自监督论文阅读笔记 Self-Supervised Pretraining for RGB-D Salient Object Detection
现有的基于 CNN 的 RGB-D 显著对象检测 (SOD) 网络都需要在 ImageNet 上进行预训练,以学习有助于提供良好初始化的层次特征。然而,大规模数据集的收集和注释既耗时又昂贵。在本文中,利用自监督表示学习(SSL)来设计两个前置任务:跨模态自动编码器 和 深度轮廓估计。本文的前置任务只需要少量且未标记的 RGB-D 数据集来执行预训练,这使得网络能够捕获丰富的语义上下文并减少两种模态之间的差距,从而为下游任务提供有效的初始化。
此外,针对RGB-D SOD中跨模态融合的固有问题,本文提出了一种 一致性-差异聚合(Consistency-Difference Aggregation,CDA)模块,将单个特征融合 拆分为 多路径融合,以实现对一致和差异信息的充分感知。 CDA模块具有通用性,适用于 跨模态 和 跨级别的特征融合。在六个基准数据集上进行的大量实验表明,本文的自监督预训练模型优于在 ImageNet 上预训练的大多数最先进的方法。
RGB-D 显著目标检测 (SOD) 任务 旨在 利用 包含 稳定几何结构 和 额外对比度线索 的深度图,为处理复杂环境(例如与背景具有相似外观的低对比度显著对象)提供重要的补充信息。受益于 Microsoft Kinect、Intel RealSense 和一些现代智能手机(例如,华为 Mate30、iPhone X 和三星 Galaxy S20),可以方便地获取深度信息。
随着深度卷积神经网络 (CNN) 的发展,许多基于 CNNs 的 SOD 方法(Zhang et al. 2019, 2020b; Li et al. 2021b; Liu, Zhang, and Han 2020; Fan et al. 2020b; Li et al. . 2020; Zhang et al. 2020a, 2021b; Sun et al. 2021; Zhao, Zhang, and Lu 2021; Zhao et al. 2021; Li et al. 2021a; Zhao et al. 2020a; Pang et al. 2020b; Ji et al. . 2021b; Li et al. 2022; Zhang et al. 2021a; Pang et al. 2020a) 可以达到令人满意的性能。它们都需要在 ImageNet (Deng et al. 2009) 上进行预训练,以学习下游任务的丰富和高性能的视觉表示。然而,ImageNet 包含大约 130 万张标记图像,涵盖 1,000 个类别,而每个图像都由具有一个类别标签的人工标记。如此昂贵的人工成本是无法估量的。
最近,Doersch 等人。 (Doersch、Gupta 和 Efros 2015)、Wang 和 Gupta(Wang 和 Gupta 2015)和 Agrawal 等人。 (Agrawal、Carreira 和 Malik 2015)探索了一种新的无监督学习范式,称为自监督学习 (SSL)。主要思想是利用 视觉数据 之外或之内 免费提供的不同标签,并将它们用作内在奖励信号来学习通用特征。在学习过程中,上下文 已被证明是学习表示的自动监督信号的强大来源(Ando 和 Zhang 2005;Okanohara 和 Tsujii 2007;Collobert 和 Weston 2008;Mikolov 等人 2013)。 SSL 需要设计一个“pretext” 任务来学习丰富的上下文,然后将预训练模型用于其他一些“下游”任务,例如分类、检测和语义分割。此外,对于 RGB-D SOD 任务,如何充分融合两种模态的特征仍然是一个备受关注的悬而未决的问题,就像 跨层特征融合 一样。如何更好地设计一个适用于具有多种互补关系的特征对的通用模块是目前被忽视的问题。
双流 RGB-D SOD 网络(Piao et al. 2019; Liu, Zhang, and Han 2020; Fu et al. 2020; Pang et al. 2020a; Jin et al. 2021; Ji et al. 2020)通常加载 ImageNet - 预训练的权重。他们的 RGB 和深度流 编码器具有相同的预训练任务,即图像分类。他们的解码器也有相同的显着性预测任务,这种编码器和解码器的任务同质性可以大大减少两个流之间的模态间差距。
我们知道,图像分类网络通常会激活特征图中的相应语义区域(例如,类激活图),而深度图可能会突出显著区域。受此启发,本文首先设计了一个深度估计的前置任务,该任务可以促进RGB编码器通过 比较像素级的相对空间位置 来捕获目标的定位、边界和形状信息。此外,深度图在RGB-D SOD中起到 信息过滤 和 注意力 的作用,这与图像分类中的类激活图相同。
其次,为了加强跨模态信息交互,本文设计了另一个从深度图重构 RGB 通道的前置任务。此任务要求网络学习为不同位置分配颜色的方法。由于先验信息有限,这是一项非常困难的任务,它可以激发表示学习的潜力,并驱动 深度编码器 捕捉不同对象 和 前景/背景之间形状和语义关系的线索。上述两个前置任务实际上形成了一个跨模态的自动编码器,它只需要成对的 RGB 和 Depth 图像,没有任何相互标签。
在解码器中,本文设计了一个深度轮廓估计的前置任务。原因有两个:
(1)相似的预测任务有助于缩小模态之间的差距。轮廓预测是一个类似于显着性检测的过程。
(2)深度轮廓比 RGB 轮廓更清晰,并且倾向于更好地描绘关于显著对象/对象的边缘信息,因为基于人类认知,显着对象 通常 与背景 具有更明显的深度差异。此外,轮廓也是显着对象的一个重要属性。一旦前置可以很好地预测显着对象的轮廓,它就可以简化下游的 RGB-D SOD 任务来预测轮廓内外的 前/背景属性。在这些前置网络被训练之后,RGB-D SOD 网络可以获得良好的初始化。
关于网络架构,本文提出了一个通用模块,称为一致性-差异聚合(CDA),以实现 跨模式 cross-modal 和 跨级别 cross-leve的融合。具体来说,对于具有互补关系的两类特征,本文计算它们的联合一致(JC)特征 和 联合微分(JD)特征。 JC更加关注它们的一致性,抑制非显着信息的干扰,而JD描绘了它们在显着区域的差异,鼓励 跨模态 或 跨层次 对齐。通过显著性引导的一致性差异聚合,模态或级别之间的差距大大缩小。
本文的主要贡献可以总结如下:
• 本文提出了一个与 RGB-D SOD 任务密切相关的自监督网络,它由一个 跨模态自动编码器 和一个 深度轮廓估计解码器 组成。它是第一个使用自监督表示学习进行 RGB-D SOD 的方法。
• 本文设计了一个简单而有效的 一致性-差异聚合结构,适用于 跨级别 和 跨模态的特征集成。
• 本文使用 6, 392 对 RGB-Depth 图像(没有手动注释)来预训练模型,而不是使用 ImageNet(1, 280, 000 和图像级标签)。本文的模型在六个 RGB-D SOD 数据集上的表现仍然比大多数竞争对手好得多。
Related Work:
RGB-D 显著目标检测:
一般来说,深度图 可以通过三种方式利用:早期融合(Peng et al. 2014; Song et al. 2017; Zhao et al. 2020b),中间融合(Feng et al. 2016)和 晚期融合(Fan、Liu 和 Sun 2014)。
根据编码流的数量,RGB-D SOD 方法可以 分为 双流(Zhao et al. 2019; Chen and Fu 2020; Fan et al. 2020b; Liu, Zhang, and Han 2020; Zhang et al. 2020a , 2021b; Sun et al. 2021; Ji et al. 2021a) 和 单流 (Zhao et al. 2020b)。
双流网络主要侧重于 充分结合跨模式互补性。刘等人 (Liu, Zhang, and Han 2020) 利用 非局部结构中的自注意力 和 其他模态的注意力 来融合多模态信息。 Chen 和 Fu (Chen and Fu 2020) 提出了一种替代的细化策略,并结合了 引导残差块 来生成细化特征 和 细化预测。孙等人(Sun et al. 2021) 为 RGB-D SOD 中的异构特征融合设计了一种新的基于 NAS 的模型。这些双流设计 显着增加了网络中的参数数量。
最近,赵等人 (Zhao et al. 2020b) 从结合 深度图和 RGB 图像 开始构建真正的 单流网络,以利用 深度图 提供的潜在对比度信息,这为 RGB-D SOD 领域提供了新的视角。
此外,不同层次的特征具有不同的特征。高级的具有更多的语义信息,有助于定位对象,而低级的具有更详细的信息,可以捕获对象的微妙结构。然而,双流和单流网络 都轻视了跨层融合,这可能导致跨模态融合的有效性显着降低。
本文提出了一种一致性-差异聚合模块,可以应用于多种互补关系(RGB/Depth,High/Low level)的通用组合。
自监督学习(SSL)是无监督学习技术的一个重要分支。它指的是使用 自动生成的标签 显式训练 ConvNet 的学习范式。在训练阶段,为 ConvNets 设计了一个预定义的 pretext 任务,pretext 任务中的伪标签是 根据数据的某些属性 自动生成的。然后训练 ConvNet 来学习前置任务的目标函数。 SSL 训练完成后,将学习到的权重 作为预训练模型 转移到下游任务。该策略可以克服小样本的过拟合问题,获得ConvNets的泛化能力。
许多前置任务被设计并应用于自监督学习,例如 图像修复(Pathak et al 2016)、聚类(Caron et al 2018)、图像着色(Larsson、Maire 和 Shakhnarovich 2017)、时间顺序验证(Misra 、Zitnick 和 Hebert 2016)和 视觉音频对应验证(Korbar、Tran 和 Torresani 2018)。有效的前置任务可以促进 ConvNets 为下游任务学习有用的语义特征。
本文依靠 RGB-D SOD 任务的特点设计了两个相关的前置任务:跨模态自动编码器 和 深度轮廓估计。前者鼓励 双流编码器 学习每个模态信息 并 减少模态间的差距。后者可以进一步 促进跨模态融合,这也提供了一个很好的特征,可以轻松捕获 目标轮廓 和 目标定位。
在本节中,首先描述所提出的 RGB-D SOD 网络的整体架构。然后,介绍了用于 跨模式 和 跨级别特征融合的 一致性-差异聚合 (CDA) 模块 的详细信息。接下来,介绍设计的前置任务:跨模态自动编码器 和 深度轮廓估计。最后,本文列出了网络中用于 前置任务 和 下游任务的所有监督 和 损失函数。
整体架构:

本文的网络架构,如图 1 所示,遵循 双流模型,由五个编码器块、五个过渡层(Ti i ∈ {1、2、3、4、5})、四个解码器块(Di i ∈ {1, 2, 3, 4} ) 和 九个一致性-差异聚合模块。编码器-解码器架构 基于 FPN (Lin et al 2017)。
编码器基于通用骨干网络,例如 VGG-16 (Simonyan and Zisserman 2014),分别对 RGB 和深度进行特征提取。本文抛弃了 VGG-16 的 所有全连接层 和 最后一个池化层,将其修改为全卷积网络。本文将 两种模态编码块的输出特征 传递给 一致性-差异聚合模块,以实现每个级别的 跨模态融合。 CDA (一致性-差异聚合模块)也嵌入在解码器中。一旦获得这些跨模态融合特征,它们就会参与到decoder中,从高层到低层 逐渐融合细节,从而不断恢复全分辨率的显著图。
一致性-差异聚合模块:
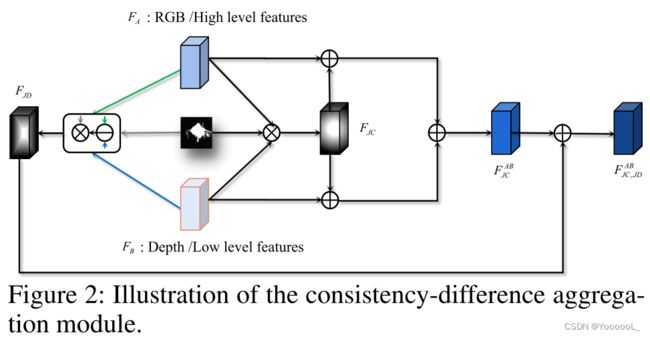
一致性-差异聚合模块 可以 加强特征的一致性 并 突出它们的差异,从而 增加类间差异,减少类内差异。图 2 显示了所提出的 CDA 模块的内部结构。本文使用 FA 和 FB 来表示 不同的 模态 或级别 特征图。它们都已被 ReLU 操作激活。首先,我们在 FA 和 FB 之间 使用逐元素的乘法,同时 受到 side-out侧出预测的 显著图 S 的约束,以获得 通常与显著对象一致的 高置信度的区域特征。这个过程可以表述如下:

其中⊗是 逐元素乘法,Conv(·)表示卷积层。接下来,应用 联合一致的特征 来增强 FA 和 FB 中的显著性线索,从而 产生初始的融合特征,

其中⊕是 逐元素相加。  实现了 特征的一致性提升,尤其是在显著区域。
实现了 特征的一致性提升,尤其是在显著区域。
我们计算 FA 和 FB 的 联合微分特征:
![]()
其中![]() 是逐元素减法, | · |计算绝对值。 FJD 描述了显著区域的特征差异。通过结合和 FJD 生成最终融合:
是逐元素减法, | · |计算绝对值。 FJD 描述了显著区域的特征差异。通过结合和 FJD 生成最终融合:
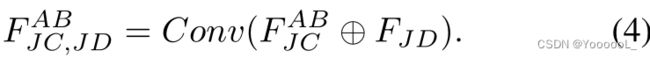
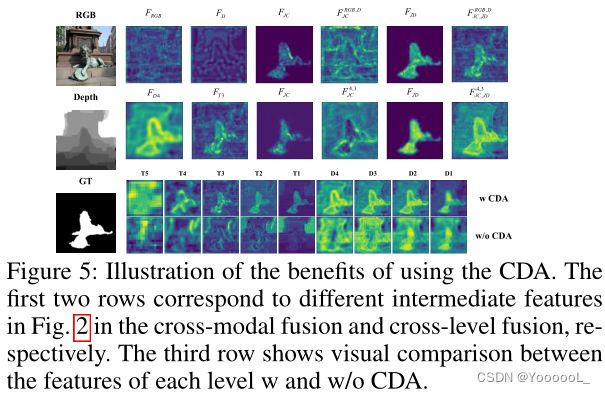
与相比,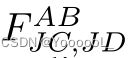 包含更丰富的显著目标的互补信息。通过一系列的加减法,使特征在side-out预测的约束下 得到很好的对齐,从而逐步促进了 特征分布 与 公共空间中前/背景类别的对应关系,如图5所示。
包含更丰富的显著目标的互补信息。通过一系列的加减法,使特征在side-out预测的约束下 得到很好的对齐,从而逐步促进了 特征分布 与 公共空间中前/背景类别的对应关系,如图5所示。
Pretext Tasks:跨模态自动编码器和深度轮廓估计
与以前通过 ImageNet 预训练 获得有效的初始表示 的方法不同,本文设计了一个纯自监督网络 来挖掘 RGB-D 信息 而无需手动注释。图 3 显示了所提出的 SSL 网络的结构,它由两个组件组成,即 跨模式自动编码器 和 深度轮廓估计解码器。
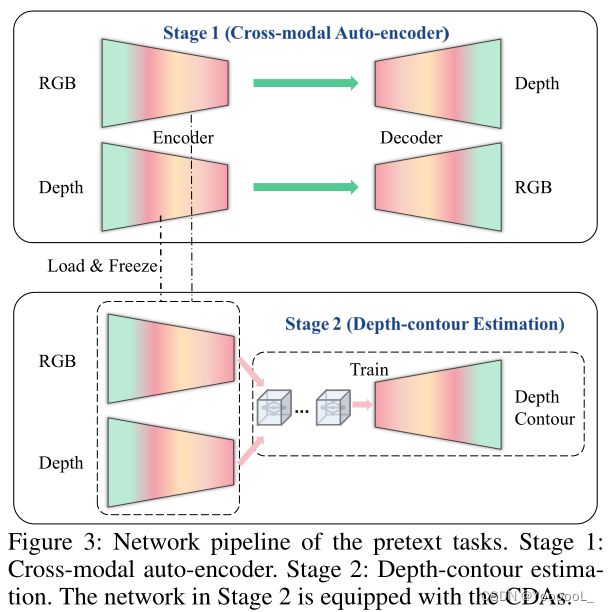
在第一阶段,我们使用 成对的 RGB-Depth 数据 相互预测,即 使用 RGB 图像预测深度图 并 使用深度图重建 RGB 图像。这两个网络的主干基于 随机初始化的 VGG-16。本文直接采用FPN 作为基本结构。通过 跨模态自动编码器,RGB或深度流的编码器 可以分别转向捕捉另一个模态的信息。
这样一来,两个编码器的特征往往会 收敛到一个共同的空间中,这大大减小了模态之间的差距,便于后续的跨模态融合。此外,在相互预测的过程中,可以在各自的流中有效地学习 上下文表示能力。
正如 (Goyal et al 2019),增加前置任务的复杂性 通常有利于 SSL 的性能。本文的跨模式编码器不会以任何方式相互交互。完全独立的跨模态生成 显然提高了难度,使网络尽最大努力学习关于两种模态的有用语义线索。
在第二阶段,我们加载在第一阶段训练的编码器的参数,以计算每个编码流中的多尺度特征。然后,本文利用CDA 模块。实现 预测深度轮廓的 跨模态和跨层级融合。这个前置任务允许进一步的跨模态集成,并且学习的特征为下游任务提供轮廓先验(即一种前/背景语义指导)来预测显著性图。
监督:
在本文的 RGB-D SOD 网络中,总损失写为:
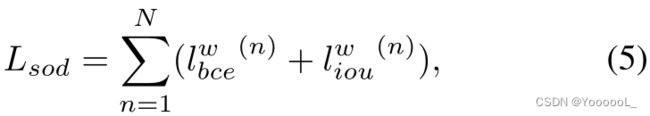
其中 ![]() 和
和![]() 表示 在分割任务中 广泛采用的 加权 IoU 损失 和 二元交叉熵 (BCE) 损失。本文使用与(Wei、Wang 和 Huang 2020;Fan 等人 2020a;Zhao、Zhang 和 Lu 2021)中相同的定义。 N表示侧出的数量。本文的 RGB-D SOD 模型由五个输出深度监督,即 N = 5。
表示 在分割任务中 广泛采用的 加权 IoU 损失 和 二元交叉熵 (BCE) 损失。本文使用与(Wei、Wang 和 Huang 2020;Fan 等人 2020a;Zhao、Zhang 和 Lu 2021)中相同的定义。 N表示侧出的数量。本文的 RGB-D SOD 模型由五个输出深度监督,即 N = 5。
跨模态自动编码器任务包括 深度估计 和 RGB 重建。由于 RGB 和深度信息都呈现 场景中的patch一致性,本文遵循相关的深度估计工作(Pillai、Ambrus 和 Gaidon 2019;Ranftl 等 2020;Ocal 和 Mustafa 2020)采用 L1 和 SSIM 的组合损失(王、西蒙切利和博维克,2003 年)。 SSIM 的使用非常适合作为 patch级正则化的损失函数。 L1 loss 计算 预测的映射图 和 真值之间的绝对距离,在像素级进行监督。
SSIM-loss 和 L1-loss 的结合使网络同时具有 patch级 和 像素级 监督,从而促进 更局部一致的预测。
对于深度轮廓估计任务,其真值(Gdc) 是根据 RGB-D 数据集提供的深度图 (Gd) 计算的。具体来说,本文采用如下的 形态学膨胀和腐蚀:

其中 D(·) 和 E(·) 分别是 膨胀和腐蚀操作。 m 表示一个大小为 m × m 的完整过滤器,用于腐蚀和膨胀。本文设置为 5。本文只在训练阶段对每个 旁侧side-out 使用 L1-loss。
Experiments:
MAE 值越低越好,其他值越高越好。一般来说,大规模数据集可以保证模型性能的评价稳定性,而小规模数据集往往会出现较大的性能波动。
本文首先使用 随机初始化 来训练 SSL 跨模式自动编码器。然后加载每个流的编码器参数,用于接下来的 深度轮廓估计。在这个过程中,双流编码器的参数被冻结,只用 CDA 模块训练解码器。一旦前置任务完成,我们加载它们的参数以初始化下游任务(RGB-D SOD)的网络。
本文采用了一些数据增强技术来避免过度拟合:随机水平翻转、随机旋转、随机亮度、饱和度和对比度。
图 1 显示了 F 度量、加权 F 度量、S 度量、E 度量和 MAE 分数方面的性能比较。根据每个测试集占所有测试集的比例,对所有数据集上的结果进行加权求和,得到一个整体性能评价,在“Ave-Metric”行中列出。
本文的全监督(即ImageNet预训练)模型在总排名的18个模型中 排名第一。在所有数据集的 30 个分数中,本文的 26 个分数达到了前三名。这表明 本文的模型具有出色的综合能力。值得注意的是,本文的自监督模型仍然可以胜过大多数全监督方法,在其中排名第九,这表明了自监督学习的巨大潜力和 本文设计的前置任务的有效性。
本文所提出的方法在各种具有挑战性的场景中产生更接近真值的结果。对于具有单个对象的图像,本文的方法可以完全分割整个对象,而其他竞争对手或多或少地丢失了对象的部分(见第 1 行和第 2 行)。对于具有多个对象的图像,本文的方法仍然可以准确地定位和捕获所有对象(参见第 3 行和第 4 行)。此外,可以看出,与其他完全监督的方法相比,本文的 SSL 模型甚至具有更好的视觉效果。
Ablation:
一致性-差异聚合的有效性:
在表 2 中,我们根据加权平均指标“Ave-Metric”显示了所有 RGB-D SOD 数据集上不同结构所贡献的性能。基线(模型 1)是具有深度监督的双流 FPN 结构。我们可以看到这个基线已经强于 A2DELE 和 DisenFuse。基于这个强大的基线,性能提升更具说服力。
模型 2 与模型 1 和 模型 4 与模型 1 分别显示了 联合一致特征 (JC) 在跨模式和跨级别集成中的有效性。 联合一致 JC 可以显著提高性能。同样,模型 3 与模型 2 和模型 5 与模型 4 显示了 联合微分特征(JD)的优势。 Model 6 在跨模式和跨层融合中都配备了 CDA 模块。模型 6 与模型 3 和模型 6 与模型 5 展示了 CDA 在两种信息融合中的泛化,两者相辅相成,互不排斥。
为了进一步评估该模块的合理性,将CDA替换为一些加法和卷积操作,并保留了相似数量的参数。这个新网络被称为 Model 7。与它相比,Model 6 在性能上具有明显的优势。
本文将 CDA 模块中的中间特征可视化,如图 5 所示。通过在显著图的约束下显式叠加跨模态(或跨级别)联合一致性 FJC 和联合差异 FJD 的影响,融合特征 可以很好地突出显著区域。因此,配备 CDA 的网络可以更完整地提取显著目标,而没有 CDA 的网络会受到大量非显着区域的干扰(见图 5 中的第三行)。补充材料中显示了更多比较。
可以很好地突出显著区域。因此,配备 CDA 的网络可以更完整地提取显著目标,而没有 CDA 的网络会受到大量非显着区域的干扰(见图 5 中的第三行)。补充材料中显示了更多比较。
自监督预训练的有效性:
在表 3 中,本文根据加权平均指标“Ave-Metric”评估了所提出的 SSL 前置对 RGB-D SOD 任务的有效性。首先,我们训练第一个前置(P1),跨模态自动编码器。如图 6 所示,预测的深度图接近 GT,重建的 RGB 图像明显符合原始图像的语义,例如天空变成蓝色,甚至猫也被涂上了白色。

接下来,我们从 P1 加载预训练参数来联合训练第二个前置(P2),深度轮廓估计。视觉结果如图 6 模型 2 与模型 1 的对比表明,P1 任务可以显著提高双流编码器的表示能力。模型 3 与模型 2、模型 5 与模型 4 和模型 7 与模型 6 证明了 P2 任务的有效性。此外,Model 4 vs. Model 2和Model 5 vs. Model 3可以进一步验证 CDA在跨模态融合中的作用。而 Model 6 vs. Model 2 和 Model 7 vs. Model 3 展示了CDA在跨层融合中的优势。最后,模型 9 与模型 8 表明了两个自监督学习借口的总体贡献。可以看出,在加权 F-measure 和 MAE 方面,性能显着提高,分别为 7.95% 和 27.42%。
此外,本文将本文提出的 通用双流自监督编码器(SSL-P1)的预训练权重加载到表1中的第二种和第四种方法(第三种是基于 ResNet-18 主干网)中。 作为初始化并重新训练它们。从表 4 可以看出,与随机初始化相比,使用自监督预训练权重可以帮助两种性能最佳的方法持续获得巨大的性能提升。这充分验证了本文 SSL 设计的泛化能力。更多比较可以在补充材料中找到。
预训练数据规模的评估:
在表5,我们列出了使用不同数量的 SSL 训练图像的性能。当仅使用 ∼2, 000 个样本时,基于 SSL 的网络已经明显优于随机初始化的网络。随着训练数据的增加,性能稳步提高,这表明本文的 SSL 模型具有很大的潜力。更多比较可以在补充材料中找到。
Conclusion:
本文提出了一种新颖的自监督学习 (SSL) 方案来完成 RGB-D SOD 的有效预训练,而无需人工注释。 SSL 前置任务包含 跨模态自动编码器 和 深度轮廓估计,通过它们网络可以捕获丰富的上下文 并 减少模态之间的差距。此外,本文设计了一个一致性-差异聚合模块 来结合 跨模态 和 跨级别 的信息。大量实验表明本文的模型在 RGB-D SOD 数据集上表现良好。作为 RGB-D SOD 中 SSL 的第一种方法,它可以作为未来研究的新基线。