银行营销数据的Python数据分析--连接SQLserver
一共有4万多条数据,来自著名的machine learning网站UCI,数据集名称是bank marketing,应该很好搜到
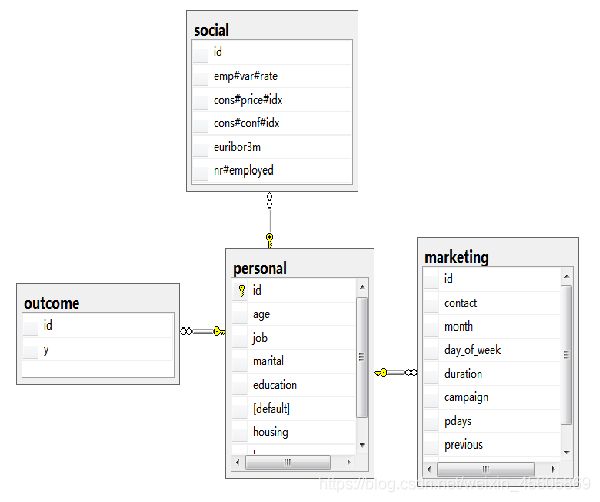
数据是这样的4个文件,分别是个人信息、营销信息、社会经济情况和最终结果,我把导入到SQLserver中
每个文件都有一个id变量,是每个银行用户独一无二的标识,我把它设置为了主键
接下来用Python连接SQLserver读取数据,代码如下
pip install pymssql
import pymssql
connect = pymssql.connect('(local)', 'sa', '密码', '要访问的数据库名称')
cursor = connect.cursor()
cursor.execute("select*from bank_additional")
我先在数据库里合成了这四个文件为一个bank_additional,其实也可以直接Python写SQL语句合成,用到join on
data = cursor.fetchall()
这样数据就成功从SQLserver读取到了Python,但是这是数组文件,为便于后续分析我把转化为了dataframe
import pandas as pd
data=pd.DataFrame(data,columns=[.....])
接下来就可以基于data做数据分析了

import pandas as pd
import numpy as np
import random
import warnings
warnings.filterwarnings("ignore")
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
首先画出出各个分类型变量的分布情况:
categorcial_variables = ['job', 'marital', 'education', 'default', 'loan', 'contact', 'month', 'day_of_week', 'poutcome','y']
for element in categorcial_variables:
plt.figure(figsize=(10,4))
sns.barplot(data[element].value_counts().values, data[element].value_counts().index)
plt.title(element)
然后是各个分类型变量与y的关系
for ele in categorcial_variables:
pd.crosstab(data[ele],data['y']).plot.bar()
这里其实变量Default,education, job, housing,loan等是存在缺失值unknown的,但是考虑到这是因为受访者不愿意透露自己的真实情况,对结果也是有一定影响的,因此处理方式是将unknown作为一个单独的取值
好了,下面是对数值型数据的简单描述
numerical_variables = ['age','campaign', 'pdays', 'previous', 'emp.var.rate', 'cons.price.idx','cons.conf.idx','euribor3m', 'nr.employed']
data[numerical_variables].describe()
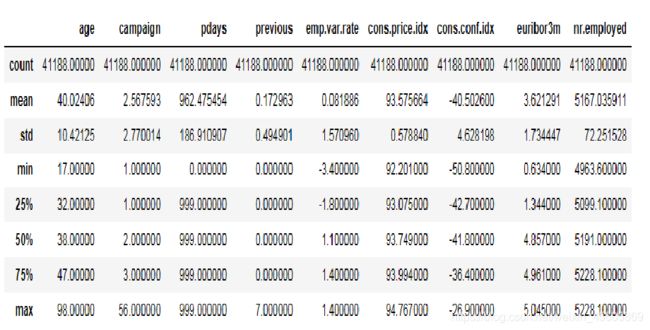
同样数值型变量的‘pdays’也存在缺失值,用999表示,注意到
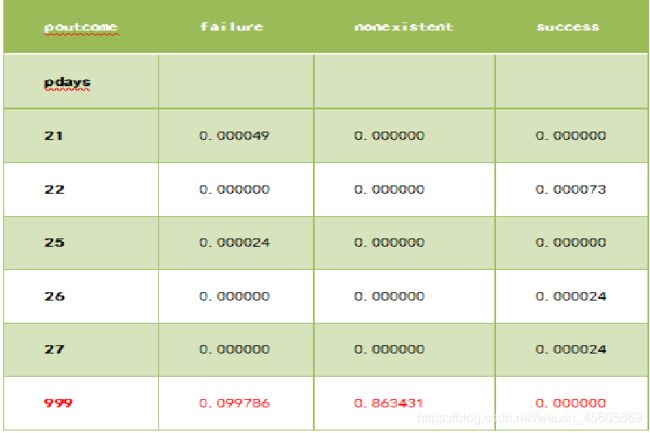
几乎所有pdays的缺失值,另一变量poutcome的取值都是noexist,zhe很好理解,由于之前没有做过营销,因此数据不存在,过去的营销结果自然是noexist,所以变量pdays的信息可以被poucome替代,所以简单删除这一变量即可。
下面对所有的分类型变量进行0-1编码,使他们成为新的0-1变量,做出新的变量之间的相关系数图