Learning the Weight of Feature Interactions via Attention Networks
一. 论文解读
FM estimates the target by modelling all interactions between each pair of features:
where is the global bias, denotes the weight of the i-th feature, and denotes the weight of the cross feature , which is factorized as: , where denotes the size of the embedding vector for feature , and denotes the size of embedding vector.
It is worth noting that FM models all feature interactions in the same way: first, a latent vector is shared in estimating all feature interactions that the i-th feature involves; second, all estimated feature interactions have a uniform weight of 1. In practice, it is common that not all features are relevant to prediction. However, FM models all possible feature interactions with the same weight, which may adversely deteriorate its generalization performance.
(AFM), which learns the importance of each feature interaction from data via a neural attention network.
1. 模型结构:
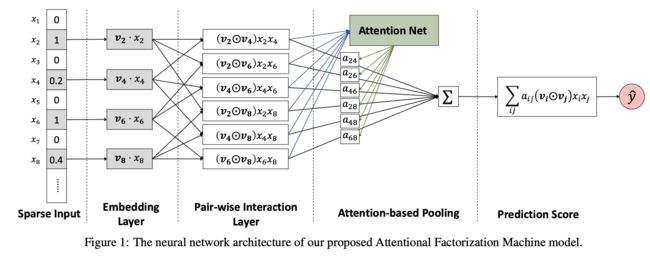
2. 计算流程:
2.1 Pair-wise Interaction Layer
Formally, let the set of non-zero features in the feature vector x be , and the output of the embedding layer be and
2.2 Attention-based Pooling Layer
where is the attention score for feature interaction , which can be interpreted as the importance of in predicting the target.
Formally, the attention network is defined as:
where , , are model parameters, and denotes the hidden layer size of the attention network, which we call attention factor.
2.3 Prediction Layer
3. 损失函数:
二. 代码实现
1. 系统环境
- tensorflow 2.0
- python 3.6.8
2. Pair-wise Interaction Layer
class PairWiseLayer(tf.keras.layers.Layer):
"""
include embedding layer and pair-wise interaction layer
"""
def __init__(self, feature_size, field_size, embedding_size, l2_reg=0.01, **kwargs):
super().__init__(**kwargs)
self.feature_size = feature_size
self.field_size = field_size
self.embeding_size = embedding_size
self.l2_reg = l2_reg
def build(self, input_shape):
self.embeddings = tf.keras.layers.Embedding(self.feature_size, self.embeding_size,
embeddings_regularizer=tf.keras.regularizers.l2(self.l2_reg))
def call(self, inputs):
feature_ids = inputs['feature_ids'] # [batch_size, field_size]
feature_vals = inputs['feature_vals'] # [batch_size, filed_size]
embeddings = self.embeddings(feature_ids) # [batch_size, field_size, embedding_size]
# todo 需要优化,目前这种方式太低效
outputs = []
for i in range(self.field_size):
for j in range(i+1, self.field_size):
weight = tf.multiply(embeddings[:, i, :], embeddings[:, j, :])
dot = tf.reduce_sum(tf.multiply(feature_vals[:, i], feature_vals[:, j]))
outputs.append(weight * dot)
outputs = tf.transpose(tf.stack(outputs), perm=[1, 0, 2]) # [batch_size, interaction_dim, embedding_size]
return outputs
2. Attention-based Pooling Layer
class AttentionLayer(tf.keras.layers.Layer):
"""
计算 a_ij, just one layer.
"""
def __init__(self, hidden_units=64, embedding_size=32, l2_reg=0.01, **kwargs):
super().__init__(**kwargs)
self.hidden_units = hidden_units
self.embedding_size = embedding_size
self.l2_reg = l2_reg
def build(self, input_shape):
"""
:param input_shape: [batch_size, interaction_dim, embedding_size]
:return:
"""
self.h = self.add_weight(name='h',
shape=[self.hidden_units],
initializer=tf.zeros_initializer())
# self.w = self.add_weight(name='w',
# shape=[self.hidden_units, self.embedding_size],
# initializer=tf.zeros_initializer())
# self.b = self.add_weight(name='b',
# shape=[self.hidden_units],
# initializer=tf.zeros_initializer())
self.dense = tf.keras.layers.Dense(units=self.hidden_units,
activation='relu',
use_bias=True,
kernel_regularizer=tf.keras.regularizers.l2(self.l2_reg),
bias_regularizer=tf.keras.regularizers.l2(self.l2_reg))
def call(self, inputs):
"""
:param inputs:
:return: [batch_size, interaction_dim, 1]
"""
inner = self.dense(inputs) # [batch_size, interaction_dim, hidden_units]
outer = tf.matmul(inner, tf.expand_dims(self.h, axis=-1))
outputs = tf.nn.softmax(outer, axis=1)
return outputs
3. Predict Layer
class PredictLayer(tf.keras.layers.Layer):
def __init__(self, embedding_size=32, **kwargs):
super().__init__(**kwargs)
self.embedding_size = embedding_size
def build(self, input_shape):
self.p = self.add_weight(name='p',
shape=[self.embedding_size],
initializer=tf.zeros_initializer())
def call(self, pi_out, att_out):
# [batch_size, embedding_size]
inner = tf.reduce_sum(att_out * pi_out, axis=1)
outputs = tf.matmul(inner, tf.expand_dims(self.p, axis=-1))
return outputs
4. model
class AFM(tf.keras.Model):
def __init__(self, feature_size, field_size, embedding_size=32, l2_reg=0.01, attention_units=64, **kwargs):
super().__init__(**kwargs)
self.pi_layer = PairWiseLayer(feature_size=feature_size, field_size=field_size, embedding_size=embedding_size,
l2_reg=l2_reg, **kwargs)
self.attention_layer = AttentionLayer(hidden_units=attention_units, embedding_size=embedding_size, l2_reg=l2_reg)
self.dense = tf.keras.layers.Dense(units=1, activation=None)
self.predict_layer = PredictLayer(embedding_size=embedding_size)
def call(self, inputs):
pi_out = self.pi_layer(inputs)
# print('pi_layer_out shape: ', pi_out.shape)
att_out = self.attention_layer(pi_out)
# print('att_out shape: ', att_out.shape)
den_out = self.dense(inputs['feature_vals'])
preds = den_out + self.predict_layer(pi_out, att_out)
return preds
5. train
import tensorflow as tf
from afm import AFM
import argparse
import shutil
import numpy as np
import json
import requests
parser = argparse.ArgumentParser()
parser.add_argument('--data_dir', default=r'', help='Data dir.')
parser.add_argument('--feature_size', default=454, help='Number of features.')
parser.add_argument('--field_size', default=196, help='Number of field_size.')
parser.add_argument('--embedding_size', default=16, help='Embedding size.')
parser.add_argument('--attention_units', default=64, help='Hidden units of MLP.')
parser.add_argument('--l2_reg', default=0.01, help='L2 regularizer for trainable variables.')
parser.add_argument('--batch_size', default=64, help='Batch size.')
parser.add_argument('--num_epochs', default=1, help='Number of epochs.')
parser.add_argument('--learning_rate', default=0.01, help='Learning rate.')
parser.add_argument('--task_type', default='train', help='Task type {train, eval, export, predict}.')
parser.add_argument('--model_dir', default=r'',
help='Model check point dir.')
parser.add_argument('--servable_model_dir', default=r'',
help='Model for tensorflow serving dir.')
parser.add_argument('--clear_existing_model', default=True, help='Weather to clearing the old model.')
def input_fn(filename, batch_size, num_epochs=1, shuffle=False):
print('Parsing: ', filename)
def decode_libsvm(line):
"parsing libsvm file."
columns = tf.strings.split(line, sep=' ')
labels = tf.strings.to_number(columns[0], out_type=tf.int32)
id_vals = tf.strings.split(columns[1:], sep=':').to_tensor()
feature_ids, feature_vals = tf.split(id_vals, num_or_size_splits=2, axis=1)
feature_ids = tf.squeeze(tf.strings.to_number(feature_ids, out_type=tf.int32))
feature_vals = tf.squeeze(tf.strings.to_number(feature_vals, out_type=tf.float32))
return {'feature_ids': feature_ids, 'feature_vals': feature_vals}, labels
# return feature_ids, feature_vals, labels
dataset = tf.data.TextLineDataset(filename).map(decode_libsvm, num_parallel_calls=10).prefetch(500000)
if shuffle:
dataset = dataset.shuffle(buffer_size=256)
dataset = dataset.repeat(num_epochs)
dataset = dataset.batch(batch_size)
return dataset
def model_train(args):
feature_size = args.feature_size
field_size = args.field_size
embedding_size = args.embedding_size
attention_units = args.attention_units
l2_reg = args.l2_reg
batch_size = args.batch_size
num_epochs = args.num_epochs
learning_rate = args.learning_rate
data_dir = args.data_dir
model_dir = args.model_dir
servable_model_dir = args.servable_model_dir
if args.clear_existing_model:
try:
shutil.rmtree(model_dir)
except Exception as e:
print(e, ' at clear existing model.')
else:
print('Existing model cleared at ', model_dir)
train_file = data_dir + 'tr.libsvm'
valid_file = data_dir + 'va.libsvm'
train_data = input_fn(train_file, batch_size=batch_size, num_epochs=num_epochs, shuffle=True)
valid_data = input_fn(valid_file, batch_size=64, num_epochs=1, shuffle=False)
model = AFM(feature_size, field_size, embedding_size, l2_reg, attention_units)
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate)
checkpoint = tf.train.Checkpoint(model=model)
for batch_index, (inputs, y) in enumerate(train_data):
with tf.GradientTape() as tape:
y_pred = model(inputs, training=True)
loss = tf.keras.losses.binary_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
grads = tape.gradient(target=loss, sources=model.trainable_variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.trainable_variables))
if batch_index % 500 == 0:
print('batch: %d, loss: %f' % (batch_index, loss))
if batch_index % 1000 == 0:
checkpoint.save(model_dir + 'model.ckpt')
# export
# tf.saved_model.save(model, export_dir=servable_model_dir, signatures={'call': model.call})
# validation
auc = tf.keras.metrics.AUC()
for inputs, y in valid_data:
y = tf.reshape(y, shape=[-1, 1])
y_pred = model.predict(inputs)
auc.update_state(y_true=y, y_pred=y_pred)
print('*' * 100)
print('Test auc: %f\n' % auc.result())
if __name__ == '__main__':
args = parser.parse_args()
task_type = args.task_type
if task_type == 'train':
model_train(args)
【参考】
- https://arxiv.org/abs/1708.04617