让AI帮你玩游戏(一) 基于目标检测用几个样本帮你实现在魔兽世界中钓鱼(群已满)
让AI帮你玩游戏
- 让AI帮你玩游戏(一) 基于目标检测用几个样本实现在魔兽世界中钓鱼
- 前言
- 思路
- 环境
- 获取图像(几个样本即可)
- 标记图片
- 从标记文件中获取Boxes坐标
- 搭建目标检测模型
- 准备训练数据
- (未完待续!我们下一篇来介绍如何训练模型!)
让AI帮你玩游戏(一) 基于目标检测用几个样本实现在魔兽世界中钓鱼(所有代码已上传qq群)
声明:
本文所涉及的内容仅用作学习研究,严禁用于非法用途,游戏中违反相关协议可能会使你失去你的游戏账号!本文为作者原创,如果转载请注明出处,盗用将追责!
前言
本来还偶尔体验下游戏乐趣的我,随着魔兽世界新版本的到来,谜一样的设计师弄一堆半成品实在提不起兴趣来玩了,不知道是否小伙伴跟我一样有同感!最想要吐槽的是钓鱼系统,我的天,简直是种折磨!今天我们来挑战一下,实现自动钓鱼,看下效果先!视频链接地址:https://v.qq.com/x/page/e3163jkj9e3.html
想要代码的的可以联系VX:JTSMJJ 加入qq群获取!
人工智能帮你玩游戏#是心动的感觉# #解压手工# #人工智能那点事# #AI#
思路
- 获取浮标坐标
本来想走捷径,通过api获取鼠标形状句柄来,然后在正前方区域扫描移动鼠标,只要鼠标变为钓钩形状我们就获取当前鼠标的位置作为浮标的位置,但事实告诉我们,我们太年轻了,鼠标句柄只要指向可交互的物体时是不停的变化的,变化的,变化的,变化的,没有固定值(设计师此时笑出了某种声音)!没有办法了吗?NoNoNo,是时候祭出我们的人工智能来了,我们搭建一个神经网络,并训练它,让它帮我们找到坐标!
- 判断上钩
这是一个麻烦的问题,我们有了坐标了,就要判断什么时候来收杆。可以判断浮标的位置的变化来获取位置,这就需要及时获取屏幕图像,我们用截屏是无法实现的,需要HOOK 技术来实时获取画面,咱不走这条路!怎么简单怎么来,我们听声音,当鱼上钩时会发声,我们把其他声音效果全关掉,只要声卡发声咱们就收网!
环境
- Anaconda集成python环境
- tenserflow 2.0+库
- Tensorflow objection detection api库
- Labelme
- VC++环境,我的的VC++2019
获取图像(几个样本即可)
进入客户端,到合适位置钓鱼,为了提高模型准确性(毕竟我们仅用几个样本来训练模型)我们将视野拉到最近,使用浮标玩具让浮标更打一点(我用的浮船玩具),开始钓鱼,调整视角角度从不同的角度截屏(游戏内按下PrintScreen)。
这是我自己截取的样张,可见画面复杂程度其实是很高的,我截取了6张图片为样本,下面我们来标记图片
标记图片
我们有了样本现在开始标记样本,我们用Labelimg来标记,未安装的直接打开Anaconda prompt命令行输入:pip install labelImg,安装完以后还是在Anaconda prompt运行labelimg,如图:
打开后会出现如下界面:
简单介绍下用法:
- 标号1
为打开你想要标记图片所在的文件夹,用open一张张打开麻烦,可以用这个将文件夹整个打开。
- 标号2
你想要保存标记文件的文件夹,文件格式是xml格式的。
-
标号3
每标记完一张图片请点击保存
-
标号4
点击后开始用一个方块区域标记目标区域
-
标号5
打对勾后,在对话框里填上你想为标记区域起的名字,这样不用每张图片输入类名
开始愉快的标记图片吧_
从标记文件中获取Boxes坐标
直接上代码,其中path为上一个步骤你保存xml的文件夹
import glob
import xml.etree.ElementTree as ET
xml_list = []
bxes = []
# 读取注释文件
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
width = int(root.find('size')[0].text)
height = int(root.find('size')[1].text)
xmin = int(member[4][0].text)
ymin = int(member[4][1].text)
xmax = int(member[4][2].text)
ymax = int(member[4][3].text)
value = (root.find('filename').text,
width,
height,
member[0].text,
xmin,
ymin,
xmax,
ymax
)
boxes.append(np.array([[round(ymin / height, 3),
round(xmin / width, 3),
round(ymax / height, 3),
round(xmax / width, 3),
]],
dtype=np.float32))
这样就从标注文件中将标注信息读取到boxes里了。
搭建目标检测模型
这里假设你已经拥有Object Detection API库了,安装方法在这里可以找到(https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2.md)
构筑模型:
import tensorflow as tf
from object_detection.utils import config_util
from object_detection.utils import visualization_utils as viz_utils
from object_detection.builders import model_builder
detection_model = model_builder.build(
model_config=model_config,
is_training=True)
ckpt = tf.compat.v2.train.Checkpoint(model=detection_model)
ckpt.restore(checkpoint_path).expect_partial()
这里需要说明下,model_config跟checkpoint_path分别是你建立模型的配置文件以及官方给出的预训练模型路径,你需要按照你搭载的模型来下载相应的文件,我这里搭建的是ssd_resnet50模型,其对应的配置文件在https://github.com/tensorflow/models/tree/master/research/object_detection/configs/tf2图示位置:
checkpoint在https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md
图示位置: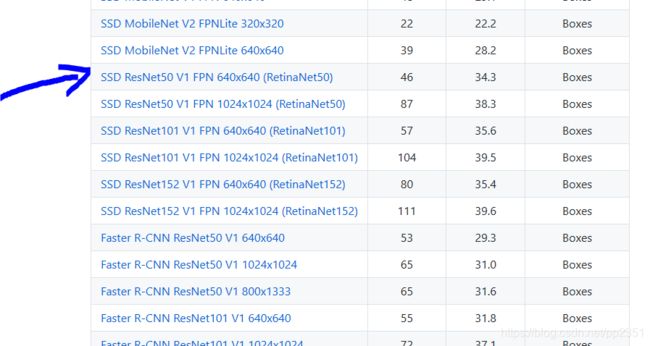
下载下来的是一个压缩包,需要解压,checkpoint就在解压后的checkpoint文件夹里
准备训练数据
没啥好说的直接上代码:
import numpy as np
from PIL import Image
def load_image_into_numpy_array(path):
global X_max, Y_max
img_data = tf.io.gfile.GFile(path, 'rb').read()
image_ = Image.open(BytesIO(img_data))
(width, height) = image_.size
X_max = width
Y_max = height
return np.array(image_.getdata()).reshape(
(height, width, 3)).astype(np.uint8)
train_images_np = []
for i in glob.glob(os.path.join(train_image_dir, '*.jpg')):
train_images_np.append(load_image_into_numpy_array(i))
dummy_scores = np.array([1.0], dtype=np.float32) #给你标记的数据记100分
label_id_offset = 1
train_image_tensors = []
gt_classes_one_hot_tensors = []
gt_box_tensors = []
for (train_image_np, gt_box_np) in zip(
train_images_np, gt_boxes):
train_image_tensors.append(tf.expand_dims(tf.convert_to_tensor(
train_image_np, dtype=tf.float32), axis=0))
gt_box_tensors.append(tf.convert_to_tensor(gt_box_np, dtype=tf.float32))
zero_indexed_groundtruth_classes = tf.convert_to_tensor(
np.ones(shape=[gt_box_np.shape[0]], dtype=np.int32) - label_id_offset)
gt_classes_one_hot_tensors.append(tf.one_hot(
zero_indexed_groundtruth_classes, num_classes))
其中 gt_boxes为我们前边步骤获取到的boxes,train_image_dir为你所标记的图片所在路径。
(未完待续!我们下一篇来介绍如何训练模型!https://blog.csdn.net/pp2351/article/details/109302828)