32位ALU设计(verilog实现)
32位ALU设计
算术逻辑单元(arithmetic and logic unit) 是能实现多组算术运算和逻辑运算的组合逻辑电路,简称ALU。算术逻辑单元是中央处理器(CPU)的执行单元,是所有中央处理器的核心组成部分,由"And Gate"(与门) 和"Or Gate"(或门)构成的算术逻辑单元,主要功能是进行二位元的算术运算,如加减乘(不包括整数除法)。基本上,在所有现代CPU体系结构中,二进制都以补码的形式来表示。
- 设计思路
- 设计实现
- 仿真测试
文章目录
- 32位ALU设计
-
- 一、设计思路
-
- 1. 算术运算
- 2. 逻辑运算
- 3.比较运算
- 4.移位运算
- 二、设计实现
- 三、仿真测试
- 四、模块设计
-
- 1. CLA_adder32
-
- (1). 简单实现
- (2). 超前进位加法器(Carry-lookahead adder)
一、设计思路
1. 算术运算
-
addu、subu
addu: 最高有效位向高位有进位,产生进位carryout
subu: 当被减数小于减数时,最高有效位向高位有借位,产生借位carryout
-
add、sub
[x]补+[y]补=[x+y]补[x-y]补=[x]补-[y]补=[x]补+[-y]补[-y补]=~[y]补+1add溢出:两个正数相加产生负数
0111(7)+0110(6)=1101 两个负数相加产生正数
1000(-8)+1001(-7)=0001 一个正数与一个负数相加不产生溢出
sub溢出:正数 - 正数(不产生溢出)
正数 - 负数,结果为负数(上溢)
负数 - 负数(不产生溢出)
负数 - 正数,结果为正数(下溢)
2. 逻辑运算
~:按位取反
&(and):按位与操作
|(or):按位或操作
^(xor):按位异或操作
~(|)(nor):按位或非操作
指令对标志位影响:指令执行后,CF和OF置0,ZF根据结果是否为0设置
3.比较运算
-
有符号数比较 slt
指令对标志位影响:in0小于in1置CF为1in0为正数,in1为负数,out为0
in0为负数,in1为正数,out为1
in0和in1为负数,alu进行补码运算,1111(-1)、1110(-2),直接进行数值比较的结果与其代表的有符号数比较结果相同
in0和in1为正数,直接进行比较
通过分析,后两种情况可以合并
-
无符号数比较 sltu
可直接进行比较
指令对标志位影响:in0小于in1置OF为1
4.移位运算
-
逻辑左移shl (shift logical left):sll,sllv
将数据向左移动,最低位用0补充
-
逻辑右移shr (shift logical right):srl,srlv
将数据向右移动,最高位用0补充
-
算术右移sar (shift arithmetic right):sra,srav
将各位依次右移指定位数,然后在左侧用原符号位补齐
指令对标志的影响:将最后移出的移位写入CF
总结来说,这六条移位操作指令可以分为两种情况:sllv、srav、srlv这3条指令的助记符最后有“v”,表示移位位数是通过寄存器的值确定的,sll、sra、srl这3条指令的助记符最后没有“v”,表示移位位数就是指令中6-10bit的sa的值。通过循环的方式,将移位后还在[31:0]部分的位置移到新的rd中,其他位置补上应补的0或1。
二、设计实现
module ALU32(
op,in0,in1,
carryout,overflow,zero,out
);
input [31:0] in0,in1;
input [10:0] op;
output reg[31:0] out;
output reg carryout,overflow,zero;
always@(*)
begin
case(op)
//add
11'b00000100000:
begin
out=in0+in1;
overflow=((in0[31]==in1[31])&&(~out[31]==in0[31]))?1:0;
zero=(out==0)?1:0;
carryout=0;
end
//addu
11'b00000100001:
begin
{carryout,out}=in0+in1;
zero=(out==0)?1:0;
overflow=0;
end
//sub
11'b00000100010:
begin
out=in0-in1;
overflow=((in0[31]==0&&in1[31]==1&&out[31]==1)|| (in0[31]==1&&in1[31]==0&&out[31]==0))?1:0;
zero=(in0==in1)?1:0;
carryout=0;
end
//subu
11'b00000100011:
begin
{carryout,out}=in0-in1;
zero=(out==0)?1:0;
overflow=0;
end
//and
11'b00000100100:
begin
out=in0&in1;
zero=(out==0)?1:0;
carryout=0;
overflow=0;
end
//or
11'b00000100101:
begin
out=in0|in1;
zero=(out==0)?1:0;
carryout=0;
overflow=0;
end
//xor
11'b00000100110:
begin
out=in0^in1;
zero=(out==0)?1:0;
carryout=0;
overflow=0;
end
//nor
11'b00000100111:
begin
out=~(in0|in1);
zero=(out==0)?1:0;
carryout=0;
overflow=0;
end
//slt
11'b00000101010:
begin
if(in0[31]==1&&in1[31]==0)
out=1;
else if(in0[31]==0&&in1[31]==1)
out=0;
else
out=(in0>in1;
carryout=in0[in1-1];
overflow=0;
zero=(out==0)?1:0;
end
//sar
11'b00000000111:
begin
out=($signed(in0))>>>in1;
carryout=in0[in1-1];
overflow=0;
zero=(out==0)?1:0;
end
endcase
end
endmodule
module ALU32_test(
);
reg [10:0] op;
reg [31:0] in0,in1;
wire [31:0] out;
wire carryout,overflow,zero;
ALU32 alu(op,in0,in1,carryout,overflow,zero,out);
initial
begin
//add
op=11'b00000100000;
in0=32'hf2340000;
in1=32'h80000000;
#20 in0=32'h7fffffff;
in1=32'h70000001;
#20 in0=32'h7fffffff;
in1=32'hf0000001;
#20 in0=32'hffffffff;
in1=32'h00000001;
//addu
#20 op=11'b00000100001;
in0=32'hf2340000;
in1=32'h80000000;
#20 in0=32'h7fffffff;
in1=32'h70000001;
#20 in0=32'hffffffff;
in1=32'h00000001;
//sub
#20 op=11'b00000100010;
in0=32'h72340000;
in1=32'h60000000;
#20 in0=32'h7fffffff;
in1=32'hf0000001;
#20 in0=32'hf00fffff;
in1=32'h7ffffff1;
#20 in0=32'hffffffff;
in1=32'hffffffff;
#20 in0=32'hf0000000;
in1=32'h0fffffff;
//subu
#20 op=11'b00000100011;
in0=32'h72340000;
in1=32'h60000000;
#20 in0=32'h7fffffff;
in1=32'hf0000001;
#20 in0=32'hffffffff;
in1=32'hffffffff;
#20 in0=32'hf0000000;
in1=32'h0fffffff;
//and
#20 op=11'b00000100100;
in0=32'h72340000;
in1=32'h60000000;
#20 in0=32'h7fffffff;
in1=32'h00000000;
//or
#20 op=11'b00000100101;
in0=32'h00000000;
in1=32'h00000000;
#20 in0=32'h7fffffff;
in1=32'hf0000001;
//xor
#20 op=11'b00000100110;
in0=32'ha0000000;
in1=32'h50000000;
#20 in0=32'h7fffffff;
in1=32'hf0000001;
//nor
#20 op=11'b00000100111;
in0=32'h123451ff;
in1=32'h60000000;
#20 in0=32'h7fffffff;
in1=32'hf0000001;
//slt
#20 op=11'b00000101010;
in0=32'h72340000;
in1=32'hf0000000;
#20 in0=32'h7000000f;
in1=32'h7f000001;
#20 in0=32'hf0001231;
in1=32'h7ac34545;
//sltu
#20 op=11'b00000101011;
in0=32'h72340000;
in1=32'hf0000000;
#20 in0=32'h7000000f;
in1=32'h7f000001;
#20 in0=32'hf0001231;
in1=32'h7ac34545;
//shl
#20 op=11'b00000000100;
in0=32'hffffffff;
in1=32'd5;
//shr
#20 op=11'b00000000110;
in0=32'hffffffff;
in1=32'd5;
//sar
#20 op=11'b00000000111;
in0=32'hffffffff;
in1=32'd3;
#20 in0=32'h0fffffff;
in1=32'd5;
end
endmodule
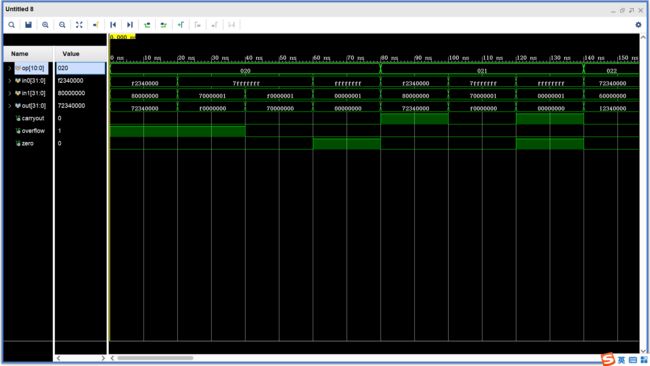
三、仿真测试
- add、addu
- sub、subu
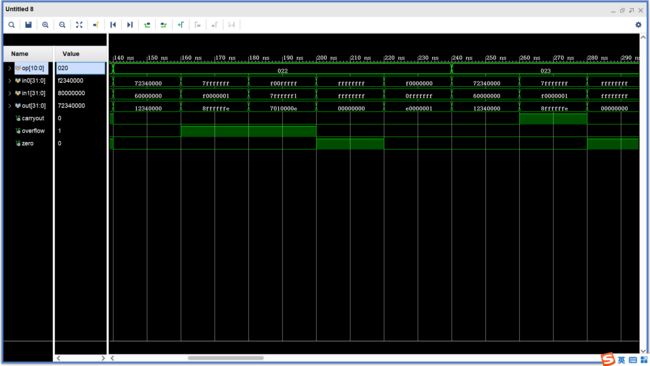

- and、or、xor
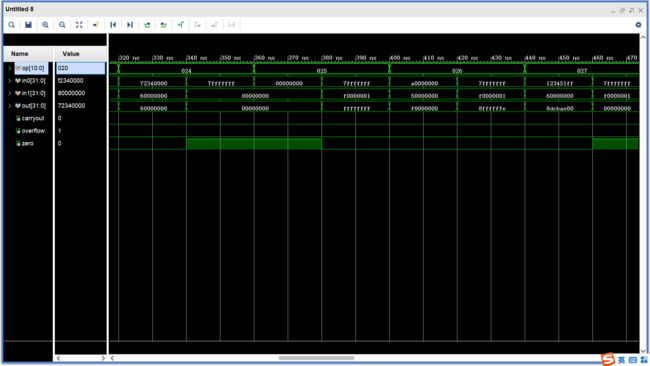
-
nor、slt
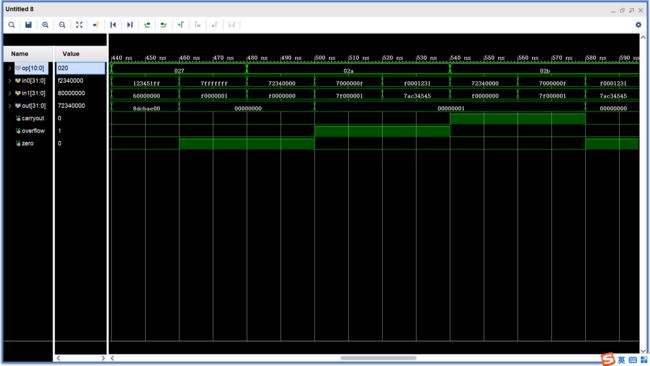
-
sltu、shl、shr、sar
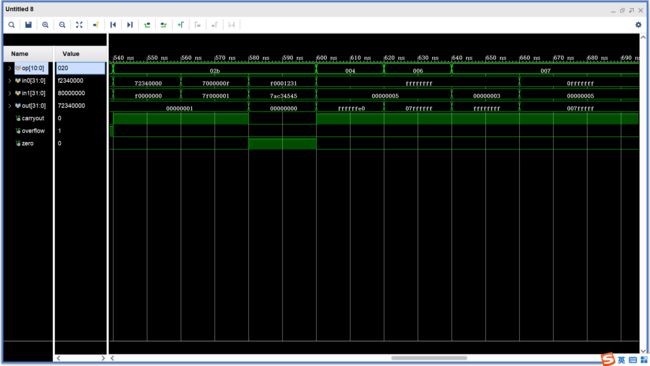
四、模块设计
1. CLA_adder32
(1). 简单实现
module full_adder(
cin,x,y,cout,s
);
input [31:0] x,y;
input cin;
output cout;
output [31:0] s;
assign {cout,s}=cin+x+y;
endmodule
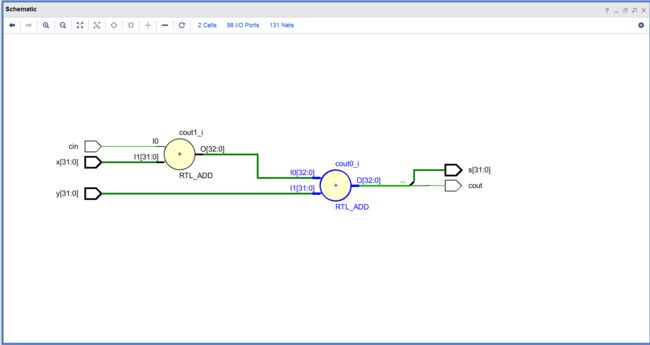
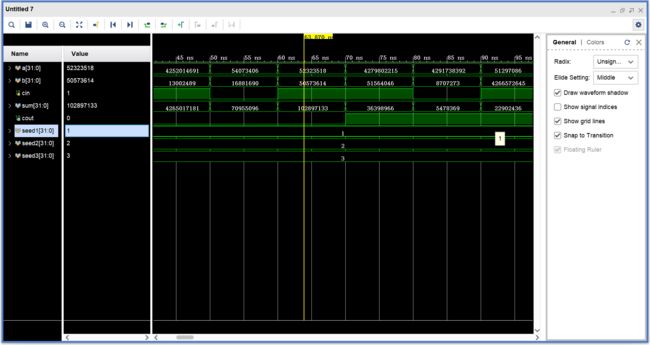
这里在综合后使用了两个32位全加器,实际门延迟比32位全加器高。
(2). 超前进位加法器(Carry-lookahead adder)


加法器的优化——超前进位加法器
由上式可以看出直接实现32位超前进位加法器会非常复杂,所以首先实现8位超前进位加法器,并通过4个8位超前进位加法器组成32位超前进位加法器。
module CLA_adder8(
cin,a,b,
cout,s
);
input [7:0] a,b;
input cin;
output [7:0] s;
output cout;
wire [7:0] G,P;
wire [7:0] C;
assign G[0]=a[0]&b[0];
assign P[0]=a[0]|b[0];
assign C[0]=cin;
assign s[0]=a[0]^b[0]^C[0];
assign G[1]=a[1]&b[1];
assign P[1]=a[1]|b[1];
assign C[1]=G[0]|(P[0]&cin);
assign s[1]=a[1]^b[1]^C[1];
assign G[2]=a[2]&b[2];
assign P[2]=a[2]|b[2];
assign C[2]=G[1] | (P[1]&G[0]) | (P[1]&P[0]&cin);
assign s[2]=a[2]^b[2]^C[2];
assign G[3]=a[3]&b[3];
assign P[3]=a[3]|b[3];
assign C[3]=G[2] | (P[2]&G[1]) | (P[2]&P[1]&G[0]) | (P[2]&P[1]&P[0]&cin);
assign s[3]=a[3]^b[3]^C[3];
assign G[4]=a[4]&b[4];
assign P[4]=a[4]|b[4];
assign C[4]=G[3] | (P[3]&G[2]) | (P[3]&P[2]&G[1]) | (P[3]&P[2]&P[1]&G[0]) | (P[3]&P[2]&P[1]&P[0]&cin);
assign s[4]=a[4]^b[4]^C[4];
assign G[5]=a[5]&b[5];
assign P[5]=a[5]|b[5];
assign C[5]=G[4] | (P[4]&G[3]) | (P[4]&P[3]&G[2]) | (P[4]&P[3]&P[2]&G[1]) | (P[4]&P[3]&P[2]&P[1]&G[0]) |
(P[4]&P[3]&P[2]&P[1]&P[0]&cin);
assign s[5]=a[5]^b[5]^C[5];
assign G[6]=a[6]&b[6];
assign P[6]=a[6]|b[6];
assign C[6]=G[5] | (P[5]&G[4]) | (P[5]&P[4]&G[3]) | (P[5]&P[4]&P[3]&G[2]) | (P[5]&P[4]&P[3]&P[2]&G[1]) |
(P[5]&P[4]&P[3]&P[2]&P[1]&G[0]) | (P[5]&P[4]&P[3]&P[2]&P[1]&P[0]&cin);
assign s[6]=a[6]^b[6]^C[6];
assign G[7]=a[7]&b[7];
assign P[7]=a[7]|b[7];
assign C[7]=G[6] | (P[6]&G[5]) | (P[6]&P[5]&G[4]) | (P[6]&P[5]&P[4]&G[3]) | (P[6]&P[5]&P[4]&P[3]&G[2]) |(P[6]&P[5]&P[4]&P[3]&P[2]&G[1]) | (P[6]&P[5]&P[4]&P[3]&P[2]&P[1]&G[0]) |
(P[6]&P[5]&P[4]&P[3]&P[2]&P[1]&P[0]&cin);
assign s[7]=a[7]^b[7]^C[7];
assign cout=G[7] | (P[7]&G[6]) | (P[7]&P[6]&G[5]) | (P[7]&P[6]&P[5]&G[4]) | (P[7]&P[6]&P[5]&P[4]&G[3]) |(P[7]&P[6]&P[5]&P[4]&P[3]&G[2]) | (P[7]&P[6]&P[5]&P[4]&P[3]&P[2]&G[1]) |
(P[7]&P[6]&P[5]&P[4]&P[3]&P[2]&P[1]&G[0]) |
(P[7]&P[6]&P[5]&P[4]&P[3]&P[2]&P[1]&P[0]&cin);
endmodule
仿真测试:
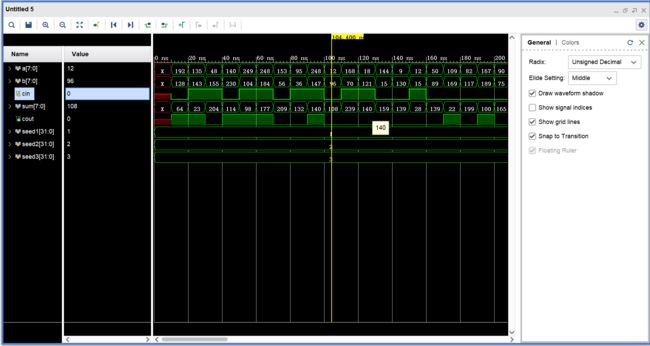
门延迟分析:
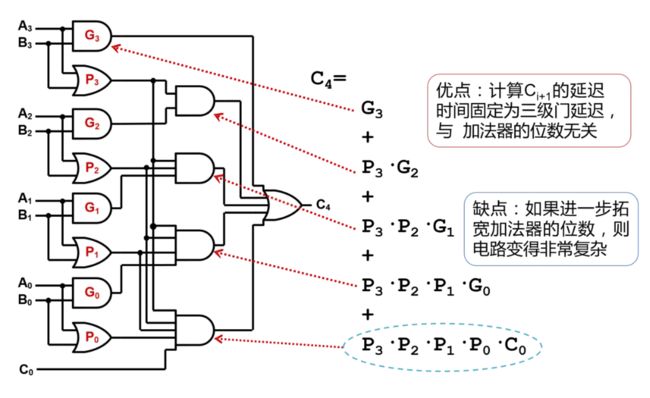
4级8位超前进位加法器构成的32位超前进位加法器门延迟:3*4+1=13
module CLA_adder32(
cin,x,y,
cout,s
);
input [31:0] x,y;
input cin;
output [31:0] s;
output cout;
wire cout1,cout2,cout3;
CLA_adder8 step1(cin,x[7:0],y[7:0],cout1,s[7:0]);
CLA_adder8 step2(cout1,x[15:8],y[15:8],cout2,s[15:8]);
CLA_adder8 step3(cout2,x[23:16],y[23:16],cout3,s[23:16]);
CLA_adder8 step4(cout3,x[31:24],y[31:24],cout,s[31:24]);
endmodule
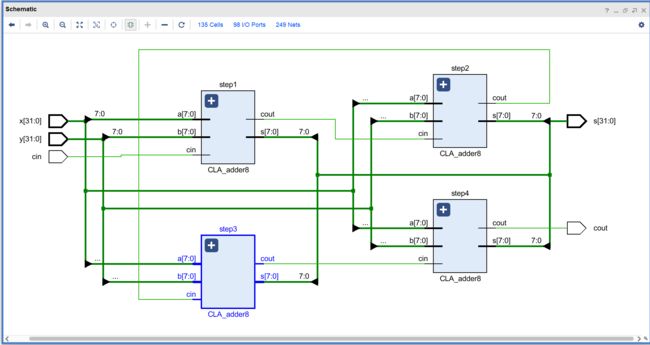
仿真测试: