R语言处理缺失数据的5个常用包
R语言处理缺失数据的5个常用包
- 1.常用缺失数据处理包
- 2. MICE 包
-
- 2.1基本介绍
- 2.2 实例展示
- 3.Amelia包
-
- 3.1基本介绍
- 3.2实例展示
- 4.missForest包
-
- 4.1基本介绍
- 4.2实例展示
- 5.Hmisc包
-
- 5.1基本介绍
- 5.2实例展示
- 6.mi包
-
- 6.1基本介绍
- 6.2实例展示
1.常用缺失数据处理包
1.MICE
2.Amelia
3.missForest
4.Hmisc
5.mi
书籍推荐:《Multiple Imputation of Missing Data in Practice Basic Theory and Analysis Strategies》
下载
提取码:2022
书籍目录:






2. MICE 包
2.1基本介绍
MICE (Multivariate Imputation via Chained Equations)通过链式方程进行多元插补,是R语言中处理缺失数据的常用包。
MICE包使用的前提是认为数据是随机缺失的(Missing at Random, MAR),这意味着一个值丢失的概率仅取决于观测值。它通过指定每个变量的插补模型,逐个变量地插补数据,利用观测值对缺失值进行预测。
例如:有X1,X2,…,Xk共k个变量。如果变量X1中含有缺失值,那么它将在其他变量X2到Xk上回归,再利用X1中的预测值替换X1中的缺失值。同理,如果变量X2中含有缺失值,那么X1、X3到Xk变量将作为自变量构建预测模型,随后,将X2中的缺失值用X2中对应的预测值代替。(通常,线性回归用于预测连续型变量的缺失值,逻辑回归用于分类型变量的缺失值。)一旦上述循环完成,就会生成多个数据集,且这些数据集仅在插补缺失值上有所不同。一般来说,结合它们的结果在这些数据集上分别建立模型是一种比较好的做法。
MICE包中提供的预测方法有以下四种:
1.PMM (Predictive Mean Matching) — 用于数值型变量
2.logreg(Logistic Regression) — 用于二值分类型数据
3.polyreg(Bayesian polytomous regression) — 用于多分类变量
4.Proportional odds model — 用于多分类有序变量
2.2 实例展示
#step1:加载数据
data <- iris
#整体统计分析
summary(iris)
#因为MICE假设数据是随机缺失的,所以我们可以安装missForest包,使用其中的prodNA函数在数据集中生成随机的缺失值。
#step2:随机产生10%的缺失数据
library(missForest)#首次使用安装
iris.mis <- prodNA(iris, noNA = 0.1)
#检查新生成数据中的缺失数据
summary(iris.mis)

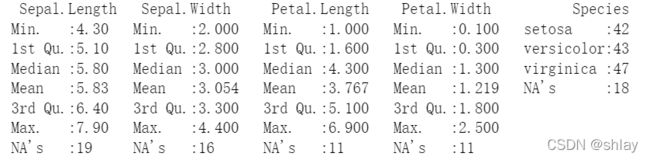
# step3:移除分类变量
iris.mis <- subset(iris.mis, select = -c(Species))
summary(iris.mis)

# step4:安装 mice
install.packages("mice")#首次使用安装
library(mice)
#mice包中的md.pattern()函数可以表格形式返回数据集中每个变量缺失值情况。
md.pattern(iris.mis)
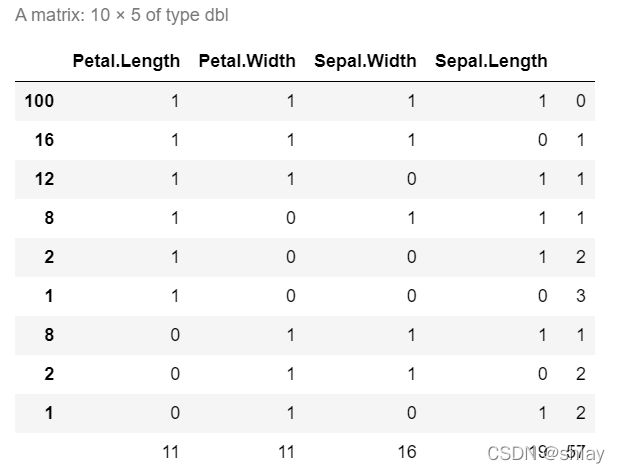
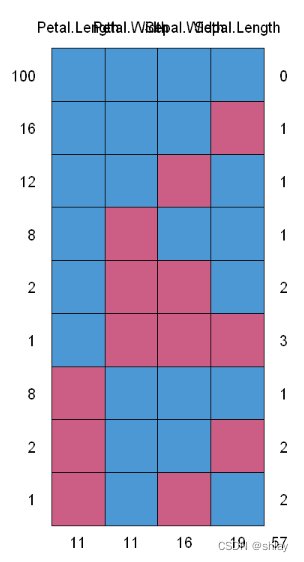
#但这中结果展示看起来不直观且有点丑。所以我们可以可以通过绘图更直观的展示数据集中变量的数据缺失情况。
install.packages("VIM")#首次使用安装
library(VIM)
mice_plot <- aggr(iris.mis, col=c('navyblue','yellow'),
numbers=TRUE, sortVars=TRUE,
labels=names(iris.mis), cex.axis=.7,
gap=3, ylab=c("Missing data","Pattern"))

#step5:填补缺失值
imputed_Data <- mice(iris.mis, m=5, maxit = 50, method = 'pmm', seed = 500)
summary(imputed_Data)
#上面mice函数中涉及的参数有带填充数据集(iris.mis),插补数据集个数(m=5),插补缺失值的最大迭代次数(maxit = 50),插补中使用的模型方法(method = 'pmm')


#step6:检查填充数据
imputed_Data$imp$Sepal.Width

#step7:得到完整数据
#方法1:由于上面的填充数据集有5个,所以可选则其中的任意一个进行缺失值的填充
completeData <- complete(imputed_Data,2)#选取5个中的第2个
summary(completeData)
completeData

`#方法2:如果你希望在5个数据集上构建模型,可以使用with()命令一次性完成。还可以组合这些模型的结果,并使用pool()命令获得合并输出。
#构建综合预测模型
fit <- with(data = imputed_Data, exp = lm(Sepal.Width ~ Sepal.Length + Petal.Width))
#组合5个模型的结果
combine <- pool(fit)
summary(combine)`

3.Amelia包
3.1基本介绍
该软件包执行多重插补进行缺失值处理,多重插补是基于bootstrap采用EMB算法。多重插补一方面有助于减少偏差和提高效率,另一方面它能够更快、更稳健地插补许多变量,包括横截面、时间序列数据等。此外,还可使用多核CPU的并行实现插补功能。
Amelia包使用的假设前提是:
1.数据集中的所有变量服从多元正态分布(MVN),可通过均值和协方差来描述数据特征。
2.缺失数据本质上是随机的(随机缺失)
Amelia包的工作步骤是:
首先,它需要m个bootstrap样本,并对每个样本应用EMB算法。所有样本将产生m组不同的均值和方差的估计值。
然后,将第一组的估计值使用回归法用于插补第一组缺失值,第二组估计值用于插补第二组缺失值,依此类推。
相较于MICE包,Amelia包具有以下不足之处:
1.与小鼠相比,Amelia包要求变量服从多元正态分布(MVN),而MICE包直接以变量为基础输入数据,没有其他数据分布的限制。
2.MICE能够处理不同类型的变量,而Amelia包的MVN假设需要变量服从或近似服从正态分布,针对分类型数据和顺序数据的处理存在一定的困难。
3.MICE包可以管理在数据子集上定义的变量的插补,而Amelia包不能。
因此,当数据满足多变量正态分布时,该软件包最有效。如果没有,就要进行转换,使数据接近正态,或选用其他工具包进行缺失数据的填补。
3.2实例展示
#step1:安装并加载工具包
install.packages("Amelia")#首次使用安装
library(Amelia)
#step2:加载数据
data("iris")
#step3:随机产生10%的缺失数据
iris.mis <- prodNA(iris, noNA = 0.1)
summary(iris.mis)
#step4:指定合适的变量(Species),利用进行缺失值填充
amelia_fit <- amelia(iris.mis, m=5, parallel = "multicore", noms = "Species")
#step5:获取填充数据集的输出
amelia_fit$imputations[[1]]
amelia_fit$imputations[[2]]
amelia_fit$imputations[[3]]
amelia_fit$imputations[[4]]
amelia_fit$imputations[[5]]
#step6:检测核心关注列(Species)是否在填充数据集中
amelia_fit$imputations[[5]]$Sepal.Length
#step7:将填充数据集导出至csv文件
write.amelia(amelia_fit, file.stem = "imputed_data_set")
结果略
4.missForest包
4.1基本介绍
顾名思义,missForest是基于随机森林算法进行的缺失值填充。这是一种适用于各种变量类型的非参数插补方法。非参数方法对函数形式f没有明确的假设。相反,它试图估算f,使其尽可能接近测试数据。
简单来说,它的工作原理是为每个变量建立了一个随机森林模型;然后利用该模型,借助观测值预测变量中的缺失值。
它产生了现成的插补误差估计。此外,它还对插补过程进行了高度控制。它可以选择单独返回每个变量,而不是对整个数据矩阵进行聚合。这有助于我们更仔细地了解模型估算每个变量值的准确程度。
因为bagging算法在分类变量上也很有效,所以我们不需要在这里删除它们。missForest包能够很好地处理不同类型变量的缺失值。
4.2实例展示
#step1:安装并加载工具包
install.packages("missForest")#首次使用安装
library(missForest)
#step2:加载数据
data("iris")
#step3:随机产生10%的缺失数据
iris.mis <- prodNA(iris, noNA = 0.1)
summary(iris.mis)
#step4:缺失数据的填充,missForest函数中的所有参数使用默认值
iris.imp <- missForest(iris.mis)
#step5:检查填充值
iris.imp$ximp
#step6:检查插补误差
iris.imp$OOBerror
#step7:计算插补的准确率
iris.err <- mixError(iris.imp$ximp, iris.mis, iris)
iris.err

输出NRMSE是标准化均方误差。它用于表示由连续型数据输入得出的误差。PFC(错误分类的比例)表示由分类型数据输入得出的误差。
5.Hmisc包
5.1基本介绍
Hmisc可用于数据分析、高级图形绘制、缺失值插补、高级表格制作、模型拟合和诊断(线性回归、逻辑回归和cox回归)等。该软件包中包含了两个强大的缺失值插补功能。它们是impute()和aregImpute()。虽然它也有transcan()函数,但使用aregImpute()更好。
impute()函数使用统计方法(均值、最大值、中位数)简单地插补缺失值。它的默认值是中位数填充。
aregImpute()函数允许使用加性回归、自举和预测平均值匹配进行平均值插补。其工作原理是在bootstrap中,对每个多重插补使用不同的bootstrap重采样。然后,在原始数据的替换样本上拟合一个灵活的加性模型(非参数回归方法),并使用非缺失值(自变量)预测缺失值(作为因变量)。
最后,它使用预测平均值匹配(默认)来插补缺失值。预测平均值匹配法适用于连续型和分类型数据,无需计算残差和极大似然拟合。
以下是Hmisc包的适用前提假设:
1.它假设预测的变量呈线性。
2.Fisher最优评分法用于预测分类变量。
5.2实例展示
#step1:安装并加载工具包
install.packages("Hmisc")#首次使用安装
library(Hmisc)
#step2:加载数据
data("iris")
#step3:随机产生10%的缺失数据
iris.mis <- prodNA(iris, noNA = 0.1)
summary(iris.mis)
# 均值插补
iris.mis$imputed_age <- with(iris.mis, impute(Sepal.Length, mean))
# 随机插补
iris.mis$imputed_age2 <- with(iris.mis, impute(Sepal.Length, 'random'))
#除此之外还可以用 min, max, median 去填充
#使用 argImpute
impute_arg <- aregImpute(~ Sepal.Length + Sepal.Width + Petal.Length + Petal.Width + Species, data = iris.mis, n.impute = 5)
#插补变量查看Sepal.Length
impute_arg$imputed$Sepal.Length

6.mi包
6.1基本介绍
mi (Multiple imputation with diagnostics) 包提供了几个处理缺失值的函数。与其他软件包一样,它还构建了多个插补模型来近似缺失值。并采用预测均值匹配方法。
在上面解释了预测平均值匹配(pmm),有一个更简单的版本:对于缺失值变量中的每个观察值,我们发现(从可用值中)与该变量最接近的预测平均值的观察值。然后将该“匹配”的观察值用作插补值。
以下是该软件包的一些独特特性:
1.它允许插补模型的图形诊断和插补过程的收敛。
2.它使用贝叶斯回归模型来处理分离问题。
3.插补模型输出与R中的回归输出类似。
4.它自动检测数据中的不规则性,例如变量之间的多重共线性。
5.它为插补过程添加了噪声,以解决加性约束问题。
6.2实例展示
#step1:安装并加载工具包
install.packages("mi")#首次使用安装
library(mi)
#step2:加载数据
data("iris")
#step3:随机产生10%的缺失数据
iris.mis <- prodNA(iris, noNA = 0.1)
summary(iris.mis)
#step4:基于mi进行缺失值填充i
mi_data <- mi(iris.mis, seed = 335)#此处使用了参数的默认值,即:插补方法:rand.imp.method=“bootstrap”;多重插补次数:n.imp=3;迭代次数:n.iter=30
summary(mi_data)
