机器学习之——K近邻算法(KNN)
文章目录
-
- 定义
- KNN的三个基本要素
- KNN的实现方法
- KNN模型的优缺点
- 闵可夫斯基距离
- 代码实现
- sklearn.neighbors.KNeighborsClassifier 使用
定义
K近邻法(k-NearestNeighbor)是一种很基本的机器学习方法,能做分类和回归任务
KNN的三个基本要素
- 欧式距离 判断类别远近
- k值,选择方式
- 决策方式
(1)距离度量
- 在引例中所画的坐标系,可以叫做特征空间。特征空间中两个实例点的距离是两个实例点相似程度的反应(距离越近,相似度越高)。kNN模型使用的距离一般是欧氏距离,但也可以是其他距离如:曼哈顿距离
(2)k值的选择
- k值的选择会对kNN模型的结果产生重大影响。选择较大的k值,相当于用较大邻域中的训练实例进行预测,模型会考虑过多的邻近点实例点,甚至会考虑到大量已经对预测结果没有影响的实例点,会让预测出错;选择较小的k值,相当于用较小邻域中的训练实例进行预测,会使模型变得敏感(如果邻近的实例点恰巧是噪声,预测就会出错)。
- 在应用中,k值一般取一个比较小的数值。通常采用一些验证方法来选取最优的k值。
(3)决策规则
- 分类:往往是多数表决,即由输入实例的k个邻近的训练实例中的多数类决定待测实例的类。或带权投票
- 回归:取平均值。或带权取平均值
KNN的实现方法
(1)蛮力法(brute-force)
- k近邻法最简单的实现方式是线性扫描,需要计算待测实例与每个实例的距离,在大数据上不可行。
(2)KD树(KDTree)
- 为了提高k近邻搜索效率,考虑使用特殊的结构存储训练数据,以减少计算距离的次数,可以使用kd树(kd tree)方法。kd树分为两个过程——构造kd树(使用特殊结构存储训练集)、搜索kd树(减少搜索计算量)
(3)球树(BallTree)
- 球树,顾名思义就是分割块都是超球体,而不是KD树里面的超矩形体。
KNN模型的优缺点
(1)优点
- 思想简单,既可以做分类又可以做回归
- 惰性学习,无需训练(蛮力法),KD树的话,则需要建树
- 对异常点不敏感
- 训练时间复杂度比支持向量机之类的算法低,仅为O(n)
- 和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感
- 对类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
- 比较适用于样本比较大的类域的自动分类,而那些样本容量比较小的类域采用这种算法容易产生误分
(2)缺点
- 计算量大、速度慢
- 样本不平衡的时候,对稀有类别的预测准确率低
- KD树,球树之类的模型建立需要大量的内存
- 相比决策树模型,KNN模型可解释性不强
- 使用懒惰的学习方法,基本不学习,导致预测时的速度比逻辑回归之类的算法慢
闵可夫斯基距离
1.假设有两个样本点x1,x2,它们两者间的闵可夫斯基距离Lp定义为
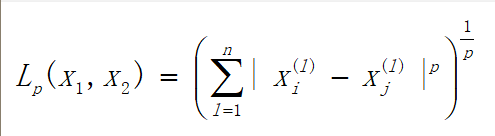
- 当p=1时,称为曼哈顿距离(Manhattan distance),即

- 当p=2时,称为欧氏距离(Euclidean distance),即

- 当p=∞时,称为切比雪夫距离

代码实现
(1)投票法[0,1]
#投票法做分类
#[x1, x2, y]
T = [[3, 104, 0],
[2, 100, 0],
[1, 81, 0],
[101, 10, 1],
[99, 5, 1],
[98, 2, 1]]
#预测分类
x = [18, 90]
#用最近k个点做预测
K = 5
#记录所有样本点到预测点距离
dis = []
import math
for i in T:
d = math.sqrt((x[0]-i[0])**2 + (x[1] - i[1])**2)
#添加距离和标签
dis.append([d,i[2]])
#按照距离排序
dis.sort(key=lambda x:x[0])
print(dis)
# box 距离最近的前k个标签点
print(1 if sum([i[1] for i in dis[:k]])>k/2 else 0)
[[18.867962264113206, 0], [19.235384061671343, 0], [20.518284528683193, 0], [115.27792503337315, 1], [117.41379816699569, 1], [118.92854997854805, 1]]
0
(2)投票法[-1,1]
#分类
#训练样本点
T = [[3, 104, -1],
[2, 100, -1],
[1, 81, -1],
[101, 10, 1],
[99, 5, 1],
[98, 2, 1]]
#测试样本
x = [18, 90]
K = 5
dis = []
import numpy as np
for i in T:
d = np.sqrt((x[0] - i[0])**2 + (x[1] - i[1])**2)
dis.append([d,i[2]])
dis.sort(key=lambda x:x[0])
print(dis)
# 计算距离为正还是负, 如果是正,那么结果是+1
print(-1 if sum([1/i[0]*i[1] for i in dis[:K]])<0 else 1)
[[18.867962264113206, -1], [19.235384061671343, -1], [20.518284528683193, -1], [115.27792503337315, 1], [117.41379816699569, 1], [118.92854997854805, 1]]
-1
(3)回归[求均值]
#回归
T = [[3, 104, 98],
[2, 100, 93],
[1, 81, 95],
[101, 10, 16],
[99, 5, 8],
[98, 2, 7]]
x = [18, 90]
K = 5
dis = []
from math import sqrt
for i in T:
d = sqrt((x[0]-i[0])**2 + (x[1]-i[1])**2)
dis.append([d, i[2]])
dis.sort(key=lambda x:x[0])
from numpy import mean
#求平均值
print(mean([i[1] for i in dis[0:K]]))
62.0
(4)带权回归
#带权回归
T = [
[3, 104, 98],
[2, 100, 93],
[1, 81, 95],
[101, 10, 16],
[99, 5, 8],
[98, 2, 7]
]
x = [18, 90]
K = 4
dis = []
import math
for i in T:
d = (x[0]-i[0])**2 + (x[1]-i[1])**2
#pow方法 幂函数
dis.append([pow(d,1/2), i[2]])
dis.sort(key=lambda x:x[0])
dis = [[1/i[0],i[1]] for i in dis][0:K]
a = 1 / sum([i[0] for i in dis])
print(dis)
res = sum([i[0]*i[1] for i in dis])
print(res*a)
[[0.052999894000318, 93], [0.05198752449100364, 95], [0.04873701788285793, 98], [0.008674687714152543, 16]]
91.02775527644329
导库求预测
from sklearn.neighbors import KNeighborsClassifier
# 编写一个kNN算法函数,并通过数据来验证算法的正确性。
# 1、四个样本数据点:[1.0, 0.9], [1.0, 1.0], [0.1, 0.2], [0.0, 0.1]
x = [1.0, 0.9], [1.0, 1.0], [0.1, 0.2], [0.0, 0.1]
# 2、四个样本数据点所属分类:['A', 'A', 'B', 'B']
y = ['A', 'A', 'B', 'B']
print(x,y)
model = KNeighborsClassifier(n_neighbors=2)
model.fit(x,y)
# 3、通过调用kNN算法,分别检验两个点[1.2, 1.0]和[0.1, 0.3]的分类
s = [1.2, 1.0], [0.1, 0.3]
print(model.predict(s))
([1.0, 0.9], [1.0, 1.0], [0.1, 0.2], [0.0, 0.1]) ['A', 'A', 'B', 'B']
['A' 'B']
sklearn.neighbors.KNeighborsClassifier 使用
sklearn.neighbors.KNeighborsClassifier(n_neighbors = 5,weights =‘uniform’,algorithm =‘auto’,leaf_size = 30,p = 2,metric =‘minkowski’,metric_params = None,n_jobs = None,kwargs
参数
- n_neighbors : int,optional(default = 5)默认情况下kneighbors查询使用的邻居数。
- weights: str或callable,可选(default = ‘uniform’)用于预测的权重函数。可能的值:
’uniform’: 均匀的重量。每个社区的所有积分均等。
’distance’: 重量点距离的倒数。在这种情况下,查询点的较近邻居将比远离的邻居具有更大的影响力。
[callable]: 一个用户定义的函数,它接受一个距离数组,并返回一个包含权重的相同形状的数组。 - algorithm : {‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选
用于计算最近邻居的算法:
'ball_tree’将使用 BallTree
'kd_tree’将使用 KDTree
'brute’将使用蛮力搜索。
'auto’将尝试根据传递给fit方法的值来确定最合适的算法。
注意:在稀疏输入上拟合将使用强力来覆盖此参数的设置。 - leaf_size : int,optional(default = 30)
叶子大小传递给BallTree或KDTree。这可能会影响构造和查询的速度,以及存储树所需的内存。最佳值取决于问题的性质。 - p : 整数,可选(default = 2)
Minkowski指标的功率参数。当p = 1时,这相当于使用manhattan_distance(l1),并且对于p = 2使用euclidean_distance(l2)。对于任意p,使用minkowski_distance(l_p)。 - metric : 字符串或可调用,默认为’minkowski’
用于树的距离度量。默认度量标准是minkowski,p = 2等于标准欧几里德度量标准。有关可用指标的列表,请参阅DistanceMetric类的文档。 - metric_params : dict,optional(默认=无)
度量函数的其他关键字参数。 - n_jobs : int或None,可选(默认=无)
为邻居搜索运行的并行作业数。 None除非在joblib.parallel_backend上下文中,否则表示1 。 -1表示使用所有处理器。有关 详细信息,请参阅词汇表。不影响fit方法。
方法
- fit(self, X, y) 使用X作为训练数据并使用y作为目标值来拟合模型
- get_params(self[, deep]) 获取此估算工具的参数。
- kneighbors(self [,X,n_neighbors,…]) 找到一个点的K邻居。
- kneighbors_graph(self [,X,n_neighbors,mode]) 计算X中点的k-邻居的(加权)图
- predict(self, X) 预测所提供数据的类标签
- predict_proba(self, X) 测试数据X的返回概率估计。
- score(self,X,y [,sample_weight]) 返回给定测试数据和标签的平均精度。
- set_params(self, **params) 设置此估算器的参数。
详情(https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html#sklearn.neighbors.KNeighborsClassifier)