机器学习100天-1-数据预处理
目录
1 导库
NumPy:数学计算函数
Pandas:导入和管理数据集
2 导入数据集
.csv:文本形式保存表格数据,一行一条数据
pd.read_csv:读取本地csv作为一个数据帧
数据帧制作自变量 因变量的矩阵和向量
3 处理丢失数据
丢失的数据会降低模型性能
sklearn.preprocessing.Imputer:整列平均值(中间值)代替丢失
4 解析分类数据
分类数据:不是数字的变量(YN)
sklearn.preprovesing库中的LabelEncoder
5 拆分数据集
数据集28分 训练集 测试集
sklearn.crossvalidation库中的rain_test_split()
6 特征缩放
欧氏距离:大部分模型用来表示距离
幅度,单位 ,范围上变化很大
距离计算中权重: 高幅度 特征 > 低幅度 特征
特征标准化 或 Z值归一化 解决
sklearn.preprocessing 中的 StandardScalar类
具体实现
第1步:导入库
import numpy as np
import pandas as pd
第2步:导入数据集
dataset = pd.read_csv('Data.csv')//读取csv文件
X = dataset.iloc[ : , :-1].values//.iloc[行,列]
Y = dataset.iloc[ : , 3].values // : 全部行 or 列;[a]第a行 or 列
// [a,b,c]第 a,b,c 行 or 列
第3步:处理丢失数据
from sklearn.preprocessing import Imputer
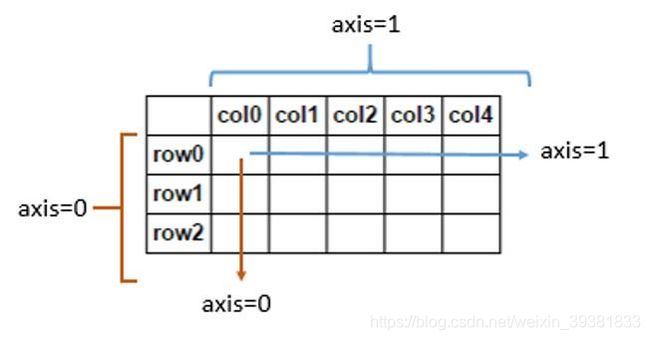
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0)
imputer = imputer.fit(X[ : , 1:3])
X[ : , 1:3] = imputer.transform(X[ : , 1:3])
第4步:解析分类数据
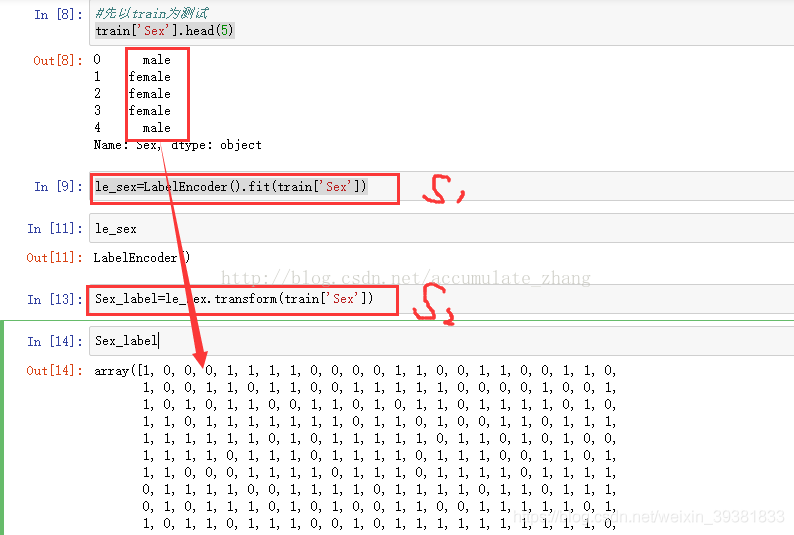
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])
创建虚拟变量
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
第5步:拆分数据集为训练集合和测试集合
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)
第6步:特征量化
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
1d.py
import numpy as np
import pandas as pd
#2 导入数据集
dataset = pd.read_csv('../datasets/Data.csv')
#iloc[行.列]
X = dataset.iloc[ : , :-1].values
Y = dataset.iloc[ : , 3].values #全部的行或者列
#[a]第a行or列 [a,b,c]第a,b,c行 or 列
#3 处理丢失数据
from sklearn.preprocessing import Imputer
imputer=Imputer(missing_values="NaN",strategy="mean",axis=0) #axis=0 列
imputer=imputer.fit(X[ : , 1:3])
X[ : , 1:3] = imputer.transform(X[ : , 1:3])
#4 解析分类数据
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : ,0])
#创建虚拟变量
onehotencoder = OneHotEncoder(categorical_features=[0])
X = onehotencoder.fit_transform(X).toarray()
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
#5 拆分数据集
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test = train_test_split( X , Y ,test_size= 0.2,random_state= 0 )
# 6 特征量化
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)