【JLOI】02金猪贺岁-贪心策略
【JLOI】02金猪贺岁-贪心策略
贪心策略!
NOIP普及组重点题型
然后,别以为算法很基础,IOI都在考贪心策略!
你问我贪心策略是啥?那就是:局部最优解就是最优解
【引入例题】P1031 均分纸牌
思考:
【算法1】如果你是大神,你可以发现N很小,然后你就可以N^3地dp
【算法2】考虑贪心。我们可以用转化法,令opt为原数组的平均数,让每个数字-=opt,然后当a[i](第i堆纸牌与平均数的关系)不等于0时,a[i+1]=a[i+1]+q[i],移动次数加1。
【算法3】由于只能移动相邻的,就可以大暴力
算法2与算法3的时间复杂度均为O(n)
算法2代码:
#include贪心的美妙之处就在于:一题一贪,策略永不同。事实上考试时不用证明贪心的正确性,只要找到规律即可。但是还是应该了解贪心的证明
对于这一道题:由于只能交换相邻的,所以如果a[i]不符合条件就推拿到a[i+1],这样的策略显然是正确的
【引入例题】P1803 凌乱的yyy / 线段覆盖
著名又经典的贪心问题
即最大不重线段覆盖问题
思考这类问题,可以画图
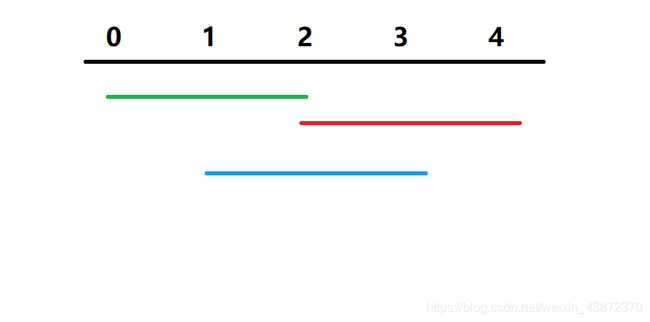
答案当然选绿色&红色线段
我们开始思考贪心策略:
按长度从小到大排?
十分容易举出反例:
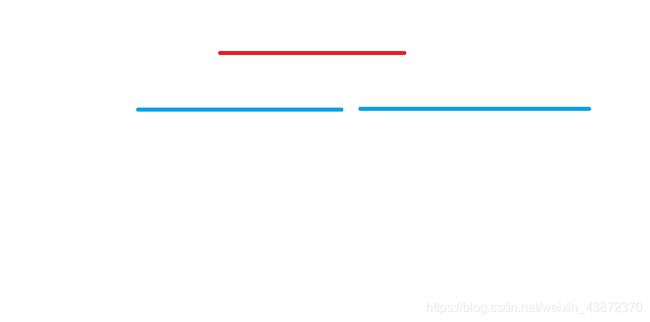
按照我们的贪心策略,应该选红色线段。事实上两条蓝色线段选了更好!
KO!
第二个贪心策略:
右端点为第一关键字从小到大排
貌似是对的
代码:
#include【难·贪心】
P2114 [NOI2014]起床困难综合症
这道题要利用位运算的性质以及二进制的好处
你就算是11111111111111111也比不过100000000000000000
位数大的必胜
所以可以从高到低贪心
十分easy
#includeP2672 [NOIP普及组2015] 推销员
从样例容易看出用贪心做,即第一次选了curr,则第二次在第一次的基础上再选出下一个。即要么选择curr左边的a,要么选择curr右边的b,若选择左边的a,则总疲劳值ans会加上A[a],若选择右边的b,则总疲劳值ans需加上A[b]+2*(S[b]-S[curr])。
总之, 下一次选择必基于上一次的选择 。
但问题来了,
怎么证明这个想法是对的?!
证明:
若已知Xn为拜访n户时的最优解,Xn={A[k1]+A[k2]+…+A[kn]}+2S[kn],即从近到远选择了{k1,k2,…kn}。
假设Yn+1为拜访n+1户时的最优解,Yn+1={A[p1]+A[p2]+…+A[pn]+A[pn+1]+2S[pn+1],且{p1,p2,…,pn+1}不包含{k1,k2,…kn}。
分类讨论 如下:
1)当pn+1==kn,即同户时,Yn+1 = {A[p1]+A[p2]+…+A[pn]+A[pn+1]}+2S[kn] < Xn+A[pk],其中pk不属于{k1,k2,…kn}
2)当S[pn+1]
3) 当S[pn+1]>S[kn],即pn+1在kn的右边时,Yn+1 = {A[p1]+A[p2]+…+A[pn]+A[pn+1]}+2*S[kn]+2(S[pn+1]-S[kn]) < Xn + A[pn+1] +2(S[pn+1]-S[kn])
综上,若{p1,p2,…,pn+1}不包含{k1,k2,…kn},Yn+1必不是最优解。
那么若{p1,p2,…,pn+1}包含{k1,k2,…kn},易知,Xn+1=Xn+max{左,右}。
那么若左边的最大值和右边的最大值相等时该取谁呢?
其实取取谁都一样,比如Xn最优解的最右方为第k户,左边最大为第k1户,右边最大为第k2户,
那么不管取左还是取右,得到的Xn+1值都一样,那么对于这两种取法会不会影响到Xn+2呢?
其实如果先取左k1,必然在Xn+2取到k2;如果先取右k2,必然在Xn+2取到k1,因为先取k2的话,右边的老二的值必然减小,肯定不如k1的大。
代码:
#includeand?
贪心和其它算法的结合/贪心的其它的奇奇怪怪的用处
【二分答案+贪心】
举个例子:P1316 丢瓶盖
二分答案,用贪心check
代码:
#include贪心+高精度
题目挺多的
就拿T63582(高精度)末日的时候有没有空?来说
题目背景
章原深爱着禾填田
但是好景不长,邪恶的轻阉鸡来了,他要统治世界
生命的最后一秒,他俩依然手牵手面对死亡······
然后悲剧发生了。
题目描述
章原把禾填田的手指掰了下来!
也不知道掰了几根。
话说禾填田几根手指也不知道
不过也好,这样就可以拯救世界了!
然后他们就用手指拯救了世界!
不过他们想知道,这几根手指最多能发挥的力量。
力量=所有根数的乘积
当然你已经知道了手指长度之和
输入输出格式
输入格式:
第一行一个整数n表示手指长度和
输出格式:
答案
输入输出样例
输入样例#1:
1
输出样例#1:
1
输入样例#2:
6
输出样例#2:
9
输入样例#3:
10
输出样例#3:
36
输入样例#4:
247
输出样例#4:
1773705952972151079792998522476599571212
说明
50%n小于等于100
n小于等于10000
首先这道题的贪心实在是太简单了!
小学奥数级别
能拆3就拆3
剩下的拆2
但系,要用高精度
哈哈哈哈哈哈哈哈
代码:
#includedijkstra
dijkstra是一种用贪心来求单源最短路的算法
它的贪心方法是:选最近的标记,拿被标记的更新没被标记的
显然,如果绕路比直走长,肯定选直走
参考代码:(普通dijkstra O(n^2) )
#include(堆优化的dijkstra O((n+m)logn) )
#includeprim
最小生成树prim算法
思路和dijkstra一毛一样
就不再放代码了
高级贪心
可以和图论、单调栈、单调队列等高级算法结合,会很难