代码详解:运用Numpy实现梯度下降优化算法的不同变体
全文共14118字,预计学习时长30分钟或更长
想了解如何使用numpy在tensorflow或pytorch中实现优化算法,以及如何使用matplotlib创建精美的动画?
本文将讨论如何实现梯度下降优化技术的不同变体,以及如何使用matplotlib将用于这些变体更新规则的运作可视化出来。
本文的内容和结构基于 One-Fourth Labs。
梯度下降是优化神经网络最常用的技术之一。梯度下降算法是通过向相对于网络参数的目标函数梯度的相反方向移动来更新参数。

运用Numpy在Python中实现

照片来源:Unsplash,克里斯托弗·高尔
编码部分将讨论以下主题。
• Sigmoid神经元类
• 总体设置——何为数据、模型、任务
• 绘图功能——3D和轮廓图
• 个体算法及其执行方式
在开始实现梯度下降之前,首先需要输入所需的库。从mpl_toolkits.mplot3d输入的Axes3D提供了一些基本的3D绘图(散点、曲面、直线、网格)工具。它并非最快或功能最完整的3D库,而是Matplotlib附带的。还从 Matplotlib输入colors和colormap(cm)。我们想要制作动画图来演示每种优化算法的工作原理,所以我们输入animation和rc来让图表看起来美观。为了显示HTML,在Jupyter Notebook中成线性排列。最后为了计算目的来输入numpy,这项计算任务很繁重。
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
from matplotlib import cm
import matplotlib.colors
from matplotlib import animation, rc
from IPython.display import HTML
import numpy as np实施Sigmoid神经元
为了实现梯度下降优化技术,以sigmoid神经元(逻辑函数)为例,看看梯度下降的不同变体是如何学习参数“ w”和“ b”的。
Sigmoid神经元复查
Sigmoid神经元类似于感知机神经元(perceptron neuron),因为对于每个输入xi,其都有与输入相关的权重wi。权重表明了输入在决策过程中的重要性。来自sigmoid的输出不同于感知机模型,其输出不是0或1,而是一个介于0到1之间的实数值,可以解释为概率。最常用的sigmoid 函数是逻辑函数,它具有“ S”形曲线的特征。
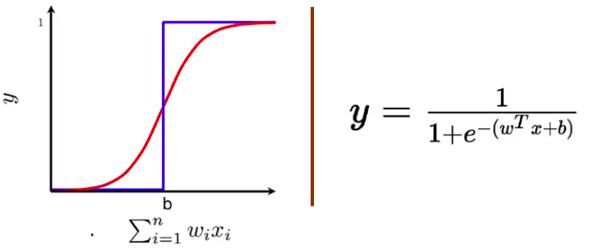
Sigmoid神经元标注(逻辑函数)
学习算法
学习算法的目标是确定参数(w和b)的最佳可能值,以使模型的整体损失(平方误差损失)尽可能最小化。

对w和b进行随机初始化。然后,对数据中的所有观测值进行迭代。使用sigmoid函数找到每个观测值相应的预测结果,并计算均方误差损失。基于损失值,将更新权重,以使在新参数下模型的整体损失将小于模型的当前损失。
Sigmoid神经元类
在开始分析梯度下降算法的不同变体之前,将在名为SN的类中构建模型。
class SN:
#constructor
def __init__(self, w_init, b_init, algo):
self.w = w_init
self.b = b_init
self.w_h = []
self.b_h = []
self.e_h = []
self.algo = algo
#logistic function
def sigmoid(self, x, w=None, b=None):
if w is None:
w = self.w
if b is None:
b = self.b
return 1. / (1. + np.exp(-(w*x + b)))
#loss function
def error(self, X, Y, w=None, b=None):
if w is None:
w = self.w
if b is None:
b = self.b
err = 0
for x, y in zip(X, Y):
err += 0.5 * (self.sigmoid(x, w, b) - y) ** 2
return err
def grad_w(self, x, y, w=None, b=None):
if w is None:
w = self.w
if b is None:
b = self.b
y_pred = self.sigmoid(x, w, b)
return (y_pred - y) * y_pred * (1 - y_pred) * x
def grad_b(self, x, y, w=None, b=None):
if w is None:
w = self.w
if b is None:
b = self.b
y_pred = self.sigmoid(x, w, b)
return (y_pred - y) * y_pred * (1 - y_pred)
def fit(self, X, Y,
epochs=100, eta=0.01, gamma=0.9, mini_batch_size=100, eps=1e-8,
beta=0.9, beta1=0.9, beta2=0.9
):
self.w_h = []
self.b_h = []
self.e_h = []
self.X = X
self.Y = Y
if self.algo == 'GD':
for i in range(epochs):
dw, db = 0, 0
for x, y in zip(X, Y):
dw += self.grad_w(x, y)
db += self.grad_b(x, y)
self.w -= eta * dw / X.shape[0]
self.b -= eta * db / X.shape[0]
self.append_log()
elif self.algo == 'MiniBatch':
for i in range(epochs):
dw, db = 0, 0
points_seen = 0
for x, y in zip(X, Y):
dw += self.grad_w(x, y)
db += self.grad_b(x, y)
points_seen += 1
if points_seen % mini_batch_size == 0:
self.w -= eta * dw / mini_batch_size
self.b -= eta * db / mini_batch_size
self.append_log()
dw, db = 0, 0
elif self.algo == 'Momentum':
v_w, v_b = 0, 0
for i in range(epochs):
dw, db = 0, 0
for x, y in zip(X, Y):
dw += self.grad_w(x, y)
db += self.grad_b(x, y)
v_w = gamma * v_w + eta * dw
v_b = gamma * v_b + eta * db
self.w = self.w - v_w
self.b = self.b - v_b
self.append_log()
elif self.algo == 'NAG':
v_w, v_b = 0, 0
for i in range(epochs):
dw, db = 0, 0
v_w = gamma * v_w
v_b = gamma * v_b
for x, y in zip(X, Y):
dw += self.grad_w(x, y, self.w - v_w, self.b - v_b)
db += self.grad_b(x, y, self.w - v_w, self.b - v_b)
v_w = v_w + eta * dw
v_b = v_b + eta * db
self.w = self.w - v_w
self.b = self.b - v_b
self.append_log()
#logging
def append_log(self):
self.w_h.append(self.w)
self.b_h.append(self.b)
self.e_h.append(self.error(self.X, self.Y))
#constructor
def __init__(self, w_init, b_init, algo):
self.w = w_init
self.b = b_init
self.w_h = []
self.b_h = []
self.e_h = []
self.algo = algoinit__函数(构造函数)有助于将sigmoid神经元的参数初始化为w权重和b偏差。这个函数有三个参数:
• w_init,b_init,这些取参数“w”和“b”的初始值,而非随机设置参数,将其设置为特定值。这样能够通过可视化不同初始点来理解算法的执行方式。有些算法在某些参数下陷入局部最小值。
• algo指出使用何种梯度下降算法的变体来发现最佳参数。
在此函数中,我们对参数进行初始化,并定义了三种带有后缀'_h'的新数组变量,表示它们是历史变量,以跟踪权重(w_h)、偏差(b_h)和误差(e_h)的值是如何随着sigmoid神经元学习参数而变化的。
def sigmoid(self, x, w=None, b=None):
if w is None:
w = self.w
if b is None:
b = self.b
return 1. / (1. + np.exp(-(w*x + b)))有一个sigmoid函数,它接受输入x-强制参数,并计算输入的逻辑函数及参数。该函数还接受其他两个可选参数。
• w & b,以“ w”和“ b”用作参数,它有助于根据特定的参数值来计算sigmoid函数的值。如果未传递这些参数,它将使用已学的参数值来计算逻辑函数。
def error(self, X, Y, w=None, b=None):
if w is None:
w = self.w
if b is None:
b = self.b
err = 0
for x, y in zip(X, Y):
err += 0.5 * (self.sigmoid(x, w, b) - y) ** 2
return err下面,有error 函数,输入X和Y作为强制参数和可选参数 ,像sigmoid函数一样。在这个函数中,通过每个数据点进行迭代,并使用sigmoid函数计算实际特征值和预测特征值之间的累积均方误差。正如在sigmoid函数中看到的,它支持在指定参数值下计算误差。
def grad_w(self, x, y, w=None, b=None):
.....
def grad_b(self, x, y, w=None, b=None):
.....
接下来,将定义两个函数grad_w和grad_b。输入“x”和“y”作为强制参数,有助于分别计算sigmoid相对于参数“w”和“b”输入的梯度。还有两个可选参数,计算指定参数值处的梯度。
def fit(self, X, Y, epochs=100, eta=0.01, gamma=0.9, mini_batch_size=100, eps=1e-8,beta=0.9, beta1=0.9, beta2=0.9):
self.w_h = []
.......
接下来,定义“ fit”法,它接受输入“ X”,“ Y”和其他一系列参数。每当将其用于梯度下降算法的特定变体时,都会解释这些参数。该函数首先初始化历史记录变量并设置本地输入变量以存储输入参数数据。
然后,对于该函数支持的每个算法,有一堆不同的“if-else”语句。依据选择的算法,将在fit法中实现梯度下降。在本文的后半部分,将详细解释这些实现。
def append_log(self):
self.w_h.append(self.w)
self.b_h.append(self.b)
self.e_h.append(self.error(self.X, self.Y))
最后,有theappend_log函数,用以存储各时期各梯度下降的参数值和损失函数值。
绘图设置
本节将定义一些配置参数,使用简单的二维toy数据集来模拟梯度下降更新规则。还定义了一些函数,创建三维和二维图并为其设置动画,可视化更新规则的运作。这种设置有助于针对不同起点、不同超参数设置和不同梯度下降变量的绘图/动画更新规则运行不同的实验。
#Data
X = np.asarray([3.5, 0.35, 3.2, -2.0, 1.5, -0.5])
Y = np.asarray([0.5, 0.50, 0.5, 0.5, 0.1, 0.3])
#Algo and parameter values
algo = 'GD'
w_init = 2.1
b_init = 4.0
#parameter min and max values- to plot update rule
w_min = -7
w_max = 5
b_min = -7
b_max = 5
#learning algorithum options
epochs = 200
mini_batch_size = 6
gamma = 0.9
eta = 5
#animation number of frames
animation_frames = 20
#plotting options
plot_2d = True
plot_3d = False首先,采用一个简单的二维玩具数据集,它包括两个输入和两个输出。在第5行定义一个字符串变量algo,它接受要执行的算法类型。初始化第6-7行中的参数'w'和'b',以指示算法的开始位置。
从第9-12行开始,设置参数的极限,即signoid神经元在指定范围内搜索最佳参数的范围。这些精心挑选的数字,用以说明梯度下降更新规则的运作。接下来将设置超参数的值,将某些变量特定于某些算法。在我们讨论算法实现的时候,我会对此进行讨论。最后,从19-22行开始,明确制作动画或绘制更新规则所需的变量。
sn = SN(w_init, b_init, algo)
sn.fit(X, Y, epochs=epochs, eta=eta, gamma=gamma, mini_batch_size=mini_batch_size)
plt.plot(sn.e_h, 'r')
plt.plot(sn.w_h, 'b')
plt.plot(sn.b_h, 'g')
plt.legend(('error', 'weight', 'bias'))
plt.title("Variation of Parameters and loss function")
plt.xlabel("Epoch")
plt.show()设置好配置参数后,将SN类进行初始化,然后使用配置参数调用fit法。此外,绘制三个历史变量,用以将参数和损失函数值在各个时期之间的变化进行可视化。
3D和2D绘图设置
if plot_3d:
W = np.linspace(w_min, w_max, 256)
b = np.linspace(b_min, b_max, 256)
WW, BB = np.meshgrid(W, b)
Z = sn.error(X, Y, WW, BB)
fig = plt.figure(dpi=100)
ax = fig.gca(projection='3d')
surf = ax.plot_surface(WW, BB, Z, rstride=3, cstride=3, alpha=0.5, cmap=cm.coolwarm, linewidth=0, antialiased=False)
cset = ax.contourf(WW, BB, Z, 25, zdir='z', offset=-1, alpha=0.6, cmap=cm.coolwarm)
ax.set_xlabel('w')
ax.set_xlim(w_min - 1, w_max + 1)
ax.set_ylabel('b')
ax.set_ylim(b_min - 1, b_max + 1)
ax.set_zlabel('error')
ax.set_zlim(-1, np.max(Z))
ax.view_init (elev=25, azim=-75) # azim = -20
ax.dist=12
title = ax.set_title('Epoch 0')首先为了创建3D绘图,要在“ w”和“ b”的最小值和最大值之间创建256个相等间隔的值来创建网格,如第2-5行所示。使用网格通过调用Sigmoid类中的error函数来计算这些值的误差(第5行)SN。在第8行创建轴手柄以创建三维绘图。
为了创建3D绘图,使用ax.plot_surface函数,通过设置rstride和cstride,指定采样点和数据的频率,创建关于权重和误差的表面图。接下来,使用ax.contourf函数,通过将误差值指定为“ Z”方向(第9-10行),在表面顶部绘制相对于权重和偏差的误差轮廓。在11-16行中,为每个轴设置标签,并为所有三维设置轴限。正在绘制三维绘图,所以需要定义视点。在第17–18行中为绘图设置了一个视点,该视点在“ z”轴上的高度为25度,距离为12个单位。
def plot_animate_3d(i):
i = int(i*(epochs/animation_frames))
line1.set_data(sn.w_h[:i+1], sn.b_h[:i+1])
line1.set_3d_properties(sn.e_h[:i+1])
line2.set_data(sn.w_h[:i+1], sn.b_h[:i+1])
line2.set_3d_properties(np.zeros(i+1) - 1)
title.set_text('Epoch: {: d}, Error: {:.4f}'.format(i, sn.e_h[i]))
return line1, line2, title
if plot_3d:
#animation plots of gradient descent
i = 0
line1, = ax.plot(sn.w_h[:i+1], sn.b_h[:i+1], sn.e_h[:i+1], color='black',marker='.')
line2, = ax.plot(sn.w_h[:i+1], sn.b_h[:i+1], np.zeros(i+1) - 1, color='red', marker='.')
anim = animation.FuncAnimation(fig, func=plot_animate_3d, frames=animation_frames)
rc('animation', html='jshtml')
anim基于静态三维绘图,想要可视化该算法的动态操作,该操作是由用于参数和误差函的历史变量在算法的各个时期捕获。要创建梯度下降算法的动画,将使用通过传递自定义函数plot_animate_3d作为参数之一的animation.FuncAnimation函数,并指定创建动画所需的帧数。plot_animate_3d函数plot_animate_3d为“ w”和“ b”的相应值更新参数值和误差值。在第7行的相同函数中,将文本设置为显示该特定时期的误差值。最后,为了在线显示动画,调用rc函数以在jupyter笔记本中呈现HTML内容。
类似于三维绘图,可以创建一个函数用以绘制二维等高线图。
if plot_2d:
W = np.linspace(w_min, w_max, 256)
b = np.linspace(b_min, b_max, 256)
WW, BB = np.meshgrid(W, b)
Z = sn.error(X, Y, WW, BB)
fig = plt.figure(dpi=100)
ax = plt.subplot(111)
ax.set_xlabel('w')
ax.set_xlim(w_min - 1, w_max + 1)
ax.set_ylabel('b')
ax.set_ylim(b_min - 1, b_max + 1)
title = ax.set_title('Epoch 0')
cset = plt.contourf(WW, BB, Z, 25, alpha=0.8, cmap=cm.bwr)
plt.savefig("temp.jpg",dpi = 2000)
plt.show()
def plot_animate_2d(i):
i = int(i*(epochs/animation_frames))
line.set_data(sn.w_h[:i+1], sn.b_h[:i+1])
title.set_text('Epoch: {: d}, Error: {:.4f}'.format(i, sn.e_h[i]))
return line, title
if plot_2d:
i = 0
line, = ax.plot(sn.w_h[:i+1], sn.b_h[:i+1], color='black',marker='.')
anim = animation.FuncAnimation(fig, func=plot_animate_2d, frames=animation_frames)
rc('animation', html='jshtml')
anim算法的实现
本节将实现梯度下降算法的不同变体,并生成三维和二维动画图。
Vanilla梯度下降
梯度下降算法是通过向相对于网络参数的目标函数梯度的相反方向移动来更新参数。
参数更新规则由下式给出:

梯度下降更新规则:
for i in range(epochs):
dw, db = 0, 0
for x, y in zip(X, Y):
dw += self.grad_w(x, y)
db += self.grad_b(x, y)
self.w -= eta * dw / X.shape[0]
self.b -= eta * db / X.shape[0]
self.append_log()在批量梯度下降中,迭代所有训练数据点,并计算参数“ w”和“ b”的梯度累积和。然后根据累积梯度值和学习率更新参数值。
要执行梯度下降算法,请如下所示更改配置设置。
X = np.asarray([0.5, 2.5])
Y = np.asarray([0.2, 0.9])
algo = 'GD'
w_init = -2
b_init = -2
w_min = -7
w_max = 5
b_min = -7
b_max = 5
epochs = 1000
eta = 1
animation_frames = 20
plot_2d = True
plot_3d = True在配置设置中,设置变量algo 为‘GD’,表明在sigmoid神经元中执行vanilla梯度下降算法,以便找到最佳参数值。设置好配置参数后,将继续执行SN类“fit”法,训练小型数据上的sigmoid神经元。
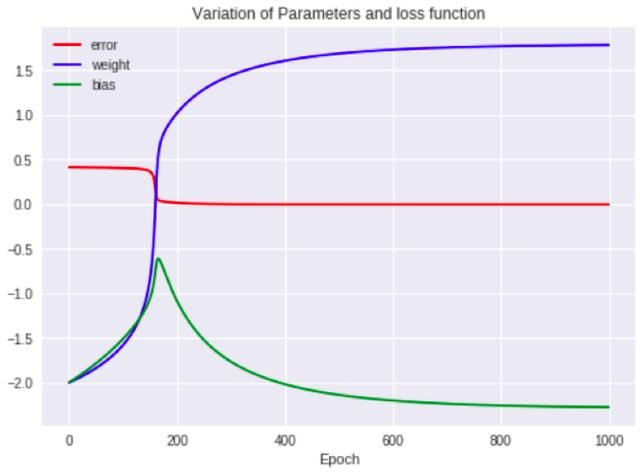
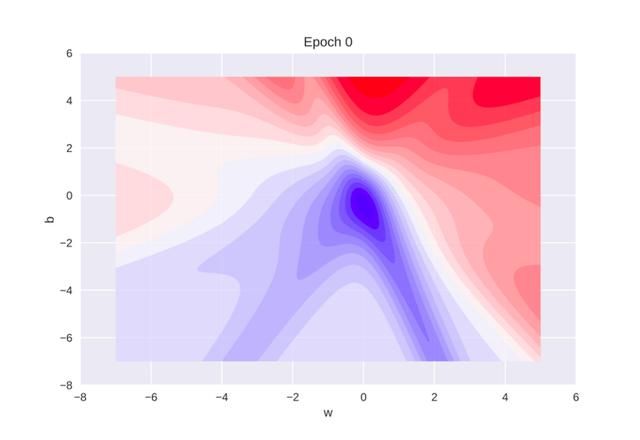
梯度下降的历史
上图显示了在算法学习最佳参数的同时,误差、权重和偏差的历史值在不同阶段之间的变化方式。图中需要注意的关键一点是,在初始阶段,误差值徘徊在0.5左右,但在200个阶段后,误差几乎达到零。
如果想要绘制三维或二维动画,则可以设置布尔变量plot_2d和 plot_3d。展示三维误差面在对应值“w”和“b”下的外观。学习算法的目标是向误差/损失最小的深蓝色区域移动。
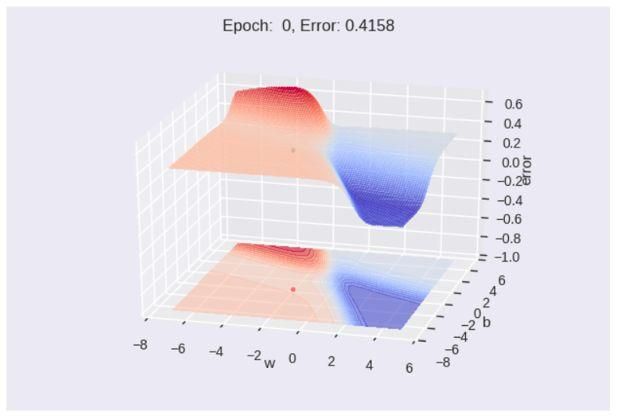
为了可视化动态执行的算法,可以使用函数plot_animate_3d生成动画。播放动画时,可以看到该阶段的编号和相应的误差值。
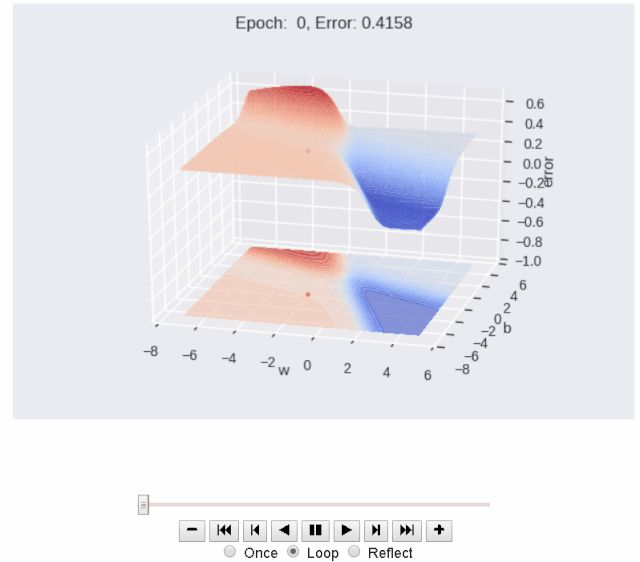
如果想要放慢动画的速度,可以通过单击视频控件中的减号来实现,如上动画所示。同样,可以为二维等高线图生成动画,以查看算法如何向全局最小值移动。
基于Momentum的梯度下降
在Momentum GD中,以先前梯度和当前梯度指数衰减的累积平均值移动。

Momentum GD的代码如下:
v_w, v_b = 0, 0
for i in range(epochs):
dw, db = 0, 0
for x, y in zip(X, Y):
dw += self.grad_w(x, y)
db += self.grad_b(x, y)
v_w = gamma * v_w + eta * dw
v_b = gamma * v_b + eta * db
self.w = self.w - v_w
self.b = self.b - v_b
self.append_log()基于Momentum GD,涵盖了历史变量,以便跟踪先前的梯度值。变量gamma表示需要给算法施加多少Momentum。变量v_w和 v_b用来计算基于历史记录和当前梯度的运动。在每个阶段结束时,调用append_log函数来存储参数和损失函数值的历史记录。
为sigmoid神经元执行Momentum GD,需要修改配置设置,如下所示:
X = np.asarray([0.5, 2.5])
Y = np.asarray([0.2, 0.9])
algo = 'Momentum'
w_init = -2
b_init = -2
w_min = -7
w_max = 5
b_min = -7
b_max = 5
epochs = 1000
mini_batch_size = 6
gamma = 0.9
eta = 1
animation_frames = 20
plot_2d = True
plot_3d = True变量algo被设置为“Momentum”,以示想要使用Momentum GD为sigmoid神经元找到最佳参数;另一个重要的变化是gamma变量,该变量用于控制在学习算法中Momentum的所需量。Gamma值在0-1之间变化。设置好配置参数后,将继续执行SN类“ fit”法来训练toy数据上的sigmoid神经元。
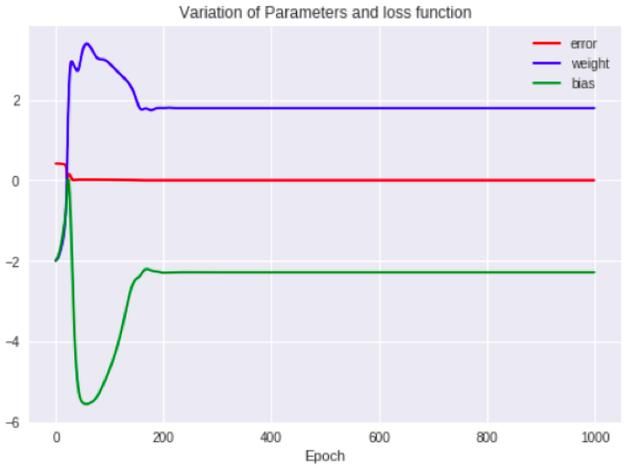
Momentum GD的变化
由图可见,累积的历史Momentum GD在极小值内外波动,权重和偏差项的值也出现了一些波动。
Nesterov加速梯度下降
在Nesterov加速梯度下降过程中,希望在根据当前梯度值采取另一步骤之前,了解是否接近最小值,从而避免出现过冲问题。

Momentum GD的代码如下:
v_w, v_b = 0, 0
for i in range(epochs):
dw, db = 0, 0
v_w = gamma * v_w
v_b = gamma * v_b
for x, y in zip(X, Y):
dw += self.grad_w(x, y, self.w - v_w, self.b - v_b)
db += self.grad_b(x, y, self.w - v_w, self.b - v_b)
v_w = v_w + eta * dw
v_b = v_b + eta * db
self.w = self.w - v_w
self.b = self.b - v_b
self.append_log()NAG GD代码的主要变化是v_w和 v_b的计算。在Momentum GD中,一步完成这些变量的计算,但在NAG中,分两个步骤进行计算。
v_w = gamma * v_w
v_b = gamma * v_b
for x, y in zip(X, Y):
dw += self.grad_w(x, y, self.w - v_w, self.b - v_b)
db += self.grad_b(x, y, self.w - v_w, self.b - v_b)
v_w = v_w + eta * dw
v_b = v_b + eta * db第一部分中,在遍历数据之前,将gamma与历史变量相乘,然后使用self.w和 self.b中减去的历史值来计算梯度。只需要设置algo变量为“NAG”。可以生成三维或二维动画,以查看NAG GD与Momentum GD在达到全局最小值方面有何差异。
Mini-Batch and Stochastic梯度下降
无需一次查看所有数据点,将整个数据分为多个子集。针对数据的每个子集,计算子集中存在的每个点的导数,并更新参数。不存在针对损失函数计算整个数据的导数,而是将其近似为更少的点或较小的mini-batch size。这种批量计算梯度的方法称为 “ Mini-Batch 梯度下降”。
Mini-Batch GD的代码如下所示:
for i in range(epochs):
dw, db = 0, 0
points_seen = 0
for x, y in zip(X, Y):
dw += self.grad_w(x, y)
db += self.grad_b(x, y)
points_seen += 1
if points_seen % mini_batch_size == 0:
self.w -= eta * dw / mini_batch_size
self.b -= eta * db / mini_batch_size
self.append_log()
dw, db = 0, 0在Mini Batch中,遍历整个数据并使用变量points_seen跟踪已看到的点数。如果看到的点数是mini-batch size 的倍数,那么是正在更新sigmoid神经元的参数。在特殊情况下,当mini-batch size等于1时,它将成为随机梯度下降。要执行Mini-Batch GD,只需要将算法变量设置为“MiniBatch”。可以生成3D或2D动画,以了解Mini-Batch GD在达到全局最小值方面与Momentum GD有何差异。
AdaGrad梯度下降
AdaGrad隐藏的主要动机是针对数据集中不同特征的自适应学习率,即不是针对数据集中所有特征,使用相同的学习率,而是不同特征采用不同学习率。
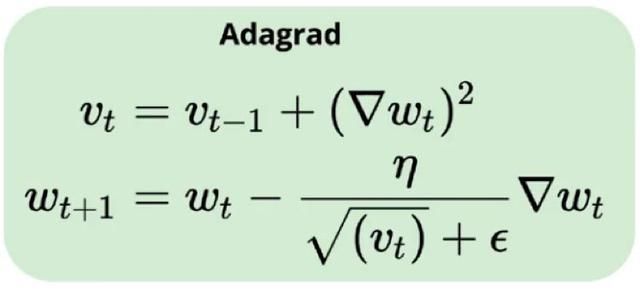
Adagrad的代码如下所示:
v_w, v_b = 0, 0
for i in range(epochs):
dw, db = 0, 0
for x, y in zip(X, Y):
dw += self.grad_w(x, y)
db += self.grad_b(x, y)
v_w += dw**2
v_b += db**2
self.w -= (eta / np.sqrt(v_w) + eps) * dw
self.b -= (eta / np.sqrt(v_b) + eps) * db
self.append_log()在Adagrad中,保持梯度的平方和,然后将学习率除以历史值的平方根更新参数。这里并非静态学习,而是密集和稀疏型的动态学习。生成图/动画的机制与上文相同。此处的想法是使用不同的toy数据集和不同的超参数配置。
RMSProp梯度下降
在RMSProp中,不同于AdaGrad中的梯度总和,梯度历史是根据指数衰减的平均值计算的,这有助于防止密集型的分母快速增长。

RMSProp的代码如下所示:
v_w, v_b = 0, 0
for i in range(epochs):
dw, db = 0, 0
for x, y in zip(X, Y):
dw += self.grad_w(x, y)
db += self.grad_b(x, y)
v_w = beta * v_w + (1 - beta) * dw**2
v_b = beta * v_b + (1 - beta) * db**2
self.w -= (eta / np.sqrt(v_w) + eps) * dw
self.b -= (eta / np.sqrt(v_b) + eps) * db
self.append_log()在AdaGrad代码中唯一的更改是更新变量v_w和 v_b的方式。在AdaGrad中,v_w和v_b,从第一阶段开始,总是按每个参数的梯度平方递增,但在RMSProp 中,v_w和 v_b是使用“gamma”的超参数指数衰减的梯度加权和。要执行RMSProp GD,只需将algo变量设置为“RMSProp”。可以生成3D或2D动画,以查看RMSProp GD在达到全局最小值方面与 AdaGrad GD有何差异。
Adam梯度下降
Adam 拥有两个历史记录,“mₜ”和Momentum GD中使用的历史类似,“vₜ”和RMSProp中使用的历史类似。

在运作中,Adam执行偏差校正。它对“mₜ”和“vₜ”使用以下等式:
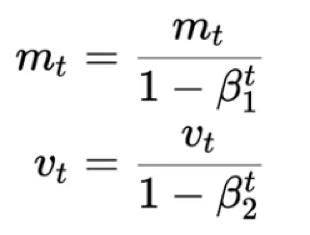
偏差校正
偏差校正可确保在训练开始时不会出现怪异的行为。Adam的要点是,它结合了Momentum GD(在温和地区移动更快)和RMSProp GD(调整学习率)的优势。
Adam GD的代码如下所示:
v_w, v_b = 0, 0
m_w, m_b = 0, 0
num_updates = 0
for i in range(epochs):
dw, db = 0, 0
for x, y in zip(X, Y):
dw = self.grad_w(x, y)
db = self.grad_b(x, y)
num_updates += 1
m_w = beta1 * m_w + (1-beta1) * dw
m_b = beta1 * m_b + (1-beta1) * db
v_w = beta2 * v_w + (1-beta2) * dw**2
v_b = beta2 * v_b + (1-beta2) * db**2
m_w_c = m_w / (1 - np.power(beta1, num_updates))
m_b_c = m_b / (1 - np.power(beta1, num_updates))
v_w_c = v_w / (1 - np.power(beta2, num_updates))
v_b_c = v_b / (1 - np.power(beta2, num_updates))
self.w -= (eta / np.sqrt(v_w_c) + eps) * m_w_c
self.b -= (eta / np.sqrt(v_b_c) + eps) * m_b_c
self.append_log()在Adam优化器中,计算m_w & m_b来跟踪momentum 历史,并计算v_w & v_b以衰减分母并阻止其快速增长,就像在RMSProp中一样。
之后,对基于Momentum和RMSProp的历史变量实施偏差校正。一旦计算出参数“ w”和“ b”的校正值,将使用这些值来更新参数值。
执行Adam梯度下降算法,请如下所示更改配置设置。
X = np.asarray([3.5, 0.35, 3.2, -2.0, 1.5, -0.5])
Y = np.asarray([0.5, 0.50, 0.5, 0.5, 0.1, 0.3])
algo = 'Adam'
w_init = -6
b_init = 4.0
w_min = -7
w_max = 5
b_min = -7
b_max = 5
epochs = 200
gamma = 0.9
eta = 0.5
eps = 1e-8
animation_frames = 20
plot_2d = True
plot_3d = False变量algo被设置为“Adam”,表示使用Adam GD为sigmoid神经元找到最佳参数;另一个重要的变化是gamma 变量,该变量用于控制学习算法所需的momentum。Gamma值在0-1之间变化。设置配置参数后,将继续执行SN类“ fit”法以训练toy数据上的sigmoid神经元。
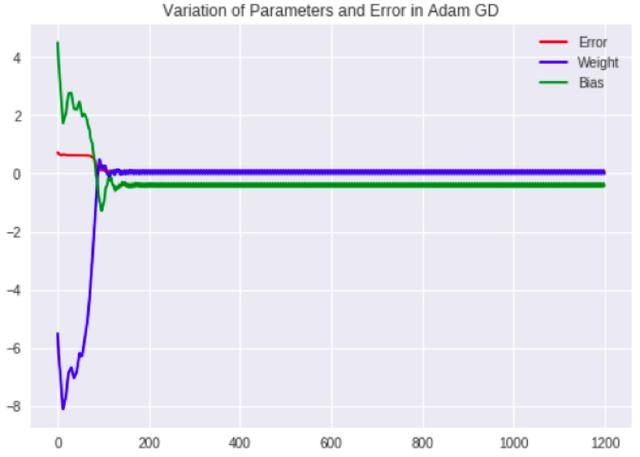
Adam GD中的参数变化
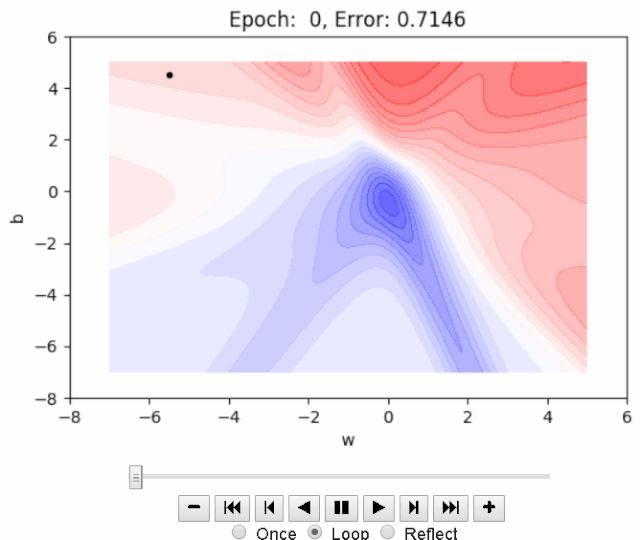
创建2D等高线动画,该动画显示Adam GD学习通向全局极小值的路径的方式。
Adam GD动画
不同于RMSProp案例,没有太多波动。尤其在最初几个阶段之后,更加确定地朝着最小值移动。
关于如何使用Numpy实现优化技术的讨论到此结束。
实践学习
本文中介绍了不同的情况,使用了带有静态初始化点的toy数据集。但是可以使用不同的初始化点,并针对每个初始化点,使用不同的算法,看看在超参数中需要进行何种调整。本文讨论的全部代码都在GitHub存储库中。随意分类或下载。最棒的是,可以直接在google colab中运行代码,而不必担心安装软件包。
https://github.com/Niranjankumar-c/GradientDescent_Implementation?source=post_page-----809e7ab3bab4----------------------
综上所述,本文介绍了如何通过采取简单的sigmoid神经元实现梯度算法的不同变种。此外,还了解了如何为每个变体(显示学习算法如何找到最佳参数)创建精美的3D或2D动画。