《MobileNetV2: Inverted Residuals and Linear Bottlenecks》论文学习笔记
文章目录
- 论文基本信息
- 研究背景
- 读完摘要后对上述问题的回答
- 读完论文后对上述问题的回答
-
- 什么是MobileNet V2?
-
- 为啥要在前边加一个Pointwise convolution?
- 什么是反向残差?
- 什么是线性瓶颈?
-
- Mobile的两种步长的不同流程
- 为什么这里进行先升维,再降维的操作后,效率提升了?
- 实验验证
-
- ImageNet分类
- 目标检测
- 语义分割
- 消融研究
- 代码分析
- 目前存在的疑问
论文基本信息
- 标题:《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
- 作者:Mark Sandler, Andrew Howard, Menglong Zhu ,Andrey Zhmoginov ,Liang-Chieh Chen
- 机构:Google Inc.
{sandler, howarda, menglong, azhmogin, lcchen}@google.com - 时间:2018
- 论文地址:arXiv:1801.04381v3 [cs.CV] 2 Apr 2018
- code:https://github.com/OUCTheoryGroup/colab_demo/blob/master/202003_models/MobileNetV2_CIFAR10.ipynb
研究背景
MobileNet V1的主要问题: 结构非常简单,但是没有使用ResNet里的residual learning; 另一方面,Depthwise Conv确实是极大程度降低了计算量,但实际中,发现不少训练出的kernel是空的。
MobileNet V2主要的改动之一:设计了inverted residual block。
读完摘要后对上述问题的回答
- 什么是MobileNet V2?
- 什么是反向残差?
- 什么是线性瓶颈?
- 为什么在这里升维后效率还有所提升?不应该是计算量增加?
读完论文后对上述问题的回答
什么是MobileNet V2?
这里先回顾一下MobileNets的网络结构:将卷积层转换为深度可分离卷积Depthwise convolution和Pointwise convolution。

而MobileNet V2则是在Depthwise convolution前添加了一层Pointwise convolution,变成了一个两端细,中间粗的结构。
为啥要在前边加一个Pointwise convolution?
通过对MoilbeNets的学习,我们可以知道深度可分离卷积中的Depthwise convolution中的卷积核数量取决于上一层的通道数,即V1提出的深度可分离卷积没有改变通道数的能力,但是一开始也进行了叙述,V1最后得到的kenerl有很多是空的,这里就表明训练不足,所以提出了V2的结构,我们先使用一层Pointwise convolution进行升维,再进行Depthwise convolution训练,最后通过Pointwise convolution进行降维。这里还存在一个反向残差后边会进行介绍。
什么是反向残差?
残差,大家在学习了residual net后有了一个初步的了解,即H(x)=f(x)+x,这种模式。

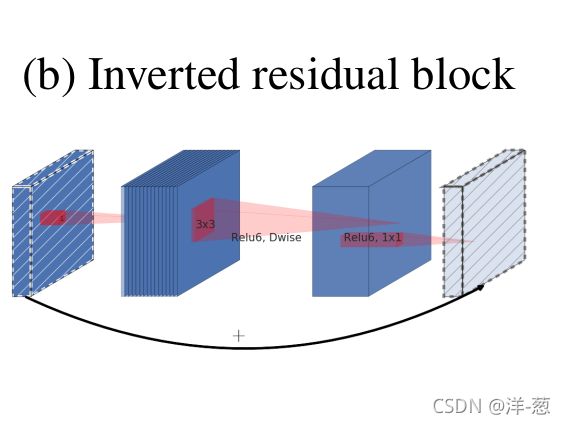
上边是论文的截图,可以看到,正常的残差是两端粗,中间细,而反向残差则是两端细,中间粗,与正常的残差正好相反。
什么是线性瓶颈?
瓶颈,就是说的我们所使用的1*1的Pointwise convolution。
线性,论文在进行高维操作的时候使用的是非线性ReLU6,而在低维的时候使用非线性会破坏特征,所以在降维操作的Pointwise convolution使用的Linear。
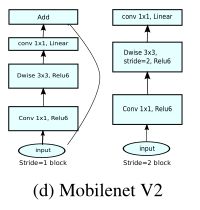
Mobile的两种步长的不同流程
当stride=1时:
- pointwise convolution进行升维;
- depthwise convolution进行提取特征;
- 通过Linear+Pointwise convolution进行降维;
- input与result进行相加(残差结构)。
当stride=2时:
因为input和output的大小不同,所以没有添加shortcut结构。
为什么这里进行先升维,再降维的操作后,效率提升了?
很多人都有这个想法,就是我们常见的减少计算量的方法就是在卷积过程中,先进行通道数的降维压缩,再经过特征提取和训练后,再将通道数进行升维恢复,这一个过程可以减少训练过程中的计算量。而这里所提出的想法貌似和大家的理解背道而驰。
在经过网上资料的学习后,可以知道,我们原本的V1的结构是可以减少计算量的,而V2的升维的时候会限制在一个范围,而这个范围则是原本直接使用卷积的通道数量,所以我们可以看作我们即使升维了,也会比原本的计算量少。
实验验证
ImageNet分类
培训的设置。 我们使用TensorFlow[31]训练我们的模型。我们使用标准的RMSPropOptimizer,衰减和动量都设置为0.9。每层后我们都采用批归一化,标准重量衰减设置为0.00004。在MobileNetV1[27]设置之后,我们使用初始学习率为0.045,学习率衰减率为0.98 / epoch。我们使用16个GPU异步工作器,96个批量。
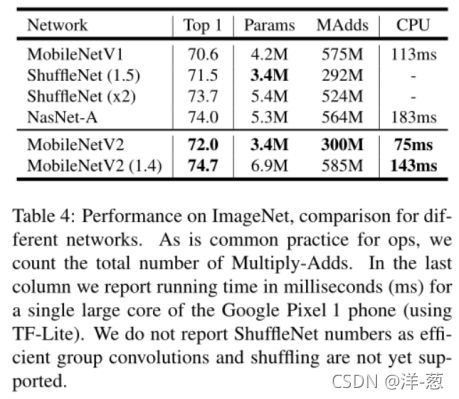
结果。 我们将我们的网络与MobileNetV1、ShuffleNet和NASNet-A模型进行了比较。表4显示了一些选定模型的统计信息,完整的性能图如图5所示。

目标检测
我们评估和比较了MobileNetV2和MobileNetV1作为特征提取器[33]在COCO数据集[2]上与改进版本的Single Shot Detector (SSD)[34]进行对象检测的性能。我们还比较了YOLOv2[35]和原始SSD(以VGG-16[6]为基础网络)作为基线。我们不比较其他架构的性能,如Faster-RCNN[36]和RFCN[37],因为我们的重点是移动/实时模型。
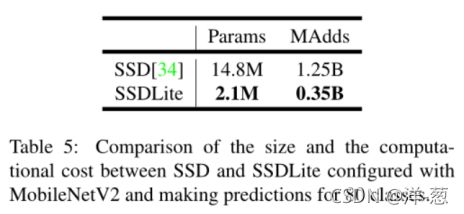
SSDLite:在本文中,我们介绍了一种移动友好型的常规SSD。在SSD预测层中,我们将所有的正则卷积替换为可分离卷积(深度上跟随1 × 1投影)。这种设计与mobilenet的总体设计一致,计算效率更高。我们称这个修改后的版本为SSDLite。与常规SSD相比,SSDLite大大减少了参数计数和计算成本,如表5所示。
对于MobileNetV1,我们遵循[33]中的设置。对于MobileNetV2,第一层SSDLite附着在第15层的扩展上(输出步幅为16)。第二个和其余的ssdlitellayers被附加在最后一层的顶部(输出步幅为32)。这个设置与MobileNetV1是一致的,因为所有层都附加到相同输出步幅的特征映射上。
这两个MobileNet模型都使用开源TensorFlow对象检测API[38]进行训练和评估。两种型号的输入分辨率都是320 × 320。我们对mAP (COCO挑战指标)、参数数量和乘数进行了基准测试和比较。结果如表6所示。MobileNetV2 SSDLite不仅是三种模型中最高效的,而且是最精确的。值得注意的是,MobileNetV2 SSDLite的效率比YOLOv2高20倍,体积小10倍,但在COCO数据集上仍然优于YOLOv2。

语义分割
在本节中,我们将MobileNetV1和MobileNetV2模型作为特征提取器与DeepLabv3[39]进行移动语义分割任务的比较。DeepLabv3采用atrous卷积[40,41,42],这是一个强大的工具来明确控制计算特征图的分辨率,并构建了5个并行头,包括(a) atrous空间金字塔池模块(ASPP)[43],包含3个不同atrous速率的3 × 3卷积,(b) 1 × 1卷积头,©图像级特征[44]。输出步幅表示输入图像空间分辨率与最终输出分辨率的比值,该比值通过适当地应用atrous卷积来控制。对于语义分割,对于密度较大的特征图,我们通常使用输出stride = 16或8。我们在PASCAL VOC 2012数据集[3]上进行实验,从[45]中添加额外的注释图像和评价指标mIOU。
为了构建移动模型,我们尝试了三种设计变体:(1)不同的特征提取器,(2)简化DeepLabv3头部以加快计算速度,以及(3)不同的推理策略以提高性能。我们的结果汇总在表7中。我们观察到:(a)多尺度输入和添加左向翻转图像的推理策略显著增加了MAdds,因此不适合设备上的应用;(b)使用output stride = 16比output stride = 8更有效;© MobileNetV1已经是一个强大的功能提取器,只需要比ResNet-101[8]少4.9 - 5.7倍的MAdds(例如,mIOU: 78.56 vs 82.70,和MAdds:991.9 b vs 4870.6B), (d)在MobileNetV2的最后一层feature map上构建DeepLabv3头比在原来的最后一层feature map上更有效,因为最后一层feature map包含320个通道而不是1280个,通过这样做,我们获得了相似的性能,但是需要的操作比MobileNetV1少2.5倍左右,(e) DeepLabv3头计算昂贵,删除ASPP模块显著减少了MAdds,只有轻微的性能下降。在theendofthetable7中,我们确定了一个设备上应用程序的潜在候选(粗体),它达到75.32% mIOU,只需要2.75B MAdds。
消融研究
反向残差连接。 剩余连接的重要性已经得到了广泛的研究[8,30,46]。本文报告的新结果是,快捷方式连接瓶颈的性能优于快捷方式连接扩展层(如图6b所示)。

线性瓶颈的重要性。 线性瓶颈模型比非线性模型更弱,因为激活总是在线性范围内运行,并对偏差和比例做出适当的改变。然而,如图6a所示的实验表明,线性瓶颈提高了性能,提供了非线性破坏低维空间信息的支持。
代码分析
expand + Depthwise + Pointwise 其中,expand就是增大feature map数量的意思。需要指出的是,当步长为1的时候,要加一个 shortcut;步长为2的时候,目的是降低feature map尺寸,就不需要加 shortcut 了。
#导入所需的包
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
#定义Block
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, in_planes, out_planes, expansion, stride):
super(Block, self).__init__()
self.stride = stride
# 通过 expansion 增大 feature map 的数量
planes = expansion * in_planes
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=planes, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes)
# 步长为 1 时,如果 in 和 out 的 feature map 通道不同,用一个卷积改变通道数
if stride == 1 and in_planes != out_planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_planes))
# 步长为 1 时,如果 in 和 out 的 feature map 通道相同,直接返回输入
if stride == 1 and in_planes == out_planes:
self.shortcut = nn.Sequential()
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
# 步长为1,加 shortcut 操作
if self.stride == 1:
return out + self.shortcut(x)
# 步长为2,直接输出
else:
return out
创建MobileNetV2网络
注意:这里的CIFAR10是32*32,因此,网络有一些修改。
class MobileNetV2(nn.Module):
# (expansion, out_planes, num_blocks, stride)
cfg = [(1, 16, 1, 1),
(6, 24, 2, 1),
(6, 32, 3, 2),
(6, 64, 4, 2),
(6, 96, 3, 1),
(6, 160, 3, 2),
(6, 320, 1, 1)]
def __init__(self, num_classes=10):
super(MobileNetV2, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.conv2 = nn.Conv2d(320, 1280, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(1280)
self.linear = nn.Linear(1280, num_classes)
def _make_layers(self, in_planes):
layers = []
for expansion, out_planes, num_blocks, stride in self.cfg:
strides = [stride] + [1]*(num_blocks-1)
for stride in strides:
layers.append(Block(in_planes, out_planes, expansion, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.relu(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
创建Dataloader
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
实例化网络
# 网络放到GPU上
net = MobileNetV2().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
模型训练
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
模型测试
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))
![]()