containsKey(name);
}
}
//Constant.class 类似于枚举类,避免在业务代码中直接出现字符串硬编码
package com.zjk.hadoop_hdfs.HDFSAPP04;
class Constant {
static final String HDFS_URI = "HDFS_URI";
static final String HDFS_USER = "HDFS_USER";
static final String SRC_PATH = "SRC_PATH";
static final String DEST_PATH = "DEST_PATH";
static final String MAP_CLASS = "MAP_CLASS";
}
//Mapper.class Mapper接口,负责业务功能的处理
package com.zjk.hadoop_hdfs.HDFSAPP04;
public interface Mapper {
void map(String content,String sep);
Context getContext();
}
//ParamsUtils.class 读取配置文件信息
package com.zjk.hadoop_hdfs.HDFSAPP04;
import java.util.Properties;
class ParamsUtils {
private Properties properties = new Properties();
Properties getProperties() {
return properties;
}
ParamsUtils() throws Exception{
properties.load(ParamsUtils.class.getClassLoader().getResourceAsStream("wc.properties"));
}
}
//WordCountMapper.class Mapper接口的具体实现,用于处理词频统计的实际业务功能
package com.zjk.hadoop_hdfs.HDFSAPP04;
public class WordCountMapper implements Mapper {
private Context context = new Context();
public void map(String string,String sep) {
string = string.toLowerCase();
string = string.replace(" +"," ");
string = string.replaceAll("[^0-9a-z]"," ");
String[] words = string.split(sep);
for(String word:words){
if (context.has(word)){
Integer cnt = Integer.parseInt(context.get(word).toString()) + 1;
context.put(word,cnt);
}
else {
context.put(word,1);
}
}
}
public Context getContext() {
return context;
}
}
//wc.properties 配置文件
HDFS_URI=hdfs://xxxx:9000
HDFS_USER=xxxx
SRC_PATH=/wc/pap
DEST_PATH=/wc/static/statics
MAP_CLASS=com.zjk.hadoop_hdfs.HDFSAPP04.WordCountMapper
hdfs元数据
元数据指的是hdfs分布式文件block的存放目录结构信息。
包括id、block、存放的DataNode编号等。
checkpoint机制
元数据信息由NameNode管理,存放在tmp文件夹下的fsimage文件中。
对于元数据信息的管理,会以树形结构存储目录结构,通过1)定期写元数据信息到磁盘中,即fsimage 2)将操作记录信息以操作日志的方式写入磁盘中(log4j滚动生成),即edits日志文件。
但是对于合并操作(元数据信息的恢复)不会再nn上进行,而是在secondaryNameNode上进行的,避免了再nn上产生更大的压力。合并后在进行反序列化,并在内存中生成完整的树并生成新的fsimage。
safemode机制
在启动hdfs时,nn会先进入safemode状态,此时是无法进行数据在dn上的读写操作的。
此时会对dn上各个block的心跳信息进行检测,当检测到block的活跃数达到一个阈值的时候,会关闭safemode表示通过了检测,可以正常读写数据了。
MapReduce
概述
适用场景:分布式大数据的离线处理
不适用于:实时流式计算
基本流程
- split
split负责将文件拆开,方便进行后续的并行计算操作。实际mr中不是以行、列或分隔符的方式拆分文件的,而是以block的方式或文件的方式进行拆分。 - mapping
将split中各个部分的数据按照指定分隔符拆分,并对拆开的每部分做一个指定的映射处理如词
频统计"aaa bbb ccc aaa"拆分后为"aaa"、"bbb"、"ccc"、"aaa",映射后为"aaa,1"、"bbb,1"、"ccc,1"、"aaa,1" - shuffling
将mapping中相同的放在一起(实际框架中是将相同"key"的放在一起),方便后续放在同一个reduce中进行处理。 - reducing
shuffle后会将key相同的计算任务放在一起,reduce会对各个部分进行计算处理。并合并生成最后结果
实际编程模型中只需要处理mapping和reducing两部分。
一些核心概念
- Split
- InputFormat
- OutputFormat
- Partitioner
用于将任务分发在集群上不同的机器上进行计算 - Combiner
编程模型
Mapper
自定义Mapper需继承Mapper基类,并指定四个泛型的类型:KEY_IN、VALUE_IN、KEY_OUT、VALUE_OUT。
其中:
KEY_IN一般表示的是输入数据的偏移量,因为通过之前的split步骤,会将原始数据拆分,需要通过偏移量来确定要进行处理的是拆分后的哪一部分。
VALUE_IN就是拆分后的每一部分数据。
KEY_OUT和VALUE_OUT是指的进行MAPPER处理后输出数据的KEY和VALUE。
MapReduce编程模型中,会涉及到序列化和反序列化操作,因此在指定上面四个泛型类型的时候是不能用java自带的数据类型的。需要使用到hadoop自定义数据类型:
Long - LongWritalbe
Integer - IntWritable
String - Text
...
这些类型实际上是基础类型附加Writable序列化操作及Comparable可对比操作
map函数
自定义mapper需要实现map函数的重写。例如词频统计中的map函数就是对每行数据按照指定分隔符分割,将各个单词附带词频数量"1"进行输出(会输出在context中,即上下文缓冲区)。
Reducer
自定义reducer实现基类Reducer,需指定四个泛型参数的类型:KEY_IN、VALUE_IN、KEY_OUT、VALUE_OUT。
其中的KEY_IN、VALUE_IN对应于Mapper的输出,而KEY_OUT、VALUE_OUT则对应于Reducer的输出(一般来说和KEY_IN、VALUE_IN是一致的)。
例如进行词频统计,mapper输出为(abc,1)(abc,1)(abc,1),即Text类型和IntWritable类型,输出为合并的结果(abc,3),同样也是Text类型和IntWritable类型。
reduce函数
自定义Reducer需重写reduce函数,该函数有三个参数,分别为KEYIN key、Iterable
因为通过shuffle过程会把相同的key的数据放在同一个reducer上进行处理,实际shuffle后输出的是(key,iterator),key表示名称,而iterator表示具有相同key的数据的各个值。例如上面的(abc,1)(abc,1)(abc,1)shuffle后为(abc,<1,1,1>),后面的<1,1,1>即为一个可迭代对象。
reduce函数即处理这个key和可迭代对象,将处理结果写出到上下文缓存context中。
Driver
Driver的作用就对MR作业进行配置,关联mapper和reducer。
例如:
// 创建连接配置
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","rn.zhujiankai.tk:9000");
// 由于一些特殊原因,需要通过环境变量HADOOP_USER_NAME来指定登录用户
System.setProperty("HADOOP_USER_NAME","wqzjk393");
//创建Job实例
Job job = Job.getInstance(configuration,"wc");
// 配置主类、mapper处理类、reducer处理类
job.setJarByClass(MRAPP01.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
// 配置mapper的output_key和output_value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 配置reducer的output_key和output_value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 删除旧的output目录
FileSystem fs = FileSystem.get(new URI(configuration.get("fs.defaultFS")), configuration, System.getProperty("HADOOP_USER_NAME"));
fs.delete(new Path("/mrwc/output"),true);
// 配置Input和Output的文件目录
FileInputFormat.setInputPaths(job,new Path("/wc/pap"));
FileOutputFormat.setOutputPath(job,new Path("/static/static"));
// 配置编译
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : -1 );
job还有其他的配置信息,例如combiner的配置等,根据个人需求进行配置。
使用本地模式进行开发
将上述例子中configuration对于hdfs的配置以及用户名配置删除,并在 FileInputFormat.setInputPaths();和FileOutputFormat.setOutputPath();中将地址写为本地目录例如"input",会直接从本地路径中读取数据,并将计算结果输出到对应的输出文件夹下。
在本地进行代码业务逻辑测试,在服务器测试环境进行性能调优,可以有效降低时间花费,提高开发效率
使用本地模式时,也可以提前删除本地已有的输出目录:
// 删除旧的Output目录
Runtime runtime = Runtime.getRuntime();
runtime.exec("rm -r local/output").waitFor();
Combiner
mapper端实际只是做数据的拆分和映射,例如(abc aaa bbb abc)经过mapper之后的输出是(abc,1 ; aaa,1 ; bbb,1 ; abc,1),当做reduce时需要将这4条数据进行传输的,会消耗带宽资源。我们可以提前进行聚合操作,即在mapper之后立马进行聚合操作,再经过网络传输同其他节点的mapper数据汇合后进行reduce。
Combiner能减少IO,提高执行性能
但是有些场景是无法使用到这种机制的,例如矩阵乘法操作等。非线性场景
使用自定义数据类型
自定义数据类型需要实现一个Writable接口,这个接口的作用是将对象序列化操作。这个接口要求实现创建一个默认构造函数,此外还要求重写write和readFields方法,其中readFields方法的读取顺序应当与write写数据的顺序是一致的(否则反序列化时会出问题):
public class Record implements WritableComparable {
private long num;
private long upFlow;
private long downFlow;
private long totalFlow;
public Record() {}
public void write(DataOutput out) throws IOException {
out.writeLong(this.num);
out.writeLong(this.upFlow);
out.writeLong(this.downFlow);
out.writeLong(this.totalFlow);
}
public void readFields(DataInput in) throws IOException {
num = in.readLong();
upFlow = in.readLong();
downFlow = in.readLong();
totalFlow = in.readLong();
}
Partitioner
Partitioner主要负责将mapper的结果分发到不同的reducer上进行处理。如果是集群中多台机器,partitioner将会把他们依据key的大小分发在不同的reducer上处理。而如果是单机版本,默认只有一个reducer(配置参数过程:默认使用HashPartitioner,HashPartitioner需要制定一个numReduceTasks,这个numReduceTasks会通过job创建时的接收到的configuration,通过JobConf(configuration)传入。JobConf有一个叫做setNumReduceTasks的方法,可以外部自己配置task数量,而默认通过configuration接受配置时,会读取external-lib/hadoop-mapreduce-client-core/mapred-default.xml中的
在集群中,每个node都会至少有一个reducer,因此可以通过默认的hashpartition算法,将key的哈希值对整个集群的reducer数量取模,按结果分发到不同的reducer上进行计算,也就实现了集群并行处理的功能。
也可以使用自定义partition算法,使得数据按自己的需求分发在不同node的reducer上。
同时可以通过job.setNumReduceTasks,配置单一节点的reducer数量,配合自定义partition算法实现分区(分类)功能。
//MRAPP_PARTITION.class
package com.zjk.hadoop_mapreduce.log_analy;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MRAPP_PARTITION {
public static void main(String[] args) throws Exception {
// 创建连接配置
Configuration configuration = new Configuration();
//创建Job实例
Job job = Job.getInstance(configuration,"partition-flow-count");
// 配置主类、mapper处理类、reducer处理类
job.setJarByClass(MRAPP_PARTITION.class);
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
// 配置mapper的output_key和output_value的类型
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Record.class);
// 配置reducer的output_key和output_value的类型
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Record.class);
// 设置分区类即分区数量
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(4);
// 删除旧目录
Runtime runtime = Runtime.getRuntime();
Process process = runtime.exec("rm -r access/partition-input");
process.waitFor();
// 配置Input和Output的文件目录
FileInputFormat.setInputPaths(job,new Path("access/input"));
FileOutputFormat.setOutputPath(job,new Path("access/partition-input"));
// 配置编译
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : -1 );
}
}
//MyPartitioner.class
package com.zjk.hadoop_mapreduce.log_analy;
import com.zjk.hadoop_mapreduce.log_analy.Record;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner {
@Override
public int getPartition(LongWritable longWritable, Record record, int i) {
if (longWritable.toString().startsWith("13")){return 0;}
else if (longWritable.toString().startsWith("15")){return 1;}
else if (longWritable.toString().startsWith("18")){return 2;}
else return 3;
}
}
YARN
MAPREDUCE2又叫做YARN,在MRV1版本架构的基础上,将JobTracker拆分为资源管理(resource management )和作业调度监控( job scheduling/monitoring)两个进程。
基本组成
- master:ResourceManager(RM),一个全局资源管理
- ApplicationMaster(AM),每一个应用程序(例如spark、MapReduce)会有一个AM。AM运行在各个node中。
- slave: NodeManager,每一个RM又会有多个slave节点即NM。
架构

YARN是master-slave架构的,即1个nameNode(Master)和多个dataNode(Slaver)。
在master node上运行ResourceManager。
每个datanode上运行一个NodeManager。
NodeManager通过心跳信息同ResourceManager保持通信,ResourceManager更新管理当前集群各个Node的资源情况。
简单理解即ResourceManager管理集群资源信息(如有多少节点、哪些是空闲的、哪些是挂掉的等),而NodeManager管理所在机器的资源(如CPU、内存、运行的程序等)信息。
Container:某个dataNode上的所有计算资源(CPU、内存)视为一个/多个Container,而Container可以被分配执行一个ApplicationMaster ,也可以分配一个具体的任务如map task、reduce task等。
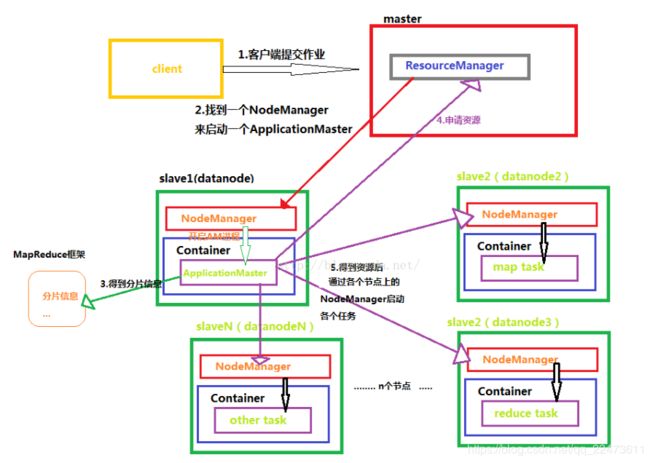
执行过程如上图:
- client客户端向ResourceManager提交一个作业需求
- ResourceManager是集群资源管理的,知道各个计算节点的资源使用情况。RM会找到一个空闲的Node,在这个Node上启动ApplicationMaster,AM负责具体的管理和监控这个计算任务。
- AM会解析任务,获取任务所需的资源信息(例如MapReduce作业拆分得到多个map,reduce,需要多个node进行计算等)。并在RM上申请所需的计算资源(即集群上的DataNode)。
- RM确认计算资源给AM后,AM根据task将各个子任务分发到不同的Node上进行计算,实时监控计算情况即节点情况。
- 当某个Node挂掉之后,AM会重新想RM申请计算资源,并在新的Node上继续进行计算工作。
reference: https://blog.csdn.net/qq_22473611/article/details/88640495
部署
基本配置可以参考官网
主要是配置mapred-site.xml和yarn-site.xml文件。
此外,如果在hdfs-site.xml中修改了tmp文件夹的位置,在yarn-site.xml中也要添加该项配置:
yarn.nodemanager.local-dirs
path
配置完成后使用start-yarn.sh启动yarn进程,可以通过jps看到NodeManager和ResourceManager的进程状态。
在web中可以通过访问8088端口页面,查看实时状态。
部署项目到yarn
本地java脚本测试完成后,修改FileInputFormat.setInputPaths(job,new Path(args[0]))和FileOutputFormat.setOutputPath(job,new Path(args[1])),而不再使用具体的路径地址作为参数。
通过mvn打包脚本文件:mvn clean package -DskipTest ,并上传到服务器上,通过hadoop jar xxx.jar 包名称.主类名称 参数1 参数2的方式将脚本提交到yarn上运行。
同时可以在8088网页上查看到当前yarn处理的进度。
电商统计分析
常见术语
ad view-广告浏览量
pv-页面点击量
uv-访客数(24小时内浏览过的算一次,以机器为单位)
ip-独立ip地址(24小时内相同ip算一次浏览)
url-统一资源定位符
key word-关键字
带宽-用于评估浏览速度
流量-用于评估浏览的数据量
日志采集一般通过专门的团队在nnginx服务器、ajax上进行采集。
java正则表达式的使用
有一个种常见的电商需求是从字符串中获得某些特征信息,然后对这些特征信息的情况做统计,此时就需要用到正则表达式来提取信息。
java的正则表达式逻辑为先对正则表达式字符串进行compile,然后对需要查找解析的字符串进行matcher,随后进行查找操作。需要注意的是一定要先使用find,否则会出错。
Pattern pattern = Pattern.compile("http://|https://");
Matcher matcher = pattern.matcher("http://");
if (matcher.find()){
System.out.println(matcher.group());
}
ETL
使用MapReduce会出现的问题
当使用某一个日志数据文件进行解析处理的时候,有时候我们需要从多个维度多个方向来进行分析统计,但是由于MapReduce的限制,我们必须给每一个需求来写一个mapper和reducer,而且通常情况下我们对于每一个需求都要在写一个driver类。这就意味着每一个需求都要对原始的日志数据文件进行读取,这会带来严重的性能浪费和无谓的时间开销。
ETL思路
原始的日志数据文件是不适合直接做分析处理的,应当对原始文件做进一步处理后,再进行统计分析。
即解析出所需要的字段,去除不需要的字段。
之后的mr作业基于这个处理后的数据做分析就可以了。
ETL基本处理过程
读取原始数据,通过mapper处理数据,将数据写入新的文件中。
etl是不需要进行reduce操作的。
HIVE
https://cwiki.apache.org/confluence/display/Hive
- facebook开源,用于处理海量结构化日志的数据统计问题
- 构建在hadoop之上的数据仓库
- 提供了类似于sql的HiveQL(HQL)
- 低层支持多种不同的执行引擎(hive1.x可以支持mr,hive2.x可以支持spark、Tez)
- 提供统一元数据管理(hdfs存储的是普通文件,通过元数据信息scheme映射为逻辑数据库)。即通过sql on hadoop(如Hive、SparkSQL、impala)创建的表,可以之间是可以正常使用的,如Hive创建的数据在Spark中依然可以使用。
Hive体系结构

部署结构
通常会有主备mysql服务器,通过vip(如Nginx代理)的方式提供一个虚拟的入口,由代理服务器自动判断并进行active/standby切换。
hive是一个客户端软件,不设计集群的概念。实际运行过程是在客户端中提交SQL查询语句,HIVE解析查询语句并将任务发送到集群中的ResourceManager上进行mr作业的调度运行。即HIVE可以放在集群中的任意一台或多台机器上,也可以放在集群外的机器上。
HIVE与RDBM之间的区别
相同
- 都是支持sql(语句)
- 都支持insert、update,但是大数据集群上一般不建议使用insert、update,性能较低。
不同
- 关系型数据库的延时性较低,而hive查询时间较长,不适合即时任务。
- RDBM集群一般机器数量都较少,但是价格都比较昂贵。而hive集群一般机器数量非常庞大,价格比较低廉。hive集群可以处理的数据量非常大(能轻松处理PB以上数据)。
HIVE部署
- 下载并解压
- 配置bash_profile环境变量
- 配置hive/conf/hive-env.sh
a) 修改HADOOP_HOME
b) 修改hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://数据库地址:3306/数据库名?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
root
- 将mysql驱动的jar包(mysql-connector-java-xxxx.jar)放到hive/libs中。并安装好一个mysql数据库(service服务端)
- 通过命令
hive驱动hive,并在mysql中(自动)创建scheme数据库。
mysql的scheme数据库中的dbs数据表:描述通过hive创建的数据库的信息
SELECT * FROM DBS;
+-------+-----------------------+------------------------------------------------------+---------+------------+------------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE |
+-------+-----------------------+------------------------------------------------------+---------+------------+------------+
| 1 | Default Hive database | hdfs://hadoop000:8020/user/hive/warehouse | default | public | ROLE |
| 2 | NULL | hdfs://hadoop000:8020/user/hive/warehouse/test000.db | test000 | hadoop | USER |
+-------+-----------------------+------------------------------------------------------+---------+------------+------------+
其中hdfs://hadoop000:8020/后面的部分即hdfs文件系统中文件的目录。可以通过hadoop fs -ls /user/hive/warehouse/查看具体的文件。
创建数据表
创建数据库:created database database_xxx
使用某个数据库:use database_xxx
以指定分隔符创建数据表:create table table_name(col1 col1_type,col2 col2_type,....) row format delimited fields terminated by '分隔符' ;
加载数据到数据表中:load data local inpath '' overwrite into table table_name
HIVE的数据结构
--hive数据库(database)->hdfs的一个目录
----hive数据表(tables)->hdfs的一个目录
------分区表(partition)->hdfs的一个目录
--------分桶(bucket)->hdfs的一个文件
例如test000数据库的fs路径为:/user/hive/warehouse/test000.db,其中的test000.db也是一个文件夹。当在该数据库中创建了内容以后,其实就相当于在这个文件夹下创建了一个文件,如数据表helloworld对应的文件:/user/hive/warehouse/test000.db/helloworld
需要特别注意的是,hive默认会创建一个叫做default的数据库,他对应的文件夹路径为/user/hive/warehouse。
DDL操作(data-defination language)
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
DDL主要是涉及创建、删除、修改、更新等相关的数据管理功能。
数据库的DDL
create
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS(如果不存在)] 数据库名称
[COMMENT 数据库描述信息]
[LOCATION 自定义hdfs文件存放路径]
[WITH DBPROPERTIES (property_name=property_value, ...
可通过desc extend tablename查看此属性信息)];
显示当前使用的数据库:
set hive.cli.print.current.db=true;
清空屏幕:!clear
查看数据表描述信息:desc formated tablename;
drop
DROP (DATABASE|SCHEMA) [IF EXISTS(如果存在)] 数据库名称 [RESTRICT|CASCADE];
默认是使用RESTRICT参数,即如果数据库中存在有数据表,则拒绝删除。如果强制删除数据库(及其下所有的表),可使用CASCADE参数(较危险,一般不建议使用)。
use
USE database_name;
使用某个数据库
alter
修改数据库
--修改属性
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...); -- (Note: SCHEMA added in Hive 0.14.0)
--修改所属用户
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role; -- (Note: Hive 0.13.0 and later; SCHEMA added in Hive 0.14.0)
--修改hdfs文件存放位置
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path; -- (Note: Hive 2.2.1, 2.4.0 and later)
数据表的DDL
create
创建新表:
CREATE [TEMPORARY(临时表)] [EXTERNAL(外部表)] TABLE [IF NOT EXISTS(如果不存在)] [db_name.]table_name(数据库名.数据表表名)
[(col_name(字段名称) data_type (字段类型)[column_constraint_specification(限制信息,例如数据的长度)] [COMMENT 字段描述], ... [int_constraspecification])]
[COMMENT table_comment(数据表描述信息)]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)(以某些字段作为分区)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS(以某种方式创建分桶)]
[SKEWED BY (col_name, col_name, ...)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row-format属性]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]
](存储配置)
[LOCATION 自定义hdfs存储位置]
[TBLPROPERTIES (property_name=property_value, ...)(自定义表属性)]
[AS select_statement](通过select语句插入数据到数据表,不适用于外部表。hive的外部表和内部表区别在于删除时是否会删除数据和元数据,外部表只会删除掉metadata,而内部表则会删除掉hdfs上的data和mysql上的metadata,hive默认生成的是内部表);
根据已有数据表创建新表:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
alter
修改数据表
ALTER TABLE table_name RENAME TO new_table_name; 修改表名称
ALTER TABLE table_name SET TBLPROPERTIES table_properties; 修改表自定义属性
......
其他
除此以外还有对表的清空操作(Truncate Table),对视图(view)、索引(index)、存储过程/函数(Functions)的增删改查等等操作,具体参考hive官方文档。
DML (Data Manipulation Language)
DML是数据管理语言,涉及到数据的加载、修改、导出等等操作。
load
加载数据到表
LOAD DATA [LOCAL(本地文件系统,如果没有加LOCAL则表示hdfs文件系统的数据)] INPATH '文件路径' [OVERWRITE(覆盖)] INTO TABLE 数据表名称 [PARTITION (partcol1=val1, partcol2=val2 ...)以某些字段进行分区]
inpath的路径可以是相对路径,也可以是绝对路径,也可以是hdfs完整路径(hdfs://hostname:port:/path)
insert
插入数据到数据表中
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
可以使用INSERT INTO/OVERWRITE LOCAL...将数据写入到本地文件系统中
导入导出
Export Syntax
EXPORT TABLE tablename [PARTITION (part_column="value"[, ...])]
TO 'export_target_path' [ FOR replication('eventid') ]
Import Syntax
IMPORT [[EXTERNAL] TABLE new_or_original_tablename [PARTITION (part_column="value"[, ...])]]
FROM 'source_path'
[LOCATION 'import_target_path']
其他
除上述外还可以使用delete、update、merge等,但一般不建议在hive中使用。
select
查询语句
类似于关系型数据库,可以使用select、where、group by、order by等关键词语句。
执行计划
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Explain
通过执行计划EXPLAIN 可以查看select查询语句的各个依赖关系及查询逻辑。通过扩展信息EXTENDED可以查看更具体的语法树解析信息。执行计划一般多用于调优使用。
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query
测试代码
内部表外部表测试。内部表在删除时数据文件与元数据都会被删掉,而外部表删除时只是把元数据删除了,而没有把数据文件删掉。
=====创建内部表,并通过load local导入数据=====
--创建内部表(默认,managed)
create table emp_local_mng(emp_no int,emp_nam string,job string,mgr_no int,hired_date string,salary double,comm double,dept_no int) row format delimited fields terminated by '\t';
--通过本地路径导入数据
load data local inpath '~/data/emp_local_mng.txt' overwrite into table emp_local_mng;
或
cd ~/data
load data local inpath 'emp_local_mng.txt' overwrite into table emp_local_mng;
也就是说这个路径是运行hive的相对路径
=====创建内部表,并导入hdfs上的数据=====
--创建内部表(默认,managed)
create table emp_hdfs_mng(emp_no int,emp_nam string,job string,mgr_no int,hired_date string,salary double,comm double,dept_no int) row format delimited fields terminated by '\t';
--通过HDFS路径导入数据
***emp文件已通过hadoop fs -put local_path hdfs_path的方式上传到了hdfs上***
load data inpath '/data/input/emp_hdfs_mng.txt' overwrite into table emp_hdfs_mng;
=====创建外部表,并通过load local导入数据=====
--创建外部表(external)
create external table emp_local_external(emp_no int,emp_nam string,job string,mgr_no int,hired_date string,salary double,comm double,dept_no int) row format delimited fields terminated by '\t'
location '/external/emp_local';
---通过本地路径导入数据
***因为指定外部表的话实际上相当于把emp.txt文件移动到外部表目录下了,所以创建一个备份的emp.txt文件,用它来做外部表导入***
load data local inpath 'emp_local_external.txt' overwrite into table emp_local_external;
=====创建外部表,并导入hdfs上的数据=====
--创建外部表(external)
create external table emp_hdfs_external(emp_no int,emp_nam string,job string,mgr_no int,hired_date string,salary double,comm double,dept_no int) row format delimited fields terminated by '\t'
location '/external/emp_hdfs';
--通过HDFS路径导入数据
***emp文件已通过hadoop fs -put local_path hdfs_path的方式上传到了hdfs上***
load data inpath '/data/input/emp_hdfs_external.txt' overwrite into table emp_hdfs_external;
在上述例子中,我一共创建了四个表,分别创建了1)内部表,从本地文件系统加载数据;2)内部表,从hdfs加载数据;3) 外部表,从本地文件系统加载数据;4)外部表,从hdfs加载数据。
测试结果表明:
- 无论是内部表还是外部表,并不会因为hive的load导入语句而影响到本地文件系统的文件;
- 无论是内部表还是外部表,如果hive的load语句中没有声明local,即通过hdfs文件系统加载数据到hive数据仓库,这时hdfs文件系统中相对应的原始文件会被hive移动到数据仓库所对应的位置。
- 内部表和外部表是分开存储的。
1)内部表
全部存放在hdfs://user/hive/warehouse/database_name/table_name/路径下,例如上述例子中两个内部表对应的文件emp_local_mng.txt和emp_hdfs_mng.txt分别存放在了hdfs://user/hive/warehouse/empdbs.db/emp_local_mng和hdfs://user/hive/warehouse/empdbs.db/emp_hdfs_mng上。
但是区别在于emp_local_mng.txt是从本地拷贝过去的,而emp_hdfs_mng.txt则是直接将hdfs的/data/input/emp_hdfs_mng.txt文件移动到了hdfs://user/hive/warehouse/empdbs.db/emp_hdfs_mng目录下。
2)外部表
外部表则是根据创建external表示指定的location路径,将本地文件系统中的文件和hdfs的文件放到了这个路径下。同样的,本地文件系统的文件只是拷贝了过去,而hdfs的文件则是移动到了这个指定的location路径下。- 综上所属,总结为:外部表和内部表是分开存放的。本地文件系统不会因为创建的是内部表或是外部表的原因而出现原始文件被移动的问题,即文件分别根据是内部表还是外部表拷贝到/user/hive/warehouse和external指定的路径下;而hdfs文件系统中无论是创建内部表还是创建外部表,都会将文件根据内部表或是外部表,分别移动到/user/hive/warehouse和external指定的路径下。
即加载本地文件系统的文件和加载hdfs的文件他们的区别在于本地文件系统是将数据文件拷贝到hive数据仓库中,而加载hdfs文件则是将hdfs的文件移动到hive数据仓库中。所以加载hdfs文件是一定要注意做好备份,否则原始文件被移动到hive数据仓库的目录下,通过hive处理后可能会发生改变,我们就无法再使用原始文件了。