阅读笔记:pg085 AXI4-Stream infrastructure
Introduction
- 前言:pg085-axi4stream-infrastructure.pdf 这篇文档,所介绍不仅仅是 AXI4-Stream Switch 一个IP核,而是分别对下图所示的几个IP核进行了说明,阅读时需要区分。另外,在这些IP核中,数据传输的基本单位是传输(transfer),类似于数据包的概念,2个以上的 transfer 构成一个 transaction。
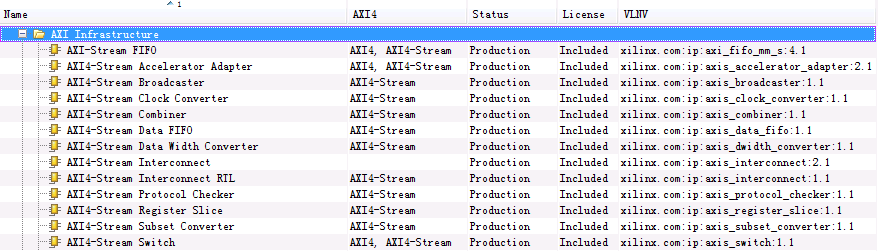
- AXI4-Stream Infrastucture IP 核们的主要功能是在 AXI4-Stream master/slave 系统 之间提供高速连接。这些IP核们的功能大概可以划分三类:buffering,transform,routing。
- buffering 类的IP核有:
- AXI4-Stream Clock Converter:作用是连通两个不同的时钟域。
- AXI4-Stream Data FIFO:用来实现不同深度的BRAM/LUTRAM。
- AXI4-Stream Register Slice:Creates timing isolation and pipelining master and slave using a two-deep register buffer。
transform 类IP核有:
- AXI4-Stream Combiner:将位宽较窄的TDATA 数据流拼接成更宽的输出。
- AXI4-Stream Data Width Converter:分两种情况:①拓宽数据宽度:将数个TDATA 混合成更宽的流;②缩小数据宽度:将TDATA拆分为数个宽度较小的流。
- AXI4-Stream Subset Converter。
routing 类的IP核有:
- AXI4-Stream Broadcaster:将一个传输复制到多个输出。
- AXI4-Stream Switch: 将多个master 和 slave 连接在一起,使用 TDEST 信号将传输 路由到不同的输出端口;或者利用可选的 control register 模式进行路由,这种模式需要AXI4-Lite接口进行控制。
- AXI4-Stream Interconnect:实际就是利用AXI4-Stream Switch 加上一些其他模块构成。
- 从上面可以看出,AXI4-Stream Switch 只是这个pg085 文档中的一个小分子。下面将着重总结AXI4-Stream Switch 相关的内容,对其他IP核的内容只是一笔带过,或者一笔也没有。
1. Overview
1.1 对 AXI4-Stream 接口协议的简介
- AXI4-Stream 是一个开放标准接口协议,支持低资源消耗,高带宽的单向数据传输。
- 对于AXI4-Stream 传输通路两端而言,发送方是master,接收方是slave。
1.2 AXI4-Stream Switch 的基本属性
- 支持 1-16个slave,支持1-16个master;
- 支持三种仲裁依据:基于TLAST信号;基于传输的数量(number of transfers);基于超时,即 对连续的 LOW TVALID计数,数量达到预设值则开始新的仲裁。
- 支持三种仲裁算法:Round-Robin, True Round-Robin, 和 Fixed Priority arbitration 。
- 支持稀疏连接;
- 支持基于TDEST base/high 信号对的路由,或者基于AXI4-Lite 接口控制的control register 路由。
2. Pruduct Specification
略过其他IP核的说明,直接总结第16页的Switch的说明,主要是对两种路由方式的说明。
- 两种路由方式包括 TDEST routing 和 control register based routing。
2.1 AXI4-Stream Switch 的两种路由方式
2.1.1 TDEST routing

- 如上图所示,在IP核定制阶段,就要先配置各个master的TDEST base/high,从而得到一个解码表。在路由时,每个slave接口对输入数据中TDEST信号进行解码,然后查找解码表找到目的master 接口,之后向目标master 接口的仲裁器发送一个请求。当仲裁器回复一个“允许”后,slave 开始进行传输。
- Arbitration can be performed at the transfer level or at the transaction level. (A transaction is a series of two or more transfers.) ==> 仲裁可以在两个层面上进行:可以对每个传输进行(transfer level),也可以对数个传输进行(transaction level)。如果是在transaction level,可以基于固定长度 或者 TLAST信号 进行仲裁。还有一个可选的超时操作,就是:即使没有达到固定长度限制 或者 没收到TLAST 信号,只要连接已经空闲太久了的话,也能终止这个transaction。这个措施在特定的系统拓扑上能够避免死锁。
- TDEST routing 要求TDEST 信号线宽度至少是 log2( master接口数量 )。
注:此处原文是 log2(Number of Slave Interfaces)。文章中对于slave和master变化多端,因为对于AXI4-Stream总线而言,发送者就是master,接收者就是slave。在switch内部,原来的相对于外部而言的slave接口是从外部接收数据,然后发送给master接口,之后master接口发送到外部。因为在内部,数据是从slave发给master,所以对于slave而言,master是它的slave,因此这里公式中的slave,实际上是通常所说的master。文档中还有不少地方这样倒腾slave和master。我们约定master和slave都是相对于外部而言的。
2.1.2 control register based routing
- control register routing 引入AXI4-Lite 接口来配置路由表。
- 每个master接口上有一个寄存器,用来控制选择器。一旦这些寄存器们被程序改写,会有一个提交寄存器(commit register)把这些寄存器们的值传入switch。在这期间,AXI4-Stream 接口会保持在reset 状态。
- 这个路由模式要求 master 和 slave 之间只有一条路径。当企图把同一slave 接口连接到多个master 时,只有编号最低的 master 能够访问这个slave。编号指的是每个接口的编号,比如slave 接口依次有 S01 S02 … S15,master 接口依次有 M01 M02 … M15。(前面的TDEST路由没提到这个限制,或许允许多径?)
- 未使用的master 接口可能会被置为disabled,任何未被连接到master的slave 接口都会被 disabled。
- 另外,对于两种路由方式,支持 slave 和 master 之间的稀疏连接。当不需要或者要禁止某些连接时,在定制IP核阶段可以点掉,从而节省开销。如果使用的是control register based routing,则无效的路由会被停止;如果使用的是 TDEST 路由,则会丢弃传输。当传输被丢弃的时候,decode_err信号 会被置为高。
2.2 Performance
2.2.1 最大频率
- 在 Kintex®-7
FPGA (xc7k325tffg900-1.) 板子上,pg085文档中的各 AXI4-Stream IP核的最大频率可以达到250 MHz。对于某些 -2 或者 -3 速度等级的元器件,最大频率能够提高 5% - 10%。但是对于 AXI4-Stream Switch,当配置超过大概 4 个master 或者 slave 时,支持的最大频率会降低 20-25%。(所以,我们 8x8 的话,还能使用这个switch 吗??)
2.2.2 时延
- 时延使用时钟周期作计算单位。
- 时延的计算的始末:从slave 接口将 TVALID 信号置高电平开始,到master 接口首次将 TVALID 信号置为高电平。
- 延迟的计算基于 master 接口上的TREADY 信号始终是高电平的假设。(这是因为只有TREADY 和TVALID 同时为高电平,传输才能开始)
- 如果要计算 背靠背 传输模式的时延,可以通过计算 当slave 接口接收到一个传输后,它的 TREADY 处于低电平的时钟周期数。

- AXI4-Stream Switch 的时延如上图所示。这是 TDEST 路由模式的时延,而 control register based routing 模式的时延在此未提及。由上图可见,非背靠背传输的时延是 2 个时钟周期,一个周期用来解码TDEST信号,另一个周期用来给仲裁器批准(前提是没有冲突)。对于 背靠背 传输,对于一个已经被允许的transaction,其时延是0。背靠背传输的transactions 之间的仲裁会导致 1 个时钟周期的时延。何哉?
2.3 Port Descriptions
- 具体可以查询文档,此处仅仅介绍一些特殊信号。
| 信号 | 描述 |
|---|---|
| TSTRB | 修饰符,用来指示TDATA中的字节们分别是data byte 还是 position byte |
| TID | data stream identifier,相当于stream ID,指示身份 |
| s_req_suppress | 置为高,则下个仲裁周期忽略这个总线。置为高时,这个bus不接收下一个仲裁;如果这个bus已经是被仲裁器允许的状态了的话,它会保持被允许状态直到仲裁周期结束 |
| s_decode_err | 表示刚接收到的传输中的TDEST值没有匹配到任何一个master,然后丢弃这个传输;仅在TDEST模式中存在 |
- 另外,如果选择 control register based routing 模式,会引入AXI4-Lite接口,接口信号可查26页表。
2.4 Register Space
- 当选择control register based routing 模式时,switch 会有一张寄存器表,如下表2-8.
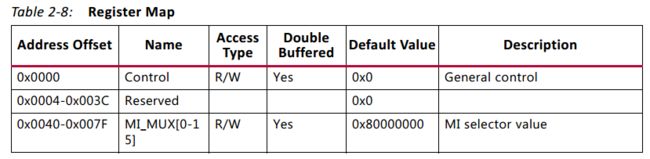
2.4.1 Control Register
- 上面表2-8中的第一行就是Control Register,共32位。这个寄存器的作用是 将master接口选择器的值(也就是路由寄存器的值)提交给switch。该寄存器描述如下表2-9.

- 由上可知,该寄存器虽然是32位,实际有用的就 1 位。利用 REG_UPDATE 这一位指示更新,并促使 switch 转入 reset 状态并持续大概 16 个时钟周期。(这是不是就是control register based routing 模式的时延??)
2.4.2 MI_MUX[0-15] Register
MI_MUX[0-15] 寄存器如表2-10所示。
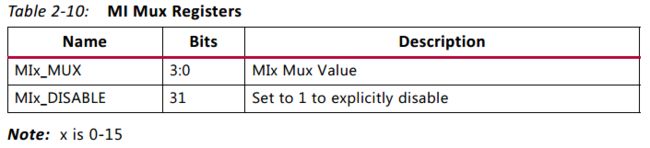
- 每个master 端口都有一个 MI_MUX 寄存器。每个 MIx_MUX 的值控制着 slave 接口的选择。比如说,MI4_MUX 的值是 0x1 的话,意味以为着 slave 接口1 会被路由到 master 接口4。
- MIx_DISABLE 可以设为1,从而将该master 置为disabled。
- 每个slave 接口只能被选择一次。如果有多于一个 MIx_MUX 的值被设置为选择同一slave,那么序号最低的master 获得该slave 的控制权,其他master 们被置为disabled。
- 各个寄存器的地址偏移量是分配好的,MI0_MUX 的地址偏移是 0x40,MI1_MUX 的地址偏移是 0x44,…,MI15_MUX 的地址偏移是 0x7C.
2.4.3 control register based routing 模式使用示例
- 假设我们现在要配置一个 4x4 的 switch,slave接口 SI1 路由到 master 接口 MI0,MI1 未使用,SI3 路由到 MI2,SI0 路由到 MI3。则示例代码如下:

- 注意最底下 commit register 的时候,在地址偏移 0x0 处写入 0x2。首先地址偏移 0x0,就是上面表2-8中第一行的control register,也就是表2-9中的寄存器。然后,写入的数值是 2,从而第二位 REG_UPDATE 的值为1,触发一次update,把更改过的 MI_MUX 的值传入 switch,更新路由表。
3. Clock & Reset
3.1 Clock
- 没什么特别内容,摘录两句:
- An optional feature for clock enables (ACLKEN ports) allows an extra level of control for essentially gating clocks.
- The optional AXI4-Lite control register interface operates asynchronously from the AXI4-Stream clocks.
3.2 Reset
- reset 是有些讲究的。reset 需要同步到 ACLK。为了确保在reset 期间不丢失数据,switch 会将所有的TREADY 和TVALID 输出信号都置为低电平,直到它们对应的源退出reset 状态。对于外部的将TREADY 或者 TVALID 信号输入到switch 的终端们(比如MAC 核),也应该将这两个信号置为低电平,直到switch 内部退出 reset 状态。
- 推荐:reset时,终端们将TREADY 和 TVALID 信号置为低电平,应该保证在 8 个时钟周期内。而ARESETn 信号应该保持至少 16 个时钟周期,从而确保系统内的其他接口们都能进入reset 状态,并在reset 状态结束前有时间去将它们的 TREADY 和 TVALID 输出信号置为低。
4.Design Flow Steps
4.1 AXI4-Stream Switch IP核的定制
- 各个基本信号基本都在前面介绍过,下面主要介绍在选择两种路由方式(TDEST路由 和 control register based routing)时,所需要进行的不同配置。
4.1.1 Data Flow Properties
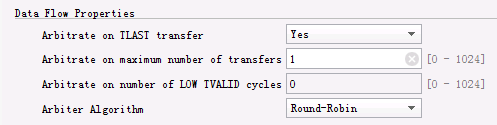
- 如上图所示,当选择TDEST路由方式时(也就是 Use control register routing 选项设为 NO),这时候才会出现Data Flow Properties 的选项们。
- Arbitrate on Maximum Number of Transfers:这个设置项表示仲裁器最多隔几个传输就把前面的“允许”撤销,进行新的仲裁。如果设为0,那么传输数量就是无限的,这时候Arbitrate on TLAST transfer 选项必须设为 Yes;如果设为1,那么每完成一次传输,switch 都会撤销前面的仲裁结果,开始新的仲裁;如果设为大于 1 的值,比如设为 n,那么每完成 n 次传输,就重新执行仲裁。
- Arbitrate on Number of LOW TVALID Cycles:这个选项允许在没有传输的情况下重新执行仲裁。switch 持续对一个被仲裁器“允许”的从master 到slave 的连接进行监视,对它的连续的 LOW TVALID 信号进行计数。如果计数值达到预设值,则重新执行仲裁。如果设为0,则不进行计数;如果有不止一个slave,不止一个master,而且Arbitrate on Maximum Number of Transfers 也设置为大于 1 的话,那么这个选项就不能设为 0。这是为了确保不发生死锁。
- Arbitrate on TLAST Transfer:如果设为 Yes,在switch 内部,会有一个从 slave 接口发送到 master 接口的 TLAST 信号,用来指示一个 transaction 的完成。然后仲裁器可以开始新一轮仲裁。这里TLAST应该和 slave 接口以及 master 接口上显示的 TLAST信号区分开,那些TLAST 信号是用来和外部设备通信的。
- 仲裁算法:有三种,如下:
- True Round-Robin 算法:对于所有出于活跃状态的slave 接口赋予同等的权重;而且如果一个slave 接口紧跟着一个已经被允许的slave 接口的话,那么新一轮仲裁中它拥有最高优先级。这种算法确保了每个活跃的slave 拥有同等的带宽资源。
- Round-Robin算法:类似与前者,不过新一轮的仲裁中每个slave 接口的优先级一致,而不是紧跟着一个刚被允许的接口的优先级最高。这种算法的带宽分配有可能不均匀。
- Fixed-Priority 固定优先级算法:slave接口 S00 拥有最高优先级,S01次之,…,S15 拥有最低优先级。这种算法中,低优先级的接口可能饿死。
- 为了区别以上三种算法,举个例子:比如对于一个有 4 个slave 接口,1 个master 接口的switch,其中 S00,S02 和 S03 在持续不断地要求传输 large transactions。经过一番仲裁之后,最终,在True Round-Robin 算法中,S00,S02 和 S03 都获得了33% 的带宽;而在Round-Robin算法中,S00 和 S03 各获得 25% 的带宽,而 S02 获得了 50% 的带宽,这是因为 S02 继承了 S01 的带宽;而在Fixed-Priority 固定优先级算法 中,S00 获得了100% 的带宽,S02 和 S03 都饿死了。
- 另外,无论哪种算法,如果Arbitrate on maximum number of transfers 选项设为 1 的话,仲裁器都是不支持来自同一slave 接口的背靠背传输的。这里面有两层意思:① 如果对于一个特定的master,只有一个slave 接口发来请求的话,则它们之间只能实现 50% 的带宽,另外 50% 就浪费了; ② 如果加上上一段所描述的场景,使用 固定优先级算法 的话,那么 S00 和 S02 会获得 50% 的带宽,S03 饿死。
4.1.2 Pipeline Registers
- 仅当Use control register routing设为 Yes 时,才有Pipeline Registers这些选项们。
- Enable Input Pipeline Register:When enabled, the slave interface side of the switch has register slices for each port at the IP boundary。
- Enable Output Pipeline Register:When enabled, the master interface side of the switch has register slices for each port at the IP boundary.