Milvus QueryCoordV2学习笔记
前言
年前看了些Milvus QueryCoordV2的代码整理了一些笔记(算是半成品),省去了很多细节。一直为做最终的整理, 直到准备去社区做分享才开始临时抱佛脚翻笔记, 之前看的东西也快忘了。本着输出倒逼输入的原则,还是把他发出来提供给大家指正。最少也是给大家提供个索引
以下是内容目录
- 从一个Load Collection 大概的流程串起来
- 分别看下这几个组件的实现
- 元数据
- Checker
- TaskScheduler & disHandler
- Observer
- NodeUp/NodeDown
LoadCollection流程
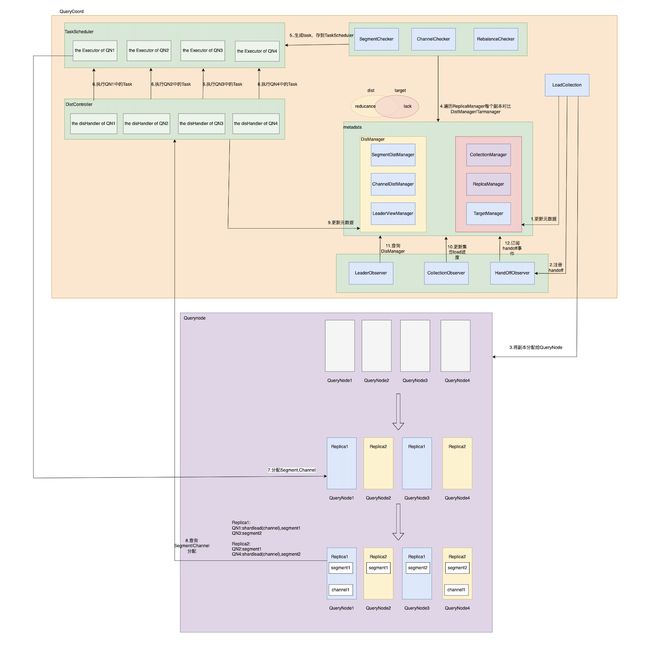
概括
QueryCoordV2负责将Segment,Channel分配到QueryNode,更新QueryNode中的LeaderView信息。相较QueryCoordV1,QueryCoordV2在分配数据过程都是异步的操作。在分配的逻辑上也会每个QueryNode粒度分别去分配。
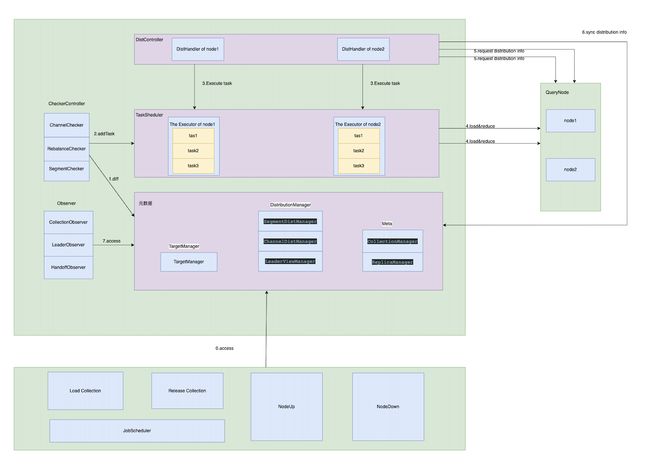
元数据组件
1.Meta
在ETCD中维护集合和副本的信息,包含了两个Manager
-
CollectionManager:维护集群的集合和分区基础信息和Load进度type CollectionManager struct { rwmutex sync.RWMutex collections map[UniqueID]*Collection partitions map[UniqueID]*Partition store Store } type Collection struct { *querypb.CollectionLoadInfo LoadPercentage int32 //Load进度 CreatedAt time.Time UpdatedAt time.Time } -
ReplicaManager:维护副本和分配给这个副本的QueryNode节点IDtype ReplicaManager struct { rwmutex sync.RWMutex idAllocator func() (int64, error) replicas map[UniqueID]*Replica store Store } type Replica struct { ID int64 CollectionID int64 Nodes []int64 //分配给这个副本的QueryNode节点ID }
2.DistributionManager
在内存中维护Segment/Channel/LeaderView在QueryNode实际的分配快照。包含了三个Manager
-
SegmentDisManager: 记录Segment的分配情况type SegmentDistManager struct { rwmutex sync.RWMutex // nodeID -> []*Segment segments map[UniqueID][]*Segment } type Segment struct { *datapb.SegmentInfo Node int64 // Node the segment is in Version int64 // Version is the timestamp of loading segment } -
ChannelDistManager:记录Channel分配的情况type ChannelDistManager struct { rwmutex sync.RWMutex // NodeID -> Channels channels map[UniqueID][]*DmChannel } type DmChannel struct { *datapb.VchannelInfo Node int64 Version int64 }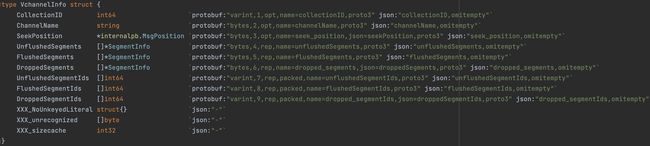
-
LeaderViewManager: 记录每个节点Leader与Segment/Channel的之间的关系type LeaderViewManager struct { rwmutex sync.RWMutex views map[int64]channelViews // 节点ID -> Views (one per shard) } type channelViews map[string]*LeaderView //channel -> View type LeaderView struct { ID int64 CollectionID int64 Channel string Segments map[int64]*querypb.SegmentDist GrowingSegments typeutil.UniqueSet }
3.TargetManager
记录需要分配给QueryNode的Segment/Channel
type TargetManager struct {
rwmutex sync.RWMutex
segments map[int64]*datapb.SegmentInfo
dmChannels map[string]*DmChannel
}
后面handoff/load等在QueryNode的操作,会修改TargetManager。通过TargetManager和DistManager,Checker会比对每个replica的差异情况,生成LoadTask/ReduceTask。接下来我们看下Checker的逻辑
Checker
刚才我们提到Checker比对TargetManager和DistManager之间的差异,生成LoadTask/ReduceTask的逻辑。简单说下
实现入口
CheckerController会有个协程定时去check,生成Task加入到TaskScheduler,现在已有的Checker :
- SegmentChecker: 生成Segment相关的Task
- ChannelChecker: 生成Channel相关的Task
- RebalanceChecker: 根据Rebalance策略,生成Loaded Collection的Segment/Channel Task
// check is the real implementation of Check
func (controller *CheckerController) check(ctx context.Context) {
tasks := make([]task.Task, 0)
for _, checker := range controller.checkers {
tasks = append(tasks, checker.Check(ctx)...)
}
for _, task := range tasks {
err := controller.scheduler.Add(task)
if err != nil {
task.Cancel()
continue
}
}
}
Check逻辑
用SegmentChecker举例:
-
对比
TargetManager和每个replica的Segment集合 -
如图,针对lacks情况生成LoadTask,针对redundancies情况生成ReduceTask
lacks, redundancies := diffSegments(targets, dists) tasks := c.createSegmentLoadTasks(ctx, lacks, replica) ret = append(ret, tasks...) tasks = c.createSegmentReduceTasks(ctx, redundancies, replica.GetID(), querypb.DataScope_All) ret = append(ret, tasks...)
-
根据数据行数均衡分配Segment
sort.Slice(segments, func(i, j int) bool { return segments[i].GetNumOfRows() > segments[j].GetNumOfRows() }) plans := make([]SegmentAssignPlan, 0, len(segments)) for _, s := range segments { // pick the node with the least row count and allocate to it. ni := queue.pop().(*nodeItem) plan := SegmentAssignPlan{ From: -1, To: ni.nodeID, Segment: s, } plans = append(plans, plan) // change node's priority and push back p := ni.getPriority() ni.setPriority(p + int(s.GetNumOfRows())) queue.push(ni) } -
此外针对其他情况,如released的collection;重复的Segment;Growing Segment对应的Sealed Segment已经load等情况都会生成相应的Task
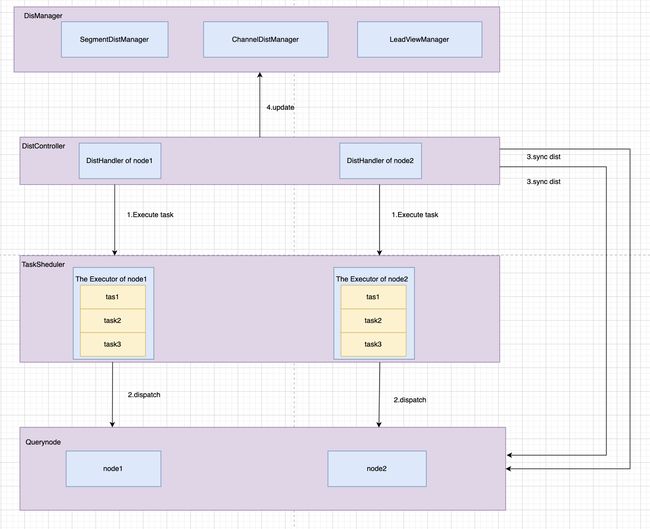
TaskScheduler&DistHandler
TaskScheduler和其他组件里的Sheduler不一样,没有队列,不会主动去执行任务,更像是一个保存Task的容器。为每个在线的node维护一个Executor。
func (scheduler *taskScheduler) AddExecutor(nodeID int64) {
scheduler.rwmutex.Lock()
defer scheduler.rwmutex.Unlock()
if _, exist := scheduler.executors[nodeID]; exist {
return
}
executor := NewExecutor(scheduler.meta,
scheduler.distMgr,
scheduler.broker,
scheduler.targetMgr,
scheduler.cluster,
scheduler.nodeMgr)
scheduler.executors[nodeID] = executor
executor.Start(scheduler.ctx)
log.Info("add executor for new QueryNode", zap.Int64("nodeID", nodeID))
}
QueryCoord会为每个node启动一个DistHandler,DistHandler会维护一个协程
-
定时获取Segment,Channel的分配信息更新DIstManager
-
通过TaskScheduler的Executor执行对应node的任务
func (dh *distHandler) handleDistResp(resp *querypb.GetDataDistributionResponse) {
node := dh.nodeManager.Get(resp.GetNodeID())
if node != nil {
node.UpdateStats(
session.WithSegmentCnt(len(resp.GetSegments())),
session.WithChannelCnt(len(resp.GetChannels())),
)
}
dh.updateSegmentsDistribution(resp)
dh.updateChannelsDistribution(resp)
dh.updateLeaderView(resp)
dh.scheduler.Dispatch(dh.nodeID)
}
Observer
前面提到Checker通过全量比对元数据生成Task存放在TaskScheduler,然后每个DisHandler都会有一个对应的协程定时分发TaskScheduler的任务到对应的QueryNode,还会同步QueryNode中Segment,Channel的分配情况到QueryCoord中的DistManager。大致的流程已经清晰了,还有一些细节如
- Collection啥时候算Loaded状态,在哪里控制load超时
- 订阅到合并的Segment或者新Sealed Segment,QueryCoord怎么处理的
- 新的loaded或者 handoff 成功后,如何让 QueryNode上的shadeLeader知道
这三个Observer分别解决这三个问题
CollectionObserver
loaded状态的集合是否晖被(nodeup影响)
1.定时更新Collection/Partition的Load状态
2.如果Load超时,放弃Load
实现
从TargetManager, LeaderViewManager ,ReplicaManager获取查看load 进度
分子 :LeaderViewManager中: Segment的副本数 +Channel副本数
分母 : (TargetManager :(Segment个数+Channel个数))*(ReplicaManager:副本数)
HandoffObserver
从ETCD订阅到Handoff事件:
- 通过修改TargetManager, 将新Segment分配到QueryNode
- 通过反查 LeaderViewManager确认是否handof后的segment是否部署完成,如果完成,TargetManager删掉过期的Segement
实现
- 从ETCD读取需要Handoff的segment
- 从TargetManager 读取这个Segment的CompactionFrom(由哪些Segment合并来的)
- 向TargetManager 添加这个新的Segment
- 去LeaderViewManager查询,如果Handoff Segment已经部署好。去TargetManager 删掉CompactionFrom Segment
LeaderObserver
从在LeaderViewManager 和SegmentDistManager 获取Segment元数据做对比更新QueryNode中ShardLeader的快照
-
在LeaderViewManager 获取 leader 的快照
-
在SegmentDistManager 获取 Segment的快照
Remove/Load的条件
-
Load : dist的segment信息的版本高于 leaderview
ret := make([]*querypb.SyncAction, 0) dists = utils.FindMaxVersionSegments(dists) for _, s := range dists { version, ok := leaderView.Segments[s.GetID()] if ok && version.GetVersion() >= s.Version || !o.target.ContainSegment(s.GetID()) { continue } ret = append(ret, &querypb.SyncAction{ Type: querypb.SyncType_Set, PartitionID: s.GetPartitionID(), SegmentID: s.GetID(), NodeID: s.Node, Version: s.Version, }) } -
Remove :
Segment在TargetManager和DistManaager都不存在ret = append(ret, &querypb.SyncAction{ Type: querypb.SyncType_Remove, SegmentID: sid, })
LoadCollection/NodeUp/NodeDown
1.LoadCollection
将副本均摊到不同节点,用ReplicaManager维护起来。
replicas, err := utils.SpawnReplicas(job.meta.ReplicaManager,
job.nodeMgr,
req.GetCollectionID(),
req.GetReplicaNumber())
集合注册给HandOffObserver
job.handoffObserver.Register(job.CollectionID())
err = utils.RegisterTargets(job.ctx,
job.targetMgr,
job.broker,
req.GetCollectionID(),
partitions)
注册给TargetManager
err = utils.RegisterTargets(job.ctx,
job.targetMgr,
job.broker,
req.GetCollectionID(),
partitions)
2.NodeUp
-
TaskScheduler 添加新Executor
s.taskScheduler.AddExecutor(node) -
为新节点添加 新的DistHandler
s.distController.StartDistInstance(s.ctx, node) -
摊平一些replica到新节点
for _, collection := range s.meta.CollectionManager.GetAll() { log := log.With(zap.Int64("collectionID", collection)) replica := s.meta.ReplicaManager.GetByCollectionAndNode(collection, node) if replica == nil { replicas := s.meta.ReplicaManager.GetByCollection(collection) sort.Slice(replicas, func(i, j int) bool { return replicas[i].Nodes.Len() < replicas[j].Nodes.Len() }) replica := replicas[0] // TODO(yah01): this may fail, need a component to check whether a node is assigned err := s.meta.ReplicaManager.AddNode(replica.GetID(), node) //3. pour replica to new Node if err != nil { log.Warn("failed to assign node to replicas", zap.Int64("replicaID", replica.GetID()), zap.Error(err), ) } log.Info("assign node to replica", zap.Int64("replicaID", replica.GetID())) } }
func (s *Server) handleNodeUp(node int64) {
log := log.With(zap.Int64("nodeID", node))
s.taskScheduler.AddExecutor(node) //1. addExecutor
s.distController.StartDistInstance(s.ctx, node) //2.new DistHandler
for _, collection := range s.meta.CollectionManager.GetAll() {
log := log.With(zap.Int64("collectionID", collection))
replica := s.meta.ReplicaManager.GetByCollectionAndNode(collection, node)
if replica == nil {
replicas := s.meta.ReplicaManager.GetByCollection(collection)
sort.Slice(replicas, func(i, j int) bool {
return replicas[i].Nodes.Len() < replicas[j].Nodes.Len()
})
replica := replicas[0]
// TODO(yah01): this may fail, need a component to check whether a node is assigned
err := s.meta.ReplicaManager.AddNode(replica.GetID(), node) //3. pour replica to new Node
if err != nil {
log.Warn("failed to assign node to replicas",
zap.Int64("replicaID", replica.GetID()),
zap.Error(err),
)
}
log.Info("assign node to replica",
zap.Int64("replicaID", replica.GetID()))
}
}
}
3.NodeDown
func (s *Server) handleNodeDown(node int64) {
log := log.With(zap.Int64("nodeID", node))
s.taskScheduler.RemoveExecutor(node)
s.distController.Remove(node)
// Refresh the targets, to avoid consuming messages too early from channel
// FIXME(yah01): the leads to miss data, the segments flushed between the two check points
// are missed, it will recover for a while.
channels := s.dist.ChannelDistManager.GetByNode(node)
for _, channel := range channels {
partitions, err := utils.GetPartitions(s.meta.CollectionManager,
s.broker,
channel.GetCollectionID())
if err != nil {
log.Warn("failed to refresh targets of collection",
zap.Int64("collectionID", channel.GetCollectionID()),
zap.Error(err))
}
err = utils.RegisterTargets(s.ctx,
s.targetMgr,
s.broker,
channel.GetCollectionID(),
partitions)
if err != nil {
log.Warn("failed to refresh targets of collection",
zap.Int64("collectionID", channel.GetCollectionID()),
zap.Error(err))
}
}
// Clear dist
s.dist.LeaderViewManager.Update(node)
s.dist.ChannelDistManager.Update(node)
s.dist.SegmentDistManager.Update(node)
// Clear meta
for _, collection := range s.meta.CollectionManager.GetAll() {
log := log.With(zap.Int64("collectionID", collection))
replica := s.meta.ReplicaManager.GetByCollectionAndNode(collection, node)
if replica == nil {
continue
}
err := s.meta.ReplicaManager.RemoveNode(replica.GetID(), node)
if err != nil {
log.Warn("failed to remove node from collection's replicas",
zap.Int64("replicaID", replica.GetID()),
zap.Error(err),
)
}
log.Info("remove node from replica",
zap.Int64("replicaID", replica.GetID()))
}
// Clear tasks
s.taskScheduler.RemoveByNode(node)
}
- 从TaskExecutor删掉Executor
- 删掉对应节点的DIstHandler
- 清空TargetManger中的数据
- 清空DistManager中的数据
- 清空meta中的数据
- 清空TaskScheduler中的数据