8月4日Pytorch笔记——RNN、LSTM
文章目录
- 前言
- 一、CIFAR10 & ResNet18 实战
- 二、循环神经网络 RNN
-
- 1、Layer 使用
- 2、时间序列预测
- 3、Gradient Exploding & Gradient Vanishing
- 三、LSTM
-
- 1、遗忘门 forget gate
- 2、输入门 input gate
- 3、输出门 output
- 4、LSTM 的使用
前言
本文为8月4日Pytorch笔记,分为三个章节:
- CIFAR10 & ResNet18 实战;
- 循环神经网络 RNN:Layer 使用、时间序列预测、Gradient Exploding & Gradient Vanishing;
- LSTM:遗忘门 forget gate、输入门 input gate、输出门 output、LSTM 的使用。
一、CIFAR10 & ResNet18 实战
- LeNet5:
import torch
from torch import nn
from torch.nn import functional as F
class Lenet5(nn.Module):
''' for CIFAR10 dataset '''
def __init__(self):
super(Lenet5, self).__init__()
self.conv_unit = nn.Sequential(
# x: [b, 3, 32, 32] ==> [b, 3, ]
nn.Conv2d(3, 6, kernel_size=5, stride=1, padding=0),
nn.AvgPool2d(kernel_size=2, stride=2, padding=0),
#
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.AvgPool2d(kernel_size=2, stride=2, padding=0),
#
)
# flatten
# fc unit
self.fc_unit = nn.Sequential(
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, 10)
)
# [b, 3, 32, 32]
tmp = torch.randn(2, 3, 32, 32)
out = self.conv_unit(tmp)
# [b, 16, 5, 5]
print('conv out: ', out.shape)
# use Cross Entropy Loss
# self.criteon = nn.MSELoss()
# self.criteon = nn.CrossEntropyLoss()
def forward(self, x):
'''
:param x: [b, 3, 32, 32]
:return:
'''
batch_size = x.size(0)
# [b, 3, 32, 32] ==> [b, 16, 5, 5]
x = self.conv_unit(x)
# [b, 16, 5, 5] ==> [b, 16*5*5]
x = x.view(batch_size, 16*5*5)
# [b, 16*5*5] ==> [b, 10]
logits = self.fc_unit(x)
# [b, 10]
# pred = F.softmax(logits, dim=1)
# loss = self.criteon(logits, y)
return logits
def main():
net = Lenet5()
tmp = torch.randn(2, 3, 32, 32)
out = net(tmp)
# [b, 16, 5, 5]
print('conv out: ', out.shape)
if __name__ == '__main__':
main()
- ResNet18:
import torch
from torch import nn
from torch.nn import functional as F
class ResBlk(nn.Module):
''' resnet block '''
def __init__(self, ch_in, ch_out, stride=1):
'''
:param ch_in:
:param ch_out:
'''
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
# [b, ch_in, h, w] ==> [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
'''
:param x: [b, ch, h, w]
:return:
'''
out = F.relu(self.bn1(self.conv1(x)))
out = F.bn2(self.conv2(out))
# short cut
# extra module: [b, ch_in, h, w] ==> [b, ch_out, h, w]
# element-wise add:
out = self.extra(x) + out
return out
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=1),
nn.BatchNorm2d(64)
)
# followed 4 blocks
# [b, 64, h, w] ==> [b, 128, h, w]
self.blk1 = ResBlk(64, 128, stride=2)
# [b, 128, h, w] ==> [b, 256, h, w]
self.blk2 = ResBlk(128, 256, stride=2)
# [b, 256, h, w] ==> [b, 512, h, w]
self.blk3 = ResBlk(256, 512, stride=2)
# [b, 512, h, w] ==> [b, 1024, h, w]
self.blk4 = ResBlk(512, 512, stride=2)
print('after conv: ', x.shape) # [b, 512, 2, 2]
# [b, 512, h, w] ==> [b, 512, 1, 1]
x = F.adaptive_avg_pool2d(x, [1, 1])
print('after pool: ', x.shape)
x = x.view(x.size(0), -1)
self.outlayer = nn.Linear(512, 10)
def forward(self, x):
'''
:param x:
:return:
'''
x = F.relu(self.conv1(x))
# [b, 64, h, w] ==> [b, 1024, h, w]
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
x = self.outlayer(x)
return x
def main():
blk = ResBlk(64, 128, stride=4)
tmp = torch.rand(2, 64, 32, 32)
out = blk(tmp)
print(out.shape)
x = torch.rand(2, 3, 32, 32)
model = ResNet18()
out = model(x)
print('resnet: ', out.shape)
if __name__ == "__main__":
main()
- Main:
import torch
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn, optim
from test_LeNet5 import Lenet5
from test_ResNet import ResNet18
def main():
batch_size = 32
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize([32, 32]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_train = DataLoader(cifar_train, batch_size=batch_size, shuffle=True)
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize([32, 32]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batch_size, shuffle=True)
x, label = iter(cifar_train).next()
print('x: ', x.shape, 'label: ', label.shape)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Lenet5().to(device)
# model = ResNet18().to(device)
criteon = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
for epoch in range(1000):
model.train()
for batchidx, (x, label) in enumerate(cifar_train):
# x: [b, 3, 32, 32]
# label: [b]
x, label = x.to(device), label.to(device)
logits = model(x)
# logits: [b, 10]
# label: [b]
# loss: tesor scalar
loss = criteon(logits, label)
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
#
print(epoch, loss.item())
model.eval()
with torch.no_grad():
# test
total_correct = 0
total_num = 0
for x, label in cifar_test:
# x: [b, 3, 32, 32]
# label: [b]
x, label = x.to(device), label.to(device)
# [b, 10]
logits = model(x)
# [b]
pred = logits.argmax(dim=1)
# [b] vs. [b] ==> scalar tensor
total_correct += torch.eq(pred, label).float().sum().item()
total_num += x.size(0)
acc = total_correct / total_num
print(epoch, acc)
if __name__ == '__main__':
main()
二、循环神经网络 RNN

h t = f W ( h t − 1 , x t ) = h t = t a n h ( W h h h t − 1 + W x h x t ) y t = W h y h t h_t = f_W(h_{t-1, x_t}) = h_t = tanh(W_{hh} h_{t-1} + W_{xh} x_t)\\ y_t = W_{hy} h_t ht=fW(ht−1,xt)=ht=tanh(Whhht−1+Wxhxt)yt=Whyht
- Training:
∂ E t ∂ W R = ∑ i = 0 t ∂ E t ∂ y t ∂ y t ∂ h t ∂ h t ∂ h i ∂ h i ∂ W R ∂ h t ∂ h i = ∏ k = i t − 1 ∂ h k + 1 ∂ h k \frac{\partial E_t}{\partial W_R} = \sum_{i=0}^{t}\frac{\partial E_t}{\partial y_t}\frac{\partial y_t}{\partial h_t} \frac{\partial h_t}{\partial h_i}\frac{\partial h_i}{\partial W_R} \\ \frac{\partial h_t}{\partial h_i} = \prod_{k=i}^{t-1}\frac{\partial h_{k+1}}{\partial h_k} ∂WR∂Et=i=0∑t∂yt∂Et∂ht∂yt∂hi∂ht∂WR∂hi∂hi∂ht=k=i∏t−1∂hk∂hk+1
1、Layer 使用
rnn = nn.RNN(100, 10)
rnn_parameters.keys()
rnn.weight_hh_l0.shape, rnn.weight_ih_l0.shape
>>> (torch.Size([10, 10]), torch.Size([10, 100]))
rnn.bias_hh_l0.shape, rnn.bias_ih_l0.shape
>>> (torch.Size([10]), torch.Size([10]))
- Single layer RNN:
rnn = nn.RNN(input_size=100, hidden_size=20, num_layers=1)
rnn
>>> RNN(100, 20)
x = torch.rand(10, 3, 100)
out, h = rnn(x, torch.zeros(1, 3, 20))
out.shape, h.shape
>>> (torch.Size([10, 3, 20]), torch.Size([1, 3, 20]))
- 2 layer RNN:
rnn = nn.RNN(100, 10, num_layers=2)
rnn._parameters.keys()
>>> odict_keys(['weight_ih_l0', 'weight_hh_l0', 'bias_ih_l0', 'bias_hh_l0', 'weight_ih_l1', 'weight_hh_l1', 'bias_ih_l1', 'bias_hh_l1'])
rnn.weight_hh_l0.shape, rnn.weight_ih_l0.shape
>>> (torch.Size([10, 10]), torch.Size([10, 100]))
rnn.weight_hh_l1.shape, rnn.weight_ih_l1.shape
>>> (torch.Size([10, 10]), torch.Size([10, 10]))
- nn.RNNCell:
cell1 = nn.RNNCell(100, 30)
cell2 = nn.RNNCell(30, 20)
h1 = torch.zeros(3, 30)
h2 = torch.zeros(3, 20)
for xt in x:
h1 = cell1(xt, h1)
h2 = cell2(h1, h2)
h2.shape
>>> torch.Size([3, 20])
2、时间序列预测
import torch
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn, optim
import numpy as np
# Sample data
start = np.random.randint(3, size=1)[0]
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1].float().view(1, num_time_steps-1, 1))
y = torch.tensor(data[1:].float().view(1, num_time_steps-1, 1))
# Network
class Net(nn.Module):
def __init__(self, ):
super(Net, self).__init__()
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=hidden_size,
num_layers=1,
batch_first=True,
)
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden_prev):
out, hidden_prev = self.rnn(x, hidden_prev)
out = out.view(-1, hidden_size)
out = self.linear(out)
out = out.unsqueeze(dim=0)
return out, hidden_prev
# Train
model = Net()
criteon = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr)
hidden_prev = torch.zeros(1, 1, hidden_size)
for iter in range(6000):
start = np.random.randint(10, size=1)[0]
time_steps = np.linspace(start, start+10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1].float().view(1, num_time_steps-1, 1))
y = torch.tensor(data[1:].float().view(1, num_time_steps - 1, 1))
output, hidden_prev = model(x, hidden_prev)
hidden_prev = hidden_prev.detach()
loss = criteon(output, y)
model.zero_grad()
loss.backward()
optimizer.step()
if iter % 100 == 0:
print('Iteration: {} loss {}'.format(iter, loss.item()))
# Predict
predictions = []
input = x[:, 0, :]
for _ in range(x.shape[1]):
input = input.view(1, 1, 1)
(pred, hidden_prev) = model(input, hidden_prev)
input = pred
predictions.append(pred.detach().numpy().ravel()[0])
3、Gradient Exploding & Gradient Vanishing
∂ h k ∂ h 1 = ∏ i k d i a g ( f ′ ( W 1 x i + W R h i − 1 ) ) W R \frac{\partial h_k}{\partial h_1} = \prod_{i}^{k} diag(f'(W_1x_i + W_Rh_{i-1}))W_R ∂h1∂hk=i∏kdiag(f′(W1xi+WRhi−1))WR
- Gradient Clipping:
loss = criterion(output, y)
model.zero_grad()
loss.backward()
for p in model.parameters():
print(p.grad.norm())
torch.nn.utlis.clip_grad_norm_(p, 10)
optimizer.step()
三、LSTM

1、遗忘门 forget gate

f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = \sigma (W_f\cdot [h_{t-1}, x_t] + b_f) ft=σ(Wf⋅[ht−1,xt]+bf)
2、输入门 input gate
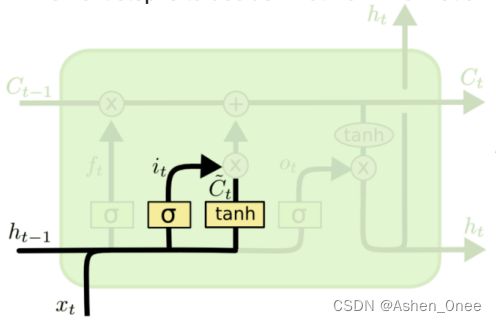
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) C t ~ = t a n h ( W C ⋅ [ h t − 1 , x t ] + b C ) i_t = \sigma (W_i\cdot [h_{t-1}, x_t] + b_i)\\ \tilde{C_t} = tanh(W_C\cdot [h_{t-1}, x_t] + b_C) it=σ(Wi⋅[ht−1,xt]+bi)Ct~=tanh(WC⋅[ht−1,xt]+bC)
3、输出门 output
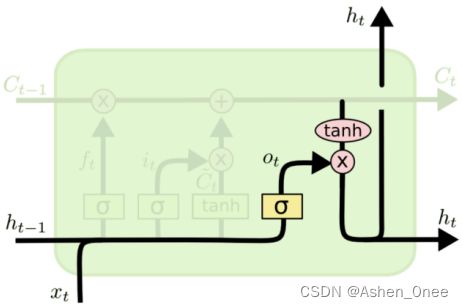
o t = σ ( W o [ h t − 1 , x t ] + b o ) h t = o t ∗ t a n h ( C t ) o_t = \sigma (W_o[h_{t-1}, x_t] + b_o)\\ h_t = o_t * tanh(C_t) ot=σ(Wo[ht−1,xt]+bo)ht=ot∗tanh(Ct)
4、LSTM 的使用
- nn.LSTM:
lstm = nn.LSTM(input_size=100, hidden_size=20, num_layers=4)
print(lstm)
x = torch.rand(10, 3, 100)
out, (h, c) = lstm(x)
print(out.shape, h.shape, c.shape)
>>> LSTM(100, 20, num_layers=4)
>>> torch.Size([10, 3, 20]) torch.Size([4, 3, 20]) torch.Size([4, 3, 20])
- Single layer:
print('one layer LSTM')
cell = nn.LSTMCell(input_size=100, hidden_size=20)
h = torch.zeros(3, 20)
c = torch.zeros(3, 20)
for xt in x:
h, c = cell(xt, [h, c])
print(h.shape, c.shape)
>>> torch.Size([3, 20]) torch.Size([3, 20])
- 2 layers:
print('two layer LSTM')
cell1 = nn.LSTMCell(input_size=100, hidden_size=30)
cell2 = nn.LSTMCell(input_size=30, hidden_size=20)
h1 = torch.zeros(3, 30)
c1 = torch.zeros(3, 30)
h2 = torch.zeros(3, 20)
c2 = torch.zeros(3, 20)
for xt in x:
h1, c1 = cell1(xt, [h1, c1])
h2, c2 = cell2(h1, [h2, c2])
print(h2.shape, c2.shape)
>>> torch.Size([3, 20]) torch.Size([3, 20])