吴恩达Course1《神经网络与深度学习》week2:神经网络基础
1. 二元分类
举例说明
逻辑回归logistic regression是一个用于二分类的算法。
什么是二分类呢?
举一个例子:输入一张图片到逻辑回归模型中,该算法输出得到1(是猫)或0(不是猫)。
更具体来说,应该如何将一张图片转化为输入值呢?
在计算机中,一张图片的存储方式是用三个矩阵分别存储图片中的红、绿、蓝。假设一张图片的大小为64*64px,则一张图片的总数据量为64*64*3=12288。顺序取出红、绿、蓝三个矩阵中的数值组成一个一维列向量 x 作为输入值,该特征向量x的纬度为(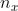 , 1),其中 = 12288
, 1),其中 = 12288

一些符号的含义
![]() :表示一个单独的样本
:表示一个单独的样本
![]() :x是
:x是![]() 维的特征向量,输入值
维的特征向量,输入值
![]() :输出结果y只能是0或1
:输出结果y只能是0或1
![]() :表示第i个样本的输入和输出
:表示第i个样本的输入和输出
![]() :训练集的样本数量
:训练集的样本数量 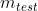 :测试集的样本数量
:测试集的样本数量
为了方便之后神经网络的计算,我们通常定义(X, Y)表示输入和输出

![]()
![]()
![]()

2. logistic 回归
二元分类问题是给定一个输入的特征向量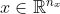 ,想要通过算法得到预测值
,想要通过算法得到预测值 。
。
这个预测值可以解释为![]() ,即在给定某一特征向量
,即在给定某一特征向量 的条件下
的条件下 的概率,所以
的概率,所以![]() 。
。
那么如何得到预测值,即算法该怎样设计呢?如果尝试让![]() (实际上是线性回归,其中
(实际上是线性回归,其中![]() 是特征值的权重,
是特征值的权重, 是一个实数,表示偏差),则结果可能不在0-1之间。所以在上述式子的基础上加一个sigmoid函数。
是一个实数,表示偏差),则结果可能不在0-1之间。所以在上述式子的基础上加一个sigmoid函数。
逻辑回归模型:![]() ,其中sigmoid函数表达式为
,其中sigmoid函数表达式为![]() ,
,
sigmoid函数图像为
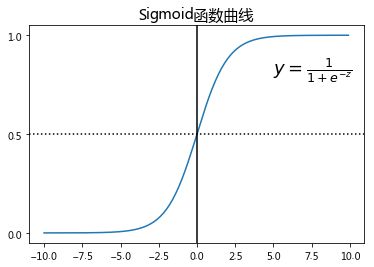
sigmoid函数特征 :当![]() 时,
时,![]() ;当
;当![]() 时,
时,![]() ;当
;当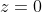 时,
时,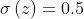

3. logistic回归损失函数
对于逻辑回归模型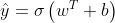 得到的预测值,我们想要尽可能接近于真实值
得到的预测值,我们想要尽可能接近于真实值 。所以需要使用训练集训练参数
。所以需要使用训练集训练参数 ,使得到的预测值接近于真实值。
,使得到的预测值接近于真实值。
为此,引入损失函数Loss function:![]() ,损失函数用来衡量预测值与真实值之间的差距。一般来说,
,损失函数用来衡量预测值与真实值之间的差距。一般来说,![]() ,但是在逻辑回归中不使用这一损失函数。原因是在使用梯度下降算法优化参数时,优化函数是非凸的,梯度下降算法找到的可能是局部最优解而不是全局最优。
,但是在逻辑回归中不使用这一损失函数。原因是在使用梯度下降算法优化参数时,优化函数是非凸的,梯度下降算法找到的可能是局部最优解而不是全局最优。
所以,逻辑回归中使用另一个损失函数![]()
为什么使用这一公式来计算逻辑回归的损失函数?因为能使预测值符合预期,即使预测值接近于真实值,举例说明:
当时,![]() ,我们想要
,我们想要![]() 的值越小越好,也就是让
的值越小越好,也就是让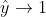 (
(![]() )
)
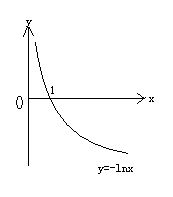
当 时,
时,![]() ,我们想要
,我们想要![]() 的值越小越好 ,也就是让
的值越小越好 ,也就是让![]()
(![]() )
)
注意,损失函数Loss function值针对单个训练样本,即![]()
为了衡量算法在全部样本上的表现,引入代价函数Cost function:

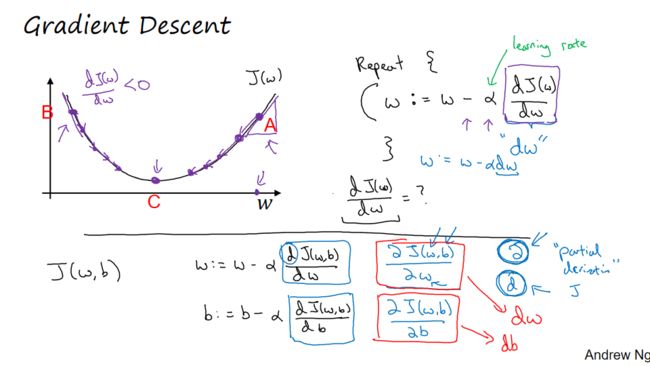
4. 梯度下降法
梯度下降算法是干什么的?在上一小节,我们学习了代价函数![]() ,它可以衡量算法在全部样本上的表现,
,它可以衡量算法在全部样本上的表现,![]() 的值越小,算法表现越好。梯度下降算法可以训练出参数,使得
的值越小,算法表现越好。梯度下降算法可以训练出参数,使得![]() 的值全局最小。
的值全局最小。
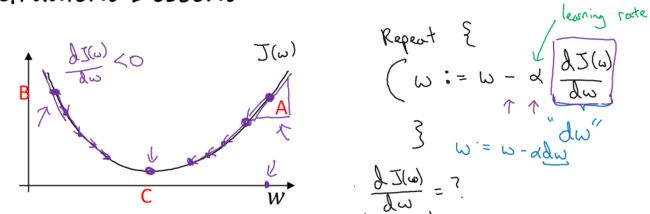
根据下图大致说明梯度下降算法的执行过程:

step1. 初始化参数。对于逻辑回归,几乎所有的初始化方法都有效,通常初始化为0。因为是凸函数,所以无论在哪里初始化,都会到达最低点。
step2. 朝最陡的下坡方向走一步,不断迭代
step3. 直至走到最低点,即全局最优解
更具体来讲,如何朝最陡下坡方向进行不断迭代?
假设代价函数![]() 只有一个参数
只有一个参数 (方便画图)
(方便画图)
 :学习率learning rate,用来控制步长step,
:学习率learning rate,用来控制步长step,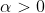
![]() :导数,可形象化理解为该点斜率slope
:导数,可形象化理解为该点斜率slope
若初始化点为A,此时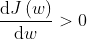 ,故值不断减小,向左不断逼近最低点
,故值不断减小,向左不断逼近最低点
若初始化点为B,此时![]() ,故值不断增大,向右不断逼近最低点
,故值不断增大,向右不断逼近最低点
逻辑回归的梯度下降算法:
![]()
在代码中使用dw代表![]() ,使用db代表
,使用db代表![]()

 7. 计算图
7. 计算图
为了方便理解神经网络中的前向传播forward propagation和反向传播back propagation过程,这一小节和下一小节会举一个比逻辑回归更简单的,不那么正式的神经网络的例子。
当我们要计算函数![]() 时,可以添加几个中间变量,分几步进行计算
时,可以添加几个中间变量,分几步进行计算
step1. 假设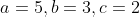
step2. 计算![]()
step3. 计算![]()
step4. 计算![]()
前向传播过程:从左向右计算表达式

8. 计算图的导数计算
继续使用上一小节的例子,计算导数![]()
step1. ![]()
step2. ![]()
step3. ![]()
step4. ![]()
step5. ![]()
反向传播过程:从右向左计算导数


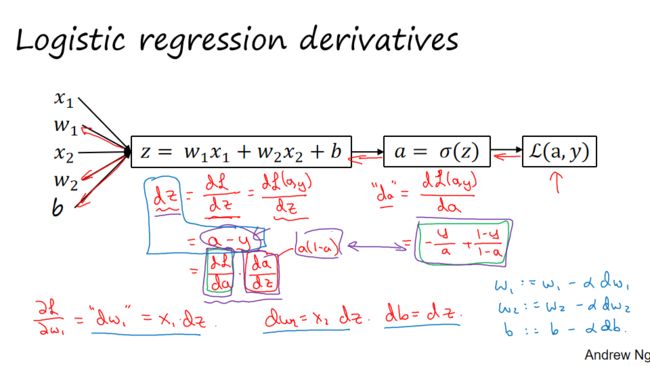
9. logistic回归中的梯度下降算法
本节内容为使用计算图对逻辑回归的损失函数 和梯度下降算法的相关导数进行计算。
和梯度下降算法的相关导数进行计算。
逻辑回归模型:![]()
![]()
逻辑回归的损失函数:![]()
举例使用计算图计算,如下图所示:
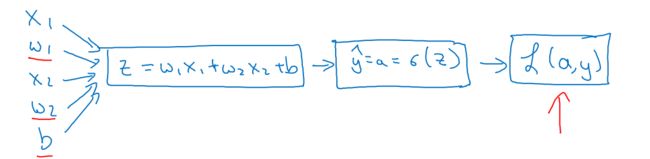 上图说明了在单个训练样本上计算损失函数的步骤,接下来讨论通过反向传播计算导数。因为梯度下降算法会用到
上图说明了在单个训练样本上计算损失函数的步骤,接下来讨论通过反向传播计算导数。因为梯度下降算法会用到![]()
step1. ![]()
step2. ![]()
step3. ![]()
![]()
![]()
之后,即可计算![]()
上述为针对单个训练样本的逻辑回归梯度下降算法,但训练逻辑回归模型的训练集不可能只有1个样本,下一小节将使用整个训练样本集。

 10. m个样本的梯度下降
10. m个样本的梯度下降
因为 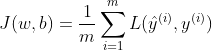
所以 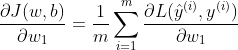 ,其余参数的导数同理
,其余参数的导数同理
所以,在m个样本的训练集上,应用梯度下降算法求解参数的代码流程如下:
# 1. 初始化
w1 = w2 = b = 0 # 参数
J = dw1 = dw2 = db = 0 # 累加器
# 2. for循环计算J,dw1,dw2,db
for i in range(1, m+1):
z[i] = w1*x1[i] + w2*x2[i] + b
a[i] = sigmoid(z[i]) # a代表预测值y_hat
J += -y[i]*log(a[i])-(1-y[i])log(1-a[i])
dz[i] = a[i] -y[i]
dw1 += x1[i]*dz[i]
dw2 += x2[i]*dz[i]
db += dz[i]
J /= m
dw1 /= m
dw2 /= m
db /= m
# 3. 应用梯度下降更新参数
w1 = w1 - alpha*dw1
w2 = w2 - alpha*dw2
b = b- alpha*db
# 4. 重复2、3两步直至J不再减小上述代码由于显示使用for循环导致算法很低效,下面我们将学习向量化来提高算法效率。

 11. 向量化
11. 向量化
在逻辑回归中我们需要计算![]()
如果使用for循环,即非向量化方式,代码如下:
z = 0
for i in range(n_x):
z += w[i] * z[i]
z += b如果使用向量化方式,代码如下:
z = np.dot(w, x) + b向量化之后运算效率大幅提升。
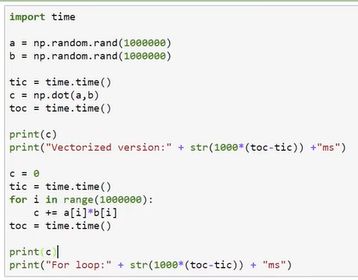
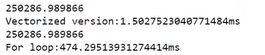

12. 向量化更多例子
1. 如果我们想计算矩阵乘法![]() ,矩阵乘法定义为
,矩阵乘法定义为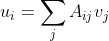
使用for循环,即非向量化方式,代码如下:
u = np.zeros((n,1))
for i in range(n):
for j in range(len(v)):
u[i] += A[i][j] * v[j]使用向量化方式,代码如下:
u = np.dot(A,v) 2. 如果有一列向量![]() ,我们想要计算
,我们想要计算![]()
使用for循环,非向量化方式,代码如下:
u = np.zeros((n, 1))
for i in range(n):
u[i] = math.exp(v[i])使用向量化方式,代码如下:
u = np.exp(v)numpy其他一些计算方法:
np.log(v) # 计算以e为底的对数
np.abs(v) # 计算绝对值
np.maximum(v, 0) # 求取v与0中较大值
v ** 2 # v的平方
1 / v # v的倒数所以当你想写for循环的时候,检查numpy是否存在类似的内置函数,从而避免使用for循环。
3. 使用上述方法,简化逻辑回归的for循环代码:
# 1. 初始化
w = np.zeros((n, 1)) # 参数
b = 0
J = db = 0 # 累加器
dw = np.zeros((n, 1))
# 2. for循环计算J,dw,db
for i in range(1, m+1):
z[i] = np.dot(w.T, x[i]) + b
a[i] = sigmoid(z[i]) # a代表预测值y_hat
J += -y[i]*log(a[i])-(1-y[i])log(1-a[i])
dz[i] = a[i] - y[i]
dw += x[i]*dz[i]
db += dz[i]
J /= m
dw /= m
db /= m
# 3. 应用梯度下降更新参数
w = w - alpha*dw
b = b- alpha*db
# 4. 重复2、3两步直至J不再减小


13. 向量化logistic回归
本节将应用向量化方法,不再应用for循环对数据集中的m个样本进行变量。
之前对于m个样本,我们的计算过程是这样的:
对第一个样本进行预测:![]()
对第二个样本进行预测:![]()
......以此类推。
如果有m个样本,我们需要重复上述步骤m次。
现在应用向量化方法:
step1. 定义 ,作为输入
,作为输入
step2. 计算![]()
![]()
step3. 计算![]()
14. 向量化logistic回归的梯度输出
本节将应用向量化方法,实现梯度下降的一次迭代过程。
step1. 定义![]() ,
,![]() ,
,![]()
step2. 计算![]()
step3. 计算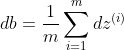
step4. 计算![]()
综上,逻辑回归梯度下降算法中的一次迭代过程如下:
# 1. 初始化
w = np.zeros((n, 1)) # 参数
b = 0
J = db = 0 # 累加器
dw = np.zeros((n, 1))
# 向量化计算J,dw,db
Z = np.dot(w.T,X) + b
A = sigmoid(Z) # a代表预测值y_hat
J = 1/m * np.sum(-Y*np.log(A)-(1-Y)np.log(1-A))
dZ = A - Y
dw = 1/m * np.dot(X,dZ.T)
db = 1/m * np.sum(dZ)
# 3. 应用梯度下降更新参数
w = w - alpha*dw
b = b- alpha*db
# 4. 重复2、3两步直至J不再减小