Transformer中的position encoding(位置编码二)
本文依旧采用4*4大小的词嵌入模型,和模仿3*3大小的特征图进行解读——可学习编码
1.根据自己模型中的定义的最大特征图大小进而定义词嵌入模型大小。
假设模型中的特征图大小不超过4*4,那么我定义的词嵌入模型大小就为4*4,同正余弦编码一样,采用10维数据进行编码。生成行方向的词嵌入模型(4 , 10),及生成列方向的词嵌入模型(4 , 10),进而生成4*10的随机权重值并均匀分布在0-1之间。
row_embed = nn.Embedding(4, 10)#生成行方向词嵌入模型
col_embed = nn.Embedding(4, 10)#生成列方向词嵌入模型
nn.init.uniform_(row_embed.weight)##row_embed.weight 生成4*10个随机权重,将4*10个随机权重均匀分布到0~1之间
nn.init.uniform_(col_embed.weight)##col_embed.weight 生成4*10个随机权重,将4*10个随机权重均匀分布到0~1之间#生成效果
>>Parameter containing:
>>tensor([[0.7210, 0.6557, 0.9614, 0.9003, 0.3136, 0.3225, 0.4364, 0.1597, 0.7911,
0.5075],
[0.4533, 0.7322, 0.3796, 0.0197, 0.2896, 0.1197, 0.3748, 0.3435, 0.6317,
0.7949],
[0.7705, 0.1192, 0.4153, 0.4846, 0.3322, 0.2019, 0.2403, 0.6203, 0.5895,
0.4519],
[0.9103, 0.9428, 0.4476, 0.5646, 0.1671, 0.0057, 0.9447, 0.3557, 0.5942,
0.5540]], requires_grad=True)
>>Parameter containing:
>>tensor([[0.1283, 0.8312, 0.8332, 0.7292, 0.9732, 0.5844, 0.6130, 0.0270, 0.7723,
0.4279],
[0.5193, 0.3034, 0.6812, 0.9023, 0.8603, 0.2662, 0.0686, 0.5559, 0.8925,
0.8579],
[0.9727, 0.9112, 0.1469, 0.9137, 0.4930, 0.9952, 0.5632, 0.3663, 0.7025,
0.7532],
[0.2231, 0.9810, 0.7064, 0.4617, 0.9261, 0.6420, 0.7784, 0.9162, 0.1140,
0.2127]], requires_grad=True)2.获取特征图大小,分别对行列进行编码
这一步的目的是为了和词嵌入模型进行匹配,避免给超出特征图的位置部分进行编码。
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])#假定特征图大小为3*3
h, w = a.shape[-2:] #读取特征图大小
i = torch.arange(w) #得到列pos
j = torch.arange(h) #得到行pos
x_emb = col_embed(i) #提取出对应的列词嵌入模型的位置权重
y_emb = row_embed(j) #提取出对应的行词嵌入模型的位置权重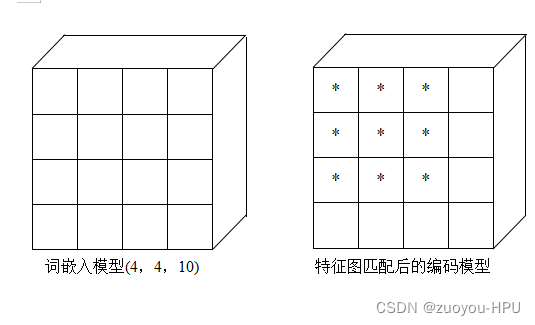
得到特征图大小以后,只对所对应的位置,进行下一步位置编码,如上图 * 号位置。
>>tensor([[0.1283, 0.8312, 0.8332, 0.7292, 0.9732, 0.5844, 0.6130, 0.0270, 0.7723,
0.4279],
[0.5193, 0.3034, 0.6812, 0.9023, 0.8603, 0.2662, 0.0686, 0.5559, 0.8925,
0.8579],
[0.9727, 0.9112, 0.1469, 0.9137, 0.4930, 0.9952, 0.5632, 0.3663, 0.7025,
0.7532]], grad_fn=)#列编码权重值
>>tensor([[0.7210, 0.6557, 0.9614, 0.9003, 0.3136, 0.3225, 0.4364, 0.1597, 0.7911,
0.5075],
[0.4533, 0.7322, 0.3796, 0.0197, 0.2896, 0.1197, 0.3748, 0.3435, 0.6317,
0.7949],
[0.7705, 0.1192, 0.4153, 0.4846, 0.3322, 0.2019, 0.2403, 0.6203, 0.5895,
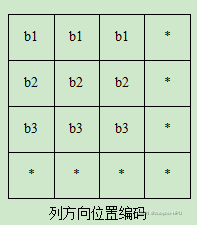
0.4519]], grad_fn=)#行编码权重值 为了便于理解,下面我们将第一组的tensor的第1行的1*10向量记作a1,第2行的1*10向量记作a2,第三行的1*10向量记作a3。将第二组的tensor的第一行的1*10向量记作b1,第2行的1*10向量记作b2,第三行的1*10向量记作b3。

3. 扩充、生成(N ,2*维数 ,h,w)
repeat(x.shape[0],1,1,1)后变成(N,2*num_pos_feats,h,w)
pos = torch.cat([
x_emb.unsqueeze(0).repeat(h, 1, 1),#(h,w,num_pos_feats)
y_emb.unsqueeze(1).repeat(1, w, 1),#(h,w,num_pos_feats),torch.cat后变成(h,w,2*num_pos_feats)
], dim=-1).permute(2, 0, 1).unsqueeze(0).repeat(a.shape[0], 1, 1, 1)将x_emb和y_emb组合以后生成了3*20*3*3tensor。
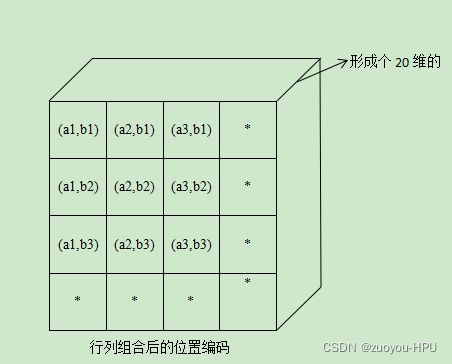
组合以后形成的位置编码如上示意图。
然后生成的是3*20*3*3维的tensor,20维的tensor前10个数据是a的10个权重值,后10个数据是b的10个权重值,3个通道*每个位置的20维的tensor*高3*宽3。
因此就可以用20维的tensor将不同位置表示出来,其中的每个位置的20维的tensor数据都是权重生成的,我所理解的学习可能就是权重的变化上面体现的吧,个人对这个可学习还是了解的不够深刻。
欢迎大家批评指正讨论,感谢各位的阅读和点赞。
以下是自己所生成的简单的可学习位置编码代码,大家可以跑一下加深理解。
#可学习位置编码
row_embed = nn.Embedding(4, 10)
col_embed = nn.Embedding(4, 10)
nn.init.uniform_(row_embed.weight)
nn.init.uniform_(col_embed.weight)
print(nn.init.uniform_(row_embed.weight))
print(nn.init.uniform_(col_embed.weight) )
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
h, w = a.shape[-2:]
print(a.shape[0])
print(h)
print(w)
i = torch.arange(w)
j = torch.arange(h)
print(i)
print(j)
x_emb = col_embed(i)
y_emb = row_embed(j)
print(x_emb)
print(y_emb)
pos = torch.cat([
x_emb.unsqueeze(0).repeat(h, 1, 1),#(h,w,num_pos_feats)
y_emb.unsqueeze(1).repeat(1, w, 1),#(h,w,num_pos_feats),torch.cat后变成(h,w,2*num_pos_feats)
], dim=-1).permute(2, 0, 1).unsqueeze(0).repeat(a.shape[0], 1, 1, 1)
# print(x_emb.unsqueeze(0).repeat(h, 1, 1))
# print(y_emb.unsqueeze(1).repeat(1, w, 1))
print(torch.cat([
x_emb.unsqueeze(0).repeat(h, 1, 1),#(h,w,num_pos_feats)
y_emb.unsqueeze(1).repeat(1, w, 1),#(h,w,num_pos_feats),torch.cat后变成(h,w,2*num_pos_feats)
], dim=-1))
print(pos)