DeepFM
DeepFM
- 简介
- 具体结构
- 代码
简介
DeepFM是2017年华为若亚方舟团队提出的一个将FM与DNN有效结合的模型,主要借鉴Google的Wide&Deep论文的思想并进行适当改进,将其中wide部分(logistic回归)换成FM与DNN进特征交叉。wide和deep部分共享原始输入特征向量,这让DeepFM可以直接从原始特征中同时学习低阶和高阶特征交叉,因此不像Wide&Deep模型那样,需要进行复杂的人工特征工程(logistic回归部分需要人工特征工程),同时训练效率会更高(DeepFM的网络结构参考下图)。
该算法从提出后,被工业界大量用于广告点击预估和推荐系统(如美团将DeepFM用于CTR预估),有非常不错的效果。该团队在参考文献5中进一步对DeepFM两种变种进行了比较,并在华为的应用市场APP推荐真实业务场景中做AB测试,发现比原来的LR算法有近10%的点击率提升。
腾讯开源的Angel(Spark on Angel)中有DeepFM的实现,读者可以尝试将DeepFM应用到自己的推荐或者CTR预估业务中。
由于DeepFM算法有效的结合了因子分解机与神经网络在特征学习中的优点:同时提取到低阶组合特征与高阶组合特征,所以越来越被广泛使用。
具体结构

其中,DeepFM的输入可由连续型变量和类别型变量共同组成,且类别型变量需要进行One-Hot编码。而正由于One-Hot编码,导致了输入特征变得高维且稀疏。
应对的措施是:针对高维稀疏的输入特征,采用Word2Vec的词嵌入(WordEmbedding)思想,把高维稀疏的向量映射到相对低维且向量元素都不为零的空间向量中。
实际上,这个过程就是FM算法中交叉项计算的过程,由上面网络结构图可以看到,DeepFM 包括 FM和 DNN两部分,所以模型最终的输出也由这两部分组成:

把结构图进行拆分。首先是FM部分的结构:
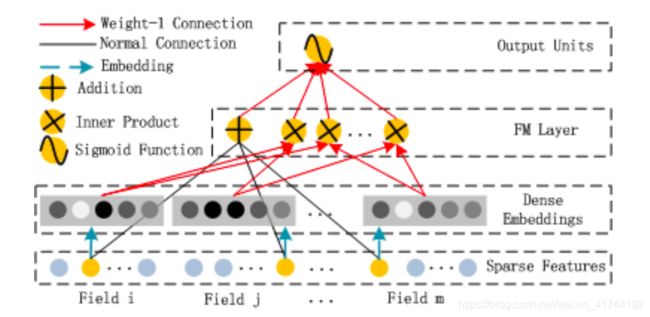
FM 部分的输出如下:

这里需要注意三点:
- 这里的wij,也就是
- 由于输入特征one-hot编码,所以embedding vector也就是输入层到Dense Embeddings层的权重
- Embeddings层的神经元个数是由embedding vector和field_size共同确定,再直白一点就是:神经元的个数为embedding vector*field_size。
然后是DNN部分的结构:
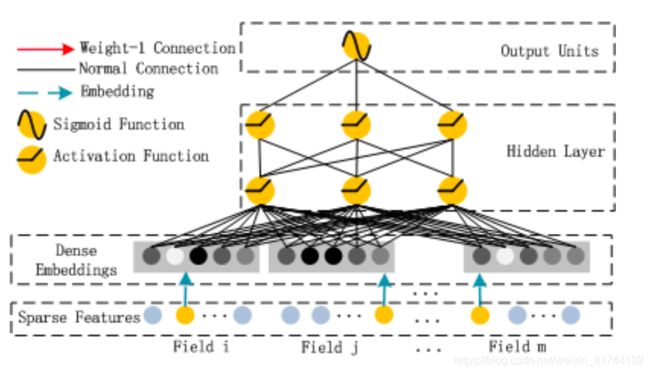
这里DNN的作用是构造高维特征,且有一个特点:DNN的输入也是embedding vector。所谓的权值共享指的就是这里。
关于DNN网络中的输入a处理方式采用前向传播,如下所示:

这里假设a(0)=(e1,e2,…em) 表示 embedding层的输出,那么a(0)作为下一层 DNN隐藏层的输入,其前馈过程如下。

代码
import os
import sys
import numpy as np
import tensorflow as tf
from build_data import load_data
BASE_PATH = os.path.dirname(os.path.dirname(__file__))
class Args():
feature_sizes = 100
field_size = 15
embedding_size = 256
deep_layers = [512, 256, 128]
epoch = 3
batch_size = 64
# 1e-2 1e-3 1e-4
learning_rate = 1.0
# 防止过拟合
l2_reg_rate = 0.01
checkpoint_dir = os.path.join(BASE_PATH, 'data/saver/ckpt')
is_training = True
class model():
def __init__(self, args):
self.feature_sizes = args.feature_sizes
self.field_size = args.field_size
self.embedding_size = args.embedding_size
self.deep_layers = args.deep_layers
self.l2_reg_rate = args.l2_reg_rate
self.epoch = args.epoch
self.batch_size = args.batch_size
self.learning_rate = args.learning_rate
self.deep_activation = tf.nn.relu
self.weight = dict()
self.checkpoint_dir = args.checkpoint_dir
self.build_model()
def build_model(self):
self.feat_index = tf.placeholder(tf.int32, shape=[None, None], name='feature_index')
self.feat_value = tf.placeholder(tf.float32, shape=[None, None], name='feature_value')
self.label = tf.placeholder(tf.float32, shape=[None, None], name='label')
# One-hot编码后的输入层与Dense embeddings层的权值定义,即DNN的输入embedding。注:Dense embeddings层的神经元个数由field_size和决定
self.weight['feature_weight'] = tf.Variable(
tf.random_normal([self.feature_sizes, self.embedding_size], 0.0, 0.01),
name='feature_weight')
# FM部分中一次项的权值定义
# shape (61,1)
self.weight['feature_first'] = tf.Variable(
tf.random_normal([self.feature_sizes, 1], 0.0, 1.0),
name='feature_first')
# deep网络部分的weight
num_layer = len(self.deep_layers)
# deep网络初始输入维度:input_size = 39x256 = 9984 (field_size(原始特征个数)*embedding个神经元)
input_size = self.field_size * self.embedding_size
init_method = np.sqrt(2.0 / (input_size + self.deep_layers[0]))
# shape (9984,512)
self.weight['layer_0'] = tf.Variable(
np.random.normal(loc=0, scale=init_method, size=(input_size, self.deep_layers[0])), dtype=np.float32
)
# shape(1, 512)
self.weight['bias_0'] = tf.Variable(
np.random.normal(loc=0, scale=init_method, size=(1, self.deep_layers[0])), dtype=np.float32
)
# 生成deep network里面每层的weight 和 bias
if num_layer != 1:
for i in range(1, num_layer):
init_method = np.sqrt(2.0 / (self.deep_layers[i - 1] + self.deep_layers[i]))
# shape (512,256) (256,128)
self.weight['layer_' + str(i)] = tf.Variable(
np.random.normal(loc=0, scale=init_method, size=(self.deep_layers[i - 1], self.deep_layers[i])),
dtype=np.float32)
# shape (1,256) (1,128)
self.weight['bias_' + str(i)] = tf.Variable(
np.random.normal(loc=0, scale=init_method, size=(1, self.deep_layers[i])),
dtype=np.float32)
# deep部分output_size + 一次项output_size + 二次项output_size 423
last_layer_size = self.deep_layers[-1] + self.field_size + self.embedding_size
init_method = np.sqrt(np.sqrt(2.0 / (last_layer_size + 1)))
# 生成最后一层的结果
self.weight['last_layer'] = tf.Variable(
np.random.normal(loc=0, scale=init_method, size=(last_layer_size, 1)), dtype=np.float32)
self.weight['last_bias'] = tf.Variable(tf.constant(0.01), dtype=np.float32)
# embedding_part
# shape (?,?,256)
self.embedding_index = tf.nn.embedding_lookup(self.weight['feature_weight'],
self.feat_index) # Batch*F*K
# shape (?,39,256)
self.embedding_part = tf.multiply(self.embedding_index,
tf.reshape(self.feat_value, [-1, self.field_size, 1]))
# [Batch*F*1] * [Batch*F*K] = [Batch*F*K],用到了broadcast的属性
print('embedding_part:', self.embedding_part)
"""
网络传递结构
"""
# FM部分
# 一阶特征
# shape (?,39,1)
self.embedding_first = tf.nn.embedding_lookup(self.weight['feature_first'],
self.feat_index) # bacth*F*1
self.embedding_first = tf.multiply(self.embedding_first, tf.reshape(self.feat_value, [-1, self.field_size, 1]))
# shape (?,39)
self.first_order = tf.reduce_sum(self.embedding_first, 2)
print('first_order:', self.first_order)
# 二阶特征
self.sum_second_order = tf.reduce_sum(self.embedding_part, 1)
self.sum_second_order_square = tf.square(self.sum_second_order)
print('sum_square_second_order:', self.sum_second_order_square)
self.square_second_order = tf.square(self.embedding_part)
self.square_second_order_sum = tf.reduce_sum(self.square_second_order, 1)
print('square_sum_second_order:', self.square_second_order_sum)
# 1/2*((a+b)^2 - a^2 - b^2)=ab
self.second_order = 0.5 * tf.subtract(self.sum_second_order_square, self.square_second_order_sum)
# FM部分的输出(39+256)
self.fm_part = tf.concat([self.first_order, self.second_order], axis=1)
print('fm_part:', self.fm_part)
# DNN部分
# shape (?,9984)
self.deep_embedding = tf.reshape(self.embedding_part, [-1, self.field_size * self.embedding_size])
print('deep_embedding:', self.deep_embedding)
# 全连接部分
for i in range(0, len(self.deep_layers)):
self.deep_embedding = tf.add(tf.matmul(self.deep_embedding, self.weight["layer_%d" % i]),
self.weight["bias_%d" % i])
self.deep_embedding = self.deep_activation(self.deep_embedding)
# FM输出与DNN输出拼接
din_all = tf.concat([self.fm_part, self.deep_embedding], axis=1)
self.out = tf.add(tf.matmul(din_all, self.weight['last_layer']), self.weight['last_bias'])
print('output:', self.out)
# loss部分
self.out = tf.nn.sigmoid(self.out)
self.loss = -tf.reduce_mean(
self.label * tf.log(self.out + 1e-24) + (1 - self.label) * tf.log(1 - self.out + 1e-24))
# 正则:sum(w^2)/2*l2_reg_rate
# 这边只加了weight,有需要的可以加上bias部分
self.loss += tf.contrib.layers.l2_regularizer(self.l2_reg_rate)(self.weight["last_layer"])
for i in range(len(self.deep_layers)):
self.loss += tf.contrib.layers.l2_regularizer(self.l2_reg_rate)(self.weight["layer_%d" % i])
self.global_step = tf.Variable(0, trainable=False)
opt = tf.train.GradientDescentOptimizer(self.learning_rate)
trainable_params = tf.trainable_variables()
print(trainable_params)
gradients = tf.gradients(self.loss, trainable_params)
clip_gradients, _ = tf.clip_by_global_norm(gradients, 5)
self.train_op = opt.apply_gradients(
zip(clip_gradients, trainable_params), global_step=self.global_step)
def train(self, sess, feat_index, feat_value, label):
loss, _, step = sess.run([self.loss, self.train_op, self.global_step], feed_dict={
self.feat_index: feat_index,
self.feat_value: feat_value,
self.label: label
})
return loss, step
def predict(self, sess, feat_index, feat_value):
result = sess.run([self.out], feed_dict={
self.feat_index: feat_index,
self.feat_value: feat_value
})
return result
def save(self, sess, path):
saver = tf.train.Saver()
saver.save(sess, save_path=path)
def restore(self, sess, path):
saver = tf.train.Saver()
saver.restore(sess, save_path=path)
def get_batch(Xi, Xv, y, batch_size, index):
start = index * batch_size
end = (index + 1) * batch_size
end = end if end < len(y) else len(y)
return Xi[start:end], Xv[start:end], np.array(y[start:end])
if __name__ == '__main__':
args = Args()
data = load_data()
args.feature_sizes = data['feat_dim']
args.field_size = len(data['xi'][0])
args.is_training = True
with tf.Session() as sess:
Model = model(args)
# init variables
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
cnt = int(len(data['y_train']) / args.batch_size)
print('time all:%s' % cnt)
sys.stdout.flush()
if args.is_training:
for i in range(args.epoch):
print('epoch %s:' % i)
for j in range(0, cnt):
X_index, X_value, y = get_batch(data['xi'], data['xv'], data['y_train'], args.batch_size, j)
loss, step = Model.train(sess, X_index, X_value, y)
if j % 100 == 0:
print('the times of training is %d, and the loss is %s' % (j, loss))
Model.save(sess, args.checkpoint_dir)
else:
Model.restore(sess, args.checkpoint_dir)
for j in range(0, cnt):
X_index, X_value, y = get_batch(data['xi'], data['xv'], data['y_train'], args.batch_size, j)
result = Model.predict(sess, X_index, X_value)
print(result)