Spark RDD详解
spark 系列
Spark 核心原理及运行架构
Spark RDD详解
Spark 常用算子大全
Spark RDD
- spark 系列
- 前言
- RDD概述
-
- 什么是 RDD
- RDD 的属性
- RDD的特点
- RDD编程
-
- RDD 创建方式
- RDD 算子操作
- RDD 函数传递
- RDD依赖关系
- RDD Jobs / Stage
- RDD 分区器
- RDD Shuffle
- RDD 持久化
-
- RDD 缓存
- RDD CheckPoint
- RDD 累加器
- RDD 广播变量
前言
看了前面的一篇 Spark 博客,相信大家对于 Spark 的基本概念、运行框架以及工作原理已经搞明白了。本篇博客将为大家详细介绍了 Spark 程序的核心,也就是弹性分布式数据集(RDD)。但到底什么是 RDD,它是做什么用的呢?请听我下面详细说来。
RDD概述
什么是 RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象。代码中是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
简单的来说,RDD是将数据项拆分为多个分区的集合,存储在集群的工作节点上的内存和磁盘中,并执行正确的操作;复杂的来说,RDD是用于数据转换的接口,RDD指向了存储在HDFS、Cassandra、HBase等、或缓存(内存、内存+磁盘、仅磁盘等),或在故障或缓存收回时重新计算其他RDD分区中的数据。
RDD是只读的、分区记录的集合,每个分区分布在集群的不同节点上;RDD默认存放在内存中,当内存不足,Spark自动将RDD写入磁盘。RDD并不存储真正的数据,只是对数据和操作的描述。
RDD 的属性

在 Spark 官网对 RDD 的描述主要有如下5大点:
A list of partitions
一个分区列表,一个rdd有多个分区,后期spark任务计算是以分区为单位,一个分区就对应上一个task线程。 通过val rdd1=sc.textFile(文件) 。如果这个文件大小的block个数小于等于2,它产生的rdd的分区数就是2 ;如果这个文件大小的block个数大于2,它产生的rdd的分区数跟文件的block相同。
A function for computing each split
由一个函数计算每一个分片 比如:rdd2=rdd1.map(x=>(x,1)) ,这里指的就是每个单词计为1的函数。
A list of dependencies on other RDDs
一个rdd会依赖于其他多个rdd,这里就涉及到rdd与rdd之间的依赖关系,后期spark任务的容错机制就是根据这个特性而来。 比如: rdd2=rdd1.map(x=>(x,1)), rdd2的结果是通过rdd1调用了map方法生成,那么rdd2就依赖于rdd1的结果对其他RDD的依赖列表,依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。
Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
(可选项) 对于kv类型的rdd才会有分区函数(必须要产生shuffle),也叫做分区器,对于不是kv类型的rdd分区函数是None。 分区函数的作用:它是决定了原始rdd的数据会流入到下面rdd的哪些分区中。 spark的分区函数有2种:第一种hashPartitioner(默认值), 通过key.hashcode % 分区数=分区号 ;第二种RangePartitioner,是基于一定的范围进行分区,这也是默认的分区方式。此外,用户可以根据自己的需求自定义分区函数来自定义分区。
Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
(可选项) 一组最优的数据块的位置,这里涉及到数据的本地性和数据位置最优 spark后期在进行任务调度的时候,会优先考虑存有数据的worker节点来进行任务的计算,也就是说将计算任务分派到其所在处理数据块的存储位置。大大减少数据的网络传输,提升性能。这里就运用到了大数据中移动数据不如移动计算理念。
RDD的特点
RDD表示只读的分区的数据集,对RDD进行改动,只能通过RDD的转换操作,由一个RDD得到一个新的RDD,新的RDD包含了从其他RDD衍生所必需的信息。RDDs之间存在依赖,RDD的执行是按照血缘关系延时计算的。如果血缘关系较长,可以通过持久化RDD来切断血缘关系。
分区
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。
如下图所示,分区是RDD被拆分并发送到节点的不同块之一。
- 我们拥有的分区越多,得到的并行性就越强
- 每个分区都是被分发到不同Worker Node的候选者
- 每个分区对应一个Task
- 每个分区上都有compute函数,计算该分区中的数据

对于如何分区,分区算法下面会详述。
只读
RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
由一个RDD转换到另一个RDD,可以通过丰富的操作算子实现,不再像MapReduce那样只能写map和reduce了。 RDD的操作算子包括两类,一类叫做transformations转化,它是用来将RDD进行转化,构建RDD的血缘关系;另一类叫做actions动作,它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。这在我的下一篇博客 spark RDD算法大全 会详细介绍。
依赖
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系,也称之为依赖。依赖包括两种,一种是窄依赖,RDDs之间分区是一一对应的,另一种是宽依赖,下游RDD的每个分区与上游RDD(也称之为父RDD)的每个分区都有关,是多对多的关系。这个下面 RDD依赖关系 会详细说明。
持久化缓存
如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。这个下面 RDD持久化 会详细说明。
RDD编程
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群以调度运行Worker,如下图所示。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务。

RDD 创建方式
在Spark中创建RDD的创建方式可以分为三种:从集合中创建RDD;从外部存储创建RDD;从其他RDD创建。
1. 从集合中创建
从集合中创建RDD,Spark主要提供了两种函数:parallelize和makeRDD
1) 使用parallelize()从集合创建
scala> val rdd = sc.parallelize(Array(1,2,3))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
2) 使用makeRDD()从集合创建
scala> val rdd1 = sc.makeRDD(Array(1,2,3))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:24
2. 由外部存储系统的数据集创建
包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
scala> val rdd2= sc.textFile("hdfs://hadoop102:9000/RELEASE")
rdd2: org.apache.spark.rdd.RDD[String] = hdfs:// hadoop102:9000/RELEASE MapPartitionsRDD[4] at textFile at <console>:24
3. 从其他RDD创建
第三种方式是通过对现有RDD的转换来创建RDD,一般情况下通过RDD 动作算子得到的新的RDD来进行创建的。
RDD 算子操作
RDD的操作算子包括两类,一类叫做transformations转化,它是用来将RDD进行转化,构建RDD的血缘关系;另一类叫做actions动作,它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。这在我的下一篇博客 spark RDD算法大全 会详细介绍。

如上图所示,Transformation返回值还是一个RDD。它使用了链式调用的设计模式,对一个RDD进行计算后,变换成另外一个RDD,然后这个RDD又可以进行另外一次转换。这个过程是分布式的。 Action返回值不是一个RDD。它要么是一个Scala的普通集合,要么是一个值,要么是空,最终或返回到Driver程序,或把RDD写入到文件系统中。
Action是返回值返回给driver或者存储到文件,是RDD到result的变换,Transformation是RDD到RDD的变换。
只有action执行时,rdd才会被计算生成,这是rdd懒惰执行的根本所在。
RDD 函数传递
在实际开发中我们往往需要自己定义一些对于RDD的操作,那么此时需要注意的是,初始化工作是在Driver端进行的,而实际运行程序是在Executor端进行的,这就涉及到了跨进程通信,是需要序列化的。
例如:
package com.hubert.test
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
class Search(query:String) extends Serializable{
//过滤出包含字符串的数据
def isMatch(s: String): Boolean = {
s.contains(query)
}
//过滤出包含字符串的RDD
def getMatch1 (rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
//过滤出包含字符串的RDD
def getMatch2(rdd: RDD[String]): RDD[String] = {
//将类变量赋值给局部变量
val query_ : String = this.query
rdd.filter(x => x.contains(query_))
}
}
object Test03 {
def main(args: Array[String]): Unit = {
//1.初始化配置信息及SparkContext
val sparkConf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.创建一个RDD
val rdd: RDD[String] = sc.parallelize(Array("hadoop", "spark", "hive", "atguigu"))
//3.创建一个Search对象
val search = new Search("h")
//4.运用第一个过滤函数并打印结果
val match1: RDD[String] = search.getMatch2(rdd)
match1.collect().foreach(println)
}
}
在getMatch2()方法中所调用的方法query是定义在Search这个类中的字段,实际上调用的是this. query,主程序search对象所调用的方法getMatch2()是定义在Search这个类中的,实际上调用的是this. getMatch2(),this表示Search这个类的对象,程序在运行过程中需要将Search对象序列化以后传递到Executor端。
RDD依赖关系
Lineage
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。

例如:
// 1)读取一个HDFS文件并将其中内容映射成一个个元组
scala> val wordAndOne = sc.textFile("/fruit.tsv").flatMap(_.split("\t")).map((_,1))
wordAndOne: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[22] at map at <console>:24
// 2)统计每一种key对应的个数
scala> val wordAndCount = wordAndOne.reduceByKey(_+_)
wordAndCount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[23] at reduceByKey at <console>:26
// 3)查看“wordAndOne”的Lineage
scala> wordAndOne.toDebugString
res5: String =
(2) MapPartitionsRDD[22] at map at <console>:24 []
| MapPartitionsRDD[21] at flatMap at <console>:24 []
| /fruit.tsv MapPartitionsRDD[20] at textFile at <console>:24 []
| /fruit.tsv HadoopRDD[19] at textFile at <console>:24 []
// 4)查看“wordAndCount”的Lineage
scala> wordAndCount.toDebugString
res6: String =
(2) ShuffledRDD[23] at reduceByKey at <console>:26 []
+-(2) MapPartitionsRDD[22] at map at <console>:24 []
| MapPartitionsRDD[21] at flatMap at <console>:24 []
| /fruit.tsv MapPartitionsRDD[20] at textFile at <console>:24 []
| /fruit.tsv HadoopRDD[19] at textFile at <console>:24 []
// 5)查看“wordAndOne”的依赖类型
scala> wordAndOne.dependencies
res7: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@5d5db92b)
// 6)查看“wordAndCount”的依赖类型
scala> wordAndCount.dependencies
res8: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@63f3e6a8)
Lineage 是RDD最重要的特性之一,保存了RDD的依赖关系;实现了基于Lineage的容错机制。
窄依赖
窄依赖指得是每一个父RDD的Partition最多被子RDD的一个Partition使用,窄依赖我们形象的比喻为独生子女。

宽依赖
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle。总结:宽依赖我们形象的比喻为超生。

宽依赖对比窄依赖
宽依赖对应shuffle操作,需要在运行时将同一个父RDD的分区传入到不同的子RDD分区中,不同的分区可能位于不同的节点,就可能涉及多个节点间数据传输。
当RDD分区丢失时,Spark会对数据进行重新计算,对于窄依赖只需重新计算一次子RDD的父RDD分区。
相比于宽依赖,窄依赖对优化更有利。
DAG
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。

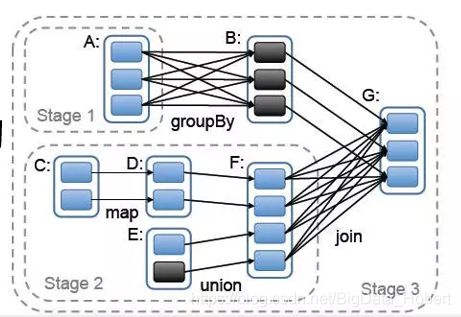
RDD Jobs / Stage

以上图WordCount为例,RDD任务切分中间分为:Application、Job、Stage和Task。
-
Application:初始化一个SparkContext即生成一个Application
-
Job:一个Action算子就会生成一个Job
-
Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
-
Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task。
注意: Application -> Job-> Stage-> Task 每一层都是 1对n 的关系。

数据本地化划分Stage的意义是移动计算,而不是移动数据;保证一个Stage内不会发生数据移动。
RDD 分区器
Spark目前支持Hash分区和Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数,RDD中每条数据经过Shuffle过程属于哪个分区和Reduce的个数。
注意:
(1) Key-Value类型的RDD才有分区器的,非Key-Value类型的RDD分区器的值是None。
(2)每个RDD的分区ID范围:0~numPartitions-1,决定这个值是属于那个分区的。
Hash分区
HashPartitioner分区的原理:对于给定的key,计算其hashCode,并除以分区的个数取余,如果余数小于0,则用余数+分区的个数(否则加0),最后返回的值就是这个key所属的分区ID。
例如:
scala> nopar.partitioner
res20: Option[org.apache.spark.Partitioner] = None
scala> val nopar = sc.parallelize(List((1,3),(1,2),(2,4),(2,3),(3,6),(3,8)),8)
nopar: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[10] at parallelize at <console>:24
scala>nopar.mapPartitionsWithIndex((index,iter)=>{ Iterator(index.toString+" : "+iter.mkString("|")) }).collect
res0: Array[String] = Array("0 : ", 1 : (1,3), 2 : (1,2), 3 : (2,4), "4 : ", 5 : (2,3), 6 : (3,6), 7 : (3,8))
scala> val hashpar = nopar.partitionBy(new org.apache.spark.HashPartitioner(7))
hashpar: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[12] at partitionBy at <console>:26
scala> hashpar.count
res18: Long = 6
scala> hashpar.partitioner
res21: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@7)
scala> hashpar.mapPartitions(iter => Iterator(iter.length)).collect()
res19: Array[Int] = Array(0, 3, 1, 2, 0, 0, 0)
Ranger分区
HashPartitioner分区弊端:可能导致每个分区中数据量的不均匀,极端情况下会导致某些分区拥有RDD的全部数据。
RangePartitioner作用:将一定范围内的数映射到某一个分区内,尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大,但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。实现过程为:
第一步:先重整个RDD中抽取出样本数据,将样本数据排序,计算出每个分区的最大key值,形成一个Array[KEY]类型的数组变量rangeBounds;
第二步:判断key在rangeBounds中所处的范围,给出该key值在下一个RDD中的分区id下标;该分区器要求RDD中的KEY类型必须是可以排序的。
自定义分区
要实现自定义的分区器,你需要继承 org.apache.spark.Partitioner 类并实现下面三个方法。
1)numPartitions: Int:返回创建出来的分区数。
2)getPartition(key: Any): Int:返回给定键的分区编号(0到numPartitions-1)。
3)equals():Java 判断相等性的标准方法。这个方法的实现非常重要,Spark 需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样 Spark 才可以判断两个 RDD 的分区方式是否相同。
例如:
// 1)创建一个pairRDD
scala> val data = sc.parallelize(Array((1,1),(2,2),(3,3),(4,4),(5,5),(6,6)))
data: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[3] at parallelize at <console>:24
// 2)定义一个自定义分区类
scala> :
class CustomerPartitioner(numParts:Int) extends org.apache.spark.Partitioner{
//覆盖分区数
override def numPartitions: Int = numParts
//覆盖分区号获取函数
override def getPartition(key: Any): Int = {
val ckey: String = key.toString
ckey.substring(ckey.length-1).toInt%numParts
}
}
// 3)将RDD使用自定义的分区类进行重新分区
scala> val par = data.partitionBy(new CustomerPartitioner(2))
par: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[2] at partitionBy at <console>:27
// 4)查看重新分区后的数据分布
scala> par.mapPartitionsWithIndex((index,items)=>items.map((index,_))).collect
res3: Array[(Int, (Int, Int))] = Array((0,(2,2)), (0,(4,4)), (0,(6,6)), (1,(1,1)), (1,(3,3)), (1,(5,5)))
RDD Shuffle
RDD Shuffle指的是在分区之间重新分配数据
- 父RDD中同一分区中的数据按照算子要求重新进入子RDD的不同分区中
- 中间结果写入磁盘
- 由子RDD拉取数据,而不是由父RDD推送
- 默认情况下,Shuffle不会改变分区数量
以reduceByKey为例解释shuffle过程。

在没有task的文件分片合并下的shuffle过程如下:spark.shuffle.consolidateFiles=false

fetch 来的数据存放到哪里?
刚 fetch 来的 FileSegment 存放在 softBuffer 缓冲区,经过处理后的数据放在内存 + 磁盘上。这里我们主要讨论处理后的数据,可以灵活设置这些数据是“只用内存”还是“内存+磁盘”。如果spark.shuffle.spill = false就只用内存。由于不要求数据有序,shuffle write 的任务很简单:将数据 partition 好,并持久化。之所以要持久化,一方面是要减少内存存储空间压力,另一方面也是为了 fault-tolerance。
shuffle之所以需要把中间结果放到磁盘文件中,是因为虽然上一批task结束了,下一批task还需要使用内存。如果全部放在内存中,内存会不够。另外一方面为了容错,防止任务挂掉。
存在问题如下:
-
产生的 FileSegment 过多。每个 ShuffleMapTask 产生 R(reducer 个数)个 FileSegment,M 个 ShuffleMapTask 就会产生 M * R 个文件。一般 Spark job 的 M 和 R 都很大,因此磁盘上会存在大量的数据文件。
-
缓冲区占用内存空间大。每个 ShuffleMapTask 需要开 R 个 bucket,M 个 ShuffleMapTask 就会产生 M * R 个 bucket。虽然一个ShuffleMapTask 结束后,对应的缓冲区可以被回收,但一个 worker node 上同时存在的 bucket 个数可以达到 cores * M * R 个(一般 worker 同时可以运行 cores 个 ShuffleMapTask),占用的内存空间也就达到了cores× R × M × 32 KB。对于 8 核 1000 个 reducer 来说,占用内存就是 256MB。
为了解决上述问题,我们可以使用文件合并的功能。
在进行task的文件分片合并下的shuffle过程如下:spark.shuffle.consolidateFiles=true

可以明显看出,在一个 core 上连续执行的 ShuffleMapTasks 可以共用一个输出文件 ShuffleFile。先执行完的 ShuffleMapTask 形成 ShuffleBlock i,后执行的 ShuffleMapTask 可以将输出数据直接追加到 ShuffleBlock i 后面,形成 ShuffleBlock i,每个 ShuffleBlock 被称为 FileSegment。下一个 stage 的 reducer 只需要 fetch 整个 ShuffleFile 就行了。这样,每个 worker 持有的文件数降为 cores× R。FileConsolidation 功能可以通过spark.shuffle.consolidateFiles=true来开启。
例如:
sc.textFile("hdfs:/data/test/input/names.txt")
.map(name=>(name.charAt(0),name))
.groupByKey()
.mapValues(names=>names.toSet.size)
.collect()
提前部分聚合减少数据移动,尽量避免Shuffle,改善代码如下:
sc.textFile("hdfs:/data/test/input/names.txt")
.distinct(numPartitions=6)
.map(name=>(name.charAt(0),1))
.reduceByKey(_+_)
.collect()
RDD 持久化
RDD 缓存
RDD通过persist方法或cache方法可以将前面的计算结果缓存,默认情况下 persist() 会把数据以序列化的形式缓存在 JVM 的堆空间中。
但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
cache最终也是调用了persist方法,只是选择的持久化级别为MEMORY_ONLY,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。
persist支持的RDD持久化级别如下:

缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
Spark只要写磁盘,就会用到序列化。除了shuffle阶段和persist会序列化,其他时候RDD处理都在内存中,不会用到序列化。
例如:
// 1)创建一个RDD
scala> val rdd = sc.makeRDD(Array("atguigu"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[19] at makeRDD at <console>:25
// 2)将RDD转换为携带当前时间戳不做缓存
scala> val nocache = rdd.map(_.toString+System.currentTimeMillis)
nocache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[20] at map at <console>:27
// 3)多次打印结果
scala> nocache.collect
res0: Array[String] = Array(atguigu1538978275359)
scala> nocache.collect
res1: Array[String] = Array(atguigu1538978282416)
scala> nocache.collect
res2: Array[String] = Array(atguigu1538978283199)
// 4)将RDD转换为携带当前时间戳并做缓存
scala> val cache = rdd.map(_.toString+System.currentTimeMillis).cache
cache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[21] at map at <console>:27
// 5)多次打印做了缓存的结果
scala> cache.collect
res3: Array[String] = Array(atguigu1538978435705)
scala> cache.collect
res4: Array[String] = Array(atguigu1538978435705)
scala> cache.collect
res5: Array[String] = Array(atguigu1538978435705)
缓存应用场景
- 从文件加载数据之后,因为重新获取文件成本较高
- 经过较多的算子变换之后,重新计算成本较高
- 单个非常消耗资源的算子之后
使用注意事项
- cache()或persist()后不能再有其他算子
- cache()或persist()遇到Action算子完成后才生效
RDD CheckPoint
虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从checkpoint处拿到数据。
Spark中对于数据的保存除了持久化操作之外,还提供了一种检查点的机制,检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。检查点通过将数据写入到HDFS文件系统实现了RDD的检查点功能。
例如:
// 1)设置检查点
scala> sc.setCheckpointDir("hdfs://hadoop102:9000/checkpoint")
// 2)创建一个RDD
scala> val rdd = sc.parallelize(Array("atguigu"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[14] at parallelize at <console>:24
// 3)将RDD转换为携带当前时间戳并做checkpoint
scala> val ch = rdd.map(_+System.currentTimeMillis)
ch: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[16] at map at <console>:26
// 4)多次打印结果
scala> ch.collect
res55: Array[String] = Array(atguigu1538981860336)
scala> ch.collect
res56: Array[String] = Array(atguigu1538981860504)
scala> ch.collect
res57: Array[String] = Array(atguigu1538981860504)
scala> ch.collect
res58: Array[String] = Array(atguigu1538981860504)
为当前RDD设置检查点。该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移除。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。
检查点与缓存的区别
- 检查点类似于快照,会删除RDD lineage,而缓存不会
- SparkContext被销毁后,检查点数据不会被删除
RDD 累加器
累加器用来对信息进行聚合,通常在向 Spark传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。如果我们想实现所有分片处理时更新共享变量的功能,那么累加器可以实现我们想要的效果。
scala> val notice = sc.textFile("./NOTICE")
notice: org.apache.spark.rdd.RDD[String] = ./NOTICE MapPartitionsRDD[40] at textFile at <console>:32
scala> val blanklines = sc.accumulator(0)
warning: there were two deprecation warnings; re-run with -deprecation for details
blanklines: org.apache.spark.Accumulator[Int] = 0
scala> val tmp = notice.flatMap(line => {
| if (line == "") {
| blanklines += 1
| }
| line.split(" ")
| })
tmp: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[41] at flatMap at <console>:36
scala> tmp.count()
res31: Long = 3213
scala> blanklines.value
res32: Int = 171
通过在驱动器中调用SparkContext.accumulator(initialValue)方法,创建出存有初始值的累加器。返回值为 org.apache.spark.Accumulator[T]对象,其中 T 是初始值 initialValue 的类型。Spark闭包里的执行器代码可以使用累加器的 += 方法(在Java中是 add)增加累加器的值。 驱动器程序可以调用累加器的value属性(在Java中使用value()或setValue())来访问累加器的值。
注意:工作节点上的任务不能访问累加器的值。从这些任务的角度来看,累加器是一个只写变量。只允许added操作,常用于实现计数。
对于要在行动操作中使用的累加器,Spark只会把每个任务对各累加器的修改应用一次。因此,如果想要一个无论在失败还是重复计算时都绝对可靠的累加器,我们必须把它放在 foreach() 这样的行动操作中。转化操作中累加器可能会发生不止一次更新。
RDD 广播变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。 在多个并行操作中使用同一个变量,但是 Spark会为每个任务分别发送。
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(35)
scala> broadcastVar.value
res33: Array[Int] = Array(1, 2, 3)
使用广播变量的过程如下:
- 通过对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T] 对象。 任何可序列化的类型都可以这么实现。
- 通过 value 属性访问该对象的值(在 Java 中为 value() 方法)。
- 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
注意事项:
- Driver端变量在每个Executor每个Task保存一个变量副本
- Driver端广播变量在每个Executor只保存一个变量副本