深度学习笔记
- 深度学习知识点总结
-
- 1 CNN发展史
-
- 1.1 AlexNet
- 1.2 VGGNet
- 1.3 GoogLeNet/Inception-v1
- 1.4 Inception-v2和Inception-v3
- 1.5 Inception-v4
- 1.6 ResNet
- 1.7 ResNeXt
- 2 目标检测之YOLO系列
-
- 2.1 YOLOv1
- 2.2 YOLOv2/YOLO9000
- 2.3 YOLOv3
- 2.4 YOLOv4
- 2.5 YOLOv5
- 2.6 YOLOv6
- 2.7 YOLOv7
- 2.8 各种IOU总结
-
- 2.8.1 IOU
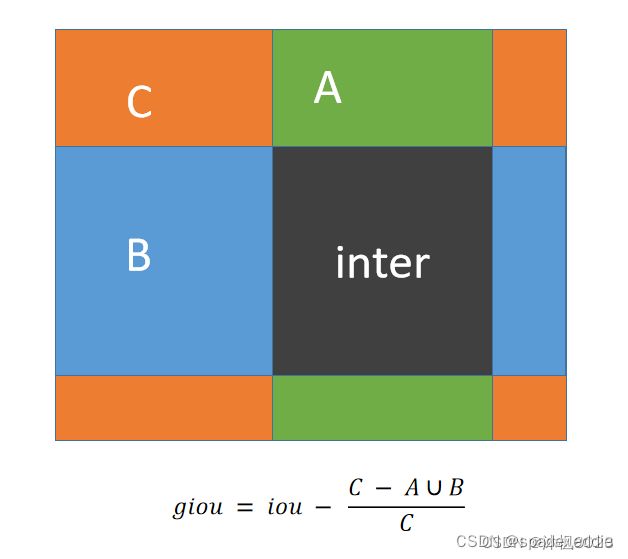
- 2.8.2 GIOU
- 2.8.3 DIOU
- 2.8.4 CIOU
- 2.8.5 EIOU
- 2.8.6 SIOU
- 2.8.7 小结
- 2.9 YOLOX
- 2.10 YOLOP
- 3 目标检测之RCNN系列
-
- 3.1 R-CNN
- 3.2 Fast-RCNN
- 3.3 Faster-RCNN
- 3.4 Mask-RCNN
- 3.5 Cascade R-CNN
深度学习知识点总结
1 CNN发展史
1.1 AlexNet
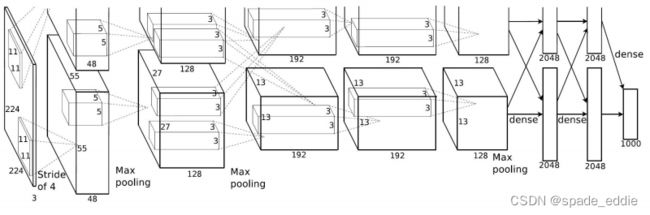
- 采用ReLU作为激活函数替换Sigmoid,缓解了深层网络训练时的梯度消失问题
- 引入**局部响应归一化(LRN)**模块
- 应用了Dropout和数据扩充技术提升训练效果
- 采用分组卷积来突破了方式GPU的显存瓶颈
1.2 VGGNet

- 用多个3×3的小卷积核代替之前的5×5、7×7等大卷积核,以实现在更少的参数量和计算量情况下,获得同样的感受野及更深的网络结构
- 用2×2池化核代替之前的3×3池化核
- 去掉了局部响应归一化(LRN)模块
1.3 GoogLeNet/Inception-v1
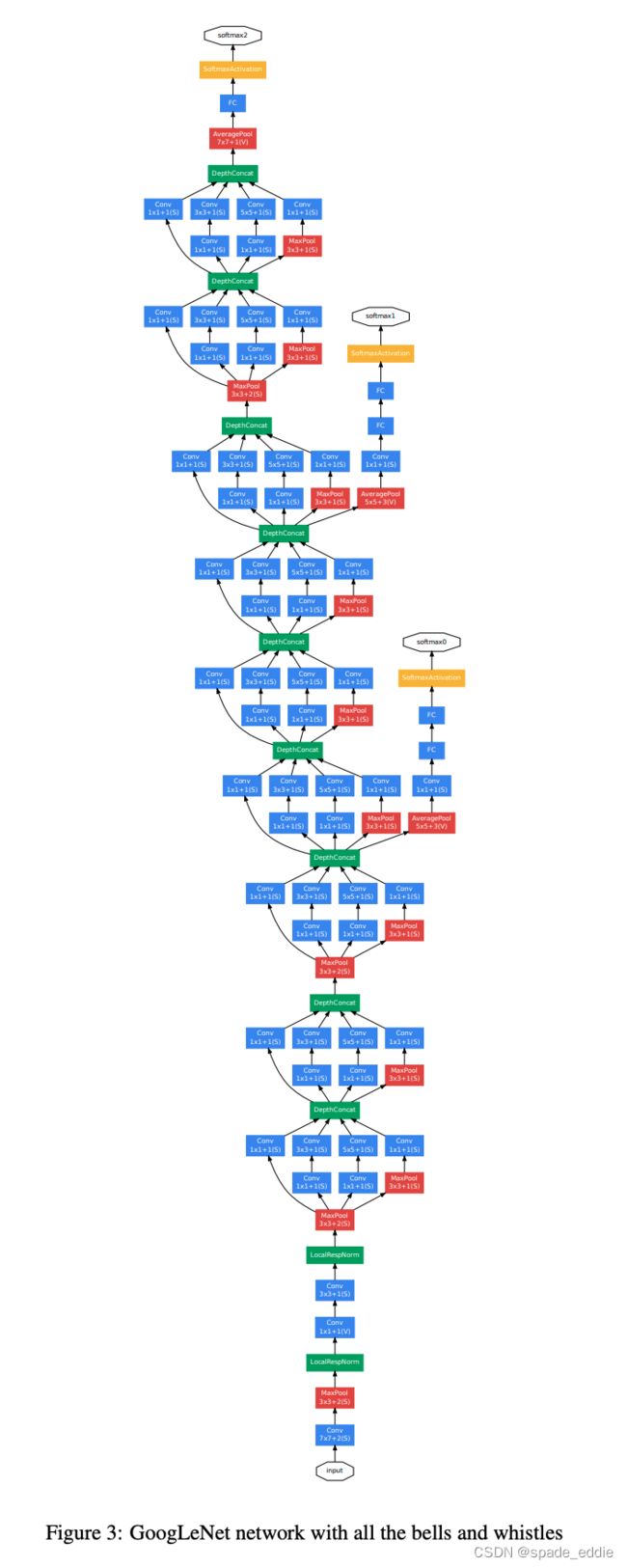
- 提出了瓶颈( bottleneck )结构,即在计算比较大的卷积层之前, 先使用 1×1卷积对其通道进行压缩以减少计算量(在较大卷积层完成计算之后,根据需要有时候会再次使用 1×1卷积将其通道数原)。
- 从网络中间层拉出多条支线,连接辅助分类器,用于计算损失并进行误差反向传播,以缓解梯度消失问题。
- 修改 了之前 VGGNet 等网络在网络末端加入多个全连接层进行分类的做法,转而将第一个全连接层换成全局平均池化层( Global Average Pooling )。
1.4 Inception-v2和Inception-v3
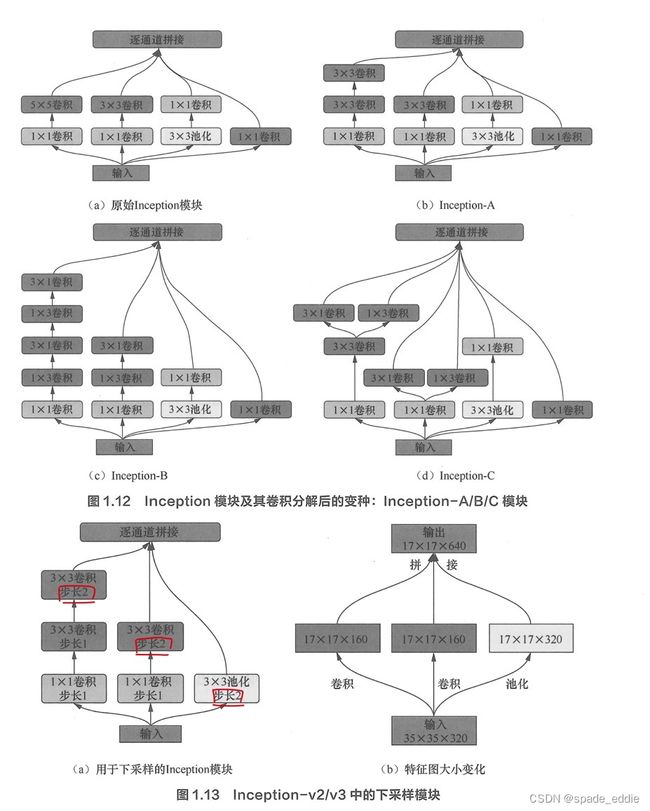
同一篇文章提出,4点关于网络结构的设计准则:
- 避免表达瓶颈( representational bottleneck ),尤真是在网络的前几层。具体来说,将整个网络看 作由输入到输出的信息流, 我们需要尽量让网络从前到后各个层的信息表征能力逐渐降低, 而不能突然剧烈下降或是在中间某些节点出现瓶颈 。
- 特征图通道越多,能表达的解耦信息就越多,从而更容易进行局部处理,最终加速网络的训练过程 。
- 如果要在特征图上做空间域的聚合操作(如3×3卷积),可以在此之前先对特征图的通道进行压缩,这通常不会导致表达能力的损失。
- 在限定总计算量的情况下,网络结构在深度和宽度上需要平衡 。
分解思路:
- 将(2k+1)×(2k+ 1)卷积核分解为 k个3×3卷积核
- 将k×k卷积分解为 1×k卷积与k×1卷积的串联
- 将 1×k卷积和 k×1卷积的组织方式由串联改成并联。
1.5 Inception-v4
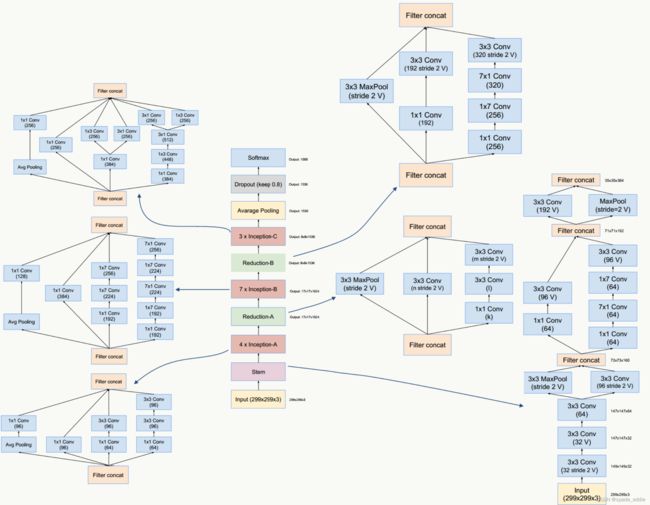
- 修改了v3网络前几层的结构(Stem)
- 采用了Inception-A、Inception-B、Inception-C模块
- 提出应用了Reduction-A、Reduction-B模块
1.6 ResNet
随着网络层数的加深,网络的训练误差和测试误差都会上升。这种现象称为网络的退化(degeneration )。
为解决这个问题, ResNet采用了跳层连接 (shortcut connection ),即在网络中构筑多条“近道”,这再以下两点好处。
- 能缩短误差皮向传播到各层的路径,有效抑制梯度消失的现象,从而使网络在不断加深时性能不会下降。
- 由于有“近道”的存在,若网络在层数加深时性能退化, 则它可以通过控制网络中“近道”和“非近道”的组合比例来退回到之前浅层时的状态,即“近道”具备自我关闭能力。
1.7 ResNeXt
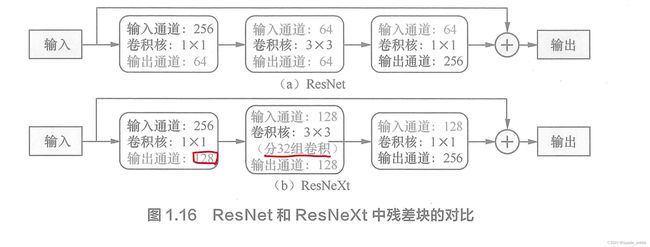
改进resnet的残差块结构。原残差块是一个瓶颈结构,ResNeXt 缩小了瓶颈比 ,并将中间的普通卷积改为分组卷积。该结构可以在不增加参数量的前提下 , 提高准确率,同时还减少 了超参数的数量。
2 目标检测之YOLO系列
2.1 YOLOv1


核心:
- 不像其它目标检测算法(例如R-CNN)采用region_proposal(回归问题) + classifiers(分类问题)的检测方式,而是将目标检测当作一个回归(regression) 问题来处理。
- 使用单个网络,输入一整张图像仅经过一次推理可以得到图像中所有目标的检测框和所属类别。同时可以直接端到端(end-to-end) 地训练和优化网络。
缺点:
- 每个网格只对应两个bounding box,当物体的长宽比不常见(也就是训练数据集覆盖不到时),效果较差。
- 原始图片只划分为7x7的网格,当两个物体靠的很近时,效果比较差。
- 最终每个网格只对应一个类别,容易出现漏检(物体没有被识别到)。
- 对于图片中比较小的物体,效果比较差。这其实是所有目标检测算法的通病。
- 每张图片能够进行分类数量太少,只有20种物体分类。检测的目标数量太少,一张图只能检测 7 * 7 = 49个目标。
2.2 YOLOv2/YOLO9000

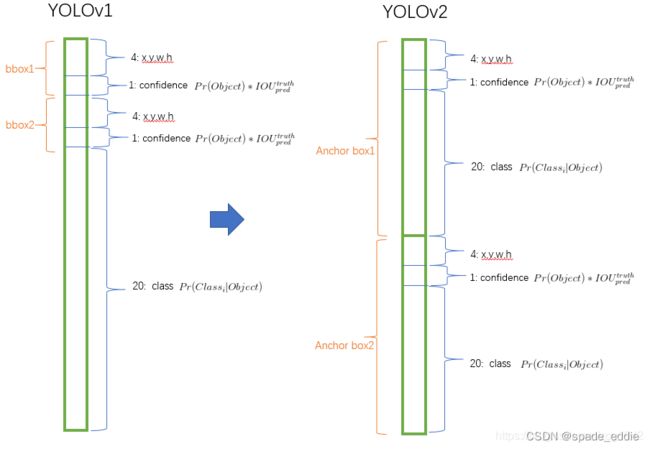

优点:
Batch Normalization(批归一化)
在每个卷积层后加Batch Normalization(BN)层,去掉了dropout层。 Batch Normalization层可以起到一定的正则化效果,能提升模型收敛速度,防止模型过拟合。High Resolution Classifier(分类网络高分辨率预训练)
YOLO v2将输入图片的分辨率提升 448 × 448Convolutional With Anchor Boxes(Anchor Box替换全连接层)
YOLO v1利用全连接层直接对边界框进行预测,导致丢失较多空间信息,定位不准。 YOLO v2去掉了 YOLO v1中的全连接层,使用Anchor Boxes预测边界框,同时为了得到更高分辨率的特征图, YOLO v2还去掉了一个池化层。Dimension Clusters(Anchor Box的宽高由聚类产生)
YOLO v2采用k-means聚类算法对训练集中的边界框做了聚类分析,选用boxes之间的IOU值作为聚类指标。Direct location prediction(绝对位置预测)
对预测框的偏移量进行约束。Fine-Grained Features(细粒度特征)
提出pass through层将高分辨率的特征图与低分辨率的特征图联系在一起,从而实现多尺度检测。Multi-Scale Training(多尺寸训练)
YOLO v2采用多尺度输入的方式训练,在训练过程中每隔10个batches,重新随机选择输入图片的尺寸,由于Darknet-19下采样总步长为32,输入图片的尺寸一般选择 32 32 32的倍数{320,352,…,608}。
2.3 YOLOv3
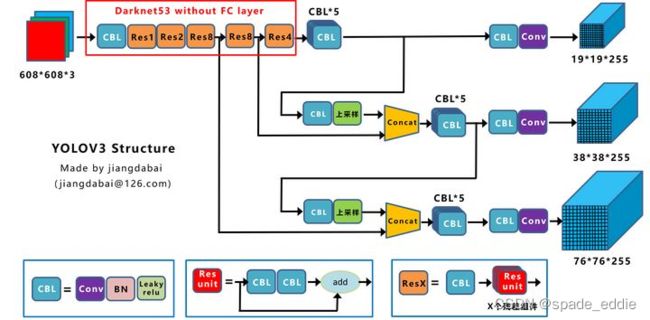
YOLOv3 主要的改进有:
- 调整了网络结构
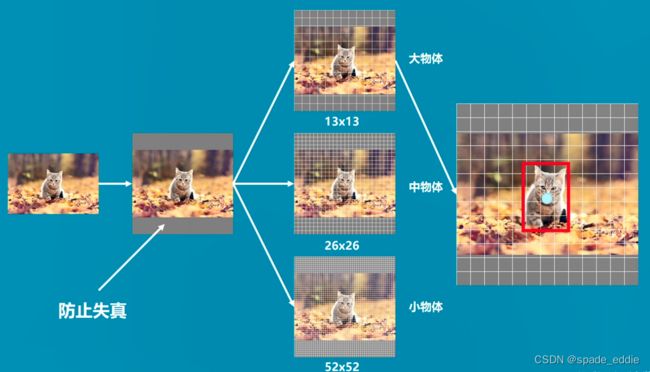
backbone部分由Yolov2时期的Darknet-19进化至Darknet-53,加深了网络层数,引入了Resnet中的跨层加和操作- 利用多尺度特征进行对象检测;
借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。- 对象分类用 Logistic 取代了 softmax。
2.4 YOLOv4
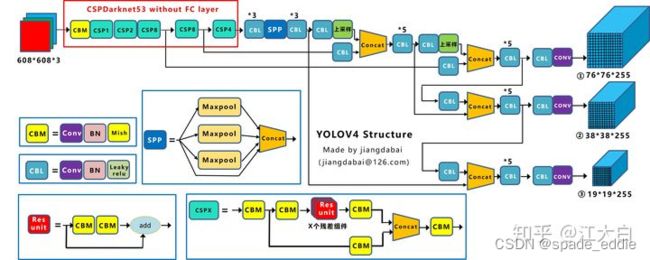
YOLOv4 主要的改进有:
- Mosaic数据增强
- 使用了新的Backbone: CSPDarknet53
- 为了增大感受野,使用了SPP-block(金字塔池化)
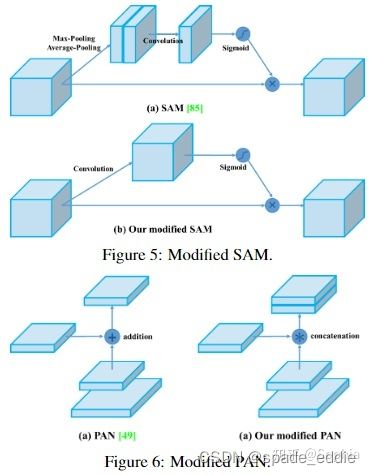
- 改进SAM,改进PAN,和交叉小批量标准化(CmBN),使YOLOv4的设计适合于有效的训练和检测
将SAM从空间注意修改为点注意,并将PAN的快捷连接分别替换为串联
- 使用CIOU损失代替原始xywh位置损失,其他的采用交叉熵损失函数。
- 加权残差连接、跨阶段部分连接、DropBlock正则化、Mish激活等。
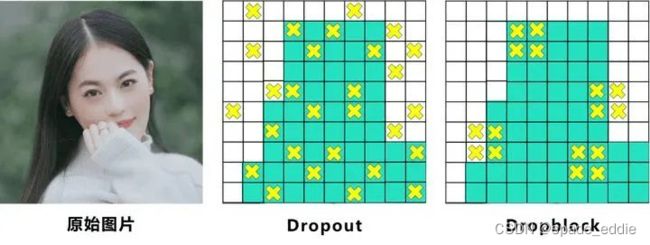
上图中,中间Dropout的方式会随机的删减丢弃一些信息,但Dropblock的研究者认为,卷积层对于这种随机丢弃并不敏感,因为卷积层通常是三层连用:卷积+激活+池化层,池化层本身就是对相邻单元起作用。而且即使随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。因此,在全连接层上效果很好的Dropout在卷积层上效果并不好。所以右图Dropblock的研究者则干脆整个局部区域进行删减丢弃。
2.5 YOLOv5
注: 现在的yolov5已经将focus换成了conv
YOLOv5 主要的改进有:
- Focus结构:以Yolov5s的结构为例,原始6086083的图像输入Focus结构,采用切片操作,先变成30430412的特征图,再经过一次32个卷积核的卷积操作,最终变成30430432的特征图。
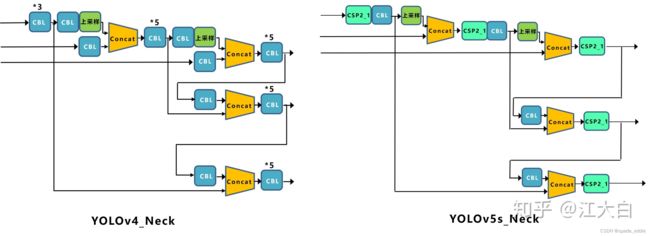
- Yolov5与Yolov4不同点在于,Yolov4中只有主干网络使用了CSP结构。而Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
- Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力

2.6 YOLOv6
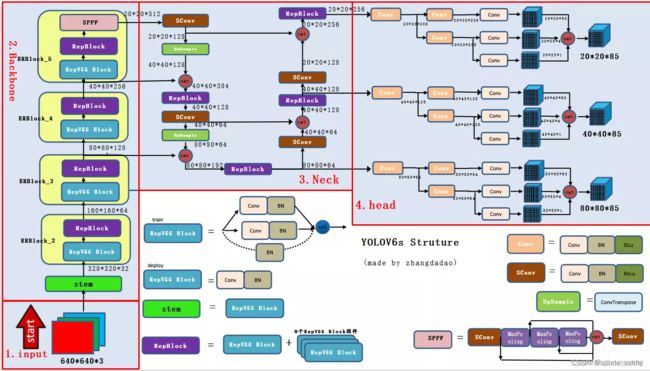
YOLOv6 主要的改进有:
- 设计了更高效的 Backbone 和 Neck :受到硬件感知神经网络设计思想的启发,基于 RepVGG style[4] 设计了可重参数化、更高效的骨干网络 EfficientRep Backbone 和 Rep-PAN Neck。
repVGG核心思想是:通过结构重参数化思想,让训练网络的多路结构转换为推理网络的单路结构,结构中均为3x3的卷积核,同时,计算库(如CuDNN,Intel MKL)和硬件针对3x3卷积有深度的优化,最终可以使网络有着高效的推理速率。- 优化设计了更简洁有效的 Efficient Decoupled Head,在维持精度的同时,进一步降低了一般解耦头带来的额外延时开销。
- 在训练策略上,采用Anchor-free 无锚范式,同时辅以 SimOTA 标签分配策略以及 SIoU 边界框回归损失来进一步提高检测精度。
2.7 YOLOv7
YOLOv7是YOLOv4团队的续作,主要是针对模型结构重参化和动态标签分配问题进行了优化。

YOLOv7 主要的改进有:
- 提出了计划的模型结构重参化。
重参化技术是模型在推理时将多个模块合并成一个模块的方法,其实就是一种集成技术。作者就是用梯度传播路径的方法来分析,因为RepConv结合了3×3卷积,1×1卷积,和在一个卷积层中的identity连接,可是这个identity破坏力ResNet的残差连接以及DenseNet的跨层连接,为不同的特征图提供了更多的梯度多样性。因此,作者认为,在同时使用重参化卷积和残差连接或者跨层连接时,不应该存在identity连接,而且作者还分析重参数化的卷积应该如何与不同的网络结构相结合以及设计了不同的重参数化的卷积。
扩展高效层聚合网络(Extended efficient layer aggregation networks):在ELAN的基础上提出了E-ELAN,主要的结构如图(d)。
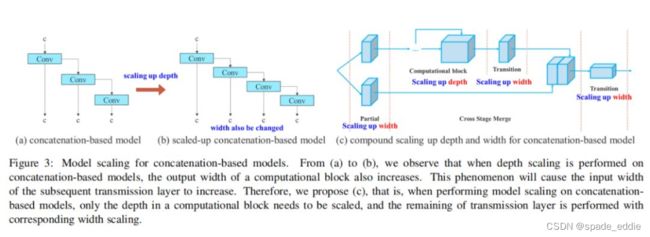
- 借鉴了YOLOv5、Scale YOLOv4、YOLOX,“拓展”和“复合缩放”方法,以便高效的利用参数和计算量。
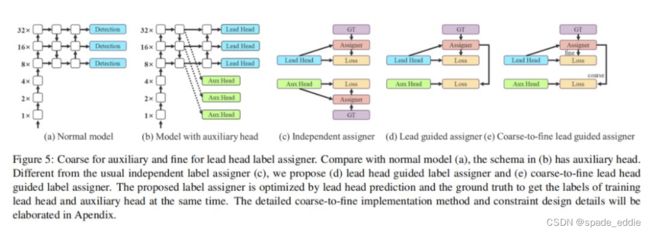
- 提出了一种新的标签分配方法:coarse-to-fine,即由粗到细引导标签分配的策略。
在网络的训练中,标签分配通常是指GT,这个是硬标签,但近年来,需要研究者会利用网络的推理结果来结合GT,去生成一些软标签,如IOU。在YOLOv7中,有辅助头也有引导头,在训练时,它们二者都需要得到监督。因此,需要考虑如何为辅助头和引导头进行标签分配。因此在这里,作者提出了一种新的标签分配方法,是以引导头为主,通过引导头的推理来指引辅助头和自身的学习。
首先使用引导头的推理结果作为指导,生成从粗到细的层次标签,分别用于辅助头和引导头的学习。

2.8 各种IOU总结
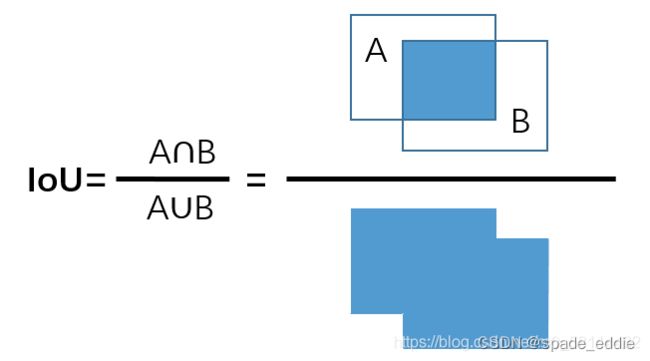
2.8.1 IOU

2.8.2 GIOU
在IOU的基础上引入了能够包围两个box的最小框C,不仅关注两个box的重叠区域,还关注两个框的非重叠区域

2.8.3 DIOU
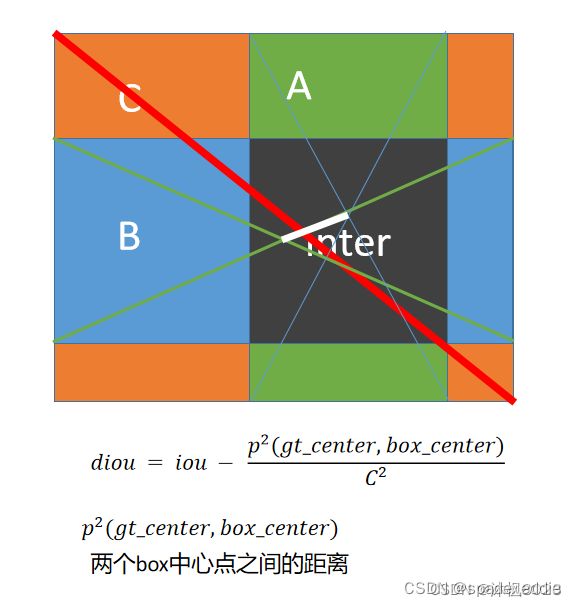

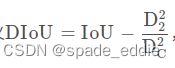
D2为预测框和目标框中心点距离, DC为最小外接矩形 C 的对角线距离。
2.8.4 CIOU

CIoU只是在DIoU上增加了一项 αv, α是个平衡参数,不参与梯度计算,真正重要的就是 v, 即矩形对角线的倾斜角度~
2.8.5 EIOU
CIOU Loss虽然考虑了边界框回归的重叠面积、中心点距离、纵横比。但是通过其公式中的v反映的纵横比的差异,而不是宽高分别与其置信度的真实差异,所以有时会阻碍模型有效的优化相似性。
在CIOU的基础上将纵横比拆开,即将 αv 改为后面两项,提出了EIOU Loss,并且加入Focal聚焦优质的锚框

EIOU 作用:
- 将纵横比的损失项拆分成预测的宽高分别与最小外接框宽高的差值,加速了收敛提高了回归精度
- 引入了Focal Loss优化了边界框回归任务中的样本不平衡问题,即减少与目标框重叠较少的大量锚框对BBox
- 回归的优化贡献,使回归过程专注于高质量锚框
2.8.6 SIOU
与用于计算图像中真实框和模型预测框不匹配的惩罚的传统指标并行——即距离、形状和 IoU,本文作者建议还要考虑不匹配的方向。
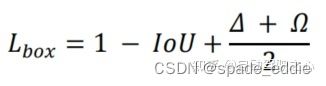
SIoU损失函数由4个Cost函数组成:
-
Angle cost

-
Distance cost
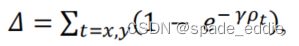

-
Shape cost


-
IoU cost
2.8.7 小结
| IOU | GIOU | DIOU | CIOU | EIOU | SIOU | |
|---|---|---|---|---|---|---|
| 优点 | IOU算法是目标检测中最常用的指标,具有尺度不变性,满足非负性、同一性、对称性及三角不等性等特点 | GIOU在基于IOU特性的基础上引入最小外接框解决检测框和真实框没有重叠时loss为0的问题 | DIOU在基于IOU特性的基础上考虑到GIOU的缺点,直接回归两个框中心点的欧式距离,加速收敛 | CIOU就是在DIOU的基础上增加了检测框尺度的loss,增加了长和宽的loss,这样预测框就会更加符合真实框 | EIOU在CIOU的基础上分别计算宽高的差异值 ,取代了纵横比,同时引入Focal loss解决难易样本不平衡的问题 | SIOU 引入角度的损失,最大限度地减少与距离相关的“奇妙”中的变量数量 |
| 缺点 | 1. 如果两个框不相交,不能反映两个框的距离远近 2. 无法精确的反映两个框的重合度大小 |
1. 当检测框和真实框出现包含现象时,GIOU退化成IOU 2. 两个框相交时,在水平和垂直方向收敛慢无法精确的反映两个框的重合度大小 |
回归过程中未考虑Bouding box的纵横比,精确度上尚有进一步提升的空间 | 1. 纵横比描述的是相对值,存在一定的模糊 2. 未考虑难易样本的平衡问题 |
待定 | 待定 |
2.9 YOLOX
Yolox主要的改进有:
- 采用了Mosaic、Mixup两种数据增强方法。注:在训练的最后15个epoch,这两个数据增强会被关闭掉。作者在研究中发现,ImageNet预训练将毫无意义,因此,所有的模型,均是从头开始训练的。
- Decoupled Head。 目前Yolo系列使用的检测头,表达能力可能有所欠缺,没有Decoupled Head的表达能力更好。使用解耦头后精度提升,且收敛加快。注:将检测头解耦,会增加运算的复杂度。.
- Anchor-free
-标签分配。初步筛选、SimOTA。
Yolov5s和Yolox-s主要区别在于:
(1)输入端:在Mosa数据增强的基础上,增加了Mixup数据增强效果;
(2)Backbone:激活函数采用SiLU函数;
(3)Neck:激活函数采用SiLU函数;
(4)输出端:检测头改为Decoupled Head、采用anchor free、multi positives、SimOTA的方式。
2.10 YOLOP

YOLOP包含三个用于三个任务的解码器:
Detect Head 类似YOLOv4,我们采用了基于Anchor的多尺度检测机制。首先,我们采用PAN进行更优特征融合,然后采用融合后特征进行检测:多尺度特征的每个grid被赋予三个先验anchor(包含不同纵横比),检测头将预测位置偏移、高宽、类别概率以及预测置信度。
Driable Area Segment Head & Lane Line Segment Head 驾驶区域分割头与车道线分割头采用了相同结构。我们将FPN的输出特征(分辨率为[W/8,H/8,256])送入到分割分支。我们设计的分割分支非常简单,通过三次上采样处理输出特征尺寸为[W,H,2],代表每个像素是驾驶区域/车道线还是背景的概率。由于Neck中已包含SPP模块,我们并未像PSPNet添加额外的SPP模块。此外,我们采用了最近邻上采样层以降低计算量。因此,分割解码器不仅具有高精度输出,同时推理速度非常快。
 两种训练范式。
两种训练范式。
- 端到端训练,然后三个任务可以进行联合学习。
- 交替优化算法:即每一步聚焦于一个或多个相关任务,而忽视不相关任务。