推荐系统实践读书笔记-02利用用户行为数据
推荐系统实践读书笔记-02利用用户行为数据
为了让推荐结果符合用户口味,我们需要深入了解用户。如何才能了解一个人呢?《论语·公冶长》中说“听其言,观其行”,也就是说可以通过用户留下的文字和行为了解用户兴趣和需求。实现个性化推荐的最理想情况是用户能在注册的时候主动告诉我们他喜欢什么,但这种方法有3个缺点:首先,现在的自然语言理解技术很难理解用户用来描述兴趣的自然语言;其次,用户的兴趣是不断变化的,但用户不会不停地更新兴趣描述;最后,很多时候用户并不知道自己喜欢什么,或者很难用语言描述自己喜欢什么。因此,我们需要通过算法自动发掘用户行为数据,从用户的行为中推测出用户的兴趣,从而给用户推荐满足他们兴趣的物品。
基于用户行为数据的应用其实早在个性化推荐系统诞生之前就已经在互联网上非常流行了,其中最典型的就是各种各样的排行榜。这些排行榜包括热门排行榜和趋势排行榜等。尽管这些排行榜应用仅仅基于简单的用户行为统计,但它们在互联网上获得了很多用户的青睐。因此,用户行为数据的分析是很多优秀产品设计的基础,个性化推荐算法通过对用户行为的深度分析,可以给用户带来更好的网站使用体验。
用户的行为不是随机的,而是蕴含着很多模式。举一个简单的例子,在电子商务网站中,我们每次购物时网站都会生成一个购物车,里面包括了我们一次购买的所有商品。购物车分析是很多电子商务网站,甚至传统零售业的核心数据分析任务,比如我们可以分析哪些商品会同时出现在购物车中。这里面最著名的例子就是啤酒和尿布的例子,这个例子是数据挖掘的经典案例。这个故事有非常多的版本,甚至有人认为这个故事本身就是一个误会。不过我们还是用这个故事简单说明一下用户行为分析的重要性。这个故事的一个版本是说,有一个超市人员发现很多人会同时购买啤酒和尿布,后来他们认为是很多妇女要在家照顾孩子,就让自己的丈夫去买尿布,而丈夫在买尿布的同时不忘买一下自己喜欢的啤酒,于是这两个风马牛不相及的东西就这么产生联系了。于是超市工作人员把啤酒和尿布放在了同一个货架上,结果这两种商品的销售量都明显上升了。不同人看到这个故事有不同的理解,我们从算法设计人员的角度看,这个故事说明用户行为数据中蕴涵着很多不是那么显而易见的规律,而个性化推荐算法的任务就是通过计算机去发现这些规律,从而为产品的设计提供指导,提高用户体验。
啤酒和尿布的故事在互联网上被发扬光大。电子商务公司通过分析用户的购物车,找出诸如“购买A商品的用户都购买B商品”这种规律,同时在用户浏览A商品时直接为其展示购买A商品的用户都购买的其他商品(如图2-1所示)。

基于用户行为分析的推荐算法是个性化推荐系统的重要算法,学术界一般将这种类型的算法称为协同过滤算法。顾名思义,协同过滤就是指用户可以齐心协力,通过不断地和网站互动,使自己的推荐列表能够不断过滤掉自己不感兴趣的物品,从而越来越满足自己的需求。
文章目录
- 推荐系统实践读书笔记-02利用用户行为数据
-
- 2.1 用户行为数据简介
- 2.2 用户行为分析
-
- 2.2.1 用户活跃度和物品流行度的分布
- 2.2.2 用户活跃度和物品流行度的关系
- 2.3 实验设计和算法评测
-
- 2.3.1 数据集
- 2.3.2 实验设计
- 2.3.3 评测指标
- 2.4 基于邻域的算法
-
- 2.4.1 基于用户的协同过滤算法
- 2.4.2 基于物品的协同过滤算法
- 2.4.3 UserCF和ItemCF的综合比较
- 2.5 隐语义模型
-
- 2.5.1 基础算法
- 2.5.2 基于LFM的实际系统的例子
- 2.5.3 LFM和基于邻域的方法的比较
- 2.6 基于图的模型
-
- 2.6.1 用户行为数据的二分图表示
- 2.6.2 基于图的推荐算法
2.1 用户行为数据简介
本章提到的个性化推荐算法都是基于用户行为数据分析设计的,因此本节将首先介绍用户行为数据。
用户行为数据在网站上最简单的存在形式就是日志。网站在运行过程中都产生大量原始日志(raw log),并将其存储在文件系统中。很多互联网业务会把多种原始日志按照用户行为汇总成会话日志(session log),其中每个会话表示一次用户行为和对应的服务。比如,在搜索引擎和搜索广告系统中,服务会为每次查询生成一个展示日志(impression log),其中记录了查询和返回结果。如果用户点击了某个结果,这个点击信息会被服务器截获并存储在点击日志(click log)中。一个并行程序会周期性地归并展示日志和点击日志,得到的会话日志中每个消息是一个用户提交的查询、得到的结果以及点击。类似地,推荐系统和电子商务网站也会汇总原始日志生成描述用户行为的会话日志。会话日志通常存储在分布式数据仓库中,如支持离线分析的 Hadoop Hive和支持在线分析的Google Dremel。这些日志记录了用户的各种行为,如在电子商务网站中这些行为主要包括网页浏览、购买、点击、评分和评论等。
用户行为在个性化推荐系统中一般分两种——显性反馈行为(explicit feedback)和隐性反馈行为(implicit feedback)。显性反馈行为包括用户明确表示对物品喜好的行为。图2-2显示了不同网站收集显性反馈的方式。可以看到,这里的主要方式就是评分和喜欢/不喜欢。很多网站都使用了5分的评分系统来让用户直接表达对物品的喜好,但也有些网站使用简单的“喜欢”或者“不喜欢”按钮收集用户的兴趣。这些不同的显性反馈方式各有利弊。YouTube最早是用5分评分系统收集显性反馈的,但后来他们的研究人员统计了不同评分的评分数,结果发现,用户最常用的评分是5分,其次是1分,其他的分数很少有用户打。因此,后来YouTube就把评分系统改成了两档评分系统(喜欢/不喜欢)。当然,我们举这个例子并不是试图说明一种评分系统比另一种好,而是要说明不同的网站需要根据自己的特点设计评分系统,而不是一味照搬其他网站的设计。YouTube的用户主要将精力放在看视频上,因此他们只有在特别不满或者特别满意时才会评分,因此二级评分系统就足够了。但如果是评论网站,用户主要将精力放在评论上,这时多级评分系统就是必要的。

和显性反馈行为相对应的是隐性反馈行为。隐性反馈行为指的是那些不能明确反应用户喜好的行为。最具代表性的隐性反馈行为就是页面浏览行为。用户浏览一个物品的页面并不代表用户一定喜欢这个页面展示的物品,比如可能因为这个页面链接显示在首页,用户更容易点击它而已。相比显性反馈,隐性反馈虽然不明确,但数据量更大。在很多网站中,很多用户甚至只有隐性反馈数据,而没有显性反馈数据。表2-1从几个不同方面比较了显性反馈数据和隐性反馈数据。

按照反馈的明确性分,用户行为数据可以分为显性反馈和隐性反馈,但按照反馈的方向分,又可以分为正反馈和负反馈。正反馈指用户的行为倾向于指用户喜欢该物品,而负反馈指用户的行为倾向于指用户不喜欢该物品。在显性反馈中,很容易区分一个用户行为是正反馈还是负反馈,而在隐性反馈行为中,就相对比较难以确定。
为了更好地说明什么数据是显性反馈数据,什么是隐性反馈数据,表2-2列举了各个领域的网站中这两种行为的例子。

互联网中的用户行为有很多种,比如浏览网页、购买商品、评论、评分等。要用一个统一的方式表示所有这些行为是比较困难的。表2-3给出了一种表示方式,它将一个用户行为表示为6部分,即产生行为的用户和行为的对象、行为的种类、产生行为的上下文、行为的内容和权重。

当然,在很多时候我们并不使用统一结构表示所有行为,而是针对不同的行为给出不同表示。而且,有些时候可能会忽略一些信息(比如上下文)。当然,有些信息是不能忽略的,比如产生行为的用户和行为的对象就是所有行为都必须包含的。一般来说,不同的数据集包含不同的行为,目前比较有代表性的数据集有下面几个。
无上下文信息的隐性反馈数据集 每一条行为记录仅仅包含用户ID和物品ID。Book-Crossing就是这种类型的数据集。
无上下文信息的显性反馈数据集 每一条记录包含用户ID、物品ID和用户对物品的评分。
有上下文信息的隐性反馈数据集 每一条记录包含用户ID、物品ID和用户对物品产生行为的时间戳。Lastfm数据集就是这种类型的数据集。
有上下文信息的显性反馈数据集 每一条记录包含用户ID、物品ID、用户对物品的评分和评分行为发生的时间戳。Netflix Prize提供的就是这种类型的数据集。本章使用的数据集基本都是第一种数据集,即无上下文信息的隐性反馈数据集。
2.2 用户行为分析
在利用用户行为数据设计推荐算法之前,研究人员首先需要对用户行为数据进行分析,了解数据中蕴含的一般规律,这样才能对算法的设计起到指导作用。本节将介绍用户行为数据中蕴含的一般规律,这些规律并不是只存在于一两个网站中的特例,而是存在于很多网站中的普遍规律。
2.2.1 用户活跃度和物品流行度的分布
很多关于互联网数据的研究发现,互联网上的很多数据分布都满足一种称为Power Law的分布,这个分布在互联网领域也称长尾分布。
长尾分布其实很早就被统计学家注意到了。1932年,哈佛大学的语言学家Zipf在研究英文单词的词频时发现,如果将单词出现的频率按照由高到低排列,则每个单词出现的频率和它在热门排行榜中排名的常数次幂成反比。这个分布称为Zipf定律。这个现象表明,在英文中大部分词的词频其实很低,只有很少的词被经常使用。
很多研究人员发现,用户行为数据也蕴含着这种规律。令fu(k)为对k个物品产生过行为的用户数,令fi(k)为被k个用户产生过行为的物品数。那么,fu(k)和fi(k)都满足长尾分布。也就是说: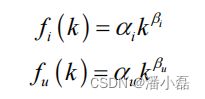
为了说明用户行为的长尾分布,我们选择Delicious和CiteULike数据集一个月的原始数据进行分析。这里,我们没有用Netflix或者MovieLens数据集是因为这两个数据集都经过了人为的清理,被清除了很多稀疏的数据,所以它们的分布不能反映网站的真实分布。图2-3展示了Delicious和CiteULike数据集中物品流行度的分布曲线。横坐标是物品的流行度K,纵坐标是流行度为K的物品的总数。这里,物品的流行度指对物品产生过行为的用户总数。图2-4展示了Delicious和CiteULike数据集中用户活跃度的分布曲线。横坐标是用户的活跃度K,纵坐标是活跃度为K的用户总数。这里,用户的活跃度为用户产生过行为的物品总数。


这两幅图都是双对数曲线,而长尾分布在双对数曲线上应该呈直线。这两幅图中的曲线都呈近似直线的形状,从而证明不管是物品的流行度还是用户的活跃度,都近似于长尾分布,特别是物品流行度的双对数曲线,非常接近直线。
2.2.2 用户活跃度和物品流行度的关系
一般来说,不活跃的用户要么是新用户,要么是只来过网站一两次的老用户。那么,不同活跃度的用户喜欢的物品的流行度是否有差别?一般认为,新用户倾向于浏览热门的物品,因为他们对网站还不熟悉,只能点击首页的热门物品,而老用户会逐渐开始浏览冷门的物品。图2-5展示了MovieLens数据集中用户活跃度和物品流行度之间的关系,其中横坐标是用户活跃度,纵坐标是具有某个活跃度的所有用户评过分的物品的平均流行度。如图2-5所示,图中曲线呈明显下降的趋势,这表明用户越活跃,越倾向于浏览冷门的物品。

仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法。学术界对协同过滤算法进行了深入研究,提出了很多方法,比如基于邻域的方法(neighborhood-based)、隐语义模型(latent factor model)、基于图的随机游走算法(random walk on graph)等。在这些方法中,最著名的、在业界得到最广泛应用的算法是基于邻域的方法,而基于邻域的方法主要包含下面两种算法
基于用户的协同过滤算法 这种算法给用户推荐和他兴趣相似的其他用户喜欢的物品。
基于物品的协同过滤算法 这种算法给用户推荐和他之前喜欢的物品相似的物品。
下面几节将首先介绍上面两种算法,然后再简单介绍隐语义模型和基于图的模型。、
2.3 实验设计和算法评测
前文说过,评测推荐系统有3种方法——离线实验、用户调查和在线实验。本节将通过离线实验方法评测提到的算法。首先介绍用到的数据集,然后介绍采用的实验方法和评测指标。
2.3.1 数据集
本章采用GroupLens提供的MovieLens数据集介绍和评测各种算法。 MovieLens数据集有3个不同的版本,本章选用中等大小的数据集。该数据集包含6000多用户对4000多部电影的100万条评分。该数据集是一个评分数据集,用户可以给电影评5个不同等级的分数(1~5分)。本章着重研究隐反馈数据集中的TopN推荐问题,因此忽略了数据集中的评分记录。也就是说,TopN推荐的任务是预测用户会不会对某部电影评分,而不是预测用户在准备对某部电影评分的前提下会给电影评多少分
2.3.2 实验设计
协同过滤算法的离线实验一般如下设计。首先,将用户行为数据集按照均匀分布随机分成M份(本章取M=8),挑选一份作为测试集,将剩下的M-1份作为训练集。然后在训练集上建立用户兴趣模型,并在测试集上对用户行为进行预测,统计出相应的评测指标。为了保证评测指标并不是过拟合的结果,需要进行M次实验,并且每次都使用不同的测试集。然后将M次实验测出的评测指标的平均值作为最终的评测指标。
下面的Python代码描述了将数据集随机分成训练集和测试集的过程:
def SplitData(data, M, k, seed):
test = []
train = []
random.seed(seed)
for user, item in data:
if random.randint(0,M) == k:
test.append([user,item])
else:
train.append([user,item])
return train, test
这里,每次实验选取不同的k(0≤k≤M-1)和相同的随机数种子seed,进行M次实验就可以得到M个不同的训练集和测试集,然后分别进行实验,用M次实验的平均值作为最后的评测指标。这样做主要是防止某次实验的结果是过拟合的结果(over fitting),但如果数据集够大,模型够简单,为了快速通过离线实验初步地选择算法,也可以只进行一次实验。
2.3.3 评测指标
对用户u推荐N个物品(记为R(u)),令用户u在测试集上喜欢的物品集合为T(u),然后可以通过准确率/召回率评测推荐算法的精度:
召回率描述有多少比例的用户—物品评分记录包含在最终的推荐列表中,而准确率描述最终的推荐列表中有多少比例是发生过的用户—物品评分记录。下面两段代码给出了召回率和准确率的计算方法。
def Recall(train, test, N):
hit = 0
all = 0
for user in train.keys():
tu = test[user]
rank = GetRecommendation(user, N)
for item, pui in rank:
if item in tu:
hit += 1
all += len(tu)
return hit / (all * 1.0)
def Precision(train, test, N):
hit = 0
all = 0
for user in train.keys():
tu = test[user]
rank = GetRecommendation(user, N)
for item, pui in rank:
if item in tu:
hit += 1
all += N
return hit / (all * 1.0)
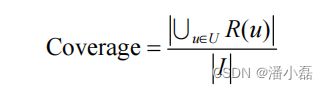
该覆盖率表示最终的推荐列表中包含多大比例的物品。如果所有的物品都被推荐给至少一个用户,那么覆盖率就是100%。如下代码可以用来计算推荐算法的覆盖率:
def Coverage(train, test, N):
recommend_items = set()
all_items = set()
for user in train.keys():
for item in train[user].keys():
all_items.add(item)
rank = GetRecommendation(user, N)
for item, pui in rank:
recommend_items.add(item)
return len(recommend_items) / (len(all_items) * 1.0)
最后,我们还需要评测推荐的新颖度,这里用推荐列表中物品的平均流行度度量推荐结果的新颖度。如果推荐出的物品都很热门,说明推荐的新颖度较低,否则说明推荐结果比较新颖。
def Popularity(train, test, N):
item_popularity = dict()
for user, items in train.items():
for item in items.keys()
if item not in item_popularity:
item_popularity[item] = 0
item_popularity[item] += 1
ret = 0
n = 0
for user in train.keys():
rank = GetRecommendation(user, N)
for item, pui in rank:
ret += math.log(1 + item_popularity[item])
n += 1
ret /= n * 1.0
return ret
这里,在计算平均流行度时对每个物品的流行度取对数,这是因为物品的流行度分布满足长尾分布,在取对数后,流行度的平均值更加稳定。
2.4 基于邻域的算法
基于邻域的算法是推荐系统中最基本的算法,该算法不仅在学术界得到了深入研究,而且在业界得到了广泛应用。基于邻域的算法分为两大类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法。下面几节将对这两种算法进行深入介绍,对比它们的优缺点并提出改进方案。
2.4.1 基于用户的协同过滤算法
基于用户的协同过滤算法是推荐系统中最古老的算法。可以不夸张地说,这个算法的诞生标志了推荐系统的诞生。该算法在1992年被提出,并应用于邮件过滤系统,1994年被GroupLens用于新闻过滤。在此之后直到2000年,该算法都是推荐系统领域最著名的算法。本节将对该算法进行详细介绍,首先介绍最基础的算法,然后在此基础上提出不同的改进方法,并通过真实的数据集进行评测。
1. 基础算法
每年新学期开始,刚进实验室的师弟总会问师兄相似的问题,比如“我应该买什么专业书啊”、“我应该看什么论文啊”等。这个时候,师兄一般会给他们做出一些推荐。这就是现实中个性化推荐的一种例子。在这个例子中,师弟可能会请教很多师兄,然后做出最终的判断。师弟之所以请教师兄,一方面是因为他们有社会关系,互相认识且信任对方,但更主要的原因是师兄和师弟有共同的研究领域和兴趣。那么,在一个在线个性化推荐系统中,当一个用户A需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A没有听说过的物品推荐给A。这种方法称为基于用户的协同过滤算法。
从上面的描述中可以看到,基于用户的协同过滤算法主要包括两个步骤。
(1) 找到和目标用户兴趣相似的用户集合。
(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
步骤(1)的关键就是计算两个用户的兴趣相似度。这里,协同过滤算法主要利用行为的相似度计算兴趣的相似度。给定用户u和用户v,令N(u)表示用户u曾经有过正反馈的物品集合,令N(v)为用户v曾经有过正反馈的物品集合。那么,我们可以通过如下的Jaccard公式简单地计算u和v的兴趣相似度:

或者通过余弦相似度计算:
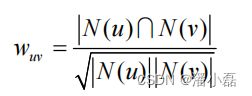
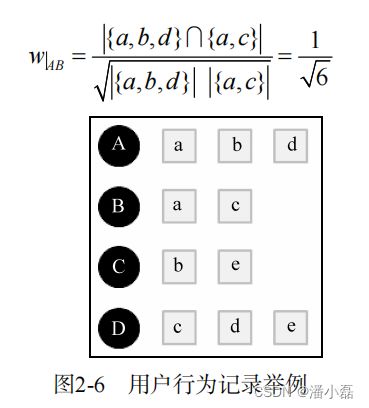
下面以图2-6中的用户行为记录为例,举例说明UserCF计算用户兴趣相似度的例子。在该例中,用户A对物品{a, b, d}有过行为,用户B对物品{a, c}有过行为,利用余弦相似度公式计算用户A和用户B的兴趣相似度为:
同理,我们可以计算出用户A和用户C、D的相似度:

以余弦相似度为例,实现该相似度可以利用如下的伪码:
def UserSimilarity(train):
W = dict()
for u in train.keys():
for v in train.keys():
if u == v:
continue
W[u][v] = len(train[u] & train[v])
W[u][v] /= math.sqrt(len(train[u]) * len(train[v]) * 1.0)
return W
该代码对两两用户都利用余弦相似度计算相似度。这种方法的时间复杂度是O(|U|*|U|),这在用户数很大时非常耗时。事实上,很多用户相互之间并没有对同样的物品产生过行为,即很多时候 交集为0 。上面的算法将很多时间浪费在了计算这种用户之间的相似度上。如果换一个思路,我们可以首先计算出交集不为零的用户对(u,v),然后再对这种情况除以并集 。
为此,可以首先建立物品到用户的倒排表,对于每个物品都保存对该物品产生过行为的用户列表。令稀疏矩阵和相似度矩阵相等 。那么,假设用户u和用户v同时属于倒排表中K个物品对应的用户列表,就有C[u][v]=K。从而,可以扫描倒排表中每个物品对应的用户列表,将用户列表中的两两用户对应的C[u][v]加1,最终就可以得到所有用户之间不为0的C[u][v]。下面的代码实现了上面提到的算法:
def UserSimilarity(train):
# build inverse table for item_users
item_users = dict()
for u, items in train.items():
for i in items.keys():
if i not in item_users:
item_users[i] = set()
item_users[i].add(u)
#calculate co-rated items between users
C = dict()
N = dict()
for i, users in item_users.items():
for u in users:
N[u] += 1
for v in users:
if u == v:
continue
C[u][v] += 1
#calculate finial similarity matrix W
W = dict()
for u, related_users in C.items():
for v, cuv in related_users.items():
W[u][v] = cuv / math.sqrt(N[u] * N[v])
return W
同样以图2-6中的用户行为为例解释上面的算法。首先,需要建立物品—用户的倒排表(如图2-7所示)。然后,建立一个4×4的用户相似度矩阵W,对于物品a,将W[A][B]和W[B][A]加1,对于物品b,将W[A][C]和W[C][A]加1,以此类推。扫描完所有物品后,我们可以得到最终的W矩阵。这里的W是余弦相似度中的分子部分,然后将W除以分母可以得到最终的用户兴趣相似度。

得到用户之间的兴趣相似度后,UserCF算法会给用户推荐和他兴趣最相似的K个用户喜欢的物品。如下的公式度量了UserCF算法中用户u对物品i的感兴趣程度:
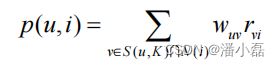
其中,S(u, K)包含和用户u兴趣最接近的K个用户,N(i)是对物品i有过行为的用户集合,wuv是用户u和用户v的兴趣相似度,rvi代表用户v对物品i的兴趣,因为使用的是单一行为的隐反馈数据,所以所有的rvi=1。
如下代码实现了上面的UserCF推荐算法:
def Recommend(user, train, W):
rank = dict()
interacted_items = train[user]
for v, wuv in sorted(W[u].items, key=itemgetter(1), \
reverse=True)[0:K]:
for i, rvi in train[v].items:
if i in interacted_items:
#we should filter items user interacted before
continue
rank[i] += wuv * rvi
return rank
利用上述算法,可以给图2-7中的用户A进行推荐。选取K=3,用户A对物品c、e没有过行为,因此可以把这两个物品推荐给用户A。根据UserCF算法,用户A对物品c、e的兴趣是:
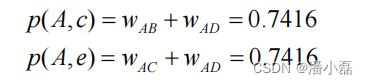
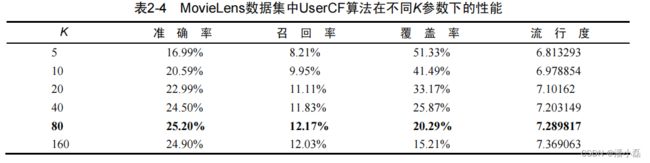
表2-4通过MovieLens数据集上的离线实验来评测基础算法的性能。UserCF只有一个重要的参数K,即为每个用户选出K个和他兴趣最相似的用户,然后推荐那K个用户感兴趣的物品。因此离线实验测量了不同K值下UserCF算法的性能指标。
为了反映该数据集上离线算法的基本性能,表2-5给出了两种基本推荐算法的性能。表中,Random算法每次都随机挑选10个用户没有产生过行为的物品推荐给当前用户,MostPopular算法则按照物品的流行度给用户推荐他没有产生过行为的物品中最热门的10个物品。这两种算法都是非个性化的推荐算法,但它们代表了两个极端。如表2-5所示,MostPopular算法的准确率和召回率远远高于Random算法,但它的覆盖率非常低,结果都非常热门。可见,Random算法的准确率和召回率很低,但覆盖度很高,结果平均流行度很低。

如表2-4和表2-5所示,UserCF的准确率和召回率相对MostPopular算法提高了将近1倍。同时,UserCF的覆盖率远远高于MostPopular,推荐结果相对MostPopular不太热门。同时可以发现参数K 是UserCF的一个重要参数,它的调整对推荐算法的各种指标都会产生一定的影响。
准确率和召回率 可以看到,推荐系统的精度指标(准确率和召回率)并不和参数K成线性关系。在MovieLens数据集中,选择K=80左右会获得比较高的准确率和召回率。因此选择合适的K对于获得高的推荐系统精度比较重要。当然,推荐结果的精度对K也不是特别敏感,只要选在一定的区域内,就可以获得不错的精度。
流行度 可以看到,在3个数据集上K越大则UserCF推荐结果就越热门。这是因为K决定了UserCF在给你做推荐时参考多少和你兴趣相似的其他用户的兴趣,那么如果K越大,参考的人越多,结果就越来越趋近于全局热门的物品。
覆盖率 可以看到,在3个数据集上,K越大则UserCF推荐结果的覆盖率越低。覆盖率的降低是因为流行度的增加,随着流行度增加,UserCF越来越倾向于推荐热门的物品,从而对长尾物品的推荐越来越少,因此造成了覆盖率的降低。
2. 用户相似度计算的改进
上一节介绍了计算用户兴趣相似度的最简单的公式(余弦相似度公式),但这个公式过于粗糙,本节将讨论如何改进该公式来提高UserCF的推荐性能。
首先,以图书为例,如果两个用户都曾经买过《新华字典》,这丝毫不能说明他们兴趣相似,因为绝大多数中国人小时候都买过《新华字典》。但如果两个用户都买过《数据挖掘导论》,那可以认为他们的兴趣比较相似,因为只有研究数据挖掘的人才会买这本书。换句话说,两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度。因此,John S. Breese在论文①中提出了如下公式,根据用户行为计算用户的兴趣相似度:
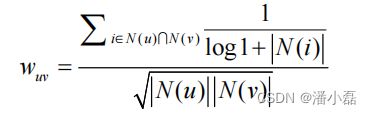
可以看到,该公式通过分子惩罚了用户u和用户v共同兴趣列表中热门物品对他们相似度的影响。
本书将基于上述用户相似度公式的UserCF算法记为User-IIF算法。下面的代码实现了上述用户相似度公式。
def UserSimilarity(train):
# build inverse table for item_users
item_users = dict()
for u, items in train.items():
for i in items.keys():
if i not in item_users:
item_users[i] = set()
item_users[i].add(u)
#calculate co-rated items between users
C = dict()
N = dict()
for i, users in item_users.items():
for u in users:
N[u] += 1
for v in users:
if u == v:
continue
C[u][v] += 1 / math.log(1 + len(users))
#calculate finial similarity matrix W
W = dict()
for u, related_users in C.items():
for v, cuv in related_users.items():
W[u][v] = cuv / math.sqrt(N[u] * N[v])
return W
同样,本节将通过实验评测UserCF-IIF的推荐性能,并将其和UserCF进行对比。在上一节的实验中,K=80时UserCF的性能最好,因此这里的实验同样选取K=80。
如表2-6所示,UserCF-IIF在各项性能上略优于UserCF。这说明在计算用户兴趣相似度时考虑物品的流行度对提升推荐结果的质量确实有帮助。

3. 实际在线系统使用UserCF的例子
相比我们后面要讨论的基于物品的协同过滤算法(ItemCF), UserCF在目前的实际应用中使用并不多。其中最著名的使用者是Digg,它在2008年对推荐系统进行了新的尝试。Digg使用推荐系统的原因也是信息过载,它的研究人员经过统计发现,每天大概会有15000篇新的文章,而每个用户的精力是有限的,而且兴趣差别很大。因此Digg觉得应该通过推荐系统帮用户从这么多篇文章中找到真正令他们感兴趣的内容,同时使每篇文章都有机会被展示给用户。
Digg的推荐系统设计思路如下。用户在Digg中主要通过“顶”和“踩”(如2-8所示,最左侧的两个手形按钮就是“顶”和“踩”的按钮)两种行为表达自己对文章的看法。当用户顶了一篇文章,Digg就认为该用户对这篇文章有兴趣,而且愿意把这篇文章推荐给其他用户。然后,Digg找到所有在该用户顶文章之前也顶了这一篇文章的其他用户,然后给他推荐那些人最近顶的其他文章。从这里的简单描述可以看到,Digg使用的是UserCF算法的简化版本。
Digg在博客中公布了使用推荐系统后的效果,主要指标如下所示。
用户反馈增加:用户“顶”和“踩”的行为增加了40%。
平均每个用户将从34个具相似兴趣的好友那儿获得200条推荐结果。
用户和好友的交互活跃度增加了24%。
用户评论增加了11%
当然,上面只是对比了使用推荐系统后和使用推荐系统前的结果,并非AB测试的结果,因此还不完全具有说服力,但还是部分证明了推荐系统的有效性。

2.4.2 基于物品的协同过滤算法
基于物品的协同过滤(item-based collaborative filtering)算法是目前业界应用最多的算法。无论是亚马逊网,还是Netflix、Hulu、YouTube,其推荐算法的基础都是该算法。本节将从基础的算法开始介绍,然后提出算法的改进方法,并通过实际数据集评测该算法。
1. 基础算法
基于用户的协同过滤算法在一些网站(如Digg)中得到了应用,但该算法有一些缺点。首先,随着网站的用户数目越来越大,计算用户兴趣相似度矩阵将越来越困难,其运算时间复杂度和空间复杂度的增长和用户数的增长近似于平方关系。其次,基于用户的协同过滤很难对推荐结果作出解释。因此,著名的电子商务公司亚马逊提出了另一个算法——基于物品的协同过滤算法①。
基于物品的协同过滤算法(简称ItemCF)给用户推荐那些和他们之前喜欢的物品相似的物品。比如,该算法会因为你购买过《数据挖掘导论》而给你推荐《机器学习》。不过,ItemCF算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度。该算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B。图2-9展示了亚马逊在iPhone商品界面上提供的与iPhone相关的商品,而相关商品都是购买iPhone的用户也经常购买的其他商品。
基于物品的协同过滤算法可以利用用户的历史行为给推荐结果提供推荐解释,比如给用户推荐《天龙八部》的解释可以是因为用户之前喜欢《射雕英雄传》。如2-10所示,Hulu在个性化视频推荐利用ItemCF给每个推荐结果提供了一个推荐解释,而用于解释的视频都是用户之前观看或者收藏过的视频。


基于物品的协同过滤算法主要分为两步。
(1) 计算物品之间的相似度。
(2) 根据物品的相似度和用户的历史行为给用户生成推荐列表。
图2-9上亚马逊显示相关物品推荐时的标题是“Customers Who Bought This Item Also Bought”(购买了该商品的用户也经常购买的其他商品)。从这句话的定义出发,我们可以用下面的公式定义物品的相似度: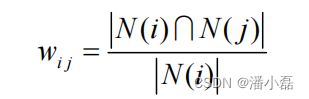
这里,分母|N(i)|是喜欢物品i的用户数,而分子 是同时喜欢物品i和物品j的用户数。因此,上述公式可以理解为喜欢物品i的用户中有多少比例的用户也喜欢物品j。
上述公式虽然看起来很有道理,但是却存在一个问题。如果物品j很热门,很多人都喜欢,那么Wij就会很大,接近1。因此,该公式会造成任何物品都会和热门的物品有很大的相似度,这对于致力于挖掘长尾信息的推荐系统来说显然不是一个好的特性。为了避免推荐出热门的物品,可以用下面的公式:
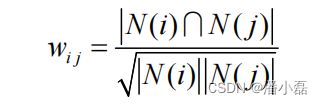
这个公式惩罚了物品j的权重,因此减轻了热门物品会和很多物品相似的可能性。
从上面的定义可以看到,在协同过滤中两个物品产生相似度是因为它们共同被很多用户喜欢,也就是说每个用户都可以通过他们的历史兴趣列表给物品“贡献”相似度。这里面蕴涵着一个假设,就是每个用户的兴趣都局限在某几个方面,因此如果两个物品属于一个用户的兴趣列表,那么这两个物品可能就属于有限的几个领域,而如果两个物品属于很多用户的兴趣列表,那么它们就可能属于同一个领域,因而有很大的相似度。
和UserCF算法类似,用ItemCF算法计算物品相似度时也可以首先建立用户—物品倒排表(即对每个用户建立一个包含他喜欢的物品的列表),然后对于每个用户,将他物品列表中的物品两两在共现矩阵C中加1。详细代码如下所示:
def ItemSimilarity(train):
#calculate co-rated users between items
C = dict()
N = dict()
for u, items in train.items():
for i in users:
N[i] += 1
for j in users:
if i == j:
continue
C[i][j] += 1
#calculate finial similarity matrix W
W = dict()
for i,related_items in C.items():
for j, cij in related_items.items():
W[u][v] = cij / math.sqrt(N[i] * N[j])
return W
图2-11是一个根据上面的程序计算物品相似度的简单例子。图中最左边是输入的用户行为记录,每一行代表一个用户感兴趣的物品集合。然后,对于每个物品集合,我们将里面的物品两两加一,得到一个矩阵。最终将这些矩阵相加得到上面的C矩阵。其中C[i][j]记录了同时喜欢物品i和物品j的用户数。最后,将C矩阵归一化可以得到物品之间的余弦相似度矩阵W。

表2-7展示了在MovieLens数据集上利用上面的程序计算电影之间相似度的结果。如表中结果所示,尽管在计算过程中没有利用任何内容属性,但利用ItemCF计算的结果却是可以从内容上看出某种相似度的。一般来说,同系列的电影、同主角的电影、同风格的电影、同国家和地区的电影会有比较大的相似度。

在得到物品之间的相似度后,ItemCF通过如下公式计算用户u对一个物品j的兴趣:

这里N(u)是用户喜欢的物品的集合,S(j,K)是和物品j最相似的K个物品的集合,wji是物品j和i的相似度,rui是用户u对物品i的兴趣。(对于隐反馈数据集,如果用户u对物品i有过行为,即可令rui=1。)该公式的含义是,和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。该公式的实现代码如下所示。
def Recommendation(train, user_id, W, K):
rank = dict()
ru = train[user_id]
for i,pi in ru.items():
for j, wj in sorted(W[i].items(), /
key=itemgetter(1), reverse=True)[0:K]:
if j in ru:
continue
rank[j] += pi * wj
return rank
图2-12是一个基于物品推荐的简单例子。该例子中,用户喜欢《C++ Primer中文版》和《编程之美》两本书。然后ItemCF会为这两本书分别找出和它们最相似的3本书,然后根据公式的定义计算用户对每本书的感兴趣程度。比如,ItemCF给用户推荐《算法导论》,是因为这本书和《C++ Primer中文版》相似,相似度为0.4,而且这本书也和《编程之美》相似,相似度是0.5。考虑到用户对《C++ Primer中文版》的兴趣度是1.3,对《编程之美》的兴趣度是0.9,那么用户对《算法导论》的兴趣度就是1.3 × 0.4 + 0.9×0.5 = 0.97。
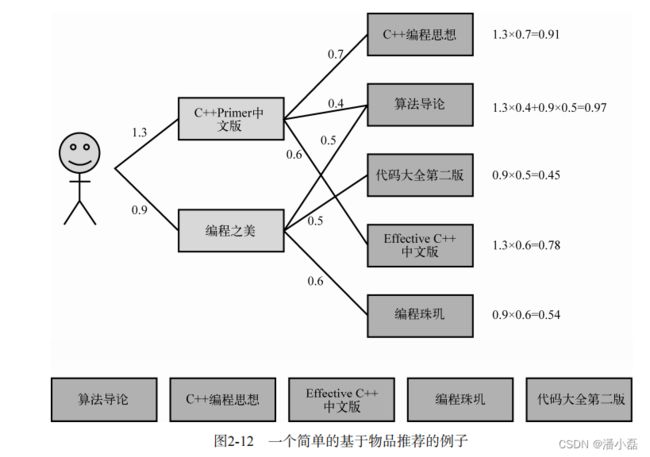
从这个例子可以看到,ItemCF的一个优势就是可以提供推荐解释,即利用用户历史上喜欢的物品为现在的推荐结果进行解释。如下代码实现了带解释的ItemCF算法:
def Recommendation(train, user_id, W, K):
rank = dict()
ru = train[user_id]
for i,pi in ru.items():
for j, wj in sorted(W[i].items(), /
key=itemgetter(1), reverse=True)[0:K]:
if j in ru:
continue
rank[j].weight += pi * wj
rank[j].reason[i] = pi * wj
return rank
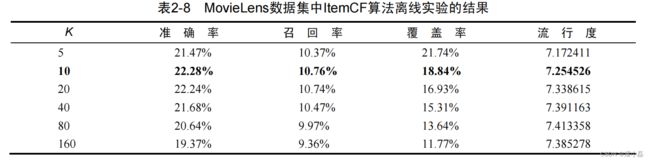
表2-8列出了在MovieLens数据集上ItemCF算法离线实验的各项性能指标的评测结果。该表包括算法在不同K值下的性能。根据表2-8中的数据我们可以得出如下结论。
精度(准确率和召回率) 可以看到ItemCF推荐结果的精度也是不和K成正相关或者负相关的,因此选择合适的K对获得最高精度是非常重要的。
流行度 和UserCF不同,参数K对ItemCF推荐结果流行度的影响也不是完全正相关的。随着K的增加,结果流行度会逐渐提高,但当K增加到一定程度,流行度就不会再有明显变化。
覆盖率 K增加会降低系统的覆盖率。
2. 用户活跃度对物品相似度的影响
从前面的讨论可以看到,在协同过滤中两个物品产生相似度是因为它们共同出现在很多用户的兴趣列表中。换句话说,每个用户的兴趣列表都对物品的相似度产生贡献。那么,是不是每个用户的贡献都相同呢?、
假设有这么一个用户,他是开书店的,并且买了当当网上80%的书准备用来自己卖。那么,他的购物车里包含当当网80%的书。假设当当网有100万本书,也就是说他买了80万本。从前面对ItemCF的讨论可以看到,这意味着因为存在这么一个用户,有80万本书两两之间就产生了相似度,也就是说,内存里即将诞生一个80万乘80万的稠密矩阵。
另外可以看到,这个用户虽然活跃,但是买这些书并非都是出于自身的兴趣,而且这些书覆盖了当当网图书的很多领域,所以这个用户对于他所购买书的两两相似度的贡献应该远远小于一个只买了十几本自己喜欢的书的文学青年。
John S. Breese在论文①中提出了一个称为IUF(Inverse User Frequence),即用户活跃度对数的倒数的参数,他也认为活跃用户对物品相似度的贡献应该小于不活跃的用户,他提出应该增加IUF参数来修正物品相似度的计算公式:
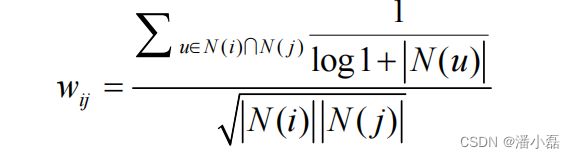
当然,上面的公式只是对活跃用户做了一种软性的惩罚,但对于很多过于活跃的用户,比如上面那位买了当当网80%图书的用户,为了避免相似度矩阵过于稠密,我们在实际计算中一般直接忽略他的兴趣列表,而不将其纳入到相似度计算的数据集中。
def ItemSimilarity(train):
#calculate co-rated users between items
C = dict()
N = dict()
for u, items in train.items():
for i in users:
N[i] += 1
for j in users:
if i == j:
continue
C[i][j] += 1 / math.log(1 + len(items) * 1.0)
#calculate finial similarity matrix W
W = dict()
for i,related_items in C.items():
for j, cij in related_items.items():
W[u][v] = cij / math.sqrt(N[i] * N[j])
return W
本书将上面的算法记为ItemCF-IUF,下面我们用离线实验评测这个算法。在这里我们不再考虑参数K的影响,而是将K选为在前面实验中取得最优准确率和召回率的值10。
如表2-9所示,ItemCF-IUF在准确率和召回率两个指标上和ItemCF相近,但ItemCF-IUF明显提高了推荐结果的覆盖率,降低了推荐结果的流行度。从这个意义上说,ItemCF-IUF确实改进了ItemCF的综合性能。

3. 物品相似度的归一化
Karypis在研究中发现如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确率。其研究表明,如果已经得到了物品相似度矩阵w,那么可以用如下公式得到归一化之后的相似度矩阵w’:
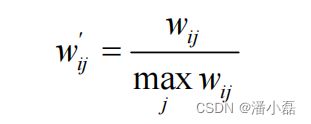
其实,归一化的好处不仅仅在于增加推荐的准确度,它还可以提高推荐的覆盖率和多样性。一般来说,物品总是属于很多不同的类,每一类中的物品联系比较紧密。举一个例子,假设在一个电影网站中,有两种电影——纪录片和动画片。那么,ItemCF算出来的相似度一般是纪录片和纪录片的相似度或者动画片和动画片的相似度大于纪录片和动画片的相似度。但是纪录片之间的相似度和动画片之间的相似度却不一定相同。假设物品分为两类——A和B,A类物品之间的相似度为0.5,B类物品之间的相似度为0.6,而A类物品和B类物品之间的相似度是0.2。在这种情况下,如果一个用户喜欢了5个A类物品和5个B类物品,用ItemCF给他进行推荐,推荐的就都是B类物品,因为B类物品之间的相似度大。但如果归一化之后,A类物品之间的相似度变成了1,B类物品之间的相似度也是1,那么这种情况下,用户如果喜欢5个A类物品和5个B类物品,那么他的推荐列表中A类物品和B类物品的数目也应该是大致相等的。从这个例子可以看出,相似度的归一化可以提高推荐的多样性。
那么,对于两个不同的类,什么样的类其类内物品之间的相似度高,什么样的类其类内物品相似度低呢?一般来说,热门的类其类内物品相似度一般比较大。如果不进行归一化,就会推荐比较热门的类里面的物品,而这些物品也是比较热门的。因此,推荐的覆盖率就比较低。相反,如果进行相似度的归一化,则可以提高推荐系统的覆盖率。
表2-10对比了ItemCF算法和ItemCF-Norm算法的离线实验性能。从实验结果可以看到,归一化确实能提高ItemCF的性能,其中各项指标都有了比较明显的提高。

2.4.3 UserCF和ItemCF的综合比较
UserCF是推荐系统领域较为古老的算法,1992年就已经在电子邮件的个性化推荐系统Tapestry中得到了应用,1994年被GroupLens用来实现新闻的个性化推荐,后来被著名的文章分享网站Digg用来给用户推荐个性化的网络文章。ItemCF则是相对比较新的算法,在著名的电子商
务网站亚马逊和DVD租赁网站Netflix中得到了广泛应用。
那么,为什么Digg使用UserCF,而亚马逊网使用ItemCF呢?
首先回顾一下UserCF算法和ItemCF算法的推荐原理。UserCF给用户推荐那些和他有共同兴趣爱好的用户喜欢的物品,而ItemCF给用户推荐那些和他之前喜欢的物品类似的物品。从这个算法的原理可以看到,UserCF的推荐结果着重于反映和用户兴趣相似的小群体的热点,而ItemCF的推荐结果着重于维系用户的历史兴趣。换句话说,UserCF的推荐更社会化,反映了用户所在的小型兴趣群体中物品的热门程度,而ItemCF的推荐更加个性化,反映了用户自己的兴趣传承。
在新闻网站中,用户的兴趣不是特别细化,绝大多数用户都喜欢看热门的新闻。即使是个性化,也是比较粗粒度的,比如有些用户喜欢体育新闻,有些喜欢社会新闻,而特别细粒度的个性化一般是不存在的。比方说,很少有用户只看某个话题的新闻,主要是因为这个话题不可能保证每天都有新的消息,而这个用户却是每天都要看新闻的。因此,个性化新闻推荐更加强调抓住新闻热点,热门程度和时效性是个性化新闻推荐的重点,而个性化相对于这两点略显次要。因此,UserCF可以给用户推荐和他有相似爱好的一群其他用户今天都在看的新闻,这样在抓住热点和时效性的同时,保证了一定程度的个性化。这是Digg在新闻推荐中使用UserCF的最重要原因。
UserCF适合用于新闻推荐的另一个原因是从技术角度考量的。因为作为一种物品,新闻的更新非常快,每时每刻都有新内容出现,而ItemCF需要维护一张物品相关度的表,如果物品更新很快,那么这张表也需要很快更新,这在技术上很难实现。绝大多数物品相关度表都只能做到一天一次更新,这在新闻领域是不可以接受的。而UserCF只需要用户相似性表,虽然UserCF对于新用户也需要更新相似度表,但在新闻网站中,物品的更新速度远远快于新用户的加入速度,而且对于新用户,完全可以给他推荐最热门的新闻,因此UserCF显然是利大于弊。
但是,在图书、电子商务和电影网站,比如亚马逊、豆瓣、Netflix中,ItemCF则能极大地发挥优势。首先,在这些网站中,用户的兴趣是比较固定和持久的。一个技术人员可能都是在购买技术方面的书,而且他们对书的热门程度并不是那么敏感,事实上越是资深的技术人员,他们看的书就越可能不热门。此外,这些系统中的用户大都不太需要流行度来辅助他们判断一个物品的好坏,而是可以通过自己熟悉领域的知识自己判断物品的质量。因此,这些网站中个性化推荐的任务是帮助用户发现和他研究领域相关的物品。因此,ItemCF算法成为了这些网站的首选算法。此外,这些网站的物品更新速度不会特别快,一天一次更新物品相似度矩阵对它们来说不会造成太大的损失,是可以接受的。
同时,从技术上考虑,UserCF需要维护一个用户相似度的矩阵,而ItemCF需要维护一个物品相似度矩阵。从存储的角度说,如果用户很多,那么维护用户兴趣相似度矩阵需要很大的空间,同理,如果物品很多,那么维护物品相似度矩阵代价较大。
在早期的研究中,大部分研究人员都是让少量的用户对大量的物品进行评价,然后研究用户兴趣的模式。那么,对于他们来说,因为用户很少,计算用户兴趣相似度是最快也是最简单的方法。但在实际的互联网中,用户数目往往非常庞大,而在图书、电子商务网站中,物品的数目则是比较少的。此外,物品的相似度相对于用户的兴趣一般比较稳定,因此使用ItemCF是比较好的选择。当然,新闻网站是个例外,在那儿,物品的相似度变化很快,物品数目庞大,相反用户兴趣则相对固定(都是喜欢看热门的),所以新闻网站的个性化推荐使用UserCF算法的更多。
表2-11从不同的角度对比了UserCF和ItemCF算法。同时,我们也将前面几节的离线实验结果展示在图2-13、图2-14和图2-15中。从图中可见,ItemCF算法在各项指标上似乎都不如UserCF,特别是其推荐结果的覆盖率和新颖度都低于UserCF,这一点似乎和我们之前讨论的不太符合。


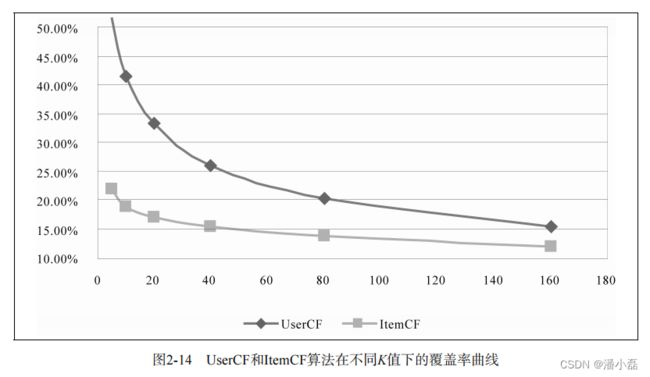

首先要指出的是,离线实验的性能在选择推荐算法时并不起决定作用。首先应该满足产品的需求,比如如果需要提供推荐解释,那么可能得选择ItemCF算法。其次,需要看实现代价,比如若用户太多,很难计算用户相似度矩阵,这个时候可能不得不抛弃UserCF算法。最后,离线指标和点击率等在线指标不一定成正比。而且,这里对比的是最原始的UserCF和ItemCF算法,这两种算法都可以进行各种各样的改进。一般来说,这两种算法经过优化后,最终得到的离线性能是近似的。
下一节将分析为什么原始ItemCF算法的覆盖率和新颖度都不高。
哈利波特问题
亚马逊网的研究人员在设计ItemCF算法之初发现ItemCF算法计算出的图书相关表存在一个问题,就是很多书都和《哈利波特》相关。也就是说,购买任何一本书的人似乎都会购买《哈利波特》。后来他们研究发现,主要是因为《哈利波特》太热门了,确实是购买任何一本书的人几乎都会购买它。
回顾一下ItemCF计算物品相似度的经典公式:
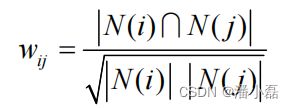
前面说过,如果j非常热门,那么上面公式的分子 就会越来越接近 N( i) 。尽管上面的公式分母已经考虑到了j的流行度,但在实际应用中,热门的j仍然会获得比较大的相似度。
哈利波特问题有几种解决方案。
第一种是最容易想到的,我们可以在分母上加大对热门物品的惩罚,比如采用如下公式:

其中α∈[0.5 ,1] 。通过提高α,就可以惩罚热门的j。
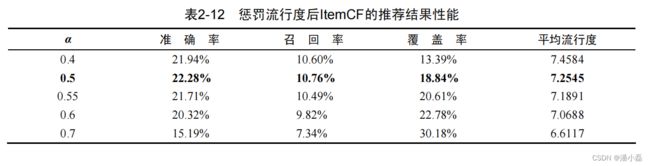
表2-12给出了选择不同的α惩罚热门物品后,ItemCF算法的推荐性能。这里,如果α=0.5就是标准的ItemCF算法。从离线实验结果可以看到,α只有在取值为0.5时才会导致最高的准确率和召回率,而无论α<0.5或者α>0.5都不会带来这两个指标的提高。但是,如果看覆盖率和平均流行度就可以发现,α越大,覆盖率就越高,并且结果的平均热门程度会降低。因此,通过这种方法可以在适当牺牲准确率和召回率的情况下显著提升结果的覆盖率和新颖性(降低流行度即提高了新颖性)。
不过,上述方法还不能彻底地解决哈利波特问题。每个用户一般都会在不同的领域喜欢一种物品。以电视为例,看新闻联播是父辈每天的必修课,他们每天基本就看新闻联播,而且每天不看别的新闻,就看这一种新闻。此外,他们很多都是电视剧迷,都会看央视一套8点的电视剧。那么,最终结果就是黄金时间的电视剧都和新闻联播相似,而新闻联播和其他新闻的相似度很低。
上面的问题换句话说就是,两个不同领域的最热门物品之间往往具有比较高的相似度。这个时候,仅仅靠用户行为数据是不能解决这个问题的,因为用户的行为表示这种物品之间应该相似度很高。此时,我们只能依靠引入物品的内容数据解决这个问题,比如对不同领域的物品降低权重等。这些就不是协同过滤讨论的范畴了。
2.5 隐语义模型
自从Netflix Prize比赛举办以来,LFM(latent factor model)隐语义模型逐渐成为推荐系统领域耳熟能详的名词。其实该算法最早在文本挖掘领域被提出,用于找到文本的隐含语义。相关的名词有LSI、pLSA、LDA和Topic Model。本节将对隐含语义模型在Top-N推荐中的应用进行详细介绍,并通过实际的数据评测该模型。
2.5.1 基础算法
隐语义模型是最近几年推荐系统领域最为热门的研究话题,它的核心思想是通过隐含特征(latent factor)联系用户兴趣和物品。
首先通过一个例子来理解一下这个模型。图2-16展示了两个用户在豆瓣的读书列表。
从他们的阅读列表可以看出,用户A的兴趣涉及侦探小说、科普图书以及一些计算机技术书,而用户B的兴趣比较集中在数学和机器学习方面。
那么如何给A和B推荐图书呢?
对于UserCF,首先需要找到和他们看了同样书的其他用户(兴趣相似的用户),然后给他们推荐那些用户喜欢的其他书。
对于ItemCF,需要给他们推荐和他们已经看的书相似的书,比如作者B看了很多关于数据挖掘的书,可以给他推荐机器学习或者模式识别方面的书。
还有一种方法,可以对书和物品的兴趣进行分类。对于某个用户,首先得到他的兴趣分类,然后从分类中挑选他可能喜欢的物品。
总结一下,这个基于兴趣分类的方法大概需要解决3个问题。
如何给物品进行分类?
如何确定用户对哪些类的物品感兴趣,以及感兴趣的程度?
对于一个给定的类,选择哪些属于这个类的物品推荐给用户,以及如何确定这些物品在一个类中的权重?
对于第一个问题的简单解决方案是找编辑给物品分类。以图书为例,每本书出版时,编辑都会给书一个分类。为了给图书分类,出版界普遍遵循中国图书分类法。但是,即使有很系统的分类体系,编辑给出的分类仍然具有以下缺点。

编辑的意见不能代表各种用户的意见。比如,对于《具体数学》应该属于什么分类,有人认为应该属于数学,有些人认为应该属于计算机。从内容看,这本书是关于数学的,但从用户看,这本书的读大部分是做计算机出身的。编辑的分类大部分是从书的内容出发,而不是从书的读者群出发。
编辑很难控制分类的粒度。我们知道分类是有不同粒度的,《数据挖掘导论》在粗粒度的分类中可能属于计算机技术,但在细粒度的分类中可能属于数据挖掘。对于不同的用户,我们可能需要不同的粒度。比如对于一位初学者,我们粗粒度地给他做推荐就可以了,而对于一名资深研究人员,我们就需要深入到他的很细分的领域给他做个性化推荐。
编辑很难给一个物品多个分类。有的书不仅属于一个类,而是可能属于很多的类。
编辑很难给出多维度的分类。我们知道,分类是可以有很多维度的,比如按照作者分类、按照译者分类、按照出版社分类。比如不同的用户看《具体数学》原因可能不同,有些人是因为它是数学方面的书所以才看的,而有些人是因为它是大师Knuth的著作所以才去看,因此在不同人的眼中这本书属于不同的分类。
编辑很难决定一个物品在某一个分类中的权重。比如编辑可以很容易地决定《数据挖掘导论》属于数据挖掘类图书,但这本书在这类书中的定位是什么样的,编辑就很难给出一个准确的数字来表示。
为了解决上面的问题,研究人员提出:为什么我们不从数据出发,自动地找到那些类,然后进行个性化推荐?于是,隐含语义分析技术(latent variable analysis)出现了。隐含语义分析技术因为采取基于用户行为统计的自动聚类,较好地解决了上面提出的5个问题。
编辑的意见不能代表各种用户的意见,但隐含语义分析技术的分类来自对用户行为的统计,代表了用户对物品分类的看法。隐含语义分析技术和ItemCF在物品分类方面的思想类似,如果两个物品被很多用户同时喜欢,那么这两个物品就很有可能属于同一个类。
编辑很难控制分类的粒度,但隐含语义分析技术允许我们指定最终有多少个分类,这个数字越大,分类的粒度就会越细,反正分类粒度就越粗。
编辑很难给一个物品多个分类,但隐含语义分析技术会计算出物品属于每个类的权重,因此每个物品都不是硬性地被分到某一个类中。
编辑很难给出多维度的分类,但隐含语义分析技术给出的每个分类都不是同一个维度的,它是基于用户的共同兴趣计算出来的,如果用户的共同兴趣是某一个维度,那么LFM给出的类也是相同的维度。
编辑很难决定一个物品在某一个分类中的权重,但隐含语义分析技术可以通过统计用户行为决定物品在每个类中的权重,如果喜欢某个类的用户都会喜欢某个物品,那么这个物品在这个类中的权重就可能比较高。
隐含语义分析技术从诞生到今天产生了很多著名的模型和方法,其中和该技术相关且耳熟能详的名词有pLSA、LDA、隐含类别模型(latent class model)、隐含主题模型(latent topic model)、矩阵分解(matrix factorization)。这些技术和方法在本质上是相通的,其中很多方法都可以用于个性化推荐系统。本章将以LFM为例介绍隐含语义分析技术在推荐系统中的应用。
LFM通过如下公式计算用户u对物品i的兴趣:

这个公式中 , pu k 和 , qi k 是模型的参数,其中 , pu k 度量了用户u的兴趣和第k个隐类的关系,而,qi k 度量了第k个隐类和物品i之间的关系。那么,下面的问题就是如何计算这两个参数。
对最优化理论或者机器学习有所了解的读者,可能对如何计算这两个参数都比较清楚。这两个参数是从数据集中计算出来的。要计算这两个参数,需要一个训练集,对于每个用户u,训练集里都包含了用户u喜欢的物品和不感兴趣的物品,通过学习这个数据集,就可以获得上面的模型参数。
推荐系统的用户行为分为显性反馈和隐性反馈。LFM在显性反馈数据(也就是评分数据)上解决评分预测问题并达到了很好的精度。不过本章主要讨论的是隐性反馈数据集,这种数据集的特点是只有正样本(用户喜欢什么物品),而没有负样本(用户对什么物品不感兴趣)。
那么,在隐性反馈数据集上应用LFM解决TopN推荐的第一个关键问题就是如何给每个用户生成负样本。
对于这个问题,Rong Pan在文章中进行了深入探讨。他对比了如下几种方法。
对于一个用户,用他所有没有过行为的物品作为负样本。
对于一个用户,从他没有过行为的物品中均匀采样出一些物品作为负样本。
对于一个用户,从他没有过行为的物品中采样出一些物品作为负样本,但采样时,保证每个用户的正负样本数目相当。
对于一个用户,从他没有过行为的物品中采样出一些物品作为负样本,但采样时,偏重采样不热门的物品。
对于第一种方法,它的明显缺点是负样本太多,正负样本数目相差悬殊,因而计算复杂度很高,最终结果的精度也很差。对于另外3种方法,Rong Pan在文章中表示第三种好于第二种,而第二种好于第四种。
后来,通过2011年的KDD Cup的Yahoo! Music推荐系统比赛,我们发现对负样本采样时应该遵循以下原则。
对每个用户,要保证正负样本的平衡(数目相似)。
对每个用户采样负样本时,要选取那些很热门,而用户却没有行为的物品。
一般认为,很热门而用户却没有行为更加代表用户对这个物品不感兴趣。因为对于冷门的物品,用户可能是压根没在网站中发现这个物品,所以谈不上是否感兴趣。
下面的Python代码实现了负样本采样过程②:
def RandomSelectNegativeSample(self, items):
ret = dict()
for i in items.keys():
ret[i] = 1
n = 0
for i in range(0, len(items) * 3):
item = items_pool[random.randint(0, len(items_pool) - 1)]
if item in ret:
continue
ret[item] = 0
n + = 1
if n > len(items):
break
return ret
在上面的代码中,items_pool维护了候选物品的列表,在这个列表中,物品i出现的次数和物品i的流行度成正比。items是一个dict,它维护了用户已经有过行为的物品的集合。因此,上面的代码按照物品的流行度采样出了那些热门的、但用户却没有过行为的物品。经过采样,可以得到一个用户—物品集K={(u,i)} ,其中如果(u, i)是正样本,则有 rui = 1,否则有 rui = 0 。然后,需要优化如下的损失函数来找到最合适的参数p和q:
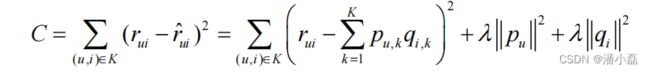
这里, λp+λq是用来防止过拟合的正则化项,λ可以通过实验获得。要最小化上面的损失函数,可以利用一种称为随机梯度下降法①的算法。该算法是最优化理论里最基础的优化算法,它首先通过求参数的偏导数找到最速下降方向,然后通过迭代法不断地优化参数。下面介绍优化方法的数学推导。
上面定义的损失函数里有两组参数puk和qik,随机梯度下降法需要首先对它们分别求偏导数,可以得到:

然后,根据随机梯度下降法,需要将参数沿着最速下降方向向前推进,因此可以得到如下递推公式:

其中,α是学习速率(learning rate),它的选取需要通过反复实验获得。
下面的Python代码实现了这一优化过程:
def LatentFactorModel(user_items, F, N, alpha, lambda):
[P, Q] = InitModel(user_items, F)
for step in range(0,N):
for user, items in user_items.items():
samples = RandSelectNegativeSamples(items)
for item, rui in samples.items():
eui = rui - Predict(user, item)
for f in range(0, F):
P[user][f] += alpha * (eui * Q[item][f] - \
lambda * P[user][f])
Q[item][f] += alpha * (eui * P[user][f] - \
lambda * Q[item][f])
alpha *= 0.9
def Recommend(user, P, Q):
rank = dict()
for f, puf in P[user].items():
for i, qfi in Q[f].items():
if i not in rank:
rank[i] += puf * qfi
return rank
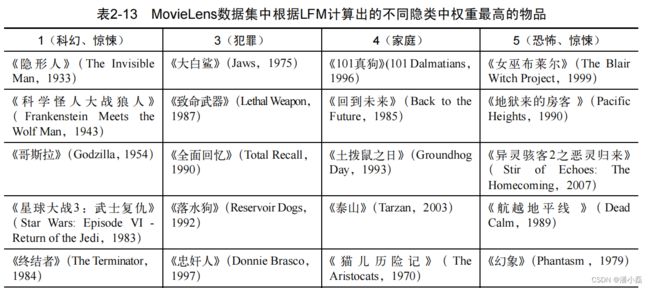
我们同样通过离线实验评测LFM的性能。首先,我们在MovieLens数据集上用LFM计算出用户兴趣向量p和物品向量q,然后对于每个隐类找出权重最大的物品。如表2-13所示,表中展示了4个隐类中排名最高(qik最大)的一些电影。结果表明,每一类的电影都是合理的,都代表了一类用户喜欢看的电影。从而说明LFM确实可以实现通过用户行为将物品聚类的功能。
其次,我们通过实验对比了LFM在TopN推荐中的性能。在LFM中,重要的参数有4个:
隐特征的个数F; 学习速率alpha; 正则化参数lambda; 负样本/正样本比例 ratio。
通过实验发现,ratio参数对LFM的性能影响最大。因此,固定F=100、alpha=0.02、lambda=0.01,然后研究负样本/正样本比例ratio对推荐结果性能的影响。
如表2-14所示,随着负样本数目的增加,LFM的准确率和召回率有明显提高。不过当ratio>10以后,准确率和召回率基本就比较稳定了。同时,随着负样本数目的增加,覆盖率不断降低,而推荐结果的流行度不断增加,说明ratio参数控制了推荐算法发掘长尾的能力。如果将LFM的结果与表2-6、表2-9、表2-10中ItemCF和UserCF算法的性能相比,可以发现LFM在所有指标上都优于UserCF和ItemCF。当然,这只是在MovieLens一个数据集上的结果,我们也发现,当数据集非常稀疏时,LFM的性能会明显下降,甚至不如UserCF和ItemCF的性能。关于这一点读者可以通过实验自己研究。

2.5.2 基于LFM的实际系统的例子
雅虎的研究人员公布过一个使用LFM进行雅虎首页个性化设计的方案①。本节将简单介绍他们的设计并讨论他们的设计方案。
图2-17展示了雅虎首页的界面。该页面包括不同的模块,比如左侧的分类导航列表、中间的热门新闻列表、右侧的最近热门话题列表。雅虎的研究人员认为这3个模块都可以进行一定的个性化,可以根据用户的兴趣给他们展示不同的内容。
雅虎的研究人员以CTR作为优化目标,利用LFM来预测用户是否会单击一个链接。为此,他们将用户历史上对首页上链接的行为记录作为训练集。其中,如果用户u单击过链接i,那么就定义(u, i)是正样本,即rui = 1。如果链接i展示给用户u,但用户u从来没有单击过,那么就定义(u, i)是负样本,即rui = -1。然后,雅虎的研究人员利用前文提到的LFM预测用户是否会单击链接:
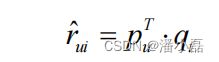
当然,雅虎的研究人员在上面的模型基础上进行了一些修改,利用了一些改进的LFM模型。这些模型主要来自Netflix Prize比赛,因此我们会在第8章详细讨论这些模型。

但是,LFM模型在实际使用中有一个困难,那就是它很难实现实时的推荐。经典的LFM模型每次训练时都需要扫描所有的用户行为记录,这样才能计算出用户隐类向量(pu)和物品隐类向量(qi)。而且LFM的训练需要在用户行为记录上反复迭代才能获得比较好的性能。因此,LFM的每次训练都很耗时,一般在实际应用中只能每天训练一次,并且计算出所有用户的推荐结果。从而LFM模型不能因为用户行为的变化实时地调整推荐结果来满足用户最近的行为。在新闻推荐中,冷启动问题非常明显。每天都会有大量新的新闻。这些新闻会在很短的时间内获得很多人的关注,但也会在很短的时间内失去用户的关注。因此,它们的生命周期很短,而推荐算法需要在它们短暂的生命周期内就将其推荐给对它们感兴趣的用户。所以,实时性在雅虎的首页个性化推荐系统中非常重要。为了解决传统LFM不能实时化,而产品需要实时性的矛盾,雅虎的研究人员提出了一个解决方案。
他们的解决方案分为两个部分。首先,他们利用新闻链接的内容属性(关键词、类别等)得到链接i的内容特征向量yi。其次,他们会实时地收集用户对链接的行为,并且用这些数据得到链接i的隐特征向量qi。然后,他们会利用如下公式预测用户u是否会单击链接i:
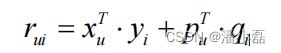
其中,yi是根据物品的内容属性直接生成的,xuk是用户u对内容特征k的兴趣程度,用户向量Xu可以根据历史行为记录获得,而且每天只需要计算一次。而pu、qi是根据实时拿到的用户最近几小时的行为训练LFM获得的。因此,对于一个新加入的物品i,可以通过 xu i * y 估计用户u对物品i的兴趣,然后经过几个小时后,就可以通过 pu*qi 得到更加准确的预测值。
上面的讨论只是简单阐述了雅虎所用的方法,关于雅虎具体的方法可以参考他们的报告。
2.5.3 LFM和基于邻域的方法的比较
LFM是一种基于机器学习的方法,具有比较好的理论基础。这个方法和基于邻域的方法(比如UserCF、ItemCF)相比,各有优缺点。下面将从不同的方面对比LFM和基于邻域的方法。
理论基础 LFM具有比较好的理论基础,它是一种学习方法,通过优化一个设定的指标建立最优的模型。基于邻域的方法更多的是一种基于统计的方法,并没有学习过程。
离线计算的空间复杂度 基于邻域的方法需要维护一张离线的相关表。在离线计算相关表的过程中,如果用户/物品数很多,将会占据很大的内存。假设有M个用户和N个物品,在计算相关表的过程中,我们可能会获得一张比较稠密的临时相关表(尽管最终我们对每个物品只保留K个最相关的物品,但在中间计算过程中稠密的相关表是不可避免的),那么假设是用户相关表,则需要O(MM)的空间,而对于物品相关表,则需要O(NN)的空间。而LFM在建模过程中,如果是F个隐类,那么它需要的存储空间是O(F*(M+N)),这在M和N很大时可以很好地节省离线计算的内存。在Netflix Prize中,因为用户数很庞大(40多万),很少有人使用UserCF算法(据说需要30 GB左右的内存),而LFM由于大量节省了训练过程中的内存(只需要4GB),从而成为Netflix Prize中最流行的算法。
离线计算的时间复杂度 假设有M个用户、N个物品、K条用户对物品的行为记录。那么,UserCF计算用户相关表的时间复杂度是O(N * (K/N)2),而ItemCF计算物品相关表的时间复杂度是O(M*(K/M)2)。而对于LFM,如果用F个隐类,迭代S次,那么它的计算复杂度是O(K * F * S)。那么,如果K/N > FS,则代表UserCF的时间复杂度低于LFM,如果K/M>FS,则说明ItemCF的时间复杂度低于LFM。在一般情况下,LFM的时间复杂度要稍微高于UserCF和ItemCF,这主要是因为该算法需要多次迭代。但总体上,这两种算法在时间复杂度上没有质的差别。
在线实时推荐 UserCF和ItemCF在线服务算法需要将相关表缓存在内存中,然后可以在线进行实时的预测。以ItemCF算法为例,一旦用户喜欢了新的物品,就可以通过查询内存中的相关表将和该物品相似的其他物品推荐给用户。因此,一旦用户有了新的行为,而且该行为被实时地记录到后台的数据库系统中,他的推荐列表就会发生变化。而从LFM的预测公式可以看到,LFM在给用户生成推荐列表时,需要计算用户对所有物品的兴趣权重,然后排名,返回权重最大的N个物品。那么,在物品数很多时,这一过程的时间复杂度非常高,可达O(MNF)。因此,LFM不太适合用于物品数非常庞大的系统,如果要用,我们也需要一个比较快的算法给用户先计算一个比较小的候选列表,然后再用LFM重新排名。另一方面,LFM在生成一个用户推荐列表时速度太慢,因此不能在线实时计算,而需要离线将所有用户的推荐结果事先计算好存储在数据库中。因此,LFM不能进行在线实时推荐,也就是说,当用户有了新的行为后,他的推荐列表不会发生变化。
推荐解释 ItemCF算法支持很好的推荐解释,它可以利用用户的历史行为解释推荐结果。但LFM无法提供这样的解释,它计算出的隐类虽然在语义上确实代表了一类兴趣和物品,却很难用自然语言描述并生成解释展现给用户。
2.6 基于图的模型
用户行为很容易用二分图表示,因此很多图的算法都可以用到推荐系统中。本节将重点讨论如何将用户行为用图表示,并利用图的算法给用户进行个性化推荐。
2.6.1 用户行为数据的二分图表示
基于图的模型(graph-based model)是推荐系统中的重要内容。其实,很多研究人员把基于邻域的模型也称为基于图的模型,因为可以把基于邻域的模型看做基于图的模型的简单形式。
在研究基于图的模型之前,首先需要将用户行为数据表示成图的形式。本章讨论的用户行为数据是由一系列二元组组成的,其中每个二元组(u, i)表示用户u对物品i产生过行为。这种数据集很容易用一个二分图①表示。
令G(V,E)表示用户物品二分图,其中 V=Vu∪Vi 由用户顶点集合Vu 和物品顶点集合Vi组成。对于数据集中每一个二元组(u, i),图中都有一套对应的边e(Vu,Vi),其中vu∈VU是用户u对应的顶点,vi∈VI 是物品i对应的顶点。图2-18是一个简单的用户物品二分图模型,其中圆形节点代表用户,方形节点代表物品,圆形节点和方形节点之间的边代表用户对物品的行为。比如图中用户节点A和物品节点a、b、d相连,说明用户A对物品a、b、d产生过行为。

2.6.2 基于图的推荐算法
将用户行为表示为二分图模型后,下面的任务就是在二分图上给用户进行个性化推荐。如果将个性化推荐算法放到二分图模型上,那么给用户u推荐物品的任务就可以转化为度量用户顶点vu和与vu没有边直接相连的物品节点在图上的相关性,相关性越高的物品在推荐列表中的权重就越高。
度量图中两个顶点之间相关性的方法很多,但一般来说图中顶点的相关性主要取决于下面3个因素:
两个顶点之间的路径数;
两个顶点之间路径的长度;
两个顶点之间的路径经过的顶点。
而相关性高的一对顶点一般具有如下特征:
两个顶点之间有很多路径相连;
连接两个顶点之间的路径长度都比较短;
连接两个顶点之间的路径不会经过出度比较大的顶点。
举一个简单的例子,如图2-19所示,用户A和物品c、e没有边相连,但是用户A和物品c有两条长度为3的路径相连,用户A和物品e有两条长度为3的路径相连。那么,顶点A与e之间的相关性要高于顶点A与c,因而物品e在用户A的推荐列表中应该排在物品c之前,因为顶点A与e之间有两条路径——(A, b, C, e)和(A, d, D, e)。其中,(A, b, C, e)路径经过的顶点的出度为(3, 2, 2, 2),而(A, d, D, e)路径经过的顶点的出度为(3, 2, 3, 2)。因此,(A, d, D, e)经过了一个出度比较大的顶点D,所以(A, d, D, e)对顶点A与e之间相关性的贡献要小于(A, b, C, e)。

基于上面3个主要因素,研究人员设计了很多计算图中顶点之间相关性的方法。本节将介绍一种基于随机游走的PersonalRank算法。
假设要给用户u进行个性化推荐,可以从用户u对应的节点vu开始在用户物品二分图上进行随机游走。游走到任何一个节点时,首先按照概率α决定是继续游走,还是停止这次游走并从vu节点开始重新游走。如果决定继续游走,那么就从当前节点指向的节点中按照均匀分布随机选择一个节点作为游走下次经过的节点。这样,经过很多次随机游走后,每个物品节点被访问到的概率会收敛到一个数。最终的推荐列表中物品的权重就是物品节点的访问概率。
如果将上面的描述表示成公式,可以得到如下公式:
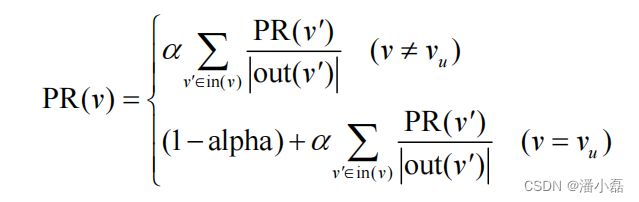
下面的Python代码简单实现了上面的公式:
def PersonalRank(G, alpha, root):
rank = dict()
rank = {x:0 for x in G.keys()}
rank[root] = 1
for k in range(20):
tmp = {x:0 for x in G.keys()}
for i, ri in G.items():
for j, wij in ri.items():
if j not in tmp:
tmp[j] = 0
tmp[j] += 0.6 * rank[i] / (1.0 * len(ri))
if j == root:
tmp[j] += 1 - alpha
rank = tmp
return rank
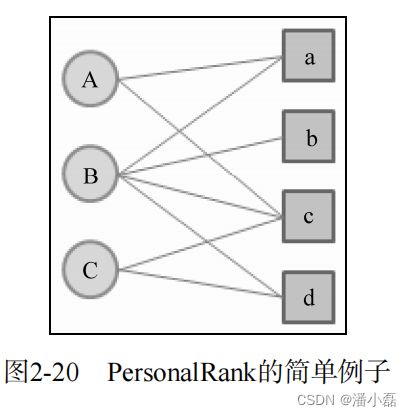
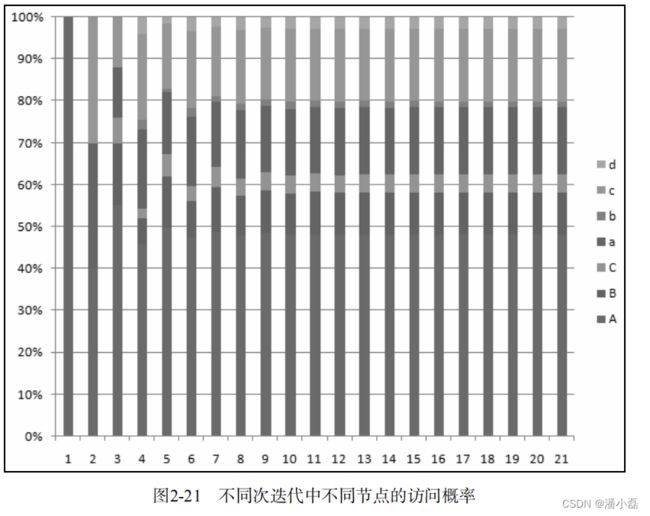
我们用上面的代码跑了一下图2-20的例子,给A用户进行推荐。图2-21给出了不同迭代次数后每个顶点的访问概率。从图中可以看到,每个顶点的访问概率在9次迭代之后就基本上收敛了。在这个例子中,用户A没有对物品b、d有过行为。在最后的迭代结果中,d的访问概率大于b,因此给A的推荐列表就是{d, b}。
本节在MovieLens的数据集上评测了PersonalRank算法,实验结果如表2-15所示。

虽然PersonalRank算法可以通过随机游走进行比较好的理论解释,但该算法在时间复杂度上有明显的缺点。因为在为每个用户进行推荐时,都需要在整个用户物品二分图上进行迭代,直到整个图上的每个顶点的PR值收敛。这一过程的时间复杂度非常高,不仅无法在线提供实时推荐,甚至离线生成推荐结果也很耗时。
为了解决PersonalRank每次都需要在全图迭代并因此造成时间复杂度很高的问题,这里给出两种解决方案。第一种很容易想到,就是减少迭代次数,在收敛之前就停止。这样会影响最终的精度,但一般来说影响不会特别大。另一种方法就是从矩阵论出发,重新设计算法。
对矩阵运算比较熟悉的读者可以轻松将PersonalRank转化为矩阵的形式。令M为用户物品二分图的转移概率矩阵,即:

那么,迭代公式可以转化为:
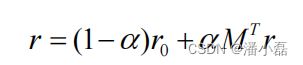
对矩阵论稍微熟悉的读者都可以解出上面的方程,得到:
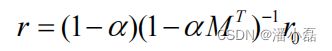
因此,只需要计算一次 (1-αMT)-1 ,这里1-αMT 是稀疏矩阵。关于如何对稀疏矩阵快速求逆,可以参考矩阵计算方面的书籍和论文,本书就不再讨论了。