高斯分布的极大似然估计
本文是关于 coursera 上 《Robotics: Estimation and Learning》 课程的笔记。
前面通过一个例子简单地介绍了极大似然估计的意思,现在来对高斯分布做极大似然估计。
一维高斯分布
概率密度函数
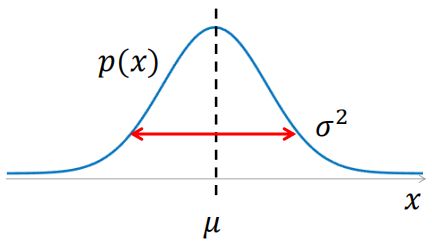
一维高斯分布(Gaussian Distribution)的概率密度函数如下:
p ( x ) = 1 2 π σ exp { − ( x − μ ) 2 2 σ 2 } p(x)=\frac{1}{\sqrt{2\pi} \sigma} \exp \left\{ - \frac{(x-\mu)^2}{2\sigma^2} \right\} p(x)=2πσ1exp{−2σ2(x−μ)2}
高斯分布非常有用,而且非常重要:
∙ \bullet ∙ 描述高斯分布只需要 2 个参数,均值 μ \mu μ 和 方差 σ 2 \sigma^2 σ2,它们就是该分布的本质信息,同也容易计算和解释。
∙ \bullet ∙ 高斯分布具有一些很好的数学性质,比如多个高斯分布的乘积可以形成另一个高斯分布,所以你不需要担心遇到其它形式的分布。
∙ \bullet ∙ 中心极限定理告诉我们,任何随机变量的样本均值的期望,都收敛于高斯分布,这说明高斯分布是一个为噪声和不确定性建模的合适选择。
下面举一个例子,图片处理的问题,看看在目标颜色的建模中如何运用高斯分布。
小球颜色
下面的图片里有一个黄色小球。人眼一下就能看出,但是电脑怎么知道它的颜色?

统计它每个像素的色相值,得到下面的直方图:

纵轴可以认为是像素点的数量,横轴是像素点的色相值。
大部分像素点的色相值在 50 ∼ 60 50 \sim 60 50∼60 ,这部分刚好是黄色所在色相区间。(黑色部分先忽略)
按照经验可以认为它是黄色小球。
如果这个图片的像素是 1920 × 1080 1920\times1080 1920×1080 呢?
有两百多万像素,统计这样的直方图需要巨大内存,非常消耗资源。
极大似然估计
为了减少工作量,我们从中抽取部分像素点,记它们的色调值为 ( x 1 , x 2 , x 3 , … , x i ) (x_1,x_2,x_3,\dots,x_i) (x1,x2,x3,…,xi)。
通过这一部分样本,来估算这张图片所有像素点的色相的分布,推算小球的颜色。
我们剧透一下结果:
由中心极限定理或者上面的直方图,可以认为该样本满足高斯分布。
求出概率密度函数中的 μ \mu μ 和 σ \sigma σ,即可得到像素点色调值的分布,大概会像这样:
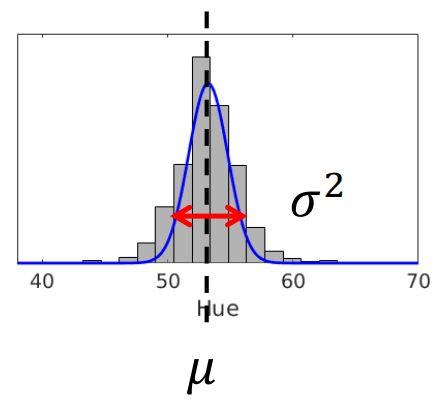
根据 μ \mu μ 可以推断小球颜色。
我们把抽取的像素点成为观测数据,如何通过观测数据,求出其概率模型的参数?
方法就是用极大似然估计(maximum likelihood estimation)。
上一篇文章通过一个例子简单介绍过它的意思。
现在我们运用高斯分布模型,它的参数是 μ \mu μ 和 σ \sigma σ。
对于观测数据 ( x 1 , x 2 , x 3 , … , x i ) (x_1,x_2,x_3,\dots,x_i) (x1,x2,x3,…,xi),我们关心的是能将似然函数最大化的参数, μ ^ \hat{\mu} μ^ 和 σ ^ \hat{\sigma} σ^。
用数学的方式来表达: μ ^ , σ ^ = arg max μ , σ p ( { x i } ∣ μ , σ ) \hat{\mu},\hat{\sigma} = \arg\max_{\mu,\sigma} p(\{x_i\}|\mu,\sigma) μ^,σ^=argμ,σmaxp({xi}∣μ,σ)
上标 ^ \hat{ } ^ 表示估计值。
我们需要最大化的似然函数是所有样本数据的联合概率,假设每一个观测之间都是相互独立的,联合似然函数就可以被简单地写成:关于每个样本的似然函数的乘积 。于是: p ( { x i } ∣ μ , σ ) = ∏ i = 1 N p ( x i ∣ μ , σ ) p\left(\{x_i\}|\mu,\sigma \right)= \prod^{N}_{i=1}p(x_i|\mu,\sigma) p({xi}∣μ,σ)=i=1∏Np(xi∣μ,σ)
所以似然函数是: μ ^ , σ ^ = arg max μ , σ ∏ i = 1 N p ( x i ∣ μ , σ ) \hat{\mu},\hat{\sigma} = \arg\max_{\mu,\sigma} \prod^{N}_{i=1}p(x_i|\mu,\sigma) μ^,σ^=argμ,σmaxi=1∏Np(xi∣μ,σ)
要求解这个似然函数,我们用到一些对数函数的特性。先画一个对数函数的样子:
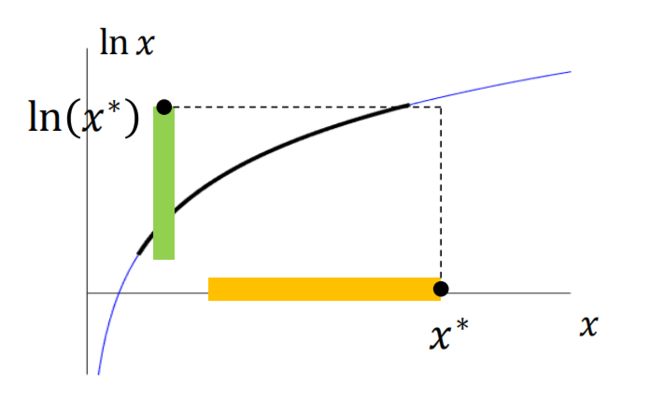
它是关于 x x x 单调递增的,原函数取对数后,单调性不变。
利用这个特性,我们改变一下求解目标:最大化对数似然函数。
arg max μ , σ ∏ i = 1 N p ( x i ∣ μ , σ ) = arg max μ , σ ln { ∏ i = 1 N p ( x i ∣ μ , σ ) } (1) \arg\max_{\mu,\sigma} \prod^{N}_{i=1}p(x_i|\mu,\sigma) = \arg\max_{\mu,\sigma} \textcolor{red}{ \ln} \left\{ \prod^{N}_{i=1}p(x_i|\mu,\sigma) \right\} \tag{1} argμ,σmaxi=1∏Np(xi∣μ,σ)=argμ,σmaxln{i=1∏Np(xi∣μ,σ)}(1)
虽然改变了目标函数,但是使目标函数达到最大值的参数值是一样的,最大化对数似然函数往往更简单。
对数函数的还一个特点是: log ( x 1 x 2 … x k ) = log ( x 1 ) + log ( x 2 ) + ⋯ + log ( x k ) \log(x_1x_2\dots x_k) = \log(x_1) + \log(x_2) + \dots + \log(x_k) log(x1x2…xk)=log(x1)+log(x2)+⋯+log(xk)
所以将式子 (1) 展开得到: arg max μ , σ ∏ i = 1 N p ( x i ∣ μ , σ ) = arg max μ , σ ln { ∏ i = 1 N p ( x i ∣ μ , σ ) } = arg max μ , σ ∑ i = 1 N ln p ( x i ∣ μ , σ ) \begin{aligned} \arg\max_{\mu,\sigma} \prod^{N}_{i=1}p(x_i|\mu,\sigma) &= \arg\max_{\mu,\sigma} \ln \left\{ \prod^{N}_{i=1}p(x_i|\mu,\sigma) \right\} \\ &= \arg\max_{\mu,\sigma} \sum^{N}_{i=1} \ln \textcolor{purple}{ p(x_i|\mu,\sigma) } \end{aligned} argμ,σmaxi=1∏Np(xi∣μ,σ)=argμ,σmaxln{i=1∏Np(xi∣μ,σ)}=argμ,σmaxi=1∑Nlnp(xi∣μ,σ)
将高斯分布的概率密度函数代进去: p ( x i ∣ μ , σ ) = 1 2 π σ exp { − ( x i − μ ) 2 2 σ 2 } \begin{aligned} \textcolor{purple}{ p(x_i|\mu,\sigma) } &= \frac{1}{\sqrt{2\pi} \sigma} \exp \left\{ - \frac{(x_i-\mu)^2}{2\sigma^2} \right\} \end{aligned} p(xi∣μ,σ)=2πσ1exp{−2σ2(xi−μ)2}
所以: ln p ( x i ∣ μ , σ ) = ln 1 2 π σ exp { − ( x i − μ ) 2 2 σ 2 } = { − ( x i − μ ) 2 2 σ 2 − ln σ − ln 2 π } \begin{aligned} \ln p(x_i|\mu,\sigma) &= \ln \frac{1}{\sqrt{2\pi} \sigma} \exp \left\{ - \frac{(x_i-\mu)^2}{2\sigma^2} \right\} \\ &= \left\{ - \frac{(x_i-\mu)^2}{2\sigma^2} - \ln \sigma - \ln \sqrt{2\pi} \right\} \end{aligned} lnp(xi∣μ,σ)=ln2πσ1exp{−2σ2(xi−μ)2}={−2σ2(xi−μ)2−lnσ−ln2π}
常数项 ln 2 π \ln \sqrt{2\pi} ln2π 可以去掉,因为它不影响参数的估计。
再把负号去掉,把 max \max max 变成 min \min min,从而把这个方程变成最小化问题。
两个方程是等价的,而且最小化形式是优化问题的标准形式。
所以我们的求解问题变成了这样: μ ^ , σ ^ = arg min μ , σ ∑ i = 1 N { ( x i − μ ) 2 2 σ 2 + ln σ } \hat{\mu},\hat{\sigma} = \arg\min_{\mu,\sigma} \color{OrangeRed}{ \sum^{N}_{i=1} \left \{ \frac{(x_i-\mu)^2}{2\sigma^2} + \ln \sigma \right\} } μ^,σ^=argμ,σmini=1∑N{2σ2(xi−μ)2+lnσ}
把上面 橙色 部分整体用 J ( μ , σ ) \textcolor{OrangeRed}{ J (\mu,\sigma)} J(μ,σ) 表示,这是对最小化问题代价函数的一个常用记号 。
利用凸优化问题的判据,令 J J J 的一阶偏导为 0 0 0 可以算出使似然函数最大的 μ \mu μ 和 σ \sigma σ:
∂ J ∂ μ = 0 ⟶ μ ^ \frac{\partial J }{ \partial \mu } = 0 \quad \textcolor{green}{ \longrightarrow} \quad \hat{\mu} ∂μ∂J=0⟶μ^ ∂ J ( μ ^ , σ ) ∂ σ = 0 ⟶ σ ^ \frac{\partial J (\hat{\mu},\sigma)}{ \partial \sigma} = 0 \quad \textcolor{green}{ \longrightarrow} \quad \hat{\sigma} ∂σ∂J(μ^,σ)=0⟶σ^
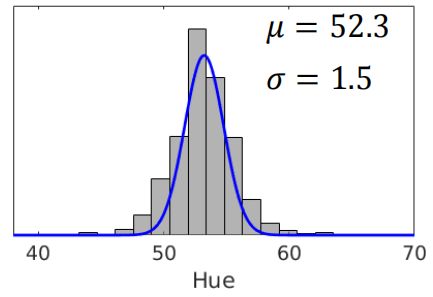
最后得到求解公式是: μ ^ = 1 N ∑ i = 1 N x i σ ^ 2 = 1 N ∑ i = 1 N ( x i − μ ^ ) 2 \begin{aligned} \hat{\mu} &= \frac{1}{N} \sum^{N}_{i=1} x_i \\ \hat{\sigma} ^2 &= \frac{1}{N} \sum^{N}_{i=1} (x_i - \hat{\mu} ) ^2 \end{aligned} μ^σ^2=N1i=1∑Nxi=N1i=1∑N(xi−μ^)2
代入所有观测数据 x i x_i xi,得到 μ = 52.3 \mu = 52.3 μ=52.3 , σ = 1.5 \sigma = 1.5 σ=1.5。
推导
偏导的过程是这样求得: ∂ J ∂ μ = ∂ ∂ μ ∑ i = 1 N { ( x i − μ ) 2 2 σ 2 + ln σ } = ∑ i = 1 N { ∂ ∂ μ ( x i − μ ) 2 2 σ 2 } = 1 σ 2 ∑ i = 1 N ( x i − μ ) = 0 ⇓ μ ^ = 1 N ∑ i = 1 N x i \begin{aligned} \frac{\partial J }{ \partial \mu } &= \frac{\partial }{ \partial \mu } \sum^{N}_{i=1} \left \{ \frac{(x_i-\mu)^2}{2\sigma^2} + \ln \sigma \right\} \\ &= \sum^{N}_{i=1} \left \{ \frac{\partial }{ \partial \mu } \frac{(x_i-\mu)^2}{2\sigma^2} \right\} \\ &= \frac{1}{\sigma^2} \sum^{N}_{i=1}(x_i - \mu) = 0 \end{aligned} \\ \textcolor{green}{ \Downarrow } \\ \quad \\ \hat{\mu} = \frac{1}{N} \sum^{N}_{i=1} x_i ∂μ∂J=∂μ∂i=1∑N{2σ2(xi−μ)2+lnσ}=i=1∑N{∂μ∂2σ2(xi−μ)2}=σ21i=1∑N(xi−μ)=0⇓μ^=N1i=1∑Nxi
∂ J ∂ σ = ∂ ∂ σ ∑ i = 1 N { ( x i − μ ) 2 2 σ 2 + ln σ } = ( ∂ ∂ σ 1 2 σ 2 ) ( ∑ i = 1 N ( x i − μ ^ ) 2 ) + N σ = 1 σ ( N − 1 σ 2 ∑ i = 1 N ( x i − μ ^ ) 2 ) = 0 ⇓ σ ^ 2 = 1 N ∑ i = 1 N ( x i − μ ^ ) 2 \begin{aligned} \frac{\partial J }{ \partial \sigma } &= \frac{\partial }{ \partial \sigma } \sum^{N}_{i=1} \left \{ \frac{(x_i-\mu)^2}{2\sigma^2} + \ln \sigma \right\} \\ &= \left( \frac{\partial }{ \partial \sigma } \frac{1}{2\sigma^2} \right) \left( \sum^{N}_{i=1} (x_i - \hat{\mu})^2 \right) + \frac{N}{\sigma} \\ &= \frac{1}{\sigma} \left( N - \frac{1}{\sigma^2} \sum^{N}_{i=1} (x_i - \hat{\mu})^2 \right) = 0 \end{aligned} \\ \textcolor{green}{ \Downarrow } \\ \quad \\ \hat{\sigma} ^2 = \frac{1}{N} \sum^{N}_{i=1} (x_i - \hat{\mu} ) ^2 ∂σ∂J=∂σ∂i=1∑N{2σ2(xi−μ)2+lnσ}=(∂σ∂2σ21)(i=1∑N(xi−μ^)2)+σN=σ1(N−σ21i=1∑N(xi−μ^)2)=0⇓σ^2=N1i=1∑N(xi−μ^)2
多维高斯分布
前面的小球颜色,是通过HSV颜色空间的色相(H)来确定的,而RGB是一种更常用的色彩模式:

在3D图中画出所有像素的RGB值,就能得到如下的色彩分布:

现在考虑用RGB三通道模型对红球的色彩建模,看看这里如何运用高斯分布。
概率密度函数
多维高斯分布的表达式如下: p ( x ) = 1 ( 2 π ) D / 2 ∣ Σ ∣ 1 / 2 exp { − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) } p(\pmb{x}) = \frac{1}{(2\pi)^{D/2} |\Sigma|^{1/2}} \exp\left\{ -\frac{1}{2}(\pmb{x} - \pmb{\mu})^T \Sigma^{-1}(\pmb{x} - \pmb{\mu})\right\} p(xxx)=(2π)D/2∣Σ∣1/21exp{−21(xxx−μμμ)TΣ−1(xxx−μμμ)}其中:
D D D 表示维度数。
x \pmb{x} xxx 是变量,注意它是加粗的,是个向量。
μ \pmb{\mu} μμμ 是均值,注意它是加粗的,是个向量。
Σ \Sigma Σ 是协方差矩阵。(这个符号读做 Sigma)
和一维的情况相比,这里的变量 x \pmb{x} xxx 是一个向量,均值 μ \pmb{\mu} μμμ 也是对应的向量形式,协方差 Σ \Sigma Σ 现在是一个方阵。
在协方差矩阵中,有两个重要部分:对角项和非对角项。
下面是一个 2 2 2 维协方差矩阵的例子: Σ = [ σ x 1 2 σ x 1 σ x 2 σ x 2 σ x 1 σ x 2 2 ] \Sigma = \begin{bmatrix} \sigma^2_{x_1} & \sigma_{x_1} \sigma_{x_2} \\[0.5em] \sigma_{x_2} \sigma_{x_1} & \sigma^2_{x_2} \end{bmatrix} Σ=[σx12σx2σx1σx1σx2σx22]
对角项是两个变量 x 1 x_1 x1 和 x 2 x_2 x2 各自的方差;非对角项表示两个变量的相关性,即一个变量和另一个变量的相关程度。分母中 Σ \Sigma Σ 两边的竖线代表 Σ \Sigma Σ 矩阵的行列式。
下面是一个蓝色小球的例子:

这是对于处理3维变量RGB,变量向量包含我们的样本像素,即每个像素的红色,绿色,蓝色的值。
均值 μ \pmb{\mu} μμμ 是一个 3 × 1 3\times 1 3×1 的向量,协方差矩阵 Σ \Sigma Σ 是 3 × 3 3\times 3 3×3 的矩阵;
p ( x ) p(\pmb{x}) p(xxx) 是这个像素由小球产生的概率:在假设已知小球RGB模型的均值和方差的条件下,该样本像素从小球中抽出的概率。
下面是一个二维情况的例子:
p ( x ) = 1 2 π exp { − x 2 + y 2 2 } p(x) = \frac{1}{2\pi} \exp\left\{- \frac{x^2+y^2}{2} \right\} p(x)=2π1exp{−2x2+y2}其中: D = 2 D = 2 D=2 , x = [ x y ] T \pmb{x} = \begin{bmatrix} x &y\end{bmatrix}^T xxx=[xy]T, μ = [ 0 0 ] T \pmb{\mu} = \begin{bmatrix} 0 &0\end{bmatrix}^T μμμ=[00]T, Σ = [ 1 0 0 1 ] \Sigma = \begin{bmatrix} 1 &0 \\ 0& 1\end{bmatrix} Σ=[1001]
这是在给定参数下,简化的概率密度函数。它的图看起来像这样:

从图上看, 0 0 0 均值的二维高斯分布,像个只有一个峰的小山。如果你从中间切开这个曲面,它正是一个 1 1 1 维的高斯分布。有时在 2 2 2 维空间而非 3 3 3 维空间画出分布更有利于理解。等高线上的所有 x x x 具有相同的概率值,由于例子的协方差矩阵是个单位阵,等高线都是圆形,最中心的点表示了山峰,越外围的圆环代表概率越低。
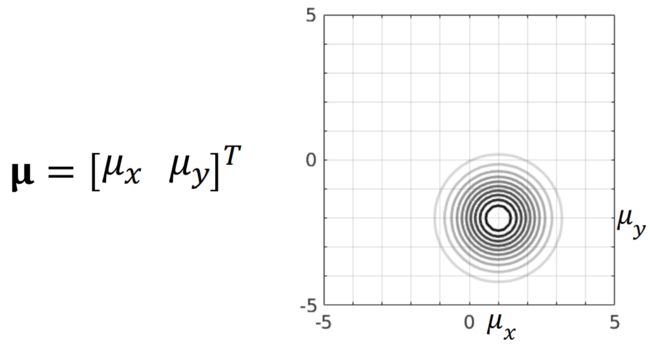
当只有均值发生变化时,分布会发生平移:
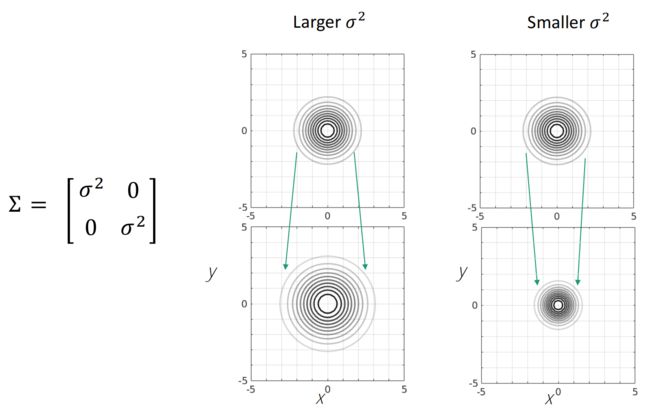
当方差变大时,分布变胖,山峰的值变小;当方差变小,山峰的 p ( x ) p(x) p(x) 变大,同时分布变瘦:
但是多变量高斯分布的协方差矩阵有一些特性,在 1 1 1 维高斯分布中是没有的。
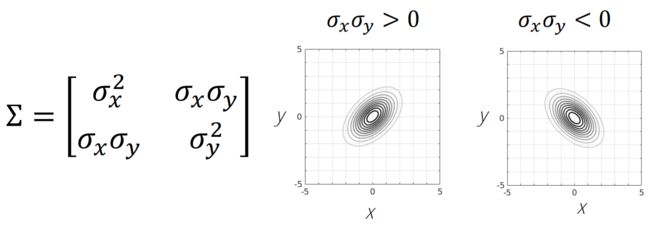
正如上面提到, Σ \Sigma Σ 协方差矩阵的非对角元素包含相关项。
如果 Σ \Sigma Σ 包含非零的对角元,则高斯分布的形状会被歪斜,这个现象在单变量情形下是不会发生的:
关于 Σ \Sigma Σ 还有一些性质。
首先,协方差矩阵必须是对称正定的,这意味着 Σ \Sigma Σ 的元素是关于对角线对称的,而且矩阵的特征值必须都是正的。
第二,就算 Σ \Sigma Σ 具有非零的相关项,我们也能找到一种坐标变换,让分布的形状变成对称的。可以使用特征值分解算法将协方差矩阵分解,进而得到这些变换。( Σ \Sigma Σ 可以被分解为 UDU T \text{UDU}^T UDUT 的形式,其中 D \text{D} D 是一个对角阵)
极大似然估计
前面已经介绍过一维高斯分布的情况,多维的情况也是一样,下面直接给出表达式: μ ^ , Σ ^ = arg max μ , Σ p ( { x i } ∣ μ , Σ ) \hat{\boldsymbol{\mu}},\hat{\Sigma} = \arg \max_{\boldsymbol{\mu},\Sigma}p(\{\textbf{\textit{x}}_i\} |\boldsymbol{\mu},\Sigma ) μ^,Σ^=argμ,Σmaxp({xi}∣μ,Σ)
再回顾一下似然的定义,似然是一个给定的包含未知参数的模型,产生这个观测数据的概率。
这里的模型是多维高斯分布模型,参数是均值向量 μ \boldsymbol{\mu} μ 和协方差矩阵 Σ \Sigma Σ。
我们感兴趣的是获得均值和协方差矩阵,来使得这个似然在给定的观测数据集上最大,这是我们目标的数学解释。
似然函数是所有数据概率的联合,通常是难以处理的。当我们假设各观测是独立的,总概率函数可以被写成每个独立似然函数的乘积,在这个假设条件下,求解问题变成这样: μ ^ , Σ ^ = arg max μ , Σ ∏ i = 1 N p ( { x i } ∣ μ , Σ ) \hat{\boldsymbol{\mu}},\hat{\Sigma} = \arg \max_{\boldsymbol{\mu},\Sigma} \prod^N_{i=1} p(\{\textbf{\textit{x}}_i\} |\boldsymbol{\mu},\Sigma ) μ^,Σ^=argμ,Σmaxi=1∏Np({xi}∣μ,Σ)
然后取对数,变成求和的问题: μ ^ , Σ ^ = arg max μ , Σ ∑ i = 1 N ln p ( x i ∣ μ , Σ ) \hat{\boldsymbol{\mu}},\hat{\Sigma} = \arg \max_{\boldsymbol{\mu},\Sigma} \sum^N_{i=1} \ln p(\textbf{\textit{x}}_i |\boldsymbol{\mu},\Sigma ) μ^,Σ^=argμ,Σmaxi=1∑Nlnp(xi∣μ,Σ)
再把概率密度函数代进去: μ ^ , Σ ^ = arg max μ , Σ ∑ i = 1 N { − 1 2 ( x i − μ ) T Σ − 1 ( x i − μ ) − 1 2 ln ∣ Σ ∣ − D 2 ln ( 2 π ) } \hat{\boldsymbol{\mu}},\hat{\Sigma} = \arg \max_{\boldsymbol{\mu},\Sigma} \sum^N_{i=1} \left\{ -\frac{1}{2}(\textbf{\textit{x}}_i - \boldsymbol{\mu} )^T \Sigma^{-1} (\textbf{\textit{x}}_i - \boldsymbol{\mu} ) - \frac{1}{2}\ln|\Sigma| -\frac{D}{2}\ln(2\pi) \right\} μ^,Σ^=argμ,Σmaxi=1∑N{−21(xi−μ)TΣ−1(xi−μ)−21ln∣Σ∣−2Dln(2π)}
常数项不影响求解,忽略它,然后再取负数,变成最小化问题: μ ^ , Σ ^ = arg min μ , Σ ∑ i = 1 N { 1 2 ( x i − μ ) T Σ − 1 ( x i − μ ) + 1 2 ln ∣ Σ ∣ } \hat{\boldsymbol{\mu}},\hat{\Sigma} = \arg \min_{\boldsymbol{\mu},\Sigma} \sum^N_{i=1} \left\{ \frac{1}{2}(\textbf{\textit{x}}_i - \boldsymbol{\mu} )^T \Sigma^{-1} (\textbf{\textit{x}}_i - \boldsymbol{\mu} ) + \frac{1}{2}\ln|\Sigma| \right\} μ^,Σ^=argμ,Σmini=1∑N{21(xi−μ)TΣ−1(xi−μ)+21ln∣Σ∣}
最后解得最小化代价函数 J J J 的最优解,这就得到了对均值和协方差矩阵的极大似然估计: J ( μ , Σ ) = ∑ i = 1 N { 1 2 ( x i − μ ) T Σ − 1 ( x i − μ ) + 1 2 ln ∣ Σ ∣ } J( \boldsymbol{\mu} ,\Sigma) = \sum^N_{i=1} \left\{ \frac{1}{2}(\textbf{\textit{x}}_i - \boldsymbol{\mu} )^T \Sigma^{-1} (\textbf{\textit{x}}_i - \boldsymbol{\mu} ) + \frac{1}{2}\ln|\Sigma| \right\} J(μ,Σ)=i=1∑N{21(xi−μ)TΣ−1(xi−μ)+21ln∣Σ∣} ∂ J ∂ μ = 0 ⟶ μ ^ \frac{\partial J }{ \partial \boldsymbol{\mu} } = 0 \quad \textcolor{green}{ \longrightarrow} \quad \hat{\boldsymbol{\mu}} ∂μ∂J=0⟶μ^ ∂ J ( μ ^ , Σ ) ∂ Σ = 0 ⟶ Σ ^ \frac{\partial J (\hat{\boldsymbol{\mu}},\Sigma)}{ \partial \Sigma} = 0 \quad \textcolor{green}{ \longrightarrow} \quad \hat{\Sigma} ∂Σ∂J(μ^,Σ)=0⟶Σ^
最后得到求解公式是: μ ^ = 1 N ∑ i = 1 N x i Σ ^ = 1 N ∑ i = 1 N ( x i − μ ^ ) ( x i − μ ^ ) T \begin{aligned} \hat{\boldsymbol{\mu}} &= \frac{1}{N} \sum^{N}_{i=1} \textbf{\textit{x}}_i \\ \hat{\Sigma} &= \frac{1}{N} \sum^{N}_{i=1} ( \textbf{\textit{x}}_i - \hat{\boldsymbol{\mu}} ) ( \textbf{\textit{x}}_i - \hat{\boldsymbol{\mu}} ) ^T \end{aligned} μ^Σ^=N1i=1∑Nxi=N1i=1∑N(xi−μ^)(xi−μ^)T
我们得到的最终解是向量形式的样本均值,和样本的协方差矩阵。
回到小球颜色的例子,图中展现了小球颜色在蓝色和红色两个维度上的分布。
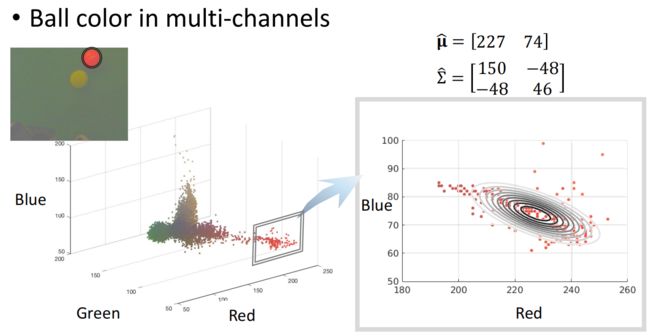
使用观测数据和我们获得的求解方程,我们可以计算参数的极大似然估计。
从图中的等高线上可以看出,在我们的模型中红色和蓝色通道是负相关的。
目前为止我们的例子是完美对称且只有一个峰,然而,一些其它奇怪的分布是可能存在的。
后面会讲如何利用多维高斯分布,去创建一个混合模型,用它可以表示各种不同的分布。
推导
这个多维高斯分布的求解(偏导)是这样来的:
μ \boldsymbol{\mu} μ 的估计:
∂ J ∂ μ = ∂ ∂ μ ∑ i = 1 N { 1 2 ( x i − μ ) T Σ − 1 ( x i − μ ) + 1 2 ln ∣ Σ ∣ } (2) \frac{\partial J}{\partial \boldsymbol{\mu}} = \frac{\partial}{\partial \boldsymbol{\mu}} \sum^N_{i=1} \left\{ \frac{1}{2}(\textbf{\textit{x}}_i - \boldsymbol{\mu} )^T \Sigma^{-1} (\textbf{\textit{x}}_i - \boldsymbol{\mu} ) + \frac{1}{2}\ln|\Sigma| \right\}\tag{2} ∂μ∂J=∂μ∂i=1∑N{21(xi−μ)TΣ−1(xi−μ)+21ln∣Σ∣}(2)
首先: x T Σ − 1 μ = [ x 1 x 2 ⋯ x n ] Σ − 1 [ μ 1 μ 2 ⋮ μ n ] = [ μ 1 μ 2 ⋯ μ n ] Σ − 1 [ x 1 x 2 ⋮ x n ] = μ T Σ − 1 x \textbf{\textit{x}}^T \Sigma^{-1} \boldsymbol{\mu} = \begin{bmatrix} x_1 & x_2 & \cdots & x_n \end{bmatrix} \Sigma^{-1} \begin{bmatrix} \mu_1 \\ \mu_2 \\ \vdots \\ \mu_n \end{bmatrix} = \begin{bmatrix} \mu_1 & \mu_2 & \cdots & \mu_n \end{bmatrix} \Sigma^{-1} \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{bmatrix} = \boldsymbol{\mu}^T \Sigma^{-1} \textbf{\textit{x}} xTΣ−1μ=[x1x2⋯xn]Σ−1⎣⎢⎢⎢⎡μ1μ2⋮μn⎦⎥⎥⎥⎤=[μ1μ2⋯μn]Σ−1⎣⎢⎢⎢⎡x1x2⋮xn⎦⎥⎥⎥⎤=μTΣ−1x
然后: ( x − μ ) T Σ − 1 ( x − μ ) = ( x T − μ T ) Σ − 1 ( x − μ ) = ( x T − μ T ) Σ − 1 x − ( x T − μ T ) Σ − 1 μ = x T Σ − 1 x − μ T Σ − 1 x − x T Σ − 1 μ + μ T Σ − 1 μ = x T Σ − 1 x − 2 μ T Σ − 1 x + μ T Σ − 1 μ \begin{aligned} (\textbf{\textit{x}} - \boldsymbol{\mu} )^T \Sigma^{-1} (\textbf{\textit{x}} - \boldsymbol{\mu} ) &= (\textbf{\textit{x}}^T - \boldsymbol{\mu}^T ) \Sigma^{-1} (\textbf{\textit{x}} - \boldsymbol{\mu} ) \\[0.5em] &= (\textbf{\textit{x}}^T - \boldsymbol{\mu}^T ) \Sigma^{-1} \textbf{\textit{x}} - ( \textbf{\textit{x}}^T - \boldsymbol{\mu}^T ) \Sigma^{-1} \boldsymbol{\mu} \\[0.5em] &= \textbf{\textit{x}}^T \Sigma^{-1} \textbf{\textit{x}} - \boldsymbol{\mu}^T \Sigma^{-1} \textbf{\textit{x}} - \textbf{\textit{x}}^T \Sigma^{-1} \boldsymbol{\mu} + \boldsymbol{\mu}^T \Sigma^{-1} \boldsymbol{\mu} \\[0.5em] &= \textbf{\textit{x}}^T \Sigma^{-1} \textbf{\textit{x}} -2 \boldsymbol{\mu}^T \Sigma^{-1} \textbf{\textit{x}} + \boldsymbol{\mu}^T \Sigma^{-1} \boldsymbol{\mu} \\[0.5em] \end{aligned} (x−μ)TΣ−1(x−μ)=(xT−μT)Σ−1(x−μ)=(xT−μT)Σ−1x−(xT−μT)Σ−1μ=xTΣ−1x−μTΣ−1x−xTΣ−1μ+μTΣ−1μ=xTΣ−1x−2μTΣ−1x+μTΣ−1μ
由于是对 μ \boldsymbol{\mu} μ 求偏导,忽略掉常数和其它变量,因此公式 (2) 变为:
∂ J ∂ μ = ∂ ∂ μ ∑ i = 1 N { 1 2 μ T Σ − 1 μ − μ T Σ − 1 x i } (3) \frac{\partial J}{\partial \boldsymbol{\mu}} = \frac{\partial}{\partial \boldsymbol{\mu}} \sum^N_{i=1} \left\{ \frac{1}{2} \textcolor{blue}{\boldsymbol{\mu}^T \Sigma^{-1} \boldsymbol{\mu} } - \textcolor{red}{\boldsymbol{\mu}^T \Sigma^{-1} \textbf{\textit{x}}_i } \right\}\tag{3} ∂μ∂J=∂μ∂i=1∑N{21μTΣ−1μ−μTΣ−1xi}(3)
公式 (3) 有两项关于指数的求导。
首先,对于 μ T Σ − 1 x \textcolor{red}{\boldsymbol{\mu}^T \Sigma^{-1} \textbf{\textit{x}}} μTΣ−1x,记 Σ − 1 x \Sigma^{-1} \textbf{\textit{x}} Σ−1x 为 A \textbf{\textit{A}} A,则 μ T Σ − 1 x = μ T A \boldsymbol{\mu}^T \Sigma^{-1} \textbf{\textit{x}} = \boldsymbol{\mu}^T \textbf{\textit{A}} μTΣ−1x=μTA。
由求导公式 d ( AX ) T d X = A T \dfrac{\text{d}(\textbf{\textit{A}} \textbf{\textit{X}} )^T}{\text{d}\textbf{\textit{X}}} = \textbf{\textit{A}}^T dXd(AX)T=AT 得:
∂ ( μ T Σ − 1 x ) ∂ μ = ∂ ( μ T A ) ∂ μ = ∂ ( A T μ ) T ∂ μ = A = Σ − 1 x (4) \frac{\partial (\textcolor{red}{\boldsymbol{\mu}^T \Sigma^{-1} \textbf{\textit{x}}})}{\partial \boldsymbol{\mu}} = \frac{\partial (\boldsymbol{\mu}^T \textbf{\textit{A}})}{\partial \boldsymbol{\mu}} = \frac{\partial (\textbf{\textit{A}}^T \boldsymbol{\mu})^T}{\partial \boldsymbol{\mu}} = \textbf{\textit{A}} = \Sigma^{-1} \textbf{\textit{x}}\tag{4} ∂μ∂(μTΣ−1x)=∂μ∂(μTA)=∂μ∂(ATμ)T=A=Σ−1x(4)
然后,对于 μ T Σ − 1 μ \textcolor{blue}{\boldsymbol{\mu}^T \Sigma^{-1} \boldsymbol{\mu} } μTΣ−1μ,根据求导公式 d ( X T AX ) d X = AX + A T X \dfrac{\text{d}(\textbf{\textit{X}} ^T \textbf{\textit{A}} \textbf{\textit{X}} )}{\text{d}\textbf{\textit{X}}} = \textbf{\textit{A}} \textbf{\textit{X}} + \textbf{\textit{A}}^T \textbf{\textit{X}} dXd(XTAX)=AX+ATX 得:
∂ ( μ T Σ − 1 μ ) ∂ μ = Σ − 1 μ + Σ − 1 T μ (5) \frac{\partial (\textcolor{blue}{\boldsymbol{\mu}^T \Sigma^{-1} \boldsymbol{\mu} })}{\partial \boldsymbol{\mu}} = \Sigma^{-1}\boldsymbol{\mu} + {\Sigma^{-1}}^T \boldsymbol{\mu}\tag{5} ∂μ∂(μTΣ−1μ)=Σ−1μ+Σ−1Tμ(5)
由于 Σ − 1 \Sigma^{-1} Σ−1 是一个对称矩阵,所以 Σ − 1 = Σ − 1 T \Sigma^{-1} = {\Sigma^{-1}}^T Σ−1=Σ−1T,把 (4) 和 (5) 代入 (3) 得:
∂ J ∂ μ = Σ − 1 ∑ i = 1 N { μ − x i } \frac{\partial J}{\partial \boldsymbol{\mu}} = \Sigma^{-1} \sum^N_{i=1} \left\{ \boldsymbol{\mu} - \textbf{\textit{x}}_i \right\} ∂μ∂J=Σ−1i=1∑N{μ−xi}
∂ J ∂ μ = 0 ⟶ μ ^ = 1 N ∑ i = 1 N x i \frac{\partial J }{ \partial \boldsymbol{\mu} } = 0 \quad \textcolor{green}{ \longrightarrow} \quad \hat{\boldsymbol{\mu}} = \frac{1}{N} \sum^{N}_{i=1} \textbf{\textit{x}}_i ∂μ∂J=0⟶μ^=N1i=1∑Nxi
Σ \Sigma Σ 的估计:
有点麻烦,推理可以看这里:https://www.cnblogs.com/bigmonkey/p/11379144.html
用的时候直接记答案好了