Generative Adversarial Active Learning生成性对抗性主动学习文献笔记
文献1702.07956.pdf (arxiv.org)
生成性对抗性主动学习
介绍
这是第一个使用 GAN的主动学习工作,在它之后的GAN主动学习有不少,所以是首创性的工作,部分涉及分类的内容一笔带过。
背景1:主动学习
拿来了当初介绍主动学习的ppt,总得来说可以帮助我们用少量的标记获得不错的训练效果,其重点主要在于挑选送于专家人工标记样本的策略上。
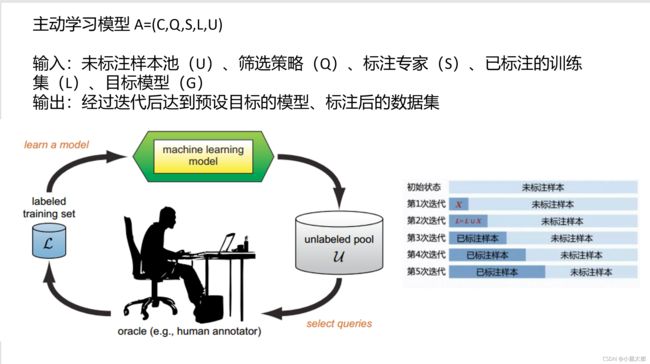

这是一个基于池主动学习与本文方法的一个对比,其中池指的是unlabeled,,其方法就是从池里面挑选一部分样本交给专家标记。本文则是由模型选择认为对自己有用需要注释的特例/生成新的标记特例。
本文是另一种主动学习方法:查询合成的方法(三种方法:查询合成,基于池和基于流)。
查询合成是模型选择认为对自己有用需要注释的特例/生成新的标记特例 ≈举一反三
但是缺点在于生成的特例可能无法识别,
本文的方法改进了之后这个缺点也明显改善了:
背景2:GAN
gan稍微了解了一下,主要是用对抗方法来生成数据的一种模型,类似于我们的对抗游戏,双方通过对抗能力上涨的一个机制,核心思想源于博弈论的纳什均衡,主要由生成器和判别器组成。
其中生成器捕捉数据潜在分布,生成数据样本(就是假样本),判别器是二分类器,判断输入的数据是真实数据还是生成器生成的假数据。而学习过程就是寻找二者之间的纳什均衡,一个比较理想的状态就是判别器判别不出来是真数据还是假数据。
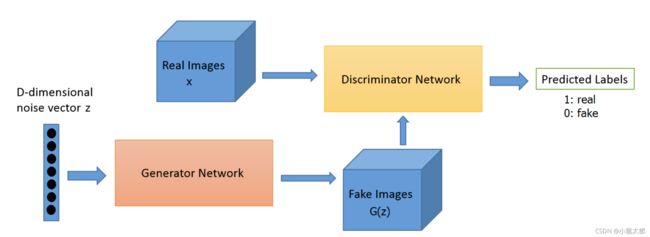
公式:
其中pdata是真实数据的基本分布, z是随机变量。 d和 G各有一组参数 θ1和 θ2.通过求解这个
博弈,得到了一个发生器 G。 在理想情况下,给定随机输入 z,我们有 G(z)∞pdata。
原始gan损失函数公式: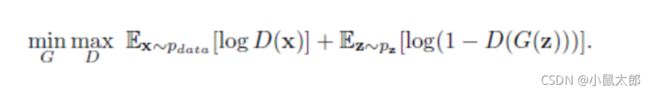
x是随机变量,D是对输入图像的一个判别,只有两种输出,1就是真样本,0为假样本(生成器生成的样本), GZ是生成的假样本。maxD是针对训练判别器D的,第一项E因为输入采样自真实数据,所以我们期望D(x)趋近于1,也就是第一项更大。同理第二项E输入采样自G生成数据,所以我们期望D(G(z))趋近于0更好,也就是说第二项又是更大。所以是这一部分是期望训练使得整体更大了,也就是maxD的含义了。
最大化log D(x))(即对于真实数据,希望其 渐渐趋向于1,就是更大更好),训练网络G最小化log(1 – D(G(z)))(对于这个输出是希望越小越好),即最大化D的损失
GAN: 原始损失函数详解 - walter_xh - 博客园 (cnblogs.com)
生成式对抗网络(GAN)-(Generative Adversarial Networks)算法总结(从原始GAN到....目前)_人工智障之深度瞎学的博客-CSDN博客
模型介绍
这个模型相当于是查询合成与不确定性采样原理结合而成,其中这里的不确定性指的是模型对数据集最不能确定的部分样本
z是潜变量,G是通过GAN算法得到的,LactiveGZ是生成信息主动学习查询的损失函数,LregGZ是确保生成样本质量的正则化项。
实验步骤:通过求解(2)在所有未标记数据上训练生成器G,人工标注少量随机选取的样本后,用DCGAN生成目前判别器相对不确定的新数据交给人去标注,由此迭代训练分类模型。
改进用于本实验的公式:这里引入了一个SVM求超平面的一个概念,看不太懂


实验:
模型训练的数据集是MNIST, SVHN and CIFAR-10,初始化50个个随机选择的样本初始化训练集。算法每次处理一批 10个新样本。
对比方法:passive GAN:从未标记的池中随机抽样实例。
Tong&Koller’s:SVM算法,用全部样本训练
randon sampling:从未标记池中随机采样实例
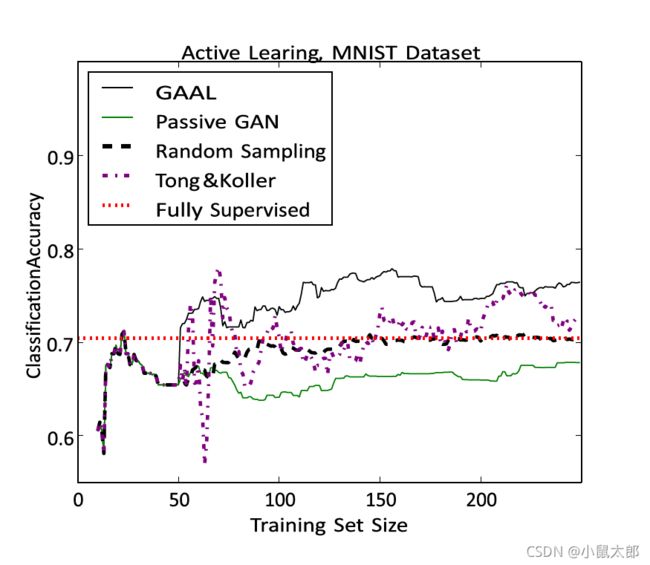
MNIST数据集的主动学习结果,分类为5和7。结果是5次运行的平均值。将完全监督学习精度绘制为水平线进行比较。
缺点:
G与D没有在迭代的过程中获得提升,并且太依赖于生成器生成图像的质量。