C#学习笔记(八)—–LINQ查询之延迟执行
LINQ查询之延迟执行
在LINQ中,另一个很重要的特性就是延迟执行,也可以说是延迟加载。它是指查询操作并不是在查询运算符定义的时候执行,真正使用集合中的数据时才执行,例如遍历数据集合时调用MoveNext方法会触发查询操作,下面是一个简单的示例:
var numbers = new List<int>();
numbers.Add (1);
IEnumerable<int> query = numbers.Select (n => n * 10); // Build query
numbers.Add (2); // Sneak in an extra element
foreach (int n in query)
Console.Write (n + "|"); // 10|20|在上面的示例中,在创建查询语句后又向集合中添加新的元素,这个新的元素最终也出现在查询结果中,这就是因为欻性能语句实在遇到foreach之后才真正执行的,而foreach在numbers.Add(2)之后,所以输出集合中包含了这个元素。这是所谓的推迟或延迟执行,他与委托实现的效果相同:
Action a = () => Console.WriteLine ("Foo");
// 上面这句实际上并不会在控制台上面输出任何东西,现在,我们再写下面一句:
a(); // 延迟执行的道理在这里!这种特性就是所谓的延迟加载,绝大部分标准的LINQ查询运算符都具有延迟加载这种特性,当然也有例外,以下是几个例外的运算符:
①那些返回单个元素或者返回一个数值的运算符,如First或者Count。
②转换运算符:ToArray、ToList、ToDictionary、ToLookUp等等ToXXX方法。
以上这些运算符都会触发LINQ语句立即执行,因为他们的返回值类型不支持延迟加载。例如Count运算符,它返回一个简单的整型数据,而一个整型数据不会用到遍历操作,因此Count运算符会被立即执行,如下面这个实例所示:
int matches = numbers.Where (n => n < 2).Count(); // 1在LINQ中,延迟加载特性具有很重要的意义,这种设计将查询的创建和查询的执行进行了解耦,这使得我们可以将查询分为多个步骤来创建,有利于查询表达式的书写,而且在执行的时候按照一个完整的结构去查询,减少了对集合的查询次数,这种特性在对数据库的查询中尤为重要。需要注意的是,子查询中表达式有额外的延迟加载限制,无论是聚合运算符还是转换运算符,如果出现在子查询中,他们都会被强制的进行延迟加载。后面将会讨论他们。
重复执行
延迟执行导致的后果是,当两次同时遍历一个集合时,查询被重复执行。也就是当多次查询同一个数据集时,它后一次遍历不会使用前一次遍历的结果,而是再次到数据源中进行一次新的查询。如下面这个示例:
var numbers = new List<int>() { 1, 2 };
IEnumerable<int> query = numbers.Select (n => n * 10);
foreach (int n in query) Console.Write (n + "|"); // 10|20|
numbers.Clear();
foreach (int n in query) Console.Write (n + "|"); // 这种重复查询是LINQ的缺点,他带来以下两个方面的影响:
①无法缓存在某一时刻的状态,以供后面的代码使用。
②对于一些远程数据源,例如远端的数据库,这种重复执行会大大降低执行效率。
这种问题是可以解决的。一般使用转换运算符来绕过这种重复执行,如ToArray或者ToList等ToXXX。ToArray是把结果集中的元素拷贝到一个新的数组中;ToList也一样的功能。这两种方式都可以保存查询结果,下次需要使用结果集时,直接使用这两种结合中保存的数据即可,下面是一段示例:
var numbers = new List() { 1, 2 };
List timesTen = numbers
.Select (n => n * 10)
.ToList(); // 立即执行,将结果存放于List中
numbers.Clear();
Console.WriteLine (timesTen.Count); // 仍然是2,没有被清除 捕获的变量
还是闭包的问题。
延迟加载还会带来另一个问题,如果在Lambda表达式中使用了本地变量,那么Lambda表达式使用的是这个本地变量的引用,而不是他拷贝。这就意味着,如果在其他地方改变了本地变量的值,Lambda表达式中的结果也会发生改变。如下面的示例所示:
int[] numbers = { 1, 2 };
int factor = 10;
IEnumerable<int> query = numbers.Select (n => n * factor);
factor = 20;
foreach (int n in query) Console.Write (n + "|"); // 20|40|对于上面的话的理解应该是由于延迟执行导致取值发生在foreach循环里面,那么在这之前对factor做的任何改变都会影响到lambda获取的局部变量的值,因为①lambda会自动更新值②lambda总是在真正MoveNext的时候才获取值。
尽管很多人知道这个问题,但是还是会犯错,特别是在foreach循环中更容易出错。如下面的实例,去掉一个字符串中的元音字符。首先是下面这种写法,看起来效率不高,但可以得到正确的结果:
IEnumerable query = "Not what you might expect";
query = query.Where (c => c != 'a');
query = query.Where (c => c != 'e');
query = query.Where (c => c != 'i');
query = query.Where (c => c != 'o');
query = query.Where (c => c != 'u');
foreach (char c in query) Console.Write (c); // Nt wht y mght xpct 如果使用foreach语句来重构这段代码,会使整个查询更简洁高效,现在让我们来看看重构后会发生什么事情,代码如下:
IEnumerable<char> query = "Not what you might expect";
string vowels = "aeiou";
for (int i = 0; i < vowels.Length; i++)
query = query.Where (c => c != vowels[i]);
foreach (char c in query) Console.Write (c);列举查询时会抛出IndexOutOfRangeException异常。前面我们也讨论过,这是因为编译器将for循环中的迭代变量作用域定义为与循环外部声明的一样了(意即捕获了局部变量形成闭包)。因此,每一个闭包都会捕获到相同的变量(i),查询在执行实际列举步骤时,他的值是5.为了解决这个问题,必须将循环变量赋值给一个临时变量:
for (int i = 0; i < vowels.Length; i++)
{
char vowel = vowels[i];
query = query.Where (c => c != vowel);
}这就迫使在每一次循环迭代中获得一个新的变量值。
**提示:**C#5.0中可以将它变成foreach循环:
foreach (char vowel in vowels)
query = query.Where (c => c != vowel);这个方法在C#5.0可以生效,但是在之前的版本同样会失败,原因在前面的内容中讲过。
延迟加载的工作原理
LINQ查询操作符通过返回装饰器序列提供延迟执行。与传统的集合类不同,例如数组或链表(他们都代表了真正的内存。你让一个返回IEnumerable的东西怎么去代表一个真正的内存?),装饰器序列(一般而言)没有自己的支持结构来存储元素,相反,它封装了在运行时提供的另一个序列,它将保持一个永久的依赖项。当您从装饰器请求数据时,它轮流请求来自包装输入序列的数据。
调用Where的时候仅仅是构造了一个装饰器序列,在Where内部所做的操作都非常简单,根据lambda表达式中指定的查询条件,对输入集合重新进行了筛选,保留那些符合条件的元素的指针引用,当外部遍历Where的返回值时,Where会到它所关联的集合中进行真正的查询,然后返回查询结果。
IEnumerable<int> lessThanTen = new int[] { 5, 12, 3 }.Where (n => n < 10);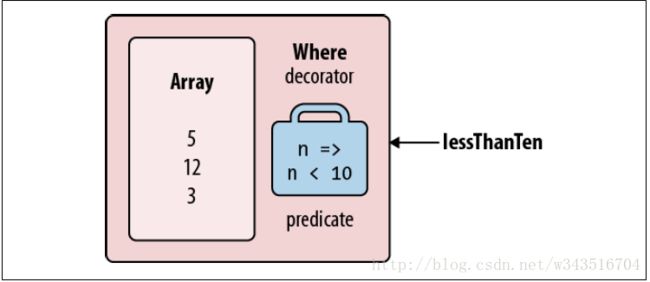
当执行lessThanThen操作时,实际上,就是使用where运算符对封装序列进行筛选。
当需要使用一些具有特殊功能的运算符时,我们可以自己动手使用C#中的迭代器轻松的实现。例如下面这个实例所示,实现一个自定义的Select运算符:
public static IEnumerable Select
(this IEnumerable source, Func selector)
{
foreach (TSource element in source)
yield return selector (element);
} 这个方法通过使用yield return而变成一个C#的迭代器,以下是一种快捷方式:
public static IEnumerable Select
(this IEnumerable source, Func selector)
{
return new SelectSequence (source, selector);
} SelectSequence是一个(编译器编写的)类,它的枚举器封装迭代器方法中的逻辑。
因此,当您调用诸如Select或Where之类的操作符时,您所做的只是实例化一个可以装饰输入序列的可枚举类。
连续使用封装集合
如果使用运算符流语法对集合进行查询,会创建多个层次的封装集合。一下面的这个查询为例:
IEnumerable query = new int[] { 5, 12, 3 }.Where (n => n < 10)
.OrderBy (n => n)
.Select (n => n * 10); 下图演示了执行这个语句时对集合进行处理的过程,这是一个完整的对象处理模型,需要注意的是,这个对象模型一定是在查询语句被真正执行之前就创建好的:
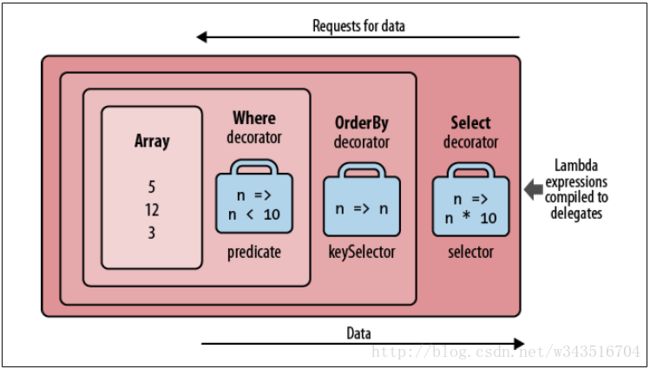
在使用LINQ语句的返回集合时,实际是在原始的输入集合中进行查询,只不过在进入原始集合之前,会经过上面这些装饰器的处理,在不同的层次的装饰器中,系统会对查询中相应的修改,这使得LINQ语句使用的各种查询条件会被反映到最终的查询结果中。如果在LINQ查询语句的最后加上ToList方法,会强制LINQ语句立即执行,查询结果会被保存到一个List类型的集合中。
下图使用UML的方式重新演示了装饰器之间的层次结构。从中可以看出,Select子句的装饰器指向orderby的装饰器,后者又指向了where的装饰器,而where最终指向一个实际的真实存在于内存中的数组。LINQ查询的延迟加载有这样的一个功能,不论查询语句是连续书写的(像上面这样select、orderby、where)还是分多个步骤完成的,在执行前,都会被组合成一个完整的对象模型,而写两种书写方式所产生的对象模型是一样的,例如下面这种书写方式并不会导致查询被多次执行:
IEnumerable
source = new int[] { 5, 12, 3 },
filtered = source .Where (n => n < 10),
sorted = filtered .OrderBy (n => n),
query = sorted .Select (n => n * 10); 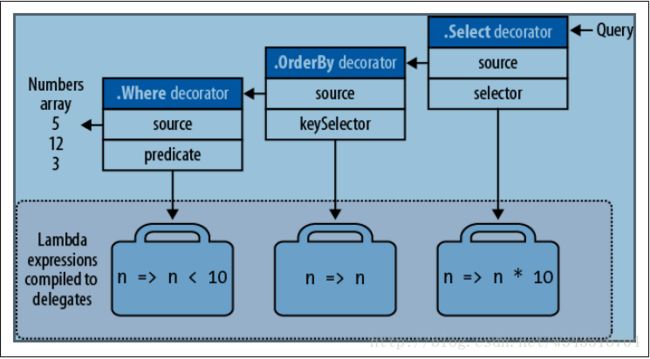
查询语句的执行方式
下面这几行代码遍历了前面得到的query集合:
foreach (int n in query) Console.WriteLine (n);
30
50这个foreach遍历了query集合,并输出了集合中的元素。分析代码可知,foreach会调用select装饰器(整个lINQ语句最外部的运算符)中的GetEnumeator方法,由这个方法拉开整个查询的帷幕。结果是一个枚举器的链表,它在结构上反映了装饰序列的链。下图展示了随着枚举的展开,执行的流程。

在本章的第一部分中,我们将查询描述为传送带的生产线。
扩展这个类比,我们可以说LINQ查询是一个懒惰的生产线,传送带只根据需要滚动元素。
构造一个查询就是构造一个生产线,所有的东西都在一个地方,但是没有任何滚动。
然后,当使用者请求一个元素(在查询中枚举)时,最右边的传送带会激活;这反过来会触发其他的,当需要输入序列元素时。
LINQ遵循的是一个需求驱动的拉模型,而不是一个供给驱动的驱动模型。
这是很重要的,因为我们将会看到后期,允许LINQ扩展到查询SQL数据库。