自然语言处理(NLP)与词嵌入
很久以前看吴恩达老师的视频和西瓜书时用jupyter写的,今天想起来就把它转到这里,
one-hot 表达的不足:每个单词都是独立的、正交的,不能把同类单词的关系表示出来。
特征表征(featurized representation):解决上述 one-hot 向量表达的缺点,做法是列出一系列的特征,对应单词符合该特征就给予(正负)高概率,不符合该特征就给予(正负)低概率。
这样一个单词就由很多特征对应了很多概率,概率表示为向量。该过程就是特征化表示方法。根据每个单词对应的向量,就可以发现发现同类词。
每个单词都由高维特征向量表征,为了可视化不同单词之间的相似性,可以使用降维操作,例如t-SNE算法,将300D降到2D平面上。平面中,同类的单词会集聚在一起,不同的单词会相隔较远。
优点是可以减少训练样本的数目,前提是对海量单词建立特征向量表述(word embedding)。这样,即使训练样本不够多,测试时遇到陌生单词,根据之前海量词汇及其特征向量便可以知道这个单词的属性。
嵌入矩阵:横轴对应的是字典中的单词,竖轴对应的是每个单词的词嵌入向量。每个单词的词嵌入向量可以用嵌入矩阵E和该单词对应的one-hot向量进行矩阵相乘求解,即E·oj = ej
词嵌入的特性:
1.类比推理:两个词的向量相近,则词意相近,向量相反,则词意相反。
e m a n − e w o m a n ≈ e k i n g − e q u e e n e_{man} - e_{woman} ≈ e_{king} - e_{queen} eman−ewoman≈eking−equeen
2.用词向量来类比: a r g m a x s i m ( e ? , e k i n g − e m a n + e w o m a n ) argmax sim(e_?,e_{king} - e_{man} + e_{woman}) argmaxsim(e?,eking−eman+ewoman)
3.余弦相似:sim方法就是采用余弦相似方法。
自然语言预测:神经网络能够根据输入的语句来预测后面的的单词。
1.要得到每个单词对应的词嵌入向量,就需要把句子中的每个单词的one-hot向量 O w O_w Ow和参数嵌入矩阵E进行矩阵乘积得到 e c e_c ec。(假设某个词汇库包含了10000个单词,每个单词包含的特征维度为300,则E为300 x 10000, O w O_w Ow=10000 x 1)
得到每个单词的词嵌入向量后,把这些向量送入神经网络,接着送入softmax层输出预测。
2.设定一个固定来历的窗口(fixed historical window),比如给出空格前的四个单词进行预测,单词的数量便是算法的超参数,可以调整为或长或短的序列,或者决定总是取空格前的几个单词。只用表示出这四个单词的词嵌入向量,然后送入网络进行训练。
超参数的选择:(输入叫做context,输出叫做target)
1.target前n个单词或后n个单词,n可调
2.target前1个单词
3.target附近某1个单词(Skip-Gram)
from IPython.display import Image
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "12.png", width=600, height=100)

word2vec的两种模型:
1.跳字模型(skip-gram model)
2.连续词袋模型(continuous bag of words,简称CBOW)
这里主要针对skip-gram模型进行讲述(因为它好)
Skip-Gram模型:用一个词来预测文本序列中它周围的词。步骤:
1.首先随机选择一句话中的一个单词作为context,然后使用一个宽度为5(自定义)的滑动窗,在context附近选择一个单词作为target,重复该步骤,最终得到了多个context—target对作为监督式学习样本。
2.把one-hot向量Ow和嵌入矩阵E矩阵相乘得到词嵌入向量 e c e_c ec,然后送入softmax层输出预测ŷ。把一个one-hot向量输入隐藏层得到一个词嵌入向量,再送入softmax层输出预测的概率。
CBOW:与skip-gram相反,用一个中心词周围的邻近词来预测该中心词。给定文本序列”i”, “want”, “a”, “galss”, “of”和”juice”,CBOW模型所关心的是,邻近词“i”, “want”, “a”, “galss”,“of”和”juice”一起生成中心词”orange”的概率。
#Skip-Gram模型后续训练
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "14.png", width=600, height=100)

Skip-Gram模型的优化:
1.采用树形分类器(相当于二分类):在每个数节点上对目标单词进行区间判断,最终定位到目标单词。
2.树形分类器再改进为非对称式:把比较常用的单词放在树的顶层,而把不常用的单词放在树的底层。
3.context采样优化:如果使用均匀采样,那么一些常用的介词、冠词,例如the, of, a, and, to等出现的概率更大一些。用其他算法不均匀采样。
Negative sampling(负采样):skip-gram模型存在一个缺点就是softmax计算起来很慢。但是负采样在这上面就比较高效了。
跟skip-gram模型一样,从训练集中选取一系列的单词对(word pairs)喂入模型。不同的是,会给选取的 target words 添加labels,且会把真正的 target word 放在首行(首位),称为正样本,其label为1。其余的候选的 target words 和选取的中心词构成负样本, label为0。这里会引入一个参数k,表示负采样k次,在小数据集上采用5-20范围内的数;在大数据集上则采用2-5范围内的数字。即数据集越小,k选值越大。
负样本的采集:对词频$ f(w_i)$(单词在单词表中出现的概率) 计算其 3/4 次方,再除以整体的值:
P ( w i ) = f ( w i ) 3 4 ∑ j 10000 f ( w j ) 3 4 P(w_i)=f(w_i)^{\frac 34}∑^{10000}_jf(w_j)^{\frac 34} P(wi)=f(wi)43∑j10000f(wj)43
负采样模型:在数据集中,我们把选定的context记为c,target words记为t,label记为y。模型所要做的就是根据提供的 c 和 t ,来预测y 是否等于 1。
数学模型为:
P ( y = 1 ∣ c , t ) = σ ( θ t T ⋅ e c ) P(y=1|c,t)=σ(θ^T_t⋅e_c) P(y=1∣c,t)=σ(θtT⋅ec)
具体操作:输入一个词的one-hot向量,输入隐藏层求出对应的词嵌入向量,最后送入输出层运用sigmoid激活函数进行logistic回归分类。
负采样模型所做的就是,把softmax计算10000维的问题,转换为 k+1 个二元分类问题,且每一个的计算都十分简单。
GloVe 词向量
X i j X_{ij} Xij: 表示i出现在j之前的次数,即i和j同时出现的次数。其中,i表示context,j表示target。若限定先后,则 X i j ≠ X j i X_{ij}≠X_{ji} Xij=Xji,我们默认存在对称关系 X i j = X j i X_{ij}=X_{ji} Xij=Xji。
GloVe模型的loss function为:
L = ∑ i = 1 10000 ∑ j = 1 10000 ( θ i T e j − l o g X i j ) 2 L=∑_{i=1}^{10000}∑_{j=1}^{10000}(θ^T_ie_j−logX_{ij})^2 L=∑i=110000∑j=110000(θiTej−logXij)2
若两个词的embedding vector越相近,同时出现的次数越多,则对应的loss越小。为了防止出现“log 0”,即两个单词不会同时出现,对loss function引入一个权重因子 f ( X i j ) f(X_{ij}) f(Xij):
L = ∑ i = 1 10000 ∑ j = 1 10000 f ( X i j ) ( θ i T e j − l o g X i j ) 2 L=∑_{i=1}^{10000}∑_{j=1}^{10000}f(X_{ij})(θ^T_ie_j−logX_{ij})^2 L=∑i=110000∑j=110000f(Xij)(θiTej−logXij)2
当 X i j = 0 X_{ij}=0 Xij=0时,权重因子 f ( X i j ) = 0 f(X_{ij})=0 f(Xij)=0。这种做法直接忽略了无任何相关性的context和target,只考虑 X i j > 0 X_{ij}>0 Xij>0的情况。
出现频率较大的单词相应的权重因子f(Xij)较大,出现频率较小的单词相应的权重因子f(Xij)较小一些。最后,加入偏移量:
L = ∑ i = 1 10000 ∑ j = 1 10000 f ( X i j ) ( θ i T e j + b i + b ′ j − l o g X i j ) 2 L=∑_{i=1}^{10000}∑_{j=1}^{10000}f(X_{ij})(θ^T_ie_j+b_i+b′_j−logX_{ij})^2 L=∑i=110000∑j=110000f(Xij)(θiTej+bi+b′j−logXij)2
参数θi和ej是对称的。使用优化算法得到所有参数之后,最终的 e w e_w ew可表示为:
e w = e w + θ w 2 e_w=\frac {e_w+θ_w}2 ew=2ew+θw
Sentiment Classification(情感分类):根据一句话来判断其喜爱程度。情感分类问题的一个主要挑战是缺少足够多的训练样本。而Word embedding恰恰可以帮助解决训练样本不足的问题。
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "15.png", width=600, height=100)

该模型的缺点是使用平均方法,没有考虑句子中单词出现的次序,忽略其位置信息,有时候会曲解句意。
RNN的many-to-one模型解决了这个问题,因为它引入了时间步长的激活函数,考虑了单词出现的次序。
使用word embedding,能够有效提高模型的泛化能力,即使训练样本不多,也能保证模型有不错的性能。
消除偏见:Word embeddings中存在一些性别、宗教、种族等偏见或者歧视。我们要修改学习算法使其尽可能减小或者理想化消除这些偏见
建立如下表格,确定偏见bias的方向。方法是对所有性别对立的单词求差值,再平均。
b i a s d i r e c t i o n = 1 N ( ( e h e − e s h e ) + ( e m a l e − e f e m a l e ) + ⋯ ) bias direction=\frac 1N((e_{he}−e_{she})+(e_{male}−e_{female})+⋯) biasdirection=N1((ehe−eshe)+(emale−efemale)+⋯)
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "16.png", width=500, height=100)

单词中立化(Neutralize):将需要消除性别偏见的单词投影到non-bias direction上去,消除bias维度。
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "17.png", width=500, height=100)
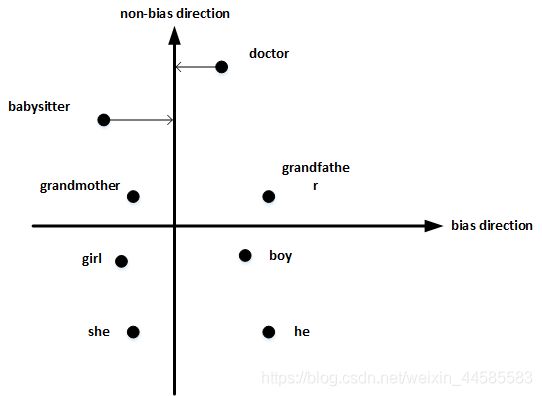
均衡对(Equalize pairs):让性别对立单词与上面的中立词距离相等,具有同样的相似度。例如让grandmother和grandfather与babysitter的距离同一化。
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "18.png", width=500, height=100)

掌握哪些单词需要中立化非常重要。一般来说,大部分英文单词,例如职业、身份等都需要中立化,消除embedding vector中性别这一维度的影响。