深入学习图像处理——图像相似度算法
最近一段时间学习并做的都是对图像进行处理,其实自己也是新手,各种尝试,所以我这个门外汉想总结一下自己学习的东西,图像处理的流程。但是动起笔来想总结,一下却不知道自己要写什么,那就把自己做过的相似图片搜索的流程整理一下,想到什么说什么吧。
首先在进行图片灰度化处理之前,我觉得有必要了解一下为什么要进行灰度化处理。
图像灰度化的目的是什么?
将彩色图像转化为灰度图像的过程是图像的灰度化处理。彩色图像中的每个像素的颜色由R,G,B三个分量决定,而每个分量有255中值可取,这样一个像素点可以有1600多万(255*255*255)的颜色的变化范围。而灰度图像是R,G,B三个分量相同的一种特殊的彩色图像,其中一个像素点的变化范围为255种,所以在数字图像处理中一般将各种格式的图像转化为灰度图像以使后续的图像的计算量少一些。灰度图像的描述与彩色图像一样仍然反映了整副图像的整体和局部的色度和高亮等级的分布和特征。
一:图像灰度化处理
灰度化处理就是将一幅色彩图像转化为灰度图像的过程。彩色图像分为R,G,B三个分量,分别显示出红绿蓝等各种颜色,灰度化就是使彩色的R,G,B分量相等的过程。灰度值大的像素点比较亮(像素值最大为255,为白色),反之比较暗(像素最下为0,为黑色)。
1.1 图像灰度化的算法:
1)最大值法:使转化后的R,G,B得值等于转化前3个值中最大的一个,即:R=G=B=max(R,G,B)。这种方法转换的灰度图亮度很高。
2)平均值法:是转化后R,G,B的值为转化前R,G,B的平均值。即:R=G=B=(R+G+B)/3。这种方法产生的灰度图像比较柔和。
3)加权平均值法:按照一定权值,对R,G,B的值加权平均,即: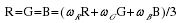 分别为R,G,B的权值,取不同的值形成不同的灰度图像。由于人眼对绿色最为敏感,红色次之,对蓝色的敏感性最低,因此使将得到较易识别的灰度图像。一般时,得到的灰度图像效果最好。
分别为R,G,B的权值,取不同的值形成不同的灰度图像。由于人眼对绿色最为敏感,红色次之,对蓝色的敏感性最低,因此使将得到较易识别的灰度图像。一般时,得到的灰度图像效果最好。
1.2 代码实现(灰度化+二值化)
from PIL import Image
# load a color image
im = Image.open('durant.jpg' )
# convert to grey level image
Lim = im.convert('L' )
Lim.save('grey.jpg' )
# setup a converting table with constant threshold
threshold = 185
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
# convert to binary image by the table
bim = Lim.point(table, '1' )
bim.save('durant_grey.jpg' )
原图图片效果展示:
灰度化图片效果展示:

二值化图片效果展示:

1.3 convert() 方法详解
Convert()会根据传入参数的不同将图像变成不同的模式。PIL中有九种不同模式。分别为1,L,P,RGB,RGBA,CMYK,YCbCr,I,F。
模式‘1’为二值图像,非黑即白。但是它每个像素用8个bit表示,
0表示黑,255表示白。
模式‘L’为灰色图像它的每个像素用8个bit表示,0表示黑,
255表示白,其他数字表示不同的灰度。在PIL中,从模式“RGB”转
换为“L”模式是按照下面的公式转换的:
L = R * 299/1000 + G * 587/1000+ B * 114/1000
模式“P”为8位彩色图像,它的每个像素用8个bit表示,其对应的
彩色值是按照调色板查询出来的。
模式“RGBA”为32位彩色图像,它的每个像素用32个bit表示,其
中24bit表示红色、绿色和蓝色三个通道,另外8bit表示alpha通道,
即透明通道。
模式“CMYK”为32位彩色图像,它的每个像素用32个bit表示。模
式“CMYK”就是印刷四分色模式,它是彩色印刷时采用的一种套色模
式,利用色料的三原色混色原理,加上黑色油墨,共计四种颜色混合
叠加,形成所谓“全彩印刷”。
模式“YCbCr”为24位彩色图像,它的每个像素用24个bit表示。
YCbCr其中Y是指亮度分量,Cb指蓝色色度分量,而Cr指红色色度分
量。人的肉眼对视频的Y分量更敏感,因此在通过对色度分量进行子
采样来减少色度分量后,肉眼将察觉不到的图像质量的变化。
模式“RGB”转换为“YCbCr”的公式如下:
Y= 0.257R+0.504G+0.098B+16
Cb = -0.148R-0.291G+0.439B+128
Cr = 0.439R-0.368G-0.071*B+128
模式“I”为32位整型灰色图像,它的每个像素用32个bit表示,0表示黑,
255表示白,(0,255)之间的数字表示不同的灰度。在PIL中,从模式“RGB”
转换为“I”模式是按照下面的公式转换的:
I = R * 299/1000 + G * 587/1000 + B * 114/1000
模式“F”为32位浮点灰色图像,它的每个像素用32个bit表示,0表示黑,
255表示白,(0,255)之间的数字表示不同的灰度。在PIL中,从模式“RGB”转
换为“F”模式是按照下面的公式转换的:
F = R * 299/1000+ G * 587/1000 + B * 114/1000
二:Python图像增强
2.1 图片增强三大类别:点增强,空间增强,频域增强
图像增强是图像模式识别中非常重要的图像预处理过程。图像增强的目的是通过对图像中的信息进行处理,使得有利于模式识别的信息得到增强,不利于模式识别的信息被抑制,扩大图像中不同物体特征之间的差别,为图像的信息提取及其识别奠定良好的基础。图像增强按实现方法不同可分为点增强、空域增强和频域增强。
点增强
点增强主要指图像灰度变换和几何变换。图像的灰度变换也称为点运算、对比度增强或对比度拉伸,它是图像数字化软件和图像显示软件的重要组成部分。
灰度变换是一种既简单又重要的技术,它能让用户改变图像数据占据的灰度范围。一幅输入图像经过灰度变换后将产生一幅新的输出图像,由输入像素点的灰度值决定相应的输出像素点的灰度值。灰度变换不会改变图像内的空间关系。
图像的几何变换是图像处理中的另一种基本变换。它通常包括图像的平移、图像的镜像变换、图像的缩放和图像的旋转。通过图像的几何变换可以实现图像的最基本的坐标变换及缩放功能。
空域增强
图像的空间信息可以反映图像中物体的位置 、形状、大小等特征,而这些特征可以通过一定的物理模式来描述。例如,物体的边缘轮廓由于灰度值变化剧烈一般出现高频率特征,而一个比较平滑的物体内部由于灰度值比较均一则呈现低频率特征。因此,根据需要可以分别增强图像的高频和低频特征。对图像的高频增强可以突出物体的边缘轮廓,从而起到锐化图像的作用。例如,对于人脸的比对查询,就需要通过高频增强技术来突出五宫的轮廓。相应地,对图像的低频部分进行增强可以对图像进行平滑处理,一般用于图像的噪声消除。
频域增强
图像的空域增强一般只是对数字图像进行局部增强,而图像的频域增强可以对图像进行全局增强。频域增强技术是在数字图像的频率域空间对图像进行滤波,因此需要将图像从空间域变换到频率域,一般通过傅里叶变换实现。在频率域空间的滤波与空域滤波一样可以通过卷积实现,因此傅里叶变换和和卷积理论是频域滤波技术的基础。
2.2 python图像增强的目的是什么?
图像增强的主要目的有:改变图像的灰度等级,提高图像对比度,消除边缘和噪声,平滑图像;突出边缘或者线性地物,锐化图像;合成彩色图像;压缩图像数据量,突出主要信息等。
图像增强的主要内容有:空间域增强、频率域增强、彩色增强、多图像代数运算、多光谱图像增强等。
在图像分类任务中,图像数据增强一般是大多数人会采用的方法之一,这是由于深度学习对数据集的大小有一定的要求,若原始的数据集比较小,无法很好地满足网络模型的训练,从而影响模型的性能,而图像增强是对原始图像进行一定的处理以扩充数据集,能够在一定程度上提升模型的性能。
2.3 亮度,色度,对比度,锐度增强
from PIL import Image
from PIL import ImageEnhance
# 原始图像
image = Image.open('deal_with/A1.jpg')
image.show()
#亮度增强
enh_bri = ImageEnhance.Brightness(image)
brightness = 1.5
image_brightened = enh_bri.enhance(brightness)
image_brightened.show()
image_brightened.save("image_brightened.jpg")
#色度增强
enh_col = ImageEnhance.Color(image)
color = 1.5
image_colored = enh_col.enhance(color)
image_colored.show()
image_colored.save("image_colored.jpg")
#对比度增强
enh_con = ImageEnhance.Contrast(image)
contrast = 1.5
image_contrasted = enh_con.enhance(contrast)
image_contrasted.show()
image_contrasted.save("image_contrasted.jpg")
#锐度增强
enh_sha = ImageEnhance.Sharpness(image)
sharpness = 3.0
image_sharped = enh_sha.enhance(sharpness)
image_sharped.show()
image_sharped.save("image_sharped.jpg")
原图:

亮度增强:

色度增强:

对比度增强:

锐度增强:

2.4 对图像进行翻转Flipping
对图像进行翻转是最流行的图像数据增强方法之一,这主要是由于翻转图像操作的代码简单,以及对于大多数问题而言,对图像进行翻转操作能够提升模型的性能。下面的模型可以看到人是朝右而不是朝左边。
三:图片相似度算法(对像素求方差并比对)的学习
3.1 算法逻辑
3.1.1 缩放图片
将需要处理的图片所放到指定尺寸,缩放后图片大小由图片的信息量和复杂度决定。譬如,一些简单的图标之类图像包含的信息量少,复杂度低,可以缩放小一点。风景等复杂场景信息量大,复杂度高就不能缩放太小,容易丢失重要信息。根据自己需求,弹性的缩放。在效率和准确度之间维持平衡。
3.1.2 灰度处理
通常对比图像相似度和颜色关系不是很大,所以处理为灰度图,减少后期计算的复杂度。如果有特殊需求则保留图像色彩。
3.1.3 计算平均值
此处开始,与传统的哈希算法不同:分别依次计算图像每行像素点的平均值,记录每行像素点的平均值。每一个平均值对应着一行的特征。
3.1.4 计算方差
对得到的所有平均值进行计算方差,得到的方差就是图像的特征值。方差可以很好的反应每行像素特征的波动,既记录了图片的主要信息。
3.1.5 比较方差
经过上面的计算之后,每张图都会生成一个特征值(方差)。到此,比较图像相似度就是比较图像生成方差的接近成程度。
一组数据方差的大小可以判断稳定性,多组数据方差的接近程度可以反应数据波动的接近程度。我们不关注方差的大小,只关注两个方差的差值的大小。方差差值越小图像越相似!
3.2 代码:
import cv2
import matplotlib.pyplot as plt
#计算方差
def getss(list):
#计算平均值
avg=sum(list)/len(list)
#定义方差变量ss,初值为0
ss=0
#计算方差
for l in list:
ss+=(l-avg)*(l-avg)/len(list)
#返回方差
return ss
#获取每行像素平均值
def getdiff(img):
#定义边长
Sidelength=30
#缩放图像
img=cv2.resize(img,(Sidelength,Sidelength),interpolation=cv2.INTER_CUBIC)
#灰度处理
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#avglist列表保存每行像素平均值
avglist=[]
#计算每行均值,保存到avglist列表
for i in range(Sidelength):
avg=sum(gray[i])/len(gray[i])
avglist.append(avg)
#返回avglist平均值
return avglist
#读取测试图片
img1=cv2.imread("james.jpg")
diff1=getdiff(img1)
print('img1:',getss(diff1))
#读取测试图片
img11=cv2.imread("durant.jpg")
diff11=getdiff(img11)
print('img11:',getss(diff11))
ss1=getss(diff1)
ss2=getss(diff11)
print("两张照片的方差为:%s"%(abs(ss1-ss2)))
x=range(30)
plt.figure("avg")
plt.plot(x,diff1,marker="*",label="$jiames$")
plt.plot(x,diff11,marker="*",label="$durant$")
plt.title("avg")
plt.legend()
plt.show()
cv2.waitKey(0)
cv2.destroyAllWindows()
两张原图:


图像结果如下:
img1: 357.03162469135805
img11: 202.56193703703704
两张照片的方差为:154.469687654321
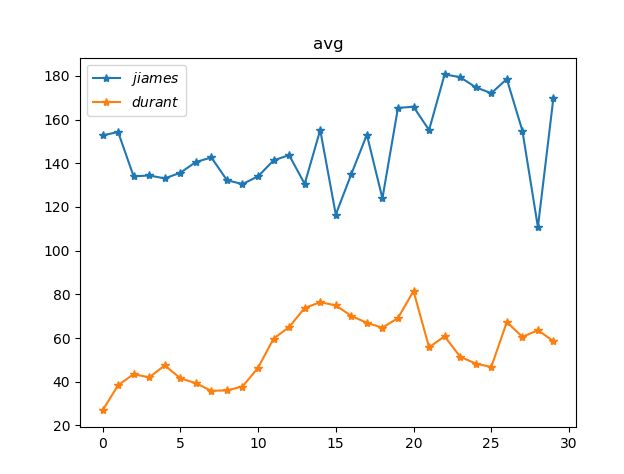
实验环境开始设置了图片像素值,而且进行灰度化处理,此方法比对图像相似对不同的图片方差很大,结果很明显,但是对比比较相似,特别相似的图片不适应。
四:图片相似度算法(感知哈希算法)的学习
"感知哈希算法"(Perceptual hash algorithm),它的作用是对每张图片生成一个"指纹"(fingerprint)字符串,然后比较不同图片的指纹。结果越接近,就说明图片越相似。
4.1 算法步骤
4.1.1 缩小尺寸
将图片缩小到8x8的尺寸,总共64个像素。这一步的作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。
4.1.2 简化色彩
将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。
4.1.3 计算平均值
计算所有64个像素的灰度平均值
4.1.4 比较像素的灰度平均值
将每个像素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
4.1.5 计算哈希值
将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的次序并不重要,只要保证所有图片都采用同样次序就行了。
得到指纹以后,就可以对比不同的图片,看看64位中有多少位是不一样的。在理论上,这等同于计算"汉明距离"(Hamming distance)。如果不相同的数据位不超过5,就说明两张图片很相似;如果大于10,就说明这是两张不同的图片。
此算法参考博客:http://www.ruanyifeng.com/blog/2011/07
/principle_of_similar_image_search.html
但是未实现代码,代码如下:
#!/usr/bin/python
import glob
import os
import sys
from PIL import Image
EXTS = 'jpg', 'jpeg', 'JPG', 'JPEG', 'gif', 'GIF', 'png', 'PNG'
def avhash(im):
if not isinstance(im, Image.Image):
im = Image.open(im)
im = im.resize((8, 8), Image.ANTIALIAS).convert('L')
avg = reduce(lambda x, y: x + y, im.getdata()) / 64.
return reduce(lambda x, (y, z): x | (z << y),
enumerate(map(lambda i: 0 if i < avg else 1, im.getdata())),
0)
def hamming(h1, h2):
h, d = 0, h1 ^ h2
while d:
h += 1
d &= d - 1
return h
if __name__ == '__main__':
if len(sys.argv) <= 1 or len(sys.argv) > 3:
print "Usage: %s image.jpg [dir]" % sys.argv[0]
else:
im, wd = sys.argv[1], '.' if len(sys.argv) < 3 else sys.argv[2]
h = avhash(im)
os.chdir(wd)
images = []
for ext in EXTS:
images.extend(glob.glob('*.%s' % ext))
seq = []
prog = int(len(images) > 50 and sys.stdout.isatty())
for f in images:
seq.append((f, hamming(avhash(f), h)))
if prog:
perc = 100. * prog / len(images)
x = int(2 * perc / 5)
print '\rCalculating... [' + '#' * x + ' ' * (40 - x) + ']',
print '%.2f%%' % perc, '(%d/%d)' % (prog, len(images)),
sys.stdout.flush()
prog += 1
if prog: print
for f, ham in sorted(seq, key=lambda i: i[1]):
print "%d\t%s" % (ham, f)
五:marking——对OpenCV中cvWaitKey函数的学习
用OpenCV来显示图像或者视频时,如果后面不加cvWaitKey这个函数,基本上是显示不出来的。
显示图像,一般要在cvShowImage()函数后面加一句cvWaitKey(0);否则图像无法正常显示。
def waitKey(delay=None): # real signature unknown; restored from __doc__
"""
waitKey([, delay]) -> retval
. @brief Waits for a pressed key.
.
. The function waitKey waits for a key event infinitely (when \f$\texttt{delay}\leq 0\f$ ) or for delay
. milliseconds, when it is positive. Since the OS has a minimum time between switching threads, the
. function will not wait exactly delay ms, it will wait at least delay ms, depending on what else is
. running on your computer at that time. It returns the code of the pressed key or -1 if no key was
. pressed before the specified time had elapsed.
.
. @note
.
. This function is the only method in HighGUI that can fetch and handle events, so it needs to be
. called periodically for normal event processing unless HighGUI is used within an environment that
. takes care of event processing.
.
. @note
.
. The function only works if there is at least one HighGUI window created and the window is active.
. If there are several HighGUI windows, any of them can be active.
.
. @param delay Delay in milliseconds. 0 is the special value that means "forever".
"""
pass
六:marking——图像增强中一阶微分和二阶微分的区别
1,斜坡面上,一阶微分一直不为0 ;二阶微分只有终点和起点不为0
2,一阶微分产生较粗的边缘,二阶微分则细得多
3,一阶微分处理一般对灰度阶梯有较强的响应;二阶微分处理细节有较强的响应
七:关于OpenCV
OpenCV的全称open Sourse Computer Vision Library ,是一个跨平台的计算机视觉库,OpenCV可用于开发实时的图像处理,计算机视觉以及模式识别的程序。
OpenCV是用C++语言编写,它的主要接口也是C++语言,但是依然保留了大量的C语言接口,该库也有大量的Python,Java和MATLAB的接口,另外,一个使用CUDA的GPU接口也用于2010.9 开始实现。
7.1 为什么使用Python+OpenCV
虽然python很强大,而且也有自己的图像处理库PIL,但是相对于OpenCV来讲,它还是弱小很多。跟很多开源软件一样OpenCV也提供了完善的python接口,非常便于调用。OpenCV 的稳定版是2.4.8,最新版是3.0,包含了超过2500个算法和函数,几乎任何一个能想到的成熟算法都可以通过调用OpenCV的函数来实现,超级方便。
7.2 import cv2发生错误的解决方案
错误如下:

1,进入cmd控制台,查看python版本

2 根据自己用的python版本,下载对应的OpenCV
https://www.lfd.uci.edu/~gohlke/pythonlibs/

3,下载numpy,对应的版本
https://pypi.python.org/pypi/numpy
cp36代表着匹配python3.6版本。
win32、amd64代表着32位、64位系统。
4,安装OpenCV,下载下来是一个whl格式文件,把此文件放在安装的文件名下,直接安装。

就这样安装成功。
参考文献:https://blog.csdn.net/wsp_1138886114/article/details/81368890