最近要学习RNN相关知识,根据知乎的建议,首先阅读了这篇经典论文。边读边想遍记录。
一、3个问题
1. 为什么一定要是序列模型?
像SVM、LR、前向反馈网络是建立在 “独立”假设的基础上,更多模型则是人为地去构造前后顺序。但即使这样,上述模型仍然不能解决长时间序列的依赖问题。比如语音或文本识别中的长句子场景。
所以,这种有时间或顺序性的模型,是不能用几个分类器或学习模型串联起来进行等价的。
对于原文中有如下一段内容,
Further, many models implicitly capture time by concatenating each input with some number of its immediate predecessors and successors, presenting the machine learning model with a sliding window of context about each point of interest.
我的理解是一些模型对输入数据的处理是在人为的构造序列性,或者保证输入在一定范围是有时间顺序的。比如现在有一个序列[1,2,3,4,5,6,7],一般的做法是每个 step 的输入一个值:[1], [2], [3], …, [7]然后这里不仅把当前时刻的值输入,还把它前面时刻和后面时刻的值一块输入(假设前后用0 padding):
[0, 1, 2], [1, 2, 3], [2,3,4], …[6, 7, 0]。
PS:这种情况下,训练参数会增加,也许会带来模型性能上的提升。
2. 为什么不是马尔可夫模型?
隐马模型也可以处理时间序列的问题,它需要对状态转移概率和状态输出概率分别建模。但是链中每一个状态只能依赖前一个状态。
传统HMM的局限性:
(1)序列的状态需要是离散有限的,而且状态越多,模型复杂度越高。
虽然传统RNN也是依赖前一个单元的输出,但是任何一个时间下的隐状态却可以包含来自几乎任意长的上下文窗口的信息。这可能是因为N个隐层单元会输出 2N 个的状态数(虽然隐藏层的单元越多,模型学习能力越强,但是模型也因此变得复杂)。
3. RNN会过拟合吗?
具有非线性激活单元的有限大小的RNN几乎可以进行任何计算。但是不会过拟合。原因如下:
(1)RNN的每一层都是可以进行求导的,所以能对参数数量(梯度计算)有很好的控制;
(2)可以通过权重衰减、dropout等方法对模型进行限制。
二、背景知识
2.1序列
RNN的输入(输出)都是一个序列。输入序列可以表示为 (x(1),x(2),...,x(T)) ,其中 x(t) 是一个实向量。输出序列则可用 (y(1),y(2),...,y(T)) 来表示。训练集就是由这样的输入输出对组成的。时间序列可解释为 x(t) 经过 t 时间到达y(t),用 ŷ (t)
2.2神经网络
神经网络中的神经元又被称为“节点“或者“单元“,每一个神经元 j 其实是一个激活函数lj(·)(有时又称为链接函数)。这里用 lj 是为了和网络中隐单元的值 hj 区分开。从单元 l′j 出发,连接到 lj 单元的边的权重记为 wjj′ ,每一个节点的权重值由所有连接到这个单元边的权重加和得到,这时记此单元为 aj 。激活函数可以选择sigmoid、tanh、ReLU函数。输出层的激活函数可根据输出类型选择,如果是多分类就选择softmax
2.3 前向网络和反向传播
前向网络整个网络是一条链,每一层的结果都是反馈给下一层。这类网络常用于分类或回归等监督学习的问题,当学习值和真实值相差很小时,网络停止训练。
反向传播算法是训练神经网络的典型算法,通过链式法则对每一层参数进行求导来计算损失函数,参数由此得以求得最优。由于损失面是非凸的没有办法通过反向传播得到一个全局最优,因此衍生了很多替代求解方法,如SGD、AdaGrad、RMSprop。
3. 循环神经网络
我理解的RNN
循环神经网络每一层不仅输出给下一层,同时还输出一个隐藏状态,给当前层在处理下一个样本时使用。
首先回忆单隐层的前馈神经网络的定义,假设隐层的激活函数是 ϕ ,那么这个隐层的输出就是 H=ϕ(XHwh+bn) 。最终的输出是 Ŷ =softmax(HWhy)+by .
将上面网络改成循环神经网络,我们首先对输入输出加上时间戳 t 。假设Xt是序列中的第 t 个输入,对应的隐层输出和最终输出是Ht和 Ŷ t 。循环神经网络只需要在计算隐层的输出的时候加上跟前一时间输入的加权和,为此我们引入一个新的可学习的权重 Whh :
输出和前面一样:
隐层输出(又叫隐藏状态)可以认为是这个网络的记忆。它存储前面时间里面的信息。输出是完全只基于这个状态。最开始的状态, H−1 ,通常会被初始为0.
论文中相关部分
RNN可以视为是前向网络按时间展开的模型。“循环边“可以连接相邻时间节点,也可以形成环,连接自身。时间 t 下,循环边会接受来自当前时间点下的输入x(t)和上一时间的隐层输出 h(t−1) .
其中, Whx 是输入到隐层之间的权重, Whh 是每一个隐层单元在相邻时间点状态下的权重。 by 和 bh 节点的权重。
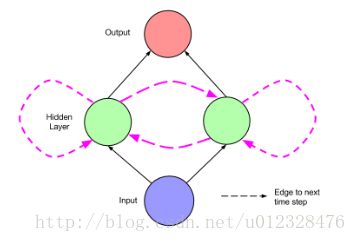
将这幅图按照时间序列展开可以得到下图
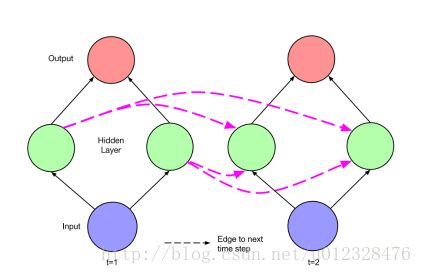
与其说这幅图是一个环形结构图,不如说是一个只有一层隐藏层的深度网络,同一个时间点下网络的权重相同。可以通过反向传播算法(BPTT)对RNN进行训练。
3.1 早期循环网络的设计
对RNN的基础研究始于1980年,直到1982年 Hopfield引入了一些列的RNN进行模式识别。这些网络节点之间的权重和连接函数的值都是以0为边界进行设置的,网络通过更新节点权重来识别不同的模式。这些网络更适用于学习固定的模式,比如恢复某个有缺失的模式,这些网络也就是玻尔兹曼机和自编码器的前身。
1860年Jordan开始研究如何在序列问题上应用监督学习。这种网络模型结果如下图所示。

这种网络也可以视为是只有一层隐藏层的前向网络,并且隐层单元有固定的连接对象,节点的输出也会输入给固定的接受单元。如果输出值被激活,被指定接受单元会将网络前一时间点的输出值保留。
3.2循环网络的训练
- 困难1:
如何解决多个时间步下,网络在反向传播中遇到的梯度弥散和梯度爆炸的问题(如果每层梯度大于一,那么多层乘下来的梯度就是一个很大的数;如果小于一,那么最后就是一个接近零的数)。梯度弥散更容易出现在激活函数是sigmoid时,而ReLU更容易引起梯度爆炸。 - 解决:
为防止在训练过程中出现梯度弥散或爆炸的问题,一般会对进行正则化处理,强行让权重的值处于比较正常的大小。常见的算法是TBPTT算法。 由于模型训练时,时间序列越长越容易出错。TBPTT算法则是对序列进行截断,牺牲了一部分对长序列的学习能力来解决训练过程中的梯度问题。LSTM就是将单元自己到自己的连接强行设置称了一个固定的常数值
|yjj(t)′wjj|=1.0
来解决梯度弥散的。 - 困难2:如何优化目标函数。绝大多数深度学习中的目标函数都很复杂。因此,很多优化问题并不存在显示解(解析解),而需要使用基于数值方法的优化算法找到近似解。这类优化算法一般通过不断迭代更新解的数值来找到近似解。优化问题中的两个挑战:局部最小值和鞍点。
局部最小:绝大多数深度学习的目标函数有若干局部最优值。当一个优化问题的数值解在局部最优解附近时,由于梯度接近或变成零,最终得到的数值解可能只令目标函数局部最小化而非全局最小化。
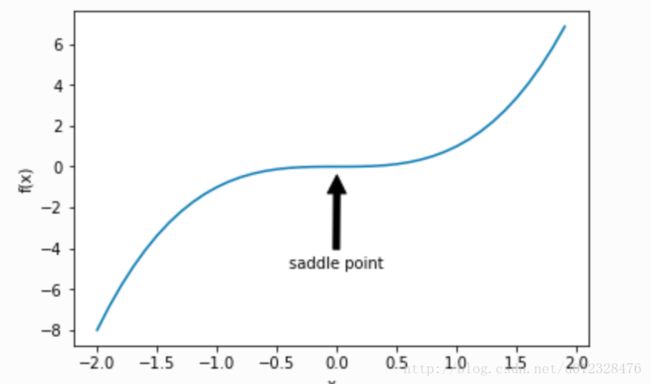
鞍点(saddle point):梯度接近或变成零除了可能是由于当前解在局部最优解附近所造成的,还有可能是当前解在鞍点附近。事实上,由于大多数深度学习模型参数都是高维的,目标函数的鞍点往往比局部最小值更常见。
下图展示了定义在一维空间的函数f(x)=x3f(x)=x3的鞍点。
下图展示了定义在二维空间的函数f(x,y)=x2−y2f(x,y)=x2−y2的鞍点。该函数看起来像一个马鞍,鞍点恰好是可以坐的区域的中心。

- 解决:
在大型神经网络的误差曲面上存在许多临界点,鞍点与真实局部最小值的比值随网络规模呈指数增长,所以可以从算法设计入手,来避免这些鞍点.
4. 改进后的RNN模型
主要包括LSTM和BRNN
### 4.1 LSTM
LSTM主要为了解决梯度弥散问题,所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。LSTM 同样是这样的结构,但是重复的模块有四个部分。为了避免梯度弥散或者爆炸的问题,LSTM的自链循环边的权重被固定为常数1。使用下表c区分记忆单元和普通节点。
- 输入节点
记为 gc ,包括当前输入和上一时间的隐层状态。二者加权求和后,在输入一个激活函数中去。 输入门
向输入节点一样,一个门也像是一个激活单元,处理当前输入和上一时间的隐层状态。之所以称为“门“,是因为这个节点的输出值需要经过一次筛选才能送入下一个节点。选择的方式输入门的值 ic 就是和来自另一个值(输入节点的值)相乘,即ft=σ(Wf·[ht−1,xt]+bf). 结果为1才能通过,0不能。内部态
每一个记忆单元的核心都是一个线性单元 sc , 自连接的循环边权重是固定的,避免训练过程中的梯度问题。它的更新方式为s(t)=g(t)⊙i(t)+f(t)⊙s(t−1)
其中 ⊙ 为点乘运算遗忘门
fc 用来帮助网络对内部态信息进行刷新,决定哪些信息要被保留输出门
记忆单元最终输出的值 oc 乘以 scps 看到这里真的是原地爆炸啊!我一直以为每一段都是在对第一个词(比如输入节点)做解释的,但是并不是啊!我还是自己搬运网络教程吧
遗忘门,通过激活函数完成信息选择

输入门,通过激活函数完成信息选择(哪些值要被更新)。
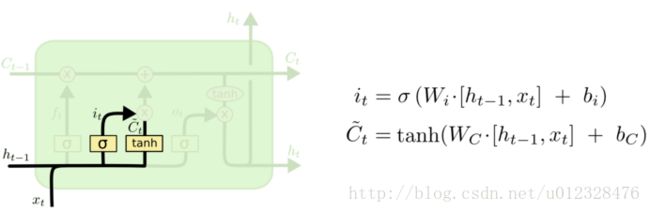
然后,一个 tanh 层创建一个新的候选值向量, C̃ t ,会被加入到状态中。中间态,通过保留下的状态完成信息更新( Ct−1 更新为 Ct )
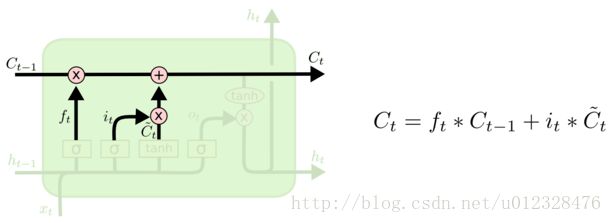
输出门 先通过sigmoid选择哪部分输出,再通过tanh完成输出。
