史上最全学习率调整策略lr_scheduler
学习率是深度学习训练中至关重要的参数,很多时候一个合适的学习率才能发挥出模型的较大潜力。所以学习率调整策略同样至关重要,这篇博客介绍一下Pytorch中常见的学习率调整方法。
import torch
import numpy as np
from torch.optim import SGD
from torch.optim import lr_scheduler
from torch.nn.parameter import Parameter
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, lr=0.1)
以上是一段通用代码,这里将基础学习率设置为0.1。接下来仅仅展示学习率调节器的代码,以及对应的学习率曲线。
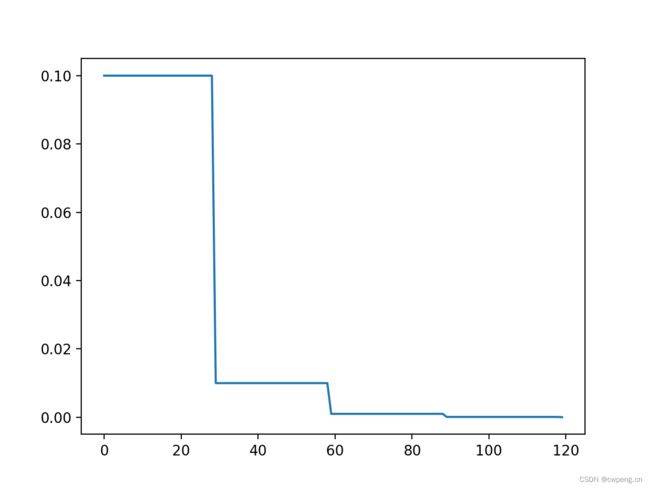
1. StepLR
这是最简单常用的学习率调整方法,每过step_size轮,将此前的学习率乘以gamma。
scheduler=lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
2. MultiStepLR
MultiStepLR同样也是一个非常常见的学习率调整策略,它会在每个milestone时,将此前学习率乘以gamma。
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[30,80], gamma=0.5)

3. ExponentialLR
ExponentialLR是指数型下降的学习率调节器,每一轮会将学习率乘以gamma,所以这里千万注意gamma不要设置的太小,不然几轮之后学习率就会降到0。
scheduler=lr_scheduler.ExponentialLR(optimizer, gamma=0.9)

4. LinearLR
LinearLR是线性学习率,给定起始factor和最终的factor,LinearLR会在中间阶段做线性插值,比如学习率为0.1,起始factor为1,最终的factor为0.1,那么第0次迭代,学习率将为0.1,最终轮学习率为0.01。下面设置的总轮数total_iters为80,所以超过80时,学习率恒为0.01。
scheduler=lr_scheduler.LinearLR(optimizer,start_factor=1,end_factor=0.1,total_iters=80)

5. CyclicLR
scheduler=lr_scheduler.CyclicLR(optimizer,base_lr=0.1,max_lr=0.2,step_size_up=30,step_size_down=10)
CyclicLR的参数要更多一些,它的曲线看起来就像是不断的上坡与下坡,base_lr为谷底的学习率,max_lr为顶峰的学习率,step_size_up是从谷底到顶峰需要的轮数,step_size_down时从顶峰到谷底的轮数。至于为啥这样设置,可以参见论文,简单来说最佳学习率会在base_lr和max_lr,CyclicLR不是一味衰减而是出现增大的过程是为了避免陷入鞍点。
scheduler=lr_scheduler.CyclicLR(optimizer,base_lr=0.1,max_lr=0.2,step_size_up=30,step_size_down=10)
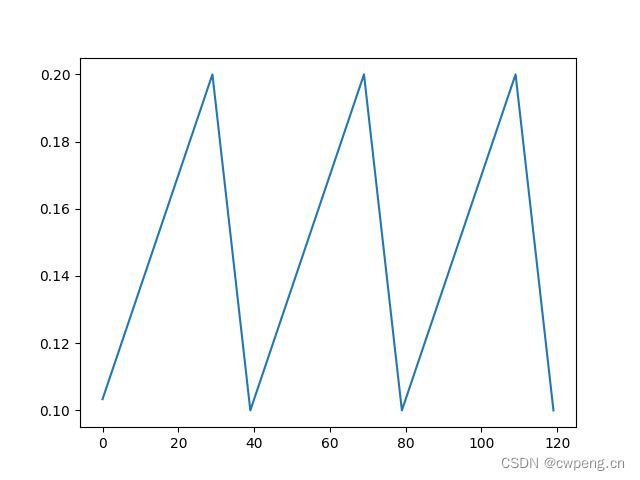
6. OneCycleLR
OneCycleLR顾名思义就像是CyclicLR的一周期版本,它也有多个参数,max_lr就是最大学习率,pct_start是学习率上升部分所占比例,一开始的学习率为max_lr/div_factor,最终的学习率为max_lr/final_div_factor,总的迭代次数为total_steps。
scheduler=lr_scheduler.OneCycleLR(optimizer,max_lr=0.1,pct_start=0.5,total_steps=120,div_factor=10,final_div_factor=10)

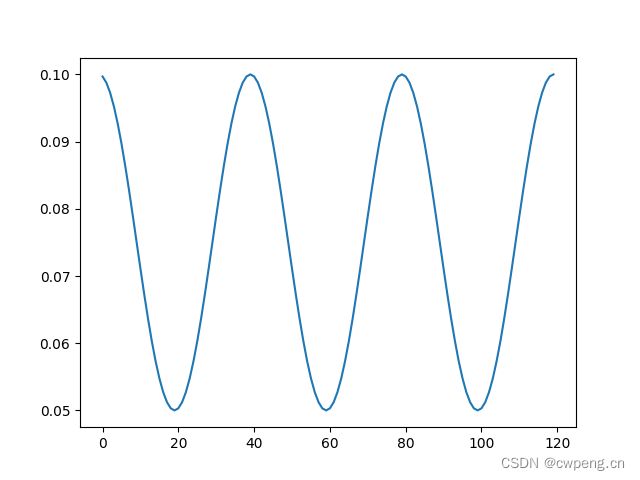
7. CosineAnnealingLR
CosineAnnealingLR是余弦退火学习率,T_max是周期的一半,最大学习率在optimizer中指定,最小学习率为eta_min。这里同样能够帮助逃离鞍点。值得注意的是最大学习率不宜太大,否则loss可能出现和学习率相似周期的上下剧烈波动。
scheduler=lr_scheduler.CosineAnnealingLR(optimizer,T_max=20,eta_min=0.05)
7. CosineAnnealingWarmRestarts
这里相对负责一些,公式如下,其中T_0是第一个周期,会从optimizer中的学习率下降至eta_min,之后的每个周期变成了前一周期乘以T_mult。
e t a t = η m i n + 1 2 ( η m a x − η m i n ) ( 1 + cos ( T c u r T i π ) ) eta_t = \eta_{min} + \frac{1}{2}(\eta_{max} - \eta_{min})\left(1 + \cos\left(\frac{T_{cur}}{T_{i}}\pi\right)\right) etat=ηmin+21(ηmax−ηmin)(1+cos(TiTcurπ))
scheduler=lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=20, T_mult=2, eta_min=0.01)

8. LambdaLR
LambdaLR其实没有固定的学习率曲线,名字中的lambda指的是可以将学习率自定义为一个有关epoch的lambda函数,比如下面我们定义了一个指数函数,实现了ExponentialLR的功能。
scheduler=lr_scheduler.LambdaLR(optimizer,lr_lambda=lambda epoch:0.9**epoch)

9.SequentialLR
SequentialLR可以将多个学习率调整策略按照顺序串联起来,在milestone时切换到下一个学习率调整策略。下面就是将一个指数衰减的学习率和线性衰减的学习率结合起来。
scheduler=lr_scheduler.SequentialLR(optimizer,schedulers=[lr_scheduler.ExponentialLR(optimizer, gamma=0.9),lr_scheduler.LinearLR(optimizer,start_factor=1,end_factor=0.1,total_iters=80)],milestones=[50])

10.ChainedScheduler
ChainedScheduler和SequentialLR类似,也是按照顺序调用多个串联起来的学习率调整策略,不同的是ChainedScheduler里面的学习率变化是连续的。
scheduler=lr_scheduler.ChainedScheduler([lr_scheduler.LinearLR(optimizer,start_factor=1,end_factor=0.5,total_iters=10),lr_scheduler.ExponentialLR(optimizer, gamma=0.95)])

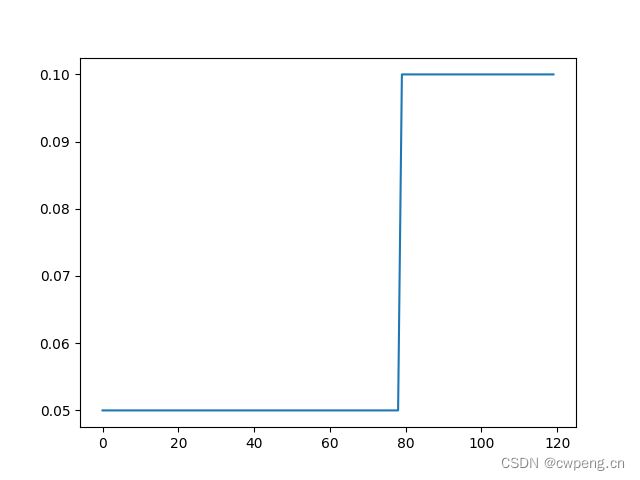
11.ConstantLR
ConstantLRConstantLR非常简单,在total_iters轮内将optimizer里面指定的学习率乘以factor,total_iters轮外恢复原学习率。
scheduler=lr_scheduler.ConstantLRConstantLR(optimizer,factor=0.5,total_iters=80)
12.ReduceLROnPlateau
ReduceLROnPlateau参数非常多,其功能是自适应调节学习率,它在step的时候会观察验证集上的loss或者准确率情况,loss当然是越低越好,准确率则是越高越好,所以使用loss作为step的参数时,mode为min,使用准确率作为参数时,mode为max。factor是每次学习率下降的比例,新的学习率等于老的学习率乘以factor。patience是能够容忍的次数,当patience次后,网络性能仍未提升,则会降低学习率。threshold是测量最佳值的阈值,一般只关注相对大的性能提升。min_lr是最小学习率,eps指最小的学习率变化,当新旧学习率差别小于eps时,维持学习率不变。
因为参数相对复杂,这里可以看一份完整的代码实操。
scheduler=lr_scheduler.ReduceLROnPlateau(optimizer,mode='min',factor=0.5,patience=5,threshold=1e-4,threshold_mode='abs',cooldown=0,min_lr=0.001,eps=1e-8)
scheduler.step(val_score)