人工智能实践——第八周【卷积网络与tensorboard】
卷积神经网络:
全连接网络的缺陷:
1:数据量过大,运算负担重
2:参数过大,出现过拟合现象
有效提取图像特征的方法
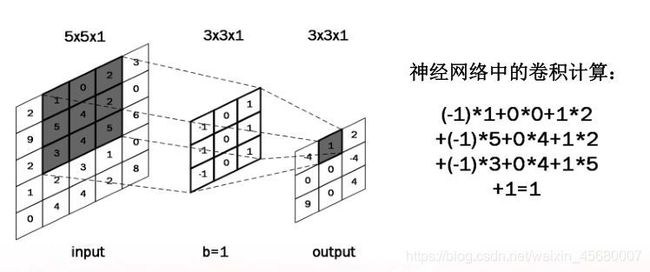
正方形卷积核(过滤器),遍历图片上的每个点
图片区域内,相对应的每一个像素值乘以卷积核内相对应点的权重,求和,再加上偏置。
输出图片边长= (输入图片边长 – 卷积核长 + 1 )/ 步长
此图:((5 – 3 + 1 )/ 1 = 3
有些时候需要输出图片边长和输入图片边长相同,则裹上n层0padding
可以看到,原来55,增加一层padding后变成77,则根据计算公式
(7-3+1)/1=5,输出图片边长和输入图片边长相同
即在Conv2D的padding中,如果选择valid,则不填充。选择same,填充i层使得图像大小不发生变化

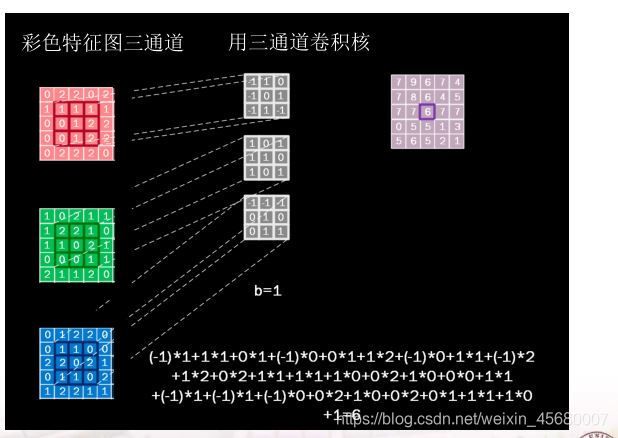
有时输入是多个channel,则利用多次处理:(三个通道和输入的三个channel分别相乘后)相加求和
可以看到,有多少个channel,就有多少个卷积核
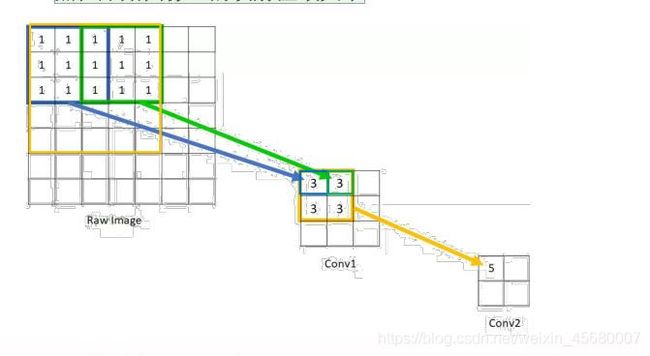
有时图像信息多,一个卷积核提取信息不充分,则利用多次进行提取。
可以看到,卷积核的数量=channel*卷积次数
输出的数量=卷积次数,两次卷积后得到两个不同输出

感受野(Receptive Field):卷积 ):输出层每个像素点在输入图像上的映射区域
tf.keras.layers.Conv2D (
input_shape = (高, 宽 , 通道数) #仅在第一层有
filters = 卷积核个数,
kernel_size = 卷积核尺寸,
strides = 卷积步长,
padding = “valid” or “same”,//valid代表不填充,samm指的是填充padding,让输入尺寸和输出尺寸相同
activation = “ relu ” or “ sigmoid ” or “ tanh ” or “ softmax”等 , #如有BN此处不写需要在BN后才调用激活函数
)
池化层(下采样层):通常用Dropout进行连接

tf.keras.layers.MaxPool2D(
pool_size=池化核尺寸, 池化核尺寸,
strides=池化步长 池化步长 ,
padding=‘valid’or‘same’
)
tf.keras.layers.AveragePooling2D(
pool_size=池化核尺寸, 池化核尺寸,
strides=池化步长 池化步长 ,
padding=‘valid’ or‘same’
)
总的来说:卷积就是实现 高层抽取,就是CBAMD
卷积——BN——激活函数——池化——Dropout——全连接
数据增强:但数据量小的时候
image_gen_train = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255, # 原像素值0 ~255 归至0 ~1
rotation_range=45, # 随机45度度旋转
width_shift_range=.15, #随机宽度偏移 [-0.15,0.15)
height_shift_range=.15, #随机高度偏移 [-0.15,0.15)
horizontal_flip=True, #随机水平翻转
zoom_range=0.5 #随机缩放到[1-50% %, ,1+50%]
)
model.fit(image_gen_train.flow(x_train, y_train,batch_size=32), ……)
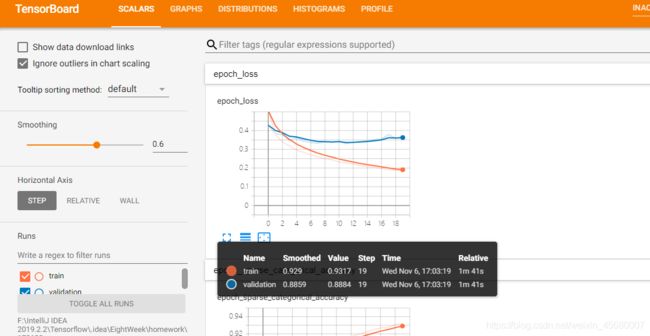
数据可视化的利器 TensorBoard
创建一个回调,每5个epochs保存模型的权重
checkpoint_path = “./checkpoint/cp-{epoch:04d}.ckpt”//每五次epoch进行一次保存
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=True,
verbose=1,
period=5)
filepath: 字符串,保存模型的路径。
monitor: 被监测的数据。val_acc或这val_loss
verbose: 详细信息模式,0 或者 1 。0为不打印输出信息,1打印
save_best_only: 如果 save_best_only=True, 将只保存在验证集上性能最好的模型
mode: {auto, min, max} 的其中之一。 如果 save_best_only=True,那么是否覆盖保存文件的决定就取决于被监测数据的最大或者最小值。 对于 val_acc,模式就会是 max,而对于 val_loss,模式就需要是 min,等等。 在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。
save_weights_only: 如果 True,那么只有模型的权重会被保存 (model.save_weights(filepath)), 否则的话,整个模型会被保存 (model.save(filepath))。
period: 每个检查点之间的间隔(训练轮数)。
创建一个回调,为TensorBoard编写一个日志
log_dir = ‘.\logs\’ +datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir,
histogram_freq=1,
update_freq=‘epoch’)
log_dir:保存TensorBoard要解析的日志文件的目录的路径。
histogram_freq:频率(在epoch中),计算模型层的激活和权重直方图。如果设置为0,则不会计算直方图。
TensorBoard。这同样适用’epoch’。如果使用整数,比方说1000,回调将会在每1000个样本后将指标和损失写入TensorBoard。请注意,过于频繁地写入TensorBoard会降低您的训练速度
#使用新的回调训练模型
model.fit(x_train, y_train, epochs=20, validation_data=(x_test, y_test),
callbacks=[tb_callback, cp_callback], validation_freq=1, verbose=1)
运行模型后,生成两个文件夹。分别是
存放Model的checkpoint文件夹,存放的是每5epoch的模型
存放可视化目录的log文件夹,存放的是可视化目录
之后在终端里
tensorboard --logdir=“F:\IntelliJ IDEA 2019.2.2\Tensorflow.idea\EightWeek\homework\logs\20191106-170132”
会出现http地址

进入后即可可视化模型