第四段第一天_数学模型之层次分析法
层次分析法
-
[ 定义]
-
[ 步骤]
-
[ 优点介绍]
-
[ 缺点介绍]
-
[程序 ]
1:定义
所谓层次分析法,是指将一个复杂的多目标决策问题作为一个系统,将目标分解为多个目标或准则,进而分解为多指标(或准则、约束)的若干层次,通过定性指标模糊量化方法算出层次单排序(权数)和总排序,以作为目标(多指标)、多方案优化决策的系统方法。
层次分析法是将决策问题按总目标、各层子目标、评价准则直至具体的备投方案的顺序分解为不同的层次结构,然后得用求解判断矩阵特征向量的办法,求得每一层次的各元素对上一层次某元素的优先权重,最后再加权和的方法递归并各备择方案对总目标的最终权重,此最终权重最大者即为最优方案。
这里所谓“优先权重”是一种相对的量度,它表明各备择方案在某一特点的评价准则或子目标,标下优越程度的相对量度,以及各子目标对上一层目标而言重要程度的相对量度。
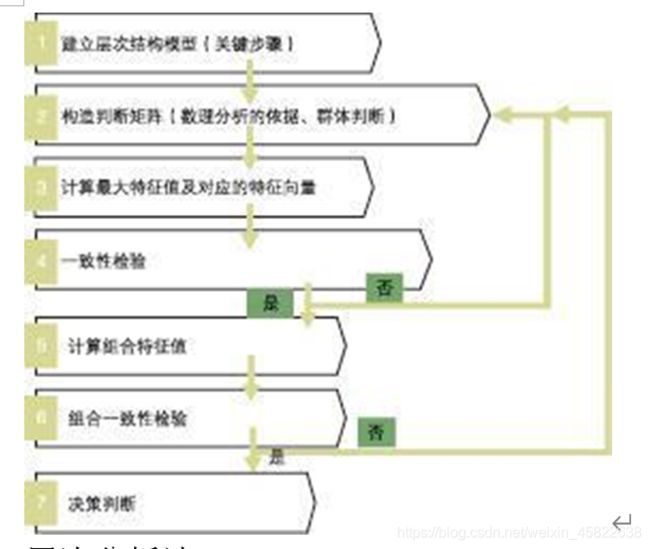
2:步骤
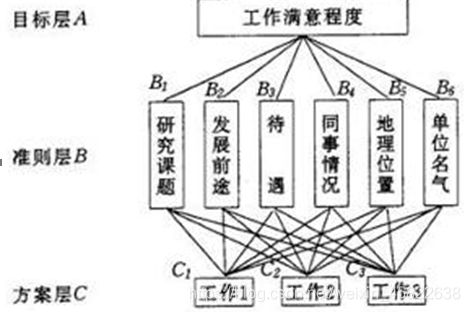
1、建立层次结构模型。在深入分析实际问题的基础上,将有关的 各个因素按照不同属性自上而下地分解成若干层次,同一层的诸因素从属于上一层的因素或对上层因素有影响,同时又支配下一层的因素或受到下层因素的作用。最上层为目标层,通常只有1个因素,最下层通常为方案或对象层,中间可以有一个或几个层次,通常为准则或指标层。当准则过多时(譬如多于9个)应进一步分解出子准则层。
2、构造成对比较阵。从层次结构模型的第2层开始,对于从属于(或影响)上一层每个因素的同一层诸因素,用成对比较法和1—9比较尺度构追成对比较阵,直到最下层。
3、计算权向量并做一致性检验。对于每一个成对比较阵计算最大特征根及对应特征向量,利用一致性指标、随机一致性指标和一致性比率做一致性检验。若检验通过,特征向量(归一化后)即为权向量:若不通过,需重新构追成对比较阵。
4、计算组合权向量并做组合一致性检验。计算最下层对目标的组合权向量,并根据公式做组合一致性检验,若检验通过,则可按照组合权向量表示的结果进行决策,否则需要重新考虑模型或重新构造那些一致性比率较大的成对比较阵。
3.优点介绍
- 系统性的分析方法
层次分析法把研究对象作为一个系统,按照分解、比较判断、综合的思维方式进行决策,成为继机理分析、统计分析之后发展起来的系统分析的重要工具。系统的思想在于不割断各个因素对结果的影响,而层次分析法中每一层的权重设置最后都会直接或间接影响到结果,而且在每个层次中的每个因素对结果的影响程度都是量化的,非常清晰、明确。这种方法尤其可用于对无结构特性的系统评价以及多目标、多准则、多时期等的系统评价。
- 简洁实用的决策方法
这种方法既不单纯追求高深数学,又不片面地注重行为、逻辑、推理,而是把定性方法与定量方法有机地结合起来,使复杂的系统分解,能将人们的思维过程数学化、系统化,便于人们接受,且能把多目标、多准则又难以全部量化处理的决策问题化为多层次单目标问题,通过两两比较确定同一层次元素相对上一层次元素的数量关系后,最后进行简单的数学运算。即使是具有中等文化程度的人也可了解层次分析的基本原理和掌握它的基本步骤,计算也经常简便,并且所得结果简单明确,容易为决策者了解和掌握。
- 所需定量数据信息较少
层次分析法主要是从评价者对评价问题的本质、要素的理解出发,比一般的定量方法更讲求定性的分析和判断。由于层次分析法是一种模拟人们决策过程的思维方式的一种方法,层次分析法把判断各要素的相对重要性的步骤留给了大脑,只保留人脑对要素的印象,化为简单的权重进行计算。这种思想能处理许多用传统的最优化技术无法着手的实际问题。
4.缺点介绍
- 不能为决策提供新方案
层次分析法的作用是从备选方案中选择较优者。这个作用正好说明了层次分析法只能从原有方案中进行选取,而不能为决策者提供解决问题的新方案。这样,我们在应用层次分析法的时候,可能就会有这样一个情况,就是我们自身的创造能力不够,造成了我们尽管在我们想出来的众多方案里选了一个最好的出来,但其效果仍然不够人家企业所做出来的效果好。而对于大部分决策者来说,如果一种分析工具能替我分析出在我已知的方案里的最优者,然后指出已知方案的不足,又或者甚至再提出改进方案的话,这种分析工具才是比较完美的。但显然,层次分析法还没能做到这点。
- 定量数据较少,定性成分多,不易令人信服
层次分析法在如今对科学的方法的评价中,一般都认为一门科学需要比较严格的数学论证和完善的定量方法。但现实世界的问题和人脑考虑问题的过程很多时候并不是能简单地用数字来说明一切的。层次分析法是一种带有模拟人脑的决策方式的方法,因此必然带有较多的定性色彩。这样,当一个人应用层次分析法来做决策时,其他人就会说:为什么会是这样?能不能用数学方法来解释?如果不可以的话,你凭什么认为你的这个结果是对的?你说你在这个问题上认识比较深,但我也认为我的认识也比较深,可我和你的意见是不一致的,以我的观点做出来的结果也和你的不一致,这个时候该如何解决?
比如说,对于一件衣服,我认为评价的指标是舒适度、耐用度,这样的指标对于女士们来说,估计是比较难接受的,因为女士们对衣服的评价一般是美观度是最主要的,对耐用度的要求比较低,甚至可以忽略不计,因为一件便宜又好看的衣服,我就穿一次也值了,根本不考虑它是否耐穿我就买了。这样,对于一个我原本分析的‘购买衣服时的选择方法’的题目,充其量也就只是‘男士购买衣服的选择方法’了。也就是说,定性成分较多的时候,可能这个研究最后能解决的问题就比较少了。
对于上述这样一个问题,其实也是有办法解决的。如果说我的评价指标太少了,把美观度加进去,就能解决比较多问题了。指标还不够?我再加嘛!还不够?再加!还不够?!不会吧?你分析一个问题的时候考虑那么多指标,不觉得辛苦吗?大家都知道,对于一个问题,指标太多了,大家反而会更难确定方案了。这就引出了层次分析法的第三个不足之处。
- 指标过多时数据统计量大,且权重难以确定
指标的选取数量很可能也就随之增加。这就像系统结构理论里,我们要分析一般系统的结构,要搞清楚关系环,就要分析到基层次,而要分析到基层次上的相互关系时,我们要确定的关系就非常多了。指标的增加就意味着我们要构造层次更深、数量更多、规模更庞大的判断矩阵。那么我们就需要对许多的指标进行两两比较的工作。由于一般情况下我们对层次分析法的两两比较是用1至9来说明其相对重要性,如果有越来越多的指标,我们对每两个指标之间的重要程度的判断可能就出现困难了,甚至会对层次单排序和总排序的一致性产生影响,使一致性检验不能通过,也就是说,由于客观事物的复杂性或对事物认识的片面性,通过所构造的判断矩阵求出的特征向量(权值)不一定是合理的。不能通过,就需要调整,在指标数量多的时候这是个很痛苦的过程,因为根据人的思维定势,你觉得这个指标应该是比那个重要,那么就比较难调整过来,同时,也不容易发现指标的相对重要性的取值里到底是哪个有问题,哪个没问题。这就可能花了很多时间,仍然是不能通过一致性检验,而更糟糕的是根本不知道哪里出现了问题。也就是说,层次分析法里面没有办法指出我们的判断矩阵里哪个元素出了问题。
- 特征值和特征向量的精确求法比较复杂
计算方法
标度:1~9尺度

案例:
A:

B:

C:
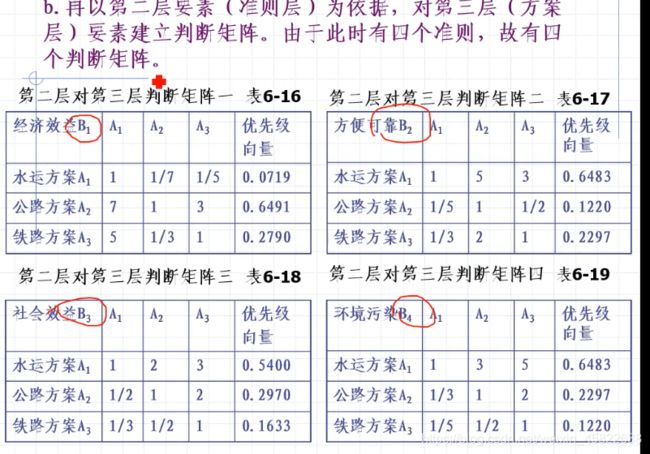
D:
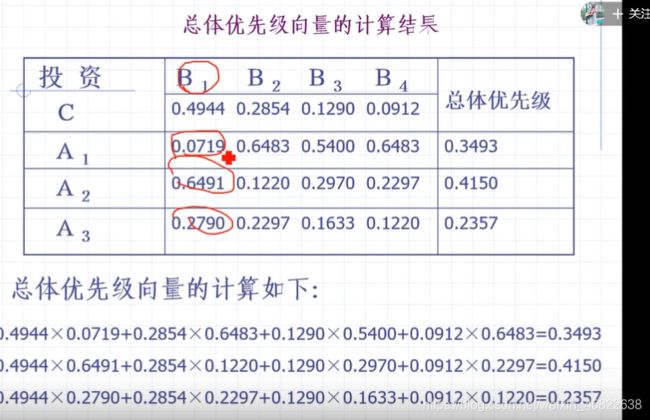
计算一致性检验

代码:
matlab程序
>> fid=fopen('txt3.txt','r');
n1=6;n2=3;
a=[];
for i=1:n1
tmp=str2num(fgetl(fid));
a=[a;tmp]; %读准则层判断矩阵
end
for i=1:n1
str1=char(['b',int2str(i),'=[];']);
str2=char(['b',int2str(i),'=[b',int2str(i),';tmp];']);
eval(str1);
for j=1:n2
tmp=str2num(fgetl(fid));
eval(str2); %读方案层的判断矩阵
end
end
ri=[0,0,0.58,0.90,1.12,1.24,1.32,1.41,1.45]; %一致性指标
[x,y]=eig(a);
lamda=max(diag(y));
num=find(diag(y)==lamda);
w0=x(:,num)/sum(x(:,num));
cr0=(lamda-n1)/(n1-1)/ri(n1)
for i=1:n1
[x,y]=eig(eval(char(['b',int2str(i)]))); lamda=max(diag(y));
num=find(diag(y)==lamda);
w1(:,i)=x(:,num)/sum(x(:,num));
cr1(i)=(lamda-n2)/(n2-1)/ri(n2);
end
cr1, ts=w1*w0, cr=cr1*w0