【论文精读 02】Swin Transformer
Swin Transformer —— 使用移位窗口的层级Vision Transformer
ICCV 2021 最佳论文
资料参考:
- https://www.bilibili.com/video/BV1pL4y1v7jC/?spm_id_from=333.788&vd_source=fab4cd66aafcb3b54c4bc627c1dcaac1
- https://www.bilibili.com/video/BV13L4y1475U/?spm_id_from=333.788&vd_source=fab4cd66aafcb3b54c4bc627c1dcaac1
作者

摘要

将 Transformer 直接从 NLP 应用到 Vision 是有挑战的,挑战主要来自两个方面,一个是尺度上的问题(例如对于一张街景的图,里面有大大小小的行人和车,对于同样一个语义的行人或车,具有不同的尺寸,这种现象在NLP当中没有),第二个问题就 resolution 太大了,如果我们要以像素点作为基本单位,序列的长度就变得高不可攀,所有的方法都是为了减少序列的长度。
本文作者提出 hierarchical Transformer ,通过移动窗口进行计算,因为 Swin Transformer有了像卷积神经网络一样有分层的结构,有多尺度的特征,就能够更容易使用到下游任务当中。
作者不光是在 ImageNet-1K 上做了实验,而且达到了87.3top-1上的精度,而且在密集预测行为预测任务上、目标检测、物体分割上都取得了很好的成绩。

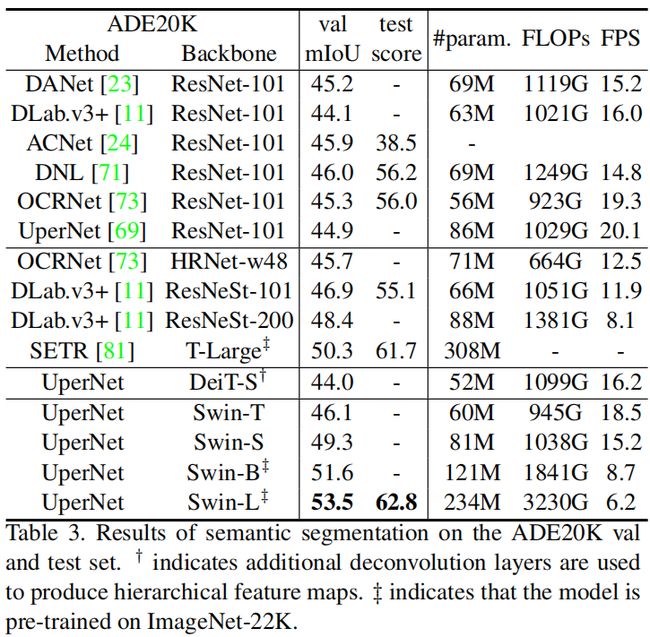
Swin Transformer 已经超越了之前的所有网络,在COCO数据集上在目标检测任务能刷到58.7的成绩,提升2.7AP值,在实例分割任务当中提升2.6AP值,在ADE20K数据集上语义分割任务当中能刷到53.5的成绩,提升3.2mIoU。基于Transformer在视觉领域非常有潜力,对于MLP架构,用 shifteed window 也能提升, https://github.com/microsoft/Swin-Transformer
5 结论
本文提出 Swin Transformer,计算复杂度是跟输入图像的大小呈线性增长。 Swin Transformer 在COCO目标检测和ADE20K语义分割方面取得了最先进的性能,明显超过了以往的最佳模型。我们希望Swin Transformer 在各种视觉问题上的强大性能将鼓励视觉和语言信号的统一建模。
基于 shifted window 的自注意作为 Swin Transformer 的一个关键元素,对视觉问题是有效的,并期待研究其在自然语言处理中的应用。
1 引言
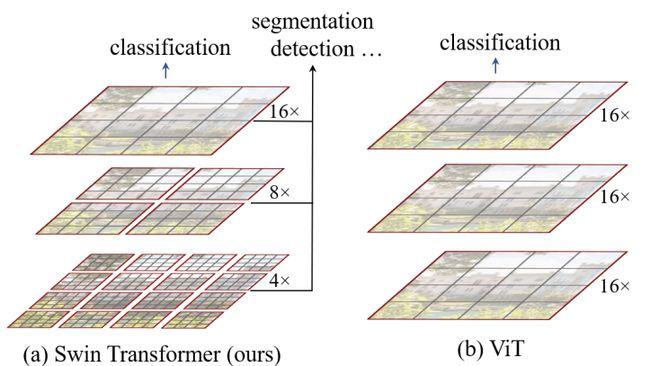
Swim Transformer 与 Vision Transformer 区别:
- Swim Transformer 能够像卷积神经网络当中构建出具有层次性的特征图,对于目标检测和分割任务有更大的优势。Vision Transformer中都是保持下采样的规律不变,所以没法像 Swim Transformer 构建出具有层次性的特征层。
- Swim Transformer 中以窗口的形式将特征图分开了,窗口与窗口之间不进行信息传递,能够降低运算量。在 Vision Transformer 中特征图是一个整体,并没有进行分割,全局建模,由于全局自注意的计算,对输入图像的大小具有平方倍的计算复杂度。
作者的研究动机是想证明 Transformer 可以作为一个通用的骨干网络,对于所有视觉的任务,不光是分类,在检测、分割、视频上都能取到很好的效果。
2 相关工作
卷积神经网络、自注意力/Transformer是如何用来帮助卷积神经网络、只用Transformer作为骨干网络。
3 模型体系结构
3.1 总体架构

图A:假设输入一张图的高度为 H ,宽度为 W ,RGB三通道的图片,首先会通过 Patch Partition 的模块,图片会变成 (H/4)*(W/4) * 48 的图片,再依次通过 Stage1、Stage2、Stage3、Stage4,Stage2 在 Stage1 的基础上下采样了两倍,Stage3 在 Stage2 的基础上下采样了两倍,Stage4 在 Stage3 的基础上下采样了两倍,在下采样的过程中 channel 会翻倍。
图A:需要注意的是 Stage1 的第一个是 Linear Embedding 层,对于 Stage2、Stage3、Stage4 都是 Patch Merging 的结构。
Patch Partition假设一个 4 * 4 大小的RGB图像,用一个 4 * 4 大小的窗口对图像进行分割,分割之后对每一个窗口,在 channel 方向进行展平(打成 patch ),下图中 16 * 3 对应 Figure 3 中的 48 。

Linear Embedding: 对 Patch Partition 出来的特征矩阵的 channel 进行调整,原来的深度是48,通过调整之后,深度变为 C 。(对于 S B L… 所采用不同,得到不同的C)需要注意 Linear Embedding 还进行了 LayerNorm 处理,
Patch Partition 和 Linear Embedding 是可以通过卷积层进行操作,也就是用卷积核大小为 4*4,采用48个卷积核,步距设成4,padding=0。
Swim Transformer Block对于每个 Stage 会堆叠每个 Swim Transformer Block n 次 (偶数次),可以从图 B 中看到,是使用了两个 Block,左边的这个Block其实是 Multi-Head Self Attention (Windows),下一个模块采用的是 SW 的自注意力模块(Shifted window Multi-Head Self Attention)。
Patch Merging实际是进行下采样,高和宽缩减为原来的一半,并且 channel 翻倍。下图为做法。以2*2作为窗口,在每个窗口当中相同位置的像素给取出来,能够得到四个特征矩阵,将这四个channel,在深度方向上进行 concat,在channel方向上进行 LayerNorm ,再通过全连接层(在每一个深度方向上进行映射),得到的就是 Patch Merging 输出的特征图。(可以类比池化操作)

在分类网络中对于 Stage4 后还会接上 LayerNorm,全局池化,以及一个全连接层进行输出。
MSA:对于 Multi-Head Self-Attention 模块,每一个像素都会求 Q、K、V,对于每一个像素求得的Q会与特征图当中的每一个像素的K进行匹配,后面再进行一系列计算。也就是对于特征图当中的每个pixel会与其他像素进行沟通。
W-MSA:首先会对特征图分成一个一个 Window(窗口),在下面的例子中分成 2*2 大小的4个窗口,在每个窗口的内部进行 Multi-Head Self-Attention 的计算过程,但 Window 和 Window 之间是没有任何通讯的。目的是为了减少计算量。缺点是窗口之间无法进行信息交互,导致感受野变小,无法看到全局的视野。

3.2 Shifted Window based Self-Attention
全局的自注意力的计算会导致平方倍的复杂度,尤其是密集型的任务或者是大尺寸的图片,全局算自注意力的计算复杂度非常贵。因此,我们在窗口做自注意力。
计算复杂度比较:

h代表feature map的高度,w代表feature map的宽度,C代表feature
map的深度,M代表每个窗口(Windows)的大小。 假设输入的高和宽都是112,h=w=112(有 h * w 个patch),C=128,M=7(7个窗口),将参数带入到公式当中,能节省大约401亿计算量。相当于用一个 h * w * c 的向量去乘以一个 c * c 的系数矩阵,得到 h * w * c ,所以每一个的计算复杂度是 h * w * c ^2 ,因为有三次操作,所以有 3 倍的 h * w * c ^2,q 与 k 的转置相乘,得到 hw * hw 的 A,计算复杂度是(hw)^2 * c ,自注意力矩阵与value的乘积 A 与 v,计算复杂度还是(hw)^2 * c ,因此就变成 2 * (hw)^2* c 。得到(1)的公式。

参考 :https://blog.csdn.net/qq_37541097/article/details/121119988?spm=1001.2014.3001.5501

Shifted Window Multi-Head Slef-Attention(SW-MSA):对窗口进行一定偏移,因为在 W-MSA 当中窗口之间是没法进行通讯的,因此引入 Shifted Window Multi-Head Slef-Attention
模块,目的是实现不同 Windows 之间的信息交互。
在 Layer 1 模块上使用 W-MSA ,在 Layer 1 + 1 上使用 SW-MSA 模块,
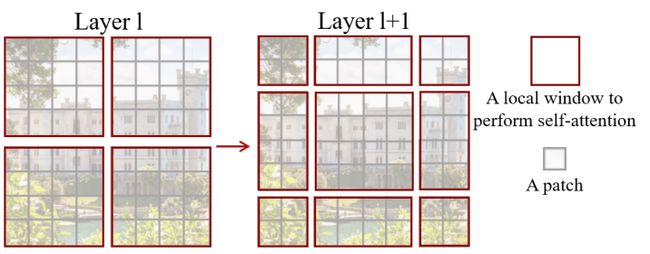

向右向下平移后:
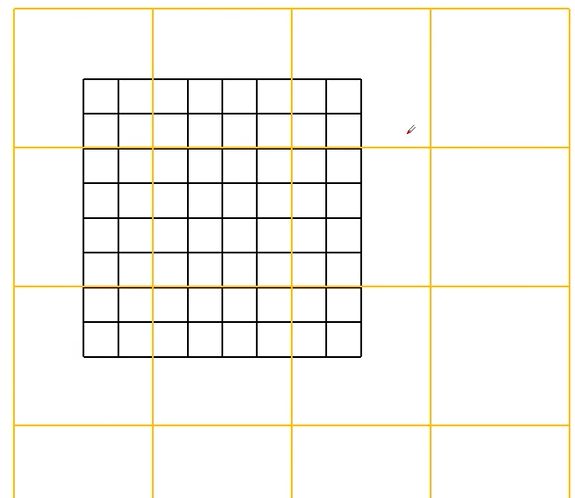
但解决了窗口之间的信息交互之后,又会出现计算量增加的问题(从4个窗口增加到9个窗口),下面是作者的解决方式:
首先是移动windows,移动之后再去划分成44的windows,将 5和3、7和1、8 6 2 0
分别分成4*4的窗口,然后再对这四个区域去做 MSA 计算。


但为了分别计算区域5和区域3,但为了不去计算区域5与区域3的信息,将其减去100,经过softmax之后,都变成0,因此得到的还是只有区域5的信息。计算完成之后再将分开后的feature map还原。

紫色区域进行SW-MSA操作,因为这几个紫色区域是不连续的。

高效的按批次计算方法:循环位移-> 掩码->还原

Relative position bias:B 代表的是相对位置偏置。



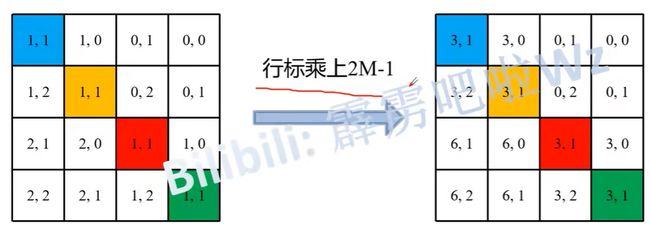


table 个数由来:(2M-1)* (2M-1)
3.3 体系结构变体
Swin-T和Swin-S的复杂性分别与ResNet-50(DeiT-S)和ResNet-101相似。区别是有两个超参数,一个是C,另一个是每个stage有多少个Transformer block,这里与残差网络很像,残差网络也是有残差网络块。

4 实验
4.1.在ImageNet-1K上的图像分类
- 在 ImageNet-1K 预训练。有128万张图片,1000个类的数据集。
- 在 ImageNet-22K 预训练和 ImageNet-1K 的微调。

在 ImageNet-1K 训练中,ViT-B/16 在 ImageNet top-1 的 acc 能达到77.9,使用 Vision Transformer 只有在非常大的数据集进行预训练才能有比较好的效果,没有用很好的数据增强,在 ImageNet-1K 上训练效果并不好,还不如 EffNet 的效果。在 DeiT-B 因为用了更好的数据增强和模型蒸馏,因此 DeiT-B 也能取得相当不错的结果,能到83.1。 对比 Swin-Transformer Base 同样输入尺寸是384*384,在 ImageNet top-1 的 acc 能达到 84.5,相对于 Vision Transformer 有非常大的提升。

在 ImageNet-21K (或ImageNet-22K)更大的数据集进行预训练之后,再在 ImageNet-1K 进行微调(或者说迁移学习),可以看到 ViT-B/16 在 ImageNet top-1 的 acc 能达到 84.0 。同样对于Swin-Transformer Base 同样输入尺寸下,在 ImageNet top-1 的 acc 能达到 86.4。因此比 Vision Transformer 效果要好很多。Swin-Transformer Large 在 ImageNet top-1 的
acc 能达到 87.3。
4.2 在COCO数据集上目标检测
在不同的算法框架下,Swin Transformer 比卷积神经网络好多少。


消融实验

1. 不去设置任何位置参数,在 ImageNet top-1 上能达到 80.1 的准确率。
2. 使用绝对位置编码,在ViT中使用的,在 ImageNet top-1 上能达到 80.5 的准确率,但在COCO数据集和ADE20k数据集当中可以看到性能降低了。可以看到效果并不好。
3. 使用相对位置偏置。在 ImageNet top-1 上能达到 81.3 的准确率,在COCO数据集和ADE20k数据集上都有明显的提升。
4. 使用了shifted windows 可以看到通过窗口与窗口之间的信息交互效果有明显提升。
Acknowledgement

Swin-T(Swin-Tiny):concat 4 * 4,96-d,LN 其实对应的就是 Patch Partition 和
Linear Embedding,Patch Partition 和 Linear Embedding 的功能其实与Patch
Merging是一样的,都是对特征图进行下采样,修改channel,再通过LN输出。这里的 4 * 4 对应的就是对高和宽下采样4倍,96
对应的就是通过 Linear Embedding 后channel变成96,LN,再堆叠两个 swin Transformer
block…
Patch Partition 和 Linear Embedding,Patch Partition 和 Linear Embedding
的功能其实与Patch Merging是一样的,都是对特征图进行下采样,修改channel,再通过LN输出。这里的 4 * 4
对应的就是对高和宽下采样4倍,96 对应的就是通过 Linear Embedding 后channel变成96,LN,再堆叠两个 swin
Transformer block…